DB4AI tries to help users get rid of tedious data handling, export and management by implanting AI computing power into the database. It sounds reasonable to use the database to store massive data, but in the face of a traditional database, users as algorithm engineers or AI beginners have to export the data of the data set and then import it into the AI computing framework to complete their computing tasks.
In detail, data relocation is a very troublesome and costly thing. The most direct way is to write the exported data to a file. Before the AI computing task, the program reads out the data in the file and feeds it to the model for training.
Here are a few obvious challenges:
1. Data security:
Without the data carrier of the database, it no longer has protective measures, including permission restriction, privacy protection and so on. The risk of data being deleted and tampered is greatly increased. For some fields, such as financial field and medical field, the data involves sensitive information. In the process of data handling, desensitization and other operations need to be carried out to degrade the sensitive information.
2. Data handling costs:
In AI computing, analysts and mathematicians hope to focus on model design and model calculation verification, and do not want to spend the cost on data handling and data sharing. Unfortunately, the time cost and computational cost of exporting massive data are inevitable and can not be ignored.
3. Version management of data:
No matter AP or TP database, there will be data addition, deletion, modification and query. For online learning, how to capture new data in real time; For off-line learning, how to detect the change of data set data distribution in time. In order to deal with these two problems, the traditional processing method may need to add more data control. At the same time, when data drift occurs, some users need to update the data set to maintain the effectiveness of the data, they will encounter the second problem mentioned above - increasing the cost. In particular, for different data processing methods and filtering conditions, users need to store different versions of data sets. This further increases storage costs.
To solve these problems, it will no longer exist in the database with DB4AI capability. The AI framework is built into the database to avoid the embarrassment of data handling, and all the calculation processes will be completed in the database. By eliminating the data movement link, DB4AI avoids the above problems programmatically.
The following will briefly introduce the use of openGauss database native AI framework:
1. Db4ai snapshot: data version control
DB4AI snapshots is a function used by the DB4AI feature to manage dataset versions. The data set is fixed by using snapshot, and the functions are divided into MSS model (using materialized algorithm to store the data entity of the original data set) and CSS model (using relative calculation algorithm to store the incremental information of the data). The incremental model greatly reduces the use space compared with full storage.
The whole function is divided into CREATE, PREPARE, SAMPLE, PUBLISH and PURGE operations. Examples of some operations are as follows:
1. CREATE SNAPSHOT
openGauss=# create snapshot s1@1.0 comment is 'first version' as select * from t1;schema | name--------+--------public | s1@1.0(1 row)
2. Sampling SMAPSHOT
Use 0.3 as the sampling rate in the snapshot s1@1.0.0 After sampling, the suffix of the generated sub snapshot is increased by '_ sample1'.
openGauss=# SAMPLE SNAPSHOT s1@1.0 STRATIFY BY id AS _sample1 AT RATIO .3; schema | name--------+---------------- public | s1_sample1@1.0(1 row)
This function can be used to generate test sets and training sets during AI calculation, such as the following syntax for 2 / 8 points:
openGauss=# SAMPLE SNAPSHOT s1@1.0 STRATIFY BY id AS _test AT RATIO .2, AS _train AT RATIO .8; schema | name--------+-------------- public | s1_test@1.0 public | s1_train@1.0(2 rows)
3. PUBLISH
In the snapshot feature, other states except the release state are not allowed to participate in AI calculation. When the user determines that the data in the current snapshot is available, change the snapshot status through PUBLISH SNAPSHOT. The current status of the snapshot can be viewed by the user through the db4ai.snapshot system table.
openGauss=# openGauss=# select * from db4ai.snapshot; id | parent_id | matrix_id | root_id | schema | name | owner | commands | comment | published | archived | created | row_count----+-----------+-----------+---------+--------+----------------+-------+-----------------------------+---------------+-----------+----------+----------------------------+----------- 0 | | | 0 | public | s1@1.0 | owner | {"select *","from t1",NULL} | first version | t | f | 2021-09-16 17:15:52.460933 | 5 1 | 0 | | 0 | public | s1_sample1@1.0 | owner | {"SAMPLE _sample1 .3 {id}"} | | f | f | 2021-09-16 17:19:12.832676 | 1 2 | 0 | | 0 | public | s1_test@1.0 | owner | {"SAMPLE _test .2 {id}"} | | f | f | 2021-09-16 17:20:46.778663 | 1 3 | 0 | | 0 | public | s1_train@1.0 | owner | {"SAMPLE _train .8 {id}"} | | f | f | 2021-09-16 17:20:46.833184 | 3(4 rows)4. Delete snapshot PURGE
openGauss=# PURGE SNAPSHOT s1_sample1@1.0; schema | name--------+---------------- public | s1_sample1@1.0(1 row)
2. DB4AI native AI syntax: used for model training and inference
This function completes AI computing tasks through specific syntax query. At present, AI operators are added to the openGauss database, and the operators are added to the execution plan to make full use of the computing power of the database to complete the model training and speculation tasks.
At present, the DB4AI engine in openGauss mainly supports four algorithms (more algorithms will be added later), namely, logistic_regression algorithm, linear_regression algorithm, support vector machine (svm_classification) and K-means clustering algorithm.
Two grammars are used for model training and speculation: CREATE MODEL and PREDICT BY.
CREATE MODEL: used for model training. This syntax will save the trained model information in the system table gs_model_warehouse of the database after completing the model training task. Users can view the model information by viewing the system table at any time. The system table not only saves the model description information, but also contains the relevant information during model training.
PREDICT BY: this syntax is used for speculation tasks. The database looks up the corresponding model in the system table through the model name and loads the model into memory. The database inputs the test data into the memory model to complete speculation and returns the results in the form of temporary result set.
Here is a simple example:
1. Training CREATE MODEL
This example takes K-means clustering algorithm as an example:

Training grammar has only four components: model name, algorithm type, training set and hyperparameter setting.
The training set supports input in the form of table, view, sub query, etc. the user only needs one query statement to complete the model hyperparameter setting and specify the training set. The next steps include input data, model saving, etc. the database is completed automatically.
When the training task is completed, the database will print success information.
At this time, the model has been written into the system table gs_model_warehouse. You can view the model information through table query:
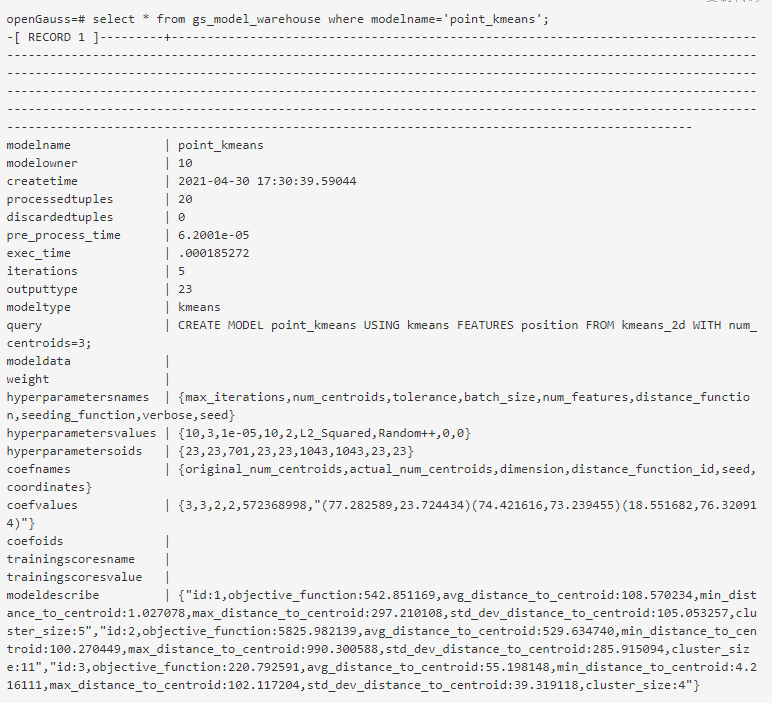
2, Guess by
Use the saved model to speculate. The query example is as follows:
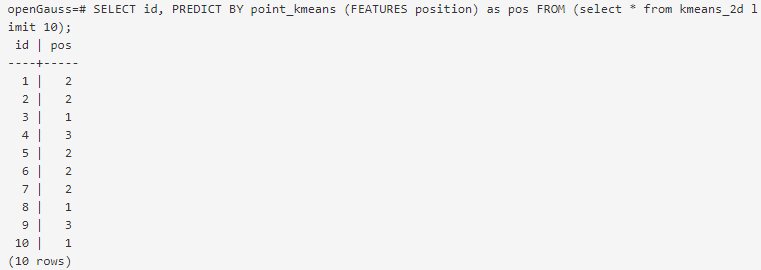
In PREDICT BY syntax, users only need to specify the model name, test set and input feature name to complete the speculation task.
Summary and Prospect
DB4AI has always been a hot topic in the database field. By intelligentizing the database, we can reduce the threshold and cost in the process of AI computing, and further fully release the computing resources of the database. Big data and AI computing are a good partner, so the database suitable for big data storage should not be independent of this system. By effectively combining the two, It is not only conducive to the AI calculation process, but also increases more possibilities for the performance optimization of the database itself.