0. Preface
It's been a while since I left my job. The epidemic hasn't passed yet. If I can't go out, I still don't go out. I feel like I've been living a long time every day. I haven't found a job yet. I'm just looking for LDD3 recently. I transplanted the AR8031 driver from my previous job. I just took advantage of this time to record and summarize. After all, good memory is not as good as bad writing.
1.Linux network device driver structure
The architecture of Linux network device driver is divided into four layers from top to bottom:
- Network protocol interface layer
It provides a unified interface for receiving and sending data packets to the network layer protocol. It sends data through the dev_queue_xmit() function and receives data through the netif_rx() function. Make upper layer protocol independent of specific equipment
- Network equipment interface layer
It provides the protocol interface layer with a uniform structure, net ﹣ device, which is used to describe the properties and operations of the specific network devices. The structure is the container of the functions in the device driver function layer.
- Device driver function layer providing actual function
Each function of this layer is a specific member of the net device data structure of the network device interface layer. It is a program for the network device hardware to complete the corresponding actions. The sending operation is started by the function of ndo_start_xmit(), and the receiving operation is triggered by the interrupt on the network device.
- Network device and media layer (for Linux system, both network device and media can be virtual)
The physical entity to send and receive packets, including network adapter and specific transmission media, which is physically driven by functions in device driver function layer.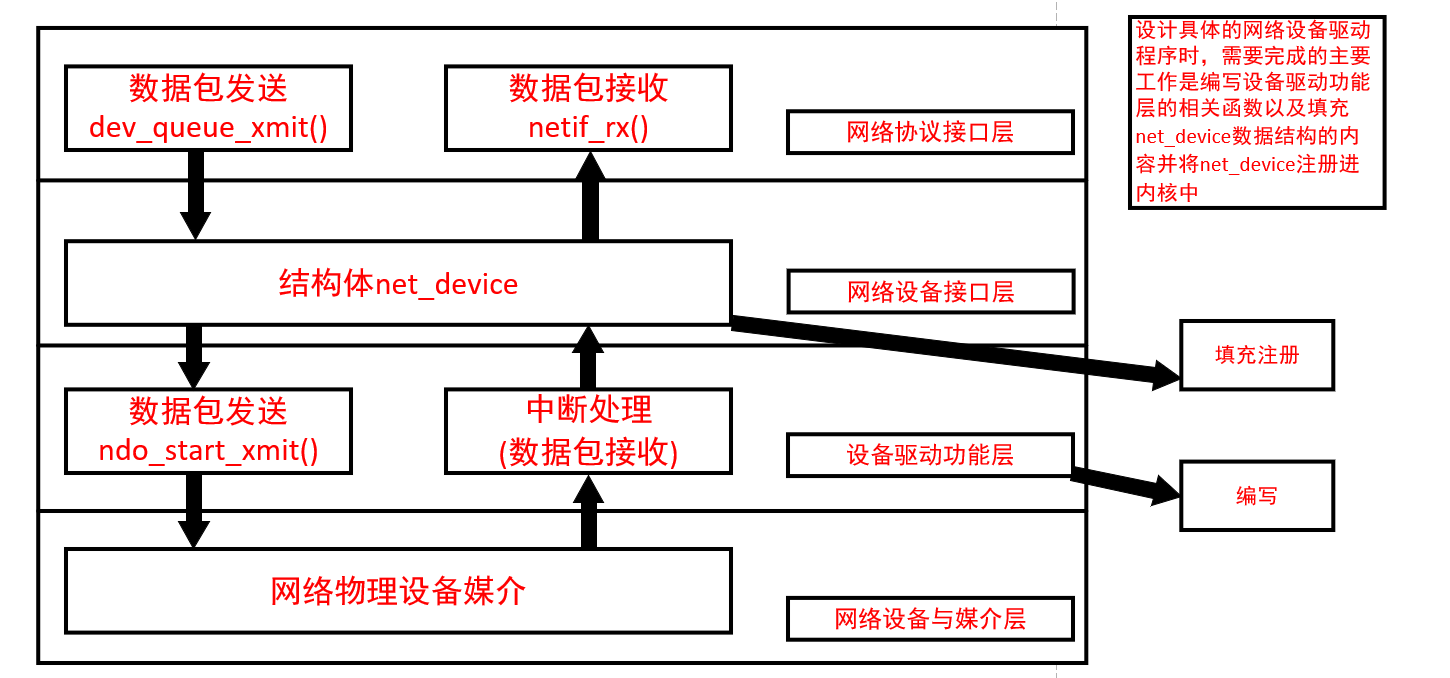
- Network protocol interface layer
The main function of network protocol interface layer is to provide transparent data packet sending and receiving interface for upper layer protocol. When the upper ARP or IP needs to send data packets, it will call the dev ﹣ queue ﹣ xmit() function of the network protocol interface layer to send data packets. At the same time, it needs to pass a pointer to the struct sk ﹣ buff data interface to the function. The upper layer also receives data packets by passing a pointer of strcut SK Bu data structure to the nentif_rx() function.
When sending packets, the network processing module of Linux kernel must establish a sk ﹐ buff containing the packets to be transmitted, and then pass sk ﹐ buff to the lower layer. Each layer adds different protocol headers in SK ﹐ buff until it is sent to the network device. Similarly, when a network device receives a packet from a network medium, it must transfer the received data to the SK ﹣ buff data structure and transfer it to the upper layer. Each layer strips off the corresponding protocol header until it is handed over to the user.
- Network equipment interface layer
Define a unified and abstract data structure for the ever-changing network devices.
The net device structure refers to a network device in the kernel, which is defined in the include/linux/netdevice.h file. The network device driver only needs to fill in the specific members of the net device and register the net device to realize the connection between the hardware operation function and the kernel.
2. Network device driver
- Equipment registration
The registration method of network device driver in its module initialization function is different from that of character driver. Because there is no equivalent to primary device number and secondary device number for network interface, network driver does not need to request such device number. For each newly detected interface, the driver inserts a data connection into the global network device list.
Each interface is described by a net device structure. Because it is related to other structures, it must be allocated dynamically. The kernel function used to perform the allocation is alloc ﹣ netdev ﹣ MQS.
struct net_device *alloc_netdev_mqs(int sizeof_priv, const char *name, unsigned char name_assign_type, void (*setup)(struct net_device *), unsigned int txqs, unsigned int rxqs)
- Sizeof priv is the size of the "private data" area of the driver, which is allocated to the network devices together with the net device structure.
- Name is the name of the interface, which is visible in user space.
- Step is an initialization function to set the rest of the net device structure.
- txqs is the number of TX subqueues allocated.
- rxqs is the number of RX subqueues allocated.
The return value of the function must be checked to determine that the assignment completed successfully.
Once the net UU device structure is initialized, the rest of the work is to pass the structure to the register UU netdev function.
ret = register_netdev(ndev); if (ret) goto failed_register;
When you call the register? Netdev function, you can call the driver to operate the device. So you have to register after initializing everything.
static const struct net_device_ops fec_netdev_ops = { .ndo_open = fec_enet_open, .ndo_stop = fec_enet_close, .ndo_start_xmit = fec_enet_start_xmit, .ndo_set_rx_mode = set_multicast_list, .ndo_validate_addr = eth_validate_addr, .ndo_tx_timeout = fec_timeout, .ndo_set_mac_address = fec_set_mac_address, .ndo_do_ioctl = fec_enet_ioctl, #ifdef CONFIG_NET_POLL_CONTROLLER .ndo_poll_controller = fec_poll_controller, #endif .ndo_set_features = fec_set_features, }; static int fec_enet_init(struct net_device *ndev) { struct fec_enet_private *fep = netdev_priv(ndev); struct bufdesc *cbd_base; dma_addr_t bd_dma; int bd_size; unsigned int i; unsigned dsize = fep->bufdesc_ex ? sizeof(struct bufdesc_ex) : sizeof(struct bufdesc); unsigned dsize_log2 = __fls(dsize); int ret; WARN_ON(dsize != (1 << dsize_log2)); #if defined(CONFIG_ARM) || defined(CONFIG_ARM64) fep->rx_align = 0xf; fep->tx_align = 0xf; #else fep->rx_align = 0x3; fep->tx_align = 0x3; #endif /* Check mask of the streaming and coherent API */ ret = dma_set_mask_and_coherent(&fep->pdev->dev, DMA_BIT_MASK(32)); if (ret < 0) { dev_warn(&fep->pdev->dev, "No suitable DMA available\n"); return ret; } fec_enet_alloc_queue(ndev); bd_size = (fep->total_tx_ring_size + fep->total_rx_ring_size) * dsize; /* Allocate memory for buffer descriptors. */ cbd_base = dmam_alloc_coherent(&fep->pdev->dev, bd_size, &bd_dma, GFP_KERNEL); if (!cbd_base) { return -ENOMEM; } /* Get the Ethernet address */ fec_get_mac(ndev); /* make sure MAC we just acquired is programmed into the hw */ fec_set_mac_address(ndev, NULL); /* Set receive and transmit descriptor base. */ for (i = 0; i < fep->num_rx_queues; i++) { struct fec_enet_priv_rx_q *rxq = fep->rx_queue[i]; unsigned size = dsize * rxq->bd.ring_size; rxq->bd.qid = i; rxq->bd.base = cbd_base; rxq->bd.cur = cbd_base; rxq->bd.dma = bd_dma; rxq->bd.dsize = dsize; rxq->bd.dsize_log2 = dsize_log2; rxq->bd.reg_desc_active = fep->hwp + offset_des_active_rxq[i]; bd_dma += size; cbd_base = (struct bufdesc *)(((void *)cbd_base) + size); rxq->bd.last = (struct bufdesc *)(((void *)cbd_base) - dsize); } for (i = 0; i < fep->num_tx_queues; i++) { struct fec_enet_priv_tx_q *txq = fep->tx_queue[i]; unsigned size = dsize * txq->bd.ring_size; txq->bd.qid = i; txq->bd.base = cbd_base; txq->bd.cur = cbd_base; txq->bd.dma = bd_dma; txq->bd.dsize = dsize; txq->bd.dsize_log2 = dsize_log2; txq->bd.reg_desc_active = fep->hwp + offset_des_active_txq[i]; bd_dma += size; cbd_base = (struct bufdesc *)(((void *)cbd_base) + size); txq->bd.last = (struct bufdesc *)(((void *)cbd_base) - dsize); } /* The FEC Ethernet specific entries in the device structure */ ndev->watchdog_timeo = TX_TIMEOUT; ndev->netdev_ops = &fec_netdev_ops; ndev->ethtool_ops = &fec_enet_ethtool_ops; writel(FEC_RX_DISABLED_IMASK, fep->hwp + FEC_IMASK); netif_napi_add(ndev, &fep->napi, fec_enet_rx_napi, NAPI_POLL_WEIGHT); if (fep->quirks & FEC_QUIRK_HAS_VLAN) /* enable hw VLAN support */ ndev->features |= NETIF_F_HW_VLAN_CTAG_RX; if (fep->quirks & FEC_QUIRK_HAS_CSUM) { ndev->gso_max_segs = FEC_MAX_TSO_SEGS; /* enable hw accelerator */ ndev->features |= (NETIF_F_IP_CSUM | NETIF_F_IPV6_CSUM | NETIF_F_RXCSUM | NETIF_F_SG | NETIF_F_TSO); fep->csum_flags |= FLAG_RX_CSUM_ENABLED; } if (fep->quirks & FEC_QUIRK_HAS_AVB) { fep->tx_align = 0; fep->rx_align = 0x3f; } ndev->hw_features = ndev->features; fec_restart(ndev); if (fep->quirks & FEC_QUIRK_MIB_CLEAR) fec_enet_clear_ethtool_stats(ndev); else fec_enet_update_ethtool_stats(ndev); return 0; }
static int fec_probe(struct platform_device *pdev) { ... /*Assign network devices*/ ndev = alloc_etherdev_mqs(sizeof(struct fec_enet_private) + FEC_STATS_SIZE, num_tx_qs, num_rx_qs); if (!ndev) return -ENOMEM; SET_NETDEV_DEV(ndev, &pdev->dev); ... ret = fec_enet_init(ndev); if (ret) goto failed_init; ... /*Network device registration*/ ret = register_netdev(ndev); if (ret) goto failed_register; device_init_wakeup(&ndev->dev, fep->wol_flag & FEC_WOL_HAS_MAGIC_PACKET); ... return ret; }
- Module uninstallation
The unregister_netdev function removes the interface from the system, and the free_netdev function returns the net_device structure to the system.
The internal purge function can only be executed after the device has been unregistered. It must be executed before the net device structure is returned to the system. Once the free net device is called, the device or private data area can no longer be referenced.
static int fec_drv_remove(struct platform_device *pdev) { struct net_device *ndev = platform_get_drvdata(pdev); struct fec_enet_private *fep = netdev_priv(ndev); struct device_node *np = pdev->dev.of_node; int ret; ret = pm_runtime_get_sync(&pdev->dev); if (ret < 0) return ret; cancel_work_sync(&fep->tx_timeout_work); fec_ptp_stop(pdev); unregister_netdev(ndev); fec_enet_mii_remove(fep); if (fep->reg_phy) regulator_disable(fep->reg_phy); if (of_phy_is_fixed_link(np)) of_phy_deregister_fixed_link(np); of_node_put(fep->phy_node); free_netdev(ndev); clk_disable_unprepare(fep->clk_ahb); clk_disable_unprepare(fep->clk_ipg); pm_runtime_put_noidle(&pdev->dev); pm_runtime_disable(&pdev->dev); return 0; }
- On and off
- open function
Before an interface can transmit packets, the kernel must open the interface and give it an address.
Before the interface can communicate with the outside world, the hardware address (MAC) should be copied from the hardware device to dev - > dev_addr. The hardware address can be copied to the device during opening.
Once you are ready to start sending data, the open method should also start the interface's transmission queue (allowing the interface to accept transmission packets). The kernel provides the following functions to start the queue.
static inline void netif_tx_start_all_queues(struct net_device *dev) { unsigned int i; for (i = 0; i < dev->num_tx_queues; i++) { struct netdev_queue *txq = netdev_get_tx_queue(dev, i); netif_tx_start_queue(txq); } }
static __always_inline void netif_tx_start_queue(struct netdev_queue *dev_queue) { clear_bit(__QUEUE_STATE_DRV_XOFF, &dev_queue->state); }
static int fec_enet_open(struct net_device *ndev) { struct fec_enet_private *fep = netdev_priv(ndev); int ret; bool reset_again; ... ret = fec_enet_alloc_buffers(ndev); if (ret) goto err_enet_alloc; /* Initialize MAC */ fec_restart(ndev); /* Probe and connect to PHY when open the interface */ ret = fec_enet_mii_probe(ndev); if (ret) goto err_enet_mii_probe; /*Start transmission queue*/ netif_tx_start_all_queues(ndev); device_set_wakeup_enable(&ndev->dev, fep->wol_flag & FEC_WOL_FLAG_ENABLE); return 0; err_enet_mii_probe: fec_enet_free_buffers(ndev); err_enet_alloc: fec_enet_clk_enable(ndev, false); clk_enable: pm_runtime_mark_last_busy(&fep->pdev->dev); pm_runtime_put_autosuspend(&fep->pdev->dev); pinctrl_pm_select_sleep_state(&fep->pdev->dev); return ret; }
- close function
The close function is the inverse of the open function.
static __always_inline void netif_tx_stop_queue(struct netdev_queue *dev_queue);
It is the reverse operation of netif ﹣ TX ﹣ start ﹣ queue. It marks that the device cannot transmit other packets. This function must be called when the interface is closed, but it can also be used to temporarily stop transmission.
static inline void netif_tx_disable(struct net_device *dev) { unsigned int i; int cpu; local_bh_disable(); cpu = smp_processor_id(); for (i = 0; i < dev->num_tx_queues; i++) { struct netdev_queue *txq = netdev_get_tx_queue(dev, i); __netif_tx_lock(txq, cpu); netif_tx_stop_queue(txq); __netif_tx_unlock(txq); } local_bh_enable(); }
static __always_inline void netif_tx_stop_queue(struct netdev_queue *dev_queue) { set_bit(__QUEUE_STATE_DRV_XOFF, &dev_queue->state); }
static int fec_enet_close(struct net_device *ndev) { struct fec_enet_private *fep = netdev_priv(ndev); phy_stop(ndev->phydev); if (netif_device_present(ndev)) { napi_disable(&fep->napi); netif_tx_disable(ndev); fec_stop(ndev); } phy_disconnect(ndev->phydev); if (fep->quirks & FEC_QUIRK_ERR006687) imx6q_cpuidle_fec_irqs_unused(); fec_enet_update_ethtool_stats(ndev); fec_enet_clk_enable(ndev, false); pinctrl_pm_select_sleep_state(&fep->pdev->dev); pm_runtime_mark_last_busy(&fep->pdev->dev); pm_runtime_put_autosuspend(&fep->pdev->dev); fec_enet_free_buffers(ndev); return 0; }
- Packet transfer
To transmit a packet, the kernel calls the driver's ndo start Xmit to put the data into the outgoing queue. Each packet processed by the kernel is in a socket buffer structure (sk_buff). The input / output buffers of all sockets are linked lists formed by sk_buff structure.
The socket buffer passed to ndo_start_xmit contains the physical packets (in its media format) and has a full transport layer packet header. SKB - > data refers to the packets to be transmitted, and SKB - > len is the length in octet.
static int fec_enet_start_xmit(struct sk_buff *skb, struct net_device *dev) { struct fec_enet_private *fep = netdev_priv(dev); struct bufdesc *bdp; void *bufaddr; unsigned short status; unsigned long estatus; unsigned long flags; ... /*disable interrupt*/ spin_lock_irqsave(&fep->hw_lock, flags); /*TX ring Entrance*/ bdp = fep->cur_tx; status = bdp->cbd_sc; ... /*Set buffer length and buffer pointer*/ bufaddr = skb->data; bdp->cbd_datlen = skb->len; /*4 byte alignment*/ if (((unsigned long) bufaddr) & FEC_ALIGNMENT) { unsigned int index; index = bdp - fep->tx_bd_base; memcpy(fep->tx_bounce[index], (void *)skb->data, skb->len); bufaddr = fep->tx_bounce[index]; } ... /* Save skb pointer */ fep->tx_skbuff[fep->skb_cur] = skb; dev->stats.tx_bytes += skb->len; fep->skb_cur = (fep->skb_cur+1) & TX_RING_MOD_MASK; /* Establish streaming DMA mapping*/ bdp->cbd_bufaddr = dma_map_single(&dev->dev, bufaddr, FEC_ENET_TX_FRSIZE, DMA_TO_DEVICE); /* Tell FEC that it is ready and interrupt after sending*/ status |= (BD_ENET_TX_READY | BD_ENET_TX_INTR | BD_ENET_TX_LAST | BD_ENET_TX_TC); bdp->cbd_sc = status; /*Triggered transmission*/ writel(0, fep->hwp + FEC_X_DES_ACTIVE); /* If this was the last BD in the ring, start at the beginning again. */ if (status & BD_ENET_TX_WRAP) bdp = fep->tx_bd_base; else bdp++; if (bdp == fep->dirty_tx) { fep->tx_full = 1; /*Inform the network system that no other packet transfer can be started until the hardware can accept the new data*/ netif_stop_queue(dev); } fep->cur_tx = bdp; spin_unlock_irqrestore(&fep->hw_lock, flags); return NETDEV_TX_OK; }
static void fec_enet_tx(struct net_device *dev) { struct fec_enet_private *fep; struct fec_ptp_private *fpp; struct bufdesc *bdp; unsigned short status; unsigned long estatus; struct sk_buff *skb; fep = netdev_priv(dev); fpp = fep->ptp_priv; spin_lock(&fep->hw_lock); bdp = fep->dirty_tx; while (((status = bdp->cbd_sc) & BD_ENET_TX_READY) == 0) { ... /*Delete DMA map*/ dma_unmap_single(&dev->dev, bdp->cbd_bufaddr, FEC_ENET_TX_FRSIZE, DMA_TO_DEVICE); bdp->cbd_bufaddr = 0; skb = fep->tx_skbuff[fep->skb_dirty]; /*Check error*/ if (status & (BD_ENET_TX_HB | BD_ENET_TX_LC | BD_ENET_TX_RL | BD_ENET_TX_UN | BD_ENET_TX_CSL)) { dev->stats.tx_errors++; if (status & BD_ENET_TX_HB) /* No heartbeat */ dev->stats.tx_heartbeat_errors++; if (status & BD_ENET_TX_LC) /* Late collision */ dev->stats.tx_window_errors++; if (status & BD_ENET_TX_RL) /* Retrans limit */ dev->stats.tx_aborted_errors++; if (status & BD_ENET_TX_UN) /* Underrun */ dev->stats.tx_fifo_errors++; if (status & BD_ENET_TX_CSL) /* Carrier lost */ dev->stats.tx_carrier_errors++; } else { dev->stats.tx_packets++; } if (status & BD_ENET_TX_READY) printk("HEY! Enet xmit interrupt and TX_READY.\n"); /* Deferred means some collisions occurred during transmit, * but we eventually sent the packet OK. */ if (status & BD_ENET_TX_DEF) dev->stats.collisions++; #if defined(CONFIG_ENHANCED_BD) if (fep->ptimer_present) { estatus = bdp->cbd_esc; if (estatus & BD_ENET_TX_TS) fec_ptp_store_txstamp(fpp, skb, bdp); } #elif defined(CONFIG_IN_BAND) if (fep->ptimer_present) { if (status & BD_ENET_TX_PTP) fec_ptp_store_txstamp(fpp, skb, bdp); } #endif /*Release the skb buffer*/ dev_kfree_skb_any(skb); fep->tx_skbuff[fep->skb_dirty] = NULL; fep->skb_dirty = (fep->skb_dirty + 1) & TX_RING_MOD_MASK; /* Update pointer to next buffer descriptor to transfer*/ if (status & BD_ENET_TX_WRAP) bdp = fep->tx_bd_base; else bdp++; /* Since we have freed up a buffer, the ring is no longer full */ if (fep->tx_full) { fep->tx_full = 0; if (netif_queue_stopped(dev)) /*Concurrent transmission, notify the network system to start the transmission of packets again*/ netif_wake_queue(dev); } } fep->dirty_tx = bdp; spin_unlock(&fep->hw_lock); }
- Packet reception
It is more complex to receive data from the network than to transmit data, because an sk_buff must be allocated in the atomic context and passed to the upper layer for processing. The network driver realizes two modes of receiving packets: interrupt driving mode and polling mode.
(1) . update its statistics counter to record each received packet, main members rx_packets, rx_bytes, etc.
(2) . configure a buffer to save packets. The allocation function of the buffer needs to know the data length.
(3) . once you have a valid sk_buff pointer, call memcpy to copy the packet data into the buffer.
(4) . before processing packets, the network layer must know some information about the packets. Therefore, it is necessary to correctly assign values to the dev and protocol members before passing the buffer to the upper layer.
(5) Finally, it is executed by netif_rx to pass the socket buffer to the upper software for processing.
static void fec_enet_rx(struct net_device *dev) { struct fec_enet_private *fep = netdev_priv(dev); struct fec_ptp_private *fpp = fep->ptp_priv; struct bufdesc *bdp; unsigned short status; struct sk_buff *skb; ushort pkt_len; __u8 *data; #ifdef CONFIG_M532x flush_cache_all(); #endif spin_lock(&fep->hw_lock); /*Get information about incoming packets*/ bdp = fep->cur_rx; while (!((status = bdp->cbd_sc) & BD_ENET_RX_EMPTY)) { ... /*Check error*/ #if 0 if (status & (BD_ENET_RX_LG | BD_ENET_RX_SH | BD_ENET_RX_NO | BD_ENET_RX_CR | BD_ENET_RX_OV)) { #else if (status & (BD_ENET_RX_LG | BD_ENET_RX_SH | BD_ENET_RX_NO | BD_ENET_RX_OV)) { #endif dev->stats.rx_errors++; if (status & (BD_ENET_RX_LG | BD_ENET_RX_SH)) { /* Frame too long or too short. */ dev->stats.rx_length_errors++; } if (status & BD_ENET_RX_NO) /* Frame alignment */ dev->stats.rx_frame_errors++; if (status & BD_ENET_RX_CR) /* CRC Error */ dev->stats.rx_crc_errors++; if (status & BD_ENET_RX_OV) /* FIFO overrun */ dev->stats.rx_fifo_errors++; } /* Report late collisions as a frame error. * On this error, the BD is closed, but we don't know what we * have in the buffer. So, just drop this frame on the floor. */ if (status & BD_ENET_RX_CL) { dev->stats.rx_errors++; dev->stats.rx_frame_errors++; goto rx_processing_done; } /*Update statistics counter, total octet transferred, address of data*/ dev->stats.rx_packets++; pkt_len = bdp->cbd_datlen; dev->stats.rx_bytes += pkt_len; data = (__u8*)__va(bdp->cbd_bufaddr); dma_unmap_single(NULL, bdp->cbd_bufaddr, bdp->cbd_datlen, DMA_FROM_DEVICE); #ifdef CONFIG_ARCH_MXS swap_buffer(data, pkt_len); #endif /* Allocate a buffer to hold packets, 16 byte aligned, packet length including FCS, but we do not want to include FCS when passing the upper layer*/ skb = dev_alloc_skb(pkt_len - 4 + NET_IP_ALIGN); if (unlikely(!skb)) { printk("%s: Memory squeeze, dropping packet.\n", dev->name); dev->stats.rx_dropped++; } else { /*Add data and tail. The header space can be reserved before the buffer is filled. Most Ethernet interfaces retain two bytes before the packet, so that the IP header can be aligned on the 16 byte boundary after the 14 byte Ethernet header*/ skb_reserve(skb, NET_IP_ALIGN); /*Update the tail and len members in the sk_buff structure to add data at the end of the buffer.*/ skb_put(skb, pkt_len - 4); /* Make room */ /*Copy packet data into buffer*/ skb_copy_to_linear_data(skb, data, pkt_len - 4); /* 1588 messeage TS handle */ if (fep->ptimer_present) fec_ptp_store_rxstamp(fpp, skb, bdp); /*Determine the protocol ID of the package*/ skb->protocol = eth_type_trans(skb, dev); /*Pass socket buffer to upper software for processing*/ netif_rx(skb); } bdp->cbd_bufaddr = dma_map_single(NULL, data, bdp->cbd_datlen, DMA_FROM_DEVICE); rx_processing_done: /* Clear the status flags for this buffer */ status &= ~BD_ENET_RX_STATS; /* Mark the buffer empty */ status |= BD_ENET_RX_EMPTY; bdp->cbd_sc = status; #ifdef CONFIG_ENHANCED_BD bdp->cbd_esc = BD_ENET_RX_INT; bdp->cbd_prot = 0; bdp->cbd_bdu = 0; #endif /* Update BD pointer to next entry */ if (status & BD_ENET_RX_WRAP) bdp = fep->rx_bd_base; else bdp++; /* Doing this here will keep the FEC running while we process * incoming frames. On a heavily loaded network, we should be * able to keep up at the expense of system resources. */ writel(0, fep->hwp + FEC_R_DES_ACTIVE); } fep->cur_rx = bdp; spin_unlock(&fep->hw_lock); }
- Interrupt handling
Most hardware interfaces are controlled by interrupt handling routines. The interface triggers an interrupt under two possible events: the arrival of a new packet, or the transfer of an outgoing packet is complete. The network interface can also generate the generation of interrupt notification error, connection status, etc.
The interrupt routine checks the status register in the physical device to distinguish the arrival interrupt of new packets from the completion interrupt of data transmission.
For the "transfer completed" processing, the statistics are updated, and the socket buffer that is no longer used is returned to the system by calling dev_kfree_skb_any. Finally, if the driver temporarily terminates the transmission queue, restart the transmission queue using netif? Wake? Queue (see packet transmission).
In contrast to transmission, packet reception does not require any special terminal processing.
static irqreturn_t fec_enet_interrupt(int irq, void * dev_id) { struct net_device *dev = dev_id; struct fec_enet_private *fep = netdev_priv(dev); struct fec_ptp_private *fpp = fep->ptp_priv; uint int_events; irqreturn_t ret = IRQ_NONE; do { int_events = readl(fep->hwp + FEC_IEVENT); writel(int_events, fep->hwp + FEC_IEVENT); if (int_events & FEC_ENET_RXF) { ret = IRQ_HANDLED; fec_enet_rx(dev); } /*Transfer complete, or non fatal error. Update buffer descriptor*/ if (int_events & FEC_ENET_TXF) { ret = IRQ_HANDLED; fec_enet_tx(dev); } if (int_events & FEC_ENET_TS_TIMER) { ret = IRQ_HANDLED; if (fep->ptimer_present && fpp) fpp->prtc++; } if (int_events & FEC_ENET_MII) { ret = IRQ_HANDLED; complete(&fep->mdio_done); } } while (int_events); return ret; }
- Do not use receive interrupt
When the interface receives every packet, the processor will be interrupted, which will degrade the system performance. In order to improve the performance of Linux on the broadband system, another interface based on polling is provided, which is called NAPI.
A NAPI interface must be able to hold multiple packets. The interface can not interrupt the received packets, but can also interrupt the transmission and other time.
During initialization, the weight and poll members of NaPi struct must be set, and the poll member must be set as the polling function of the driver.
struct napi_struct { ... int weight; ... int (*poll)(struct napi_struct *, int); ... };
static int fec_enet_init(struct net_device *ndev) { struct fec_enet_private *fep = netdev_priv(ndev); struct bufdesc *cbd_base; dma_addr_t bd_dma; int bd_size; unsigned int i; unsigned dsize = fep->bufdesc_ex ? sizeof(struct bufdesc_ex) : sizeof(struct bufdesc); unsigned dsize_log2 = __fls(dsize); int ret; ... writel(FEC_RX_DISABLED_IMASK, fep->hwp + FEC_IMASK); /*Set the weight and poll members of NaPi struct*/ netif_napi_add(ndev, &fep->napi, fec_enet_rx_napi, NAPI_POLL_WEIGHT); ... return 0; }
The next step in creating the NAPI driver is to modify the interrupt handling routine. When the interface notifies the packet of arrival, the interrupt program cannot process the packet. It wants to disable receiving interrupts and tell the kernel to start the polling interface from now on.
static irqreturn_t fec_enet_interrupt(int irq, void *dev_id) { struct net_device *ndev = dev_id; struct fec_enet_private *fep = netdev_priv(ndev); uint int_events; irqreturn_t ret = IRQ_NONE; int_events = readl(fep->hwp + FEC_IEVENT); writel(int_events, fep->hwp + FEC_IEVENT); fec_enet_collect_events(fep, int_events); if ((fep->work_tx || fep->work_rx) && fep->link) { ret = IRQ_HANDLED; /*Check if napi can schedule*/ if (napi_schedule_prep(&fep->napi)) { /*disable interrupt*/ writel(FEC_NAPI_IMASK, fep->hwp + FEC_IMASK); /*Dispatch receive function, call poll function*/ __napi_schedule(&fep->napi); } } if (int_events & FEC_ENET_MII) { ret = IRQ_HANDLED; complete(&fep->mdio_done); } return ret; }
When the interface notifies the packet, the interrupt handling routine is separated from the interface, calling the __napi_schedule function, and then calling the poll function.
static int fec_enet_rx_napi(struct napi_struct *napi, int budget) { struct net_device *ndev = napi->dev; struct fec_enet_private *fep = netdev_priv(ndev); int pkts; /*Receive packets*/ pkts = fec_enet_rx(ndev, budget); fec_enet_tx(ndev); if (pkts < budget) { /*If all packets are processed, call NaPi? Complete? Done to close the polling function and reopen the interrupt*/ napi_complete_done(napi, pkts); writel(FEC_DEFAULT_IMASK, fep->hwp + FEC_IMASK); } return pkts; }
- Socket buffer
sk_buff structure is very important. It is defined in the include/linux/skbuff.h file, which means "socket buffer". It is used to transfer data between layers in the Linux network subsystem.
When sending packets, the network processing module of the Linux kernel must assign a sk ﹐ buff containing the packets to be transmitted, and then pass the SK ﹐ buff to the lower layer. Each layer adds different protocol headers in the SK ﹐ buff until it is sent to the network device. Similarly, when a network device receives a packet from a network medium, it must copy the received data to the SK ﹣ buff data structure and transfer it to the upper layer, and each layer strips off the corresponding protocol header until it is handed over to the user.
struct sk_buff { union { struct { /* These two members must be first. */ struct sk_buff *next; struct sk_buff *prev; union { struct net_device *dev; /*Devices that receive and send this buffer*/ /* Some protocols might use this space to store information, * while device pointer would be NULL. * UDP receive path is one user. */ unsigned long dev_scratch; }; }; struct rb_node rbnode; /* used in netem, ip4 defrag, and tcp stack */ struct list_head list; }; union { struct sock *sk; int ip_defrag_offset; }; union { ktime_t tstamp; u64 skb_mstamp_ns; /* earliest departure time */ }; /* * This is the control buffer. It is free to use for every * layer. Please put your private variables there. If you * want to keep them across layers you have to do a skb_clone() * first. This is owned by whoever has the skb queued ATM. */ char cb[48] __aligned(8); union { struct { unsigned long _skb_refdst; void (*destructor)(struct sk_buff *skb); }; struct list_head tcp_tsorted_anchor; }; #if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE) unsigned long _nfct; #endif /*len It is the length of all data in the data package, and data "len" is the length of the data segment that is divided and stored.*/ unsigned int len, data_len; __u16 mac_len, hdr_len; /* Following fields are _not_ copied in __copy_skb_header() * Note that queue_mapping is here mostly to fill a hole. */ __u16 queue_mapping; /* if you move cloned around you also must adapt those constants */ #ifdef __BIG_ENDIAN_BITFIELD #define CLONED_MASK (1 << 7) #else #define CLONED_MASK 1 #endif #define CLONED_OFFSET() offsetof(struct sk_buff, __cloned_offset) __u8 __cloned_offset[0]; __u8 cloned:1, nohdr:1, fclone:2, peeked:1, head_frag:1, pfmemalloc:1; #ifdef CONFIG_SKB_EXTENSIONS __u8 active_extensions; #endif /* fields enclosed in headers_start/headers_end are copied * using a single memcpy() in __copy_skb_header() */ /* private: */ __u32 headers_start[0]; /* public: */ /* if you move pkt_type around you also must adapt those constants */ #ifdef __BIG_ENDIAN_BITFIELD #define PKT_TYPE_MAX (7 << 5) #else #define PKT_TYPE_MAX 7 #endif #define PKT_TYPE_OFFSET() offsetof(struct sk_buff, __pkt_type_offset) __u8 __pkt_type_offset[0]; __u8 pkt_type:3; /*The type of packet used in the send process. It is the driver's responsibility to set it to either pack? Host, pack? Otherhost, pack? Broadcast, or pack? Multicast.*/ __u8 ignore_df:1; __u8 nf_trace:1; __u8 ip_summed:2; /*For the verification policy of packets, the driver sets the incoming packets.*/ __u8 ooo_okay:1; __u8 l4_hash:1; __u8 sw_hash:1; __u8 wifi_acked_valid:1; __u8 wifi_acked:1; __u8 no_fcs:1; /* Indicates the inner headers are valid in the skbuff. */ __u8 encapsulation:1; __u8 encap_hdr_csum:1; __u8 csum_valid:1; #ifdef __BIG_ENDIAN_BITFIELD #define PKT_VLAN_PRESENT_BIT 7 #else #define PKT_VLAN_PRESENT_BIT 0 #endif #define PKT_VLAN_PRESENT_OFFSET() offsetof(struct sk_buff, __pkt_vlan_present_offset) __u8 __pkt_vlan_present_offset[0]; __u8 vlan_present:1; __u8 csum_complete_sw:1; __u8 csum_level:2; __u8 csum_not_inet:1; __u8 dst_pending_confirm:1; #ifdef CONFIG_IPV6_NDISC_NODETYPE __u8 ndisc_nodetype:2; #endif __u8 ipvs_property:1; __u8 inner_protocol_type:1; __u8 remcsum_offload:1; #ifdef CONFIG_NET_SWITCHDEV __u8 offload_fwd_mark:1; __u8 offload_l3_fwd_mark:1; #endif #ifdef CONFIG_NET_CLS_ACT __u8 tc_skip_classify:1; __u8 tc_at_ingress:1; __u8 tc_redirected:1; __u8 tc_from_ingress:1; #endif #ifdef CONFIG_TLS_DEVICE __u8 decrypted:1; #endif #ifdef CONFIG_NET_SCHED __u16 tc_index; /* traffic control index */ #endif union { __wsum csum; struct { __u16 csum_start; __u16 csum_offset; }; }; __u32 priority; int skb_iif; __u32 hash; __be16 vlan_proto; __u16 vlan_tci; #if defined(CONFIG_NET_RX_BUSY_POLL) || defined(CONFIG_XPS) union { unsigned int napi_id; unsigned int sender_cpu; }; #endif #ifdef CONFIG_NETWORK_SECMARK __u32 secmark; #endif union { __u32 mark; __u32 reserved_tailroom; }; union { __be16 inner_protocol; __u8 inner_ipproto; }; __u16 inner_transport_header; __u16 inner_network_header; __u16 inner_mac_header; /*The message header of each layer in the packet, the transport header is the transmission layer header, the network header is the network layer header, and the MAC header is the link layer header*/ __be16 protocol; __u16 transport_header; __u16 network_header; __u16 mac_header; /* private: */ __u32 headers_end[0]; /* public: */ /* These elements must be at the end, see alloc_skb() for details. */ /*The pointer to the data in the packet, the head to the beginning of the allocated space, and the data is the beginning of the effective octet (usually larger than the head), *tail Is the end of a valid octet, and end points to the maximum address that tail can reach. *It can also be concluded from these pointers that the available buffer space is SKB - > end - SKB - > head, and the currently used data space is SKB - > tail - SKB - > data. */ sk_buff_data_t tail; sk_buff_data_t end; unsigned char *head, *data; unsigned int truesize; refcount_t users; #ifdef CONFIG_SKB_EXTENSIONS /* only useable after checking ->active_extensions != 0 */ struct skb_ext *extensions; #endif };
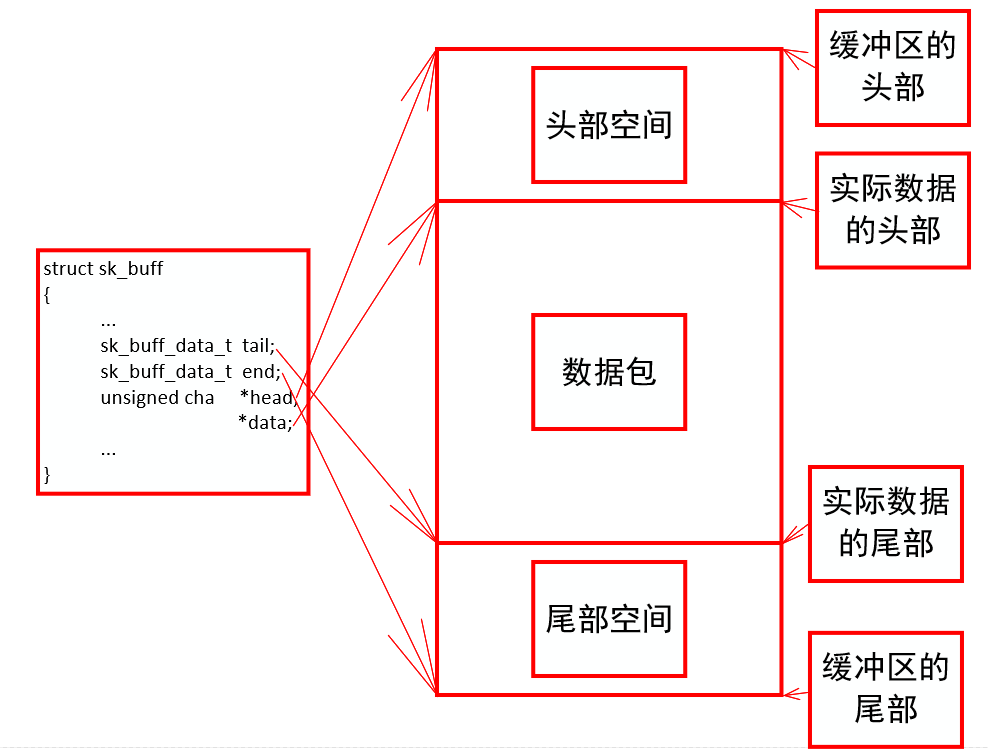
reference material:
LINUX device driver version 3
linux-5.4.9
linux-2.6.35.3

