1 getting started with elasticsearch
Elasticsearch is an open source search engine based on Apache Lucene. Whether in open source or proprietary domain, Lucene can be regarded as the most advanced, best performing and most powerful search engine library so far. However, Lucene is just a library. If you want to use it, you must use Java as the development language and integrate it directly into your application. What's worse, Lucene is very complex. You need to deeply understand the relevant knowledge of retrieval to understand how it works.
Elasticsearch also uses Java to develop and use Lucene as its core to realize all indexing and search functions, but its purpose is to hide the complexity of Lucene through a simple RESTful API, so as to make full-text search simple.
1.1 Elasticsearch installation
1.1 downloading software
Elasticsearch's official address: Elastic
Download address: https://www.elastic.co/cn/downloads/past-releases#elasticsearch
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-r95dln0c-1637994003567)( https://i.loli.net/2021/11/23/SkNfEl75oTJXFAv.png )]
Select the version of Elasticsearch as Windows.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-wexu9p1f-1637994003571)( https://i.loli.net/2021/11/27/zidIg8xhqcWLyYw.png )]
1.2 installing software
The installation is completed after decompression. The directory structure of Elasticsearch after decompression is as follows:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-ug83bqla-1637994003573)( https://i.loli.net/2021/11/23/kDyaBsmVzvblx9N.png )]
After decompression, enter the bin file directory and click elasticsearch.bat to start the ES service:
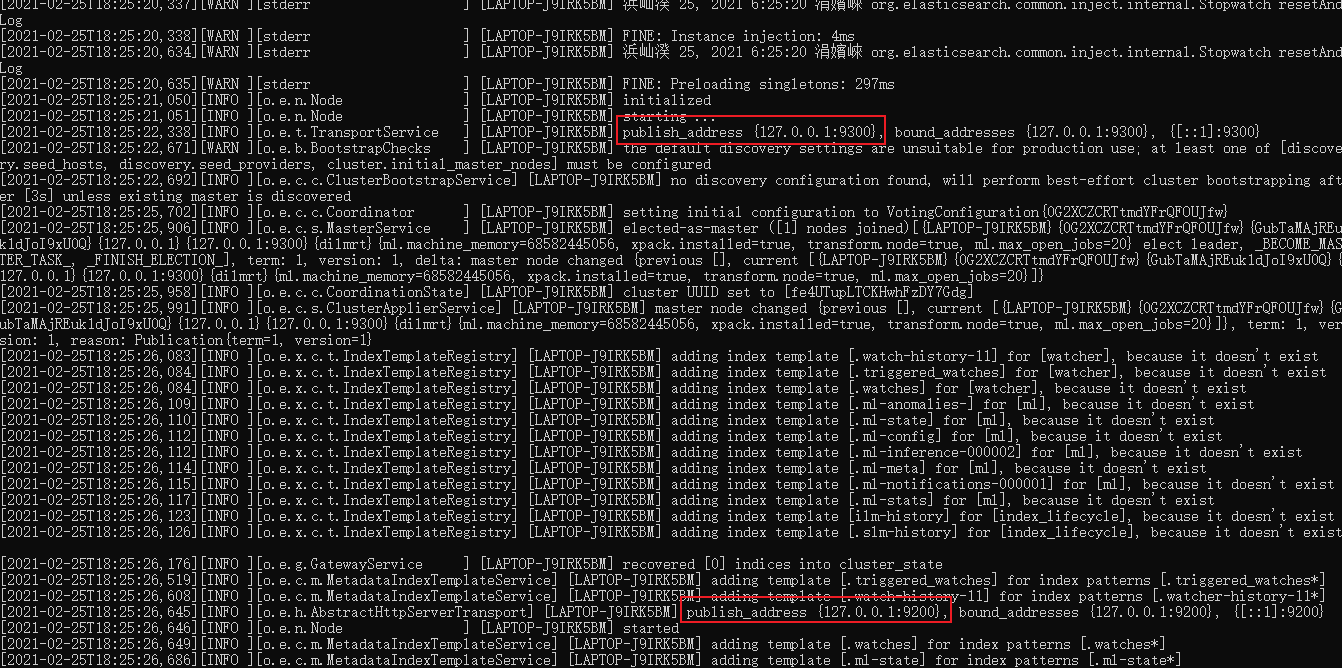
Note: Port 9300 is the communication port of Elasticsearch cluster components, and port 9200 is the http protocol RESTful port accessed by the browser.
Open with browser: http://localhost:9200/ , the following content appears, and the ES installation is started.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-7muz0lhl-1637994003578)( https://i.loli.net/2021/11/23/9FaEzUToSPQ5jkO.png )]
1.2 basic operation
Elastic search is a document oriented database, where a piece of data is a document. For understanding, the concept of document data stored in Elasticsearch and data stored in relational database MySQL can be compared:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-sq1chqlt-1637994003579)( https://i.loli.net/2021/11/23/lcwHNpTLhKJXOdW.png )]
The index in ES can be regarded as a library, while Types is equivalent to a table and Documents is equivalent to rows of a table. The concept of Types has been gradually weakened with the version update. In Elasticsearch 6.X, an index can only contain one Type. In Elasticsearch 7.X, the concept of Type has been deleted.
1.2.1 index operation
1.2.1.1 create index
Create an index and send a request to the server using PUT: http://localhost:9200/test_index_02,test_ index_ 02 is the corresponding index name:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-csjj4kjc-1637994003580)( https://i.loli.net/2021/11/23/xpe1c9kMulvO75F.png )]
After the request, the server returns a response:
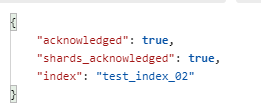
Return result Field Description:
{
"acknowledged"[Response results]: true, // true operation succeeded
"shards_acknowledged"[[segmentation results]: true, // Slicing operation succeeded
"index"[[index name]: "test_index_02"
}
// Note: the default number of slices for creating an index library is 1. In elastic search before 7.0.0, the default number is 5
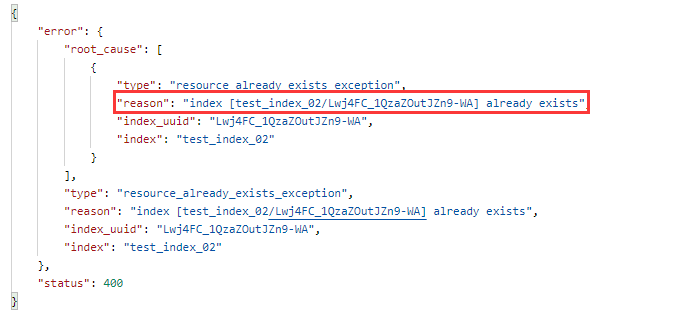
If the index is added repeatedly, an error message will be returned:
1.2.1.2 view all indexes created
Send GET request to ES server: http://localhost:9200/_cat/indices?v
In the above request path_ cat indicates view, indexes indicates index, and the server response results are as follows:
[external link picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-8lug1dks-1637994003584)( https://i.loli.net/2021/11/23/h6GEbUtfvNQ8Bk3.png )]
Return result Field Description:
| Header | meaning |
|---|---|
| health | Current server health status: green, yellow, red |
| status | Index open and close status |
| index | Index name |
| uuid | Indexes are numbered uniformly and generated automatically by the server |
| pri | Number of main segments |
| rep | Number of copies |
| docs.count | Number of documents available |
| docs.deleted | Number of documents deleted (logical deletion) |
| store.size | Overall space occupied by main partition and sub partition |
| pri.store.size | Space occupied by main partition |
1.2.1.3 view the created specified index
Send GET request to ES server: http://localhost:9200/test_index_01,test_ index_ 01 is the index name:
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-EE2aXEaO-1637994003584)(Elasticsearch/image-20210904231348533.png)]
After the request, the server returns a response:

Return result Field Description:
{
"test_index_01"[[index name]: {
"aliases"[Alias]: {},
"mappings"[Mapping]: {},
"settings"[[settings]: {
"index": [set up-[index]{
"creation_date"[set up-Indexes-[creation time]: "1630767552252",
"number_of_shards"[set up-Indexes-[number of main segments]: "1",
"number_of_replicas"[set up-Indexes-Number of sub segments]: "1",
"uuid"[set up-Indexes-[unique identification]: "GJwBy-0nShG6LQsWJarDbQ",
"version"[set up-Indexes-[version number]: {
"created": "7080099"
},
"provided_name"[set up-Indexes-[name]: "test_index_01"
}
}
}
}
1.2.1.4 viewing the total number of indexed documents
Send GET request to ES server: http://localhost:9200/movies/_count, movies is the index name_ count counts the number of documents.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-gmcsjdwr-1637994003586)( https://i.loli.net/2021/11/23/6r8nm4EILNKqvRh.png )]
1.2.1.5 delete specified index
Send DELETE request to ES server: http://localhost:9200/test_index_02,test_ index_ 02 is the index name:
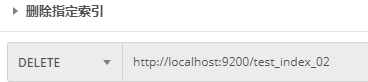
Server response result:

After deleting the index and accessing the index again, the server will return a response: the index does not exist.

1.2.2 document operation
1.2.2.1 create document
After the index is created, create a document on the index and add data.
Send POST request to ES server: http://localhost:9200/test_index_01/_doc. The content of the request body is:
{
"brand": "millet",
"model": "MIX4",
"images": "https://cdn.cnbj1.fds.api.mi-img.com/product-images/mix4/specs_m.png",
"price": 3999.00,
"stock": 1000
}
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-8urcczau-1637994003590)( https://i.loli.net/2021/11/23/n87MuQAijoO9JH1.png )]
The server returned the response result:

Return result Field Description:
{
"_index"[[index name]: "test_index_01",
"_type"[type-[document]: "_doc",
"_id"[[unique identification]: "LPp4sXsB7_Yk5DHNib04", // Similar to primary key, randomly generated
"_version"[[version number]: 1,
"result"[Results]: "created", // created: indicates that the creation was successful, and updated: indicates that the update was successful
"_shards"[[slice]: {
"total"[Slice-Total]: 2,
"successful"[Slice-[success]: 1,
"failed"[Slice-Failed]: 0
},
"_seq_no"[[incremental serial number]: 0,
"_primary_term": 1
}
After the above document is created successfully, by default, the ES server will randomly generate a unique ID.
You can also specify a unique ID when creating a document: http://localhost:9200/test_index_01/_doc/1, 1 is the specified unique ID.
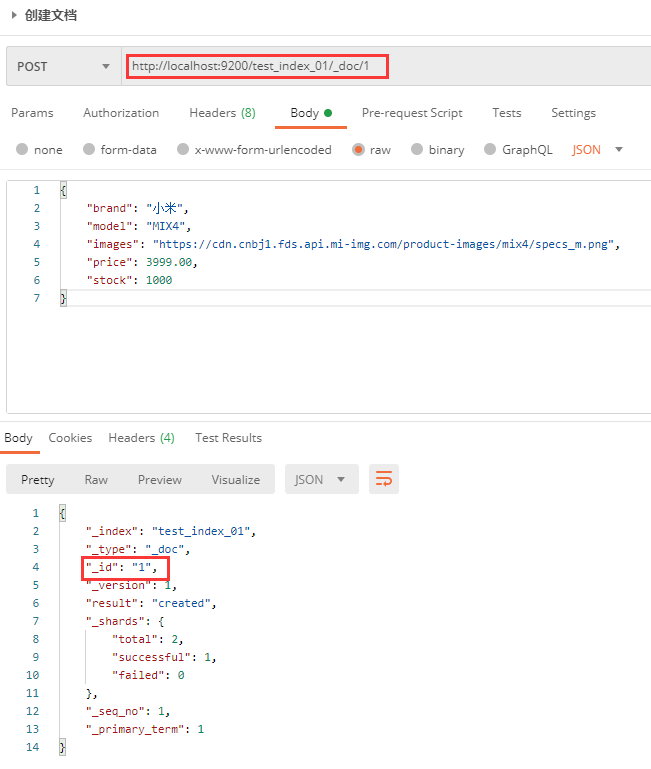
If the document is added with a clear and unique identification, the request method can also be PUT.
1.2.2.2 viewing documents
When viewing a document, you need to specify the unique ID of the document, which is similar to the primary key query of data in MySQL. Send GET request to ES server: http://localhost:9200/test_index_01/_doc/1:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-sfx5gb5l-1637994003592)( https://i.loli.net/2021/11/23/1gx87hI5sW4Lykm.png )]
The query is successful, and the server returns the following results:
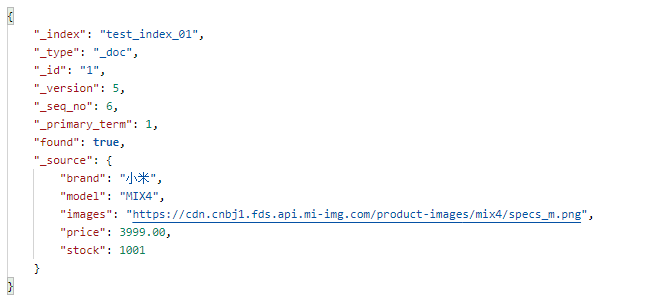
Return result Field Description:
{
"_index"[[index name]: "test_index_01",
"_type"[type-[document]: "_doc",
"_id"[[unique document ID]: "1",
"_version"[[version number]: 5,
"_seq_no"[[incremental serial number]: 6,
"_primary_term": 1,
"found"[[query results]: true, // true: indicates found, false: indicates not found
"_source"[[document source information]: {
"brand": "millet",
"model": "MIX4",
"images": "https://cdn.cnbj1.fds.api.mi-img.com/product-images/mix4/specs_m.png",
"price": 3999.00,
"stock": 1001
}
}
1.2.2.3 modifying documents
Modifying a document is the same as creating a document, and the request path is the same. If the request body changes, the original data content will be overwritten and updated. The content of the request body is:
{
"brand": "Huawei",
"model": "P50",
"images": "https://res.vmallres.com/pimages//product/6941487233519/78_78_C409A15DAE69B8B4E4A504FBDF5AB6FEB2C8F5868A7C84C4mp.png",
"price": 7488.00,
"stock": 100
}
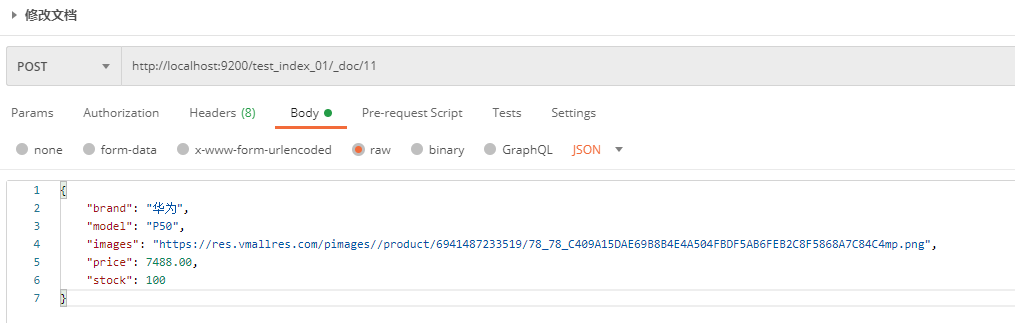
The modification is successful, and the server returns the following results:

Return result Field Description:
{
"_index"[[index]: "test_index_01",
"_type"[type-[document]: "_doc",
"_id"[[unique identification]: "1",
"_version"[[version]: 6,
"result"[Results]: "updated",
"_shards"[[slice]: {
"total"[Total number of slices]: 2,
"successful"[[slicing succeeded]: 1,
"failed"[[fragmentation failed]: 0
},
"_seq_no": 8,
"_primary_term": 1
}
1.2.2.4 update of some documents
The update API also supports the update of some documents.
Send POST request to ES server: http://localhost:9200/test_index_01/_update/1,_ Update means update. The request body is:
{
"doc":{
"stock": 123
}
}
After the modification is successful, the response result is returned:
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-xxwex7rg-1637994003596)( https://i.loli.net/2021/11/23/OexFtoATLyQJmp9.png )]
Note: if the field to be modified does not exist in the source data, it will be added to the source data.
1.2.2.5 deleting documents
When a document is deleted, it will not be removed from the disk immediately, but will be marked as deleted (logical deletion).
Send DELETE request to ES server: http://localhost:9200/test_index_01/_doc/11
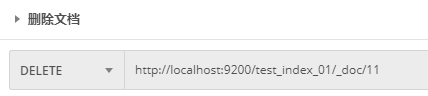
After the deletion is successful, the server returns the response result:

Return result Field Description:
{
"_index"[[index]: "test_index_01",
"_type"[type-[document]: "_doc",
"_id"[[unique identification]: "11",
"_version"[[version number]: 2,
"result"[Results]: "deleted", // Deleted: deleted successfully
"_shards"[[slice]: {
"total"[Total number of slices]: 2,
"successful"[[slicing succeeded]: 1,
"failed"[[fragmentation failed]: 0
},
"_seq_no": 11,
"_primary_term": 1
}
To view a document after deleting it:

Delete a deleted document or a document that does not exist:
1.2.2.6 delete documents according to conditions
In addition to deleting according to the unique identification of the document, you can also delete the document according to conditions.
Send POST request to ES server: http://localhost:9200/test_index_01/_delete_by_query, the request body is:
{
"query": {
"match": {
"price": 1999.00
}
}
}
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-ij26eg5h-1637994003600)( https://i.loli.net/2021/11/27/w2IXpFHQtTCZ3lh.png )]
After the deletion is successful, the server returns the response result:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-xydvdfkt-1637994003601)( https://i.loli.net/2021/11/23/TNimV93j7PRrDQE.png )]
Return result Field Description:
{
"took"[[time consuming]: 626,
"timed_out"[[request timeout]: false,
"total"[Total number of documents]: 1,
"deleted"[Number of deleted documents]: 1,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures": []
}
1.2.3 mapping operation
1.2.3.1 create mapping
Send PUT request to ES server: http://localhost:9200/test_index_01/_mapping. Request body:
{
"properties": {
"brand": {
"type": "text",
"index": true
},
"price": {
"type": "float",
"index": true
},
"stock": {
"type": "long",
"index": true
}
}
}
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-kkfismnm-1637994003602)( https://i.loli.net/2021/11/23/TfLKP38ZydM2Ont.png )]
The map is created successfully, and the response is returned:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-u7ivzs5w-1637994003602)( https://i.loli.net/2021/11/23/htVTumbRj6Q98zy.png )]
Create mapping. Parameter Description:
| Field name | describe |
|---|---|
| properties | Create mapping Attribute Collection |
| brand | Attribute name, which can be filled in arbitrarily. Multiple attributes can be specified |
| type | Types. ES supports rich data types. Common are: 1. String can be divided into two types: text, which indicates separable words, and keyword, which indicates non separable words. The data will be matched as a complete field. 2. Numerical value types are divided into two categories Basic data types: long, integer, short, byte, double, float, half_float High precision floating point number: scaled_float 3. Date date type 4. Array array type 5. Object object |
| index | Whether to index. The default value is true. The field will be indexed and can be searched. |
| store | Whether to store data independently. The default value is false. The original text is stored in the_ In the store, by default, the fields are not stored independently, but from_ Extracted from store |
| analyzer | Word splitter, e.g. ik_max_word |
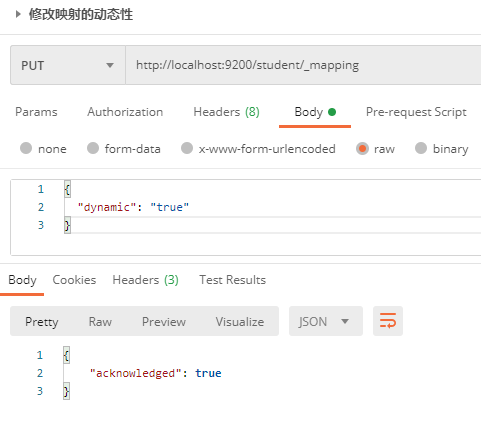
1.2.3.2 modify mapping
Once the mapping is created, the existing field types cannot be modified, but new fields can be added, and we can control the dynamic s of the mapping.
Send PUT request to ES server: http://localhost:9200/student/_mapping, the request body is as follows:
{
"dynamic": "true" // true: enable dynamic mode, false: enable static mode, strict: enable strict mode
}
1.2.3.3 view mapping
Send GET request to ES server: http://localhost:9200/test_index_01/_mapping
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (IMG dajviybj-1637994003604)( https://i.loli.net/2021/11/23/cytRxLEvY5s6CMJ.png )]
The server returned the response result:
{
"test_index_01": {
"mappings": {
"properties": {
"123": {
"type": "long"
},
"brand": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"images": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"model": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"price": {
"type": "float"
},
"qwewq": {
"type": "text"
},
"stock": {
"type": "long"
}
}
}
}
}
1.2.4 advanced query
Elasticsearch provides a complete query DSL based on JSON to define queries.
First create the index student, and then create the document:
// Create index
// POST http://localhost:9200/student
// create documents
// POST http://localhost:9200/student/_doc/10001
{
"name": "Huai Yong",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833125"
}
// POST http://localhost:9200/student/_doc/10002
{
"name": "Zhu Hao",
"sex": "male",
"age": 28,
"level": 6,
"phone": "15072833125"
}
// POST http://localhost:9200/student/_doc/10003
{
"name": "Vegetable head",
"sex": "male",
"age": 28,
"level": 5,
"phone": "178072833125"
}
// POST http://localhost:9200/student/_doc/10004
{
"name": "base",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833124"
}
// PSOT http://localhost:9200/student/_doc/10005
{
"name": "Zhang Ya",
"sex": "female",
"age": 26,
"level": 3,
"phone": "151833124"
}
1.2.4.1 query all documents
Send GET request to ES server: http://localhost:9200/student/_search. The request body is:
{
"query": {
"match_all":{}
}
}
// Query represents a query object, match_all means query all
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (IMG nwhtambv-1637994003605)( https://i.loli.net/2021/11/23/XfaYyOueg2EM64K.png )]
The response results returned by the server are as follows:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
......
]
}
}
Description of the result field returned by the server
hits
The most important part of the response is hits, which contains the total field to represent the total number of matched documents. The hits array also contains the first 10 matched data.
Each result in the hits array contains_ index , _ type and document_ id field, and the document source data is added to_ In the source field, this means that all documents will be available directly in the search results.
Each node has one_ Score field, which is the correlation score, which measures the matching degree between the document and the query. By default, the most relevant documents in the returned results are ranked first; This means that it is in accordance with_ Scores are in descending order.
max_score refers to all documents in the matching query_ The maximum value of score.
Total represents the total number of documents matching the search criteria, where value represents the value of the total hit count and relation represents the value rule (eq count is accurate and gte count is inaccurate).
took
The number of milliseconds the entire search request took.
_shards
_ The shards node indicates the number of fragments participating in the query (total field), in which how many are successful (successful field) and how many are failed (failed field). If both the primary partition and the replica partition fail due to some major faults, the data of this partition will not be able to respond to the search request. In this case, Elasticsearch will report the fragment failed, but will continue to return the results on the remaining fragments.
timed_out
time_ The out value indicates whether the query times out or not. Generally, search requests do not time out. If the response speed is more important than the complete result, you can define the timeout parameter as 10 or 10ms (10ms), or 1s (1s), then Elasticsearch will return the results collected before the request times out. Send request to ES server: http://localhost:9200/student/_search?timeout=1ms,? Timeout = 1ms means that the node data that successfully returns the result within 1ms is returned.
Note: setting timeout will not stop the query execution. It only returns the node time when the query is successfully executed, and then closes the connection. In the background, other shards may still execute queries, even though the results have been sent.
{
"took"[Query time in milliseconds]: 1,
"timed_out"[Timeout]: false,
"_shards"[[slice information]: {
"total"[Total number of slices]: 1,
"successful[Number of successful slices]": 1,
"skipped"[[number of segments ignored]: 0,
"failed"[Failed fragments]: 0
},
"hits"[[search criteria hit result information]: {
"total"[Total number of documents matching search criteria]: {
"value"[[value of total hit count]: 5,
"relation"[Counting rules]: "eq" // eq: accurate count gte: inaccurate count
},
"max_score"[Matching score]: 1.0,
"hits"[Search criteria hit result set]: [
{
"_index[[index name]": "student",
"_type"[[type]: "_doc",
"_id"[file id]: "10001",
"_score"[Correlation score]: 1.3862942,
"_source": {
"name": "Huai Yong",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833125"
}
}
]
}
}
1.2.4.2 matching query
For a match type query, the query criteria will be segmented and then queried. The relationship between multiple terms is or.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"query": {
"match": {
"name": "Huai Yong",
"operator": "and"
}
}
}
Server returned results:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10001",
"_score": 1.3862942,
"_source": {
"name": "Huai Yong",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833125"
}
}
]
}
}
1.2.4.3 multi field matching query
Match can only match one field. To match multiple fields, you have to use multi_match.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"query": {
"multi_match": {
"query": 24,
"fields":["age", "phone"]
}
}
}
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (IMG okbcwunq-1637994003066)( https://i.loli.net/2021/11/23/d8GR3pkfac5rxno.png )]
The server returned the response result:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10001",
"_score": 1.0,
"_source": {
"name": "Huai Yong",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833125"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "10004",
"_score": 1.0,
"_source": {
"name": "base",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833124"
}
}
]
}
}
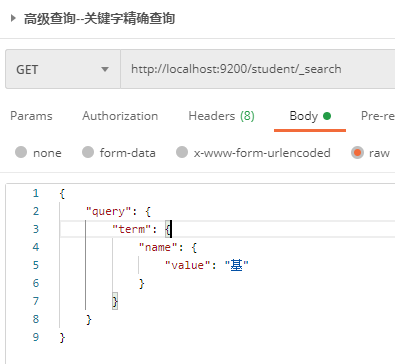
1.2.4.4 keyword accurate query
Use term query to accurately match keywords without word segmentation of query conditions.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"query": {
"term": {
"name.keyword": { // term query, the query criteria will not be word segmentation, and the data can be correctly matched only by adding. keyword
"value": "base"
}
}
}
}
The server returned the response result:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10004",
"_score": 1.3862942,
"_source": {
"name": "base",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833124"
}
}
]
}
}
1.2.4.5 multi keyword accurate query
terms has the same effect as term, but multiple keywords can be specified. The effect is similar to in query.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"query": {
"terms": {
"name.keyword": ["base", "Huai Yong"]
}
}
}
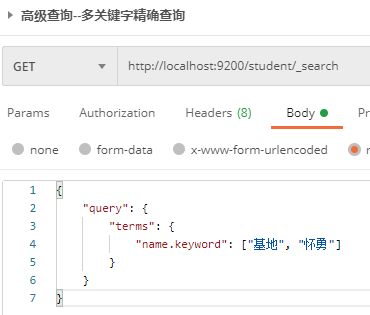
The server returned the response result:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10001",
"_score": 1.0,
"_source": {
"name": "Huai Yong",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833125"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "10004",
"_score": 1.0,
"_source": {
"name": "base",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833124"
}
}
]
}
}
1.2.4.6 specify query fields
By default, ES saves documents in the search results_ All fields of source are returned. Can pass_ Source specifies the field to return.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"_source": ["name", "sex"],
"query": {
"term": {
"name": {
"value": "base"
}
}
}
}
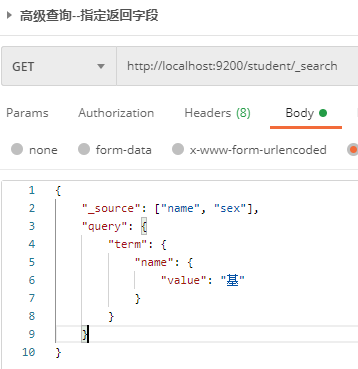
The server returned the response result:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10004",
"_score": 1.3862942,
"_source": {
"sex": "male",
"name": "base"
}
}
]
}
}
1.2.4.7 filter fields
You can also pass_ includes specifies the fields to display_ excludes specifies the fields you do not want to display.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"_source": {
"includes": ["name", "sex"]
},
"query": {
"term": {
"name": {
"value": "base"
}
}
}
}
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-vvnafwck-1637994003610)( https://i.loli.net/2021/11/23/7SxVWJHqlftijzg.png )]
The response result returned by the server is:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10004",
"_score": 1.3862942,
"_source": {
"sex": "male",
"name": "base"
}
}
]
}
}
1.2.4.8 combined query
bool is a Boolean logic that can be used to merge query results of multiple filter conditions. It contains the following operators:
1. must: multiple query criteria are completely matched, which is equivalent to and, accounting relevance score;
2,must_not: the opposite matching of multiple query criteria, which is equivalent to not, and the correlation score will not be calculated;
3. should: at least one query condition matches, equivalent to or, accounting relevance score;
4. filter: equivalent to must, but the correlation is not calculated.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"_source":["name", "sex", "age", "level", "phone"],
"query":{
"bool": {
"must": {
"term": {
"level": 3
}
},
"must_not": {
"term": {
"name": {
"value": "Conceive"
}
}
},
"should": {
"match": {
"sex": "male"
}
}
}
}
}
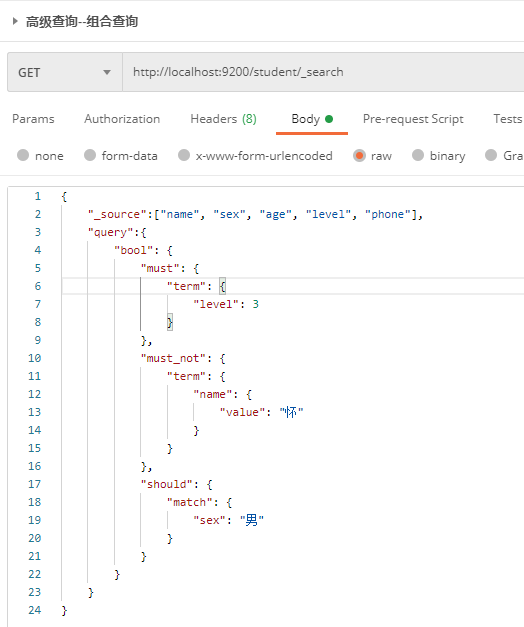
The result returned by the server is:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.287682,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10004",
"_score": 1.287682,
"_source": {
"level": 3,
"phone": "15071833124",
"sex": "male",
"name": "base",
"age": 24
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "10005",
"_score": 1.0,
"_source": {
"level": 3,
"phone": "151833124",
"sex": "female",
"name": "Zhang Ya",
"age": 26
}
}
]
}
}
1.2.4.9 range query
Through range, you can find the number or time within the specified interval. Range supports the following characters:
| Operator | explain |
|---|---|
| gt | Greater than > |
| gte | Greater than or equal to |
| lt | Less than< |
| lte | Less than or equal to |
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"_source": ["name", "age", "level", "sex"],
"query": {
"bool": {
"must": [
{
"range": {
"age": {
"gt": 25,
"lt": 30
}
}
},
{
"match": {
"sex": "female"
}
}
]
}
}
}
The result returned by the server is:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.3862944,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10005",
"_score": 2.3862944,
"_source": {
"level": 3,
"sex": "female",
"name": "Zhang Ya",
"age": 26
}
}
]
}
}
1.2.4.10 fuzzy query
Returns a document containing words similar to the search term.
Edit distance is the number of character changes required to convert one word to another. These changes include:
1. Change characters (Box - > Fox)
2. Delete characters (black - > lack)
3. Insert character (SiC - > sick)
4. Transpose two adjacent characters (act - > cat)
In order to find similar terms, a fuzzy query creates all possible variants or extensions of a set of search terms within a specified editing distance. The query then returns an exact match for each extension. Modify and edit the distance through fuzziness. Generally, the default value AUTO is used to generate the editing distance according to the length of the term.
Send GET request to ES server: http://127.0.0.1:9200/student/_search, the request body is:
{
"query": {
"fuzzy": {
"name": {
"value": "base",
"fuzziness": 0
}
}
}
}
The server returned the response result:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 0.72615415,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10004",
"_score": 0.72615415,
"_source": {
"name": "base",
"sex": "male",
"age": 24,
"level": 3,
"phone": "15071833124"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "10008",
"_score": 0.72615415,
"_source": {
"name": "foundation",
"sex": "male",
"age": 56,
"level": 7,
"phone": "15071833124"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "10006",
"_score": 0.60996956,
"_source": {
"name": "Base 1",
"sex": "male",
"age": 21,
"level": 4,
"phone": "15071833124"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "10007",
"_score": 0.60996956,
"_source": {
"name": "1 base",
"sex": "1 male",
"age": 25,
"level": 4,
"phone": "15071833124"
}
}
]
}
}
1.2.4.11 single field sorting
sort can be sorted according to different fields, and the sorting method is specified through order: desc descending and asc ascending.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"query": {
"bool": {
"must": {
"match": {
"name": "base"
}
},
"must_not": {
"range": {
"level": {
"gte": 1,
"lte": 3
}
}
}
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
The server returned the response result:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10008",
"_score": null,
"_source": {
"name": "foundation",
"sex": "male",
"age": 56,
"level": 7,
"phone": "15071833124"
},
"sort": [
56
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "10007",
"_score": null,
"_source": {
"name": "1 base",
"sex": "1 male",
"age": 25,
"level": 4,
"phone": "15071833124"
},
"sort": [
25
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "10006",
"_score": null,
"_source": {
"name": "Base 1",
"sex": "male",
"age": 21,
"level": 4,
"phone": "15071833124"
},
"sort": [
21
]
}
]
}
}
Observe the returned results and find:
1,_ Score and Max_ The correlation calculation is not performed for the score field because of the calculation_ Score is used to compare performance consumption and is usually mainly used for sorting. When sorting is not performed by correlation, it is not necessary to count its correlation. If you want to force the correlation calculation, you can set track_scores is true. For example, send a GET request to the ES server: http://localhost:9200/student/_search?track_scores=true;
2. Each returned result in hits array has a sort field, which contains values for sorting.
Note: sorting is based on the original content of the field, and the inverted index does not work. You can use fielddata and DOC in ES_ Values.
1.2.4.12 multi field sorting
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"query": {
"bool": {
"must_not": {
"match": {
"name": "Conceive"
}
},
"must": {
"range": {
"age": {
"gte": 56,
"lte": 56
}
}
}
}
},
"sort": [
{
"age": {
"order": "desc"
}
},
{
"level": {
"order": "asc"
}
}
]
}
The result set is sorted by the first sorting field. When the values used for sorting the first field are the same, then the second field is used to sort the documents with the same first sorting value, and so on.
1.2.4.13 highlight query
ES supports setting the label and style of the keyword part of the query content through highlight.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"query": {
"match": {
"name": "Zhu"
}
},
"highlight": {
"pre_tags"[[front label]: "<font color = 'red'>",
"post_tags"[[post label]: "</font>",
"fields"[[fields to highlight]: {
"name"[[field name]: {}
}
}
}
Server returned results:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.1382177,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10002",
"_score": 2.1382177,
"_source": {
"name": "Zhu Hao",
"sex": "male",
"age": 28,
"level": 6,
"phone": "15072833125"
},
"highlight": {
"name": [
"<font color = 'red'>Zhu</font>Vast"
]
}
}
]
}
}
1.2.4.15 paging query
ES supports paging queries. Set the size of the current page through size, and set the starting index of the current page from 0 by default. Calculation rules:
f
r
o
m
=
(
p
a
g
e
N
u
m
−
1
)
∗
p
a
g
e
S
i
z
e
from = (pageNum - 1) * pageSize
from=(pageNum−1)∗pageSize
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"query": {
"match": {
"name": "base"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 0,
"size": 1
}
Server returned results:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "10006",
"_score": null,
"_source": {
"name": "Base 1",
"sex": "male",
"age": 21,
"level": 4,
"phone": "15071833124"
},
"sort": [
21
]
}
]
}
}
1.2.4.16 aggregate query
ES can perform statistical analysis on documents through aggregation, similar to group by, max, avg, etc. in relational databases.
1. max for a field
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"query": {
"match": {
"name": "base"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
],
"size": 0, // Restrict not returning source data
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
Server returned results:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"max_age": {
"value": 56.0
}
}
}
**2. Take the minimum value min for a field**
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"aggs": {
"min_level": {
"min": {
"field": "level"
}
}
},
"size": 0
}
The result returned by the server is:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 9,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"min_levels": {
"value": null
}
}
}
3. Sum a field
Send GET request to ES server: http://localhost:9200/student/_search, the request body is:
{
"aggs": {
"sum_age": {
"sum": {
"field": "age"
}
}
},
"size": 0
}
The result returned by the server is:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 9,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"sum_age": {
"value": 288.0
}
}
}
4. Average a field
avg is used for the average value, and the others are consistent with max.
5. The total number is obtained after de duplication of the value of a field
The request body is:
{
"aggs": {
"distinct_age": {
"cardinality": {
"field": "age"
}
}
},
"size": 0
}
6. State aggregation
stats aggregation returns count, max, min, avg and sum for a field at one time.
The request body is:
{
"aggs": {
"stats_age": {
"stats": {
"field": "age"
}
}
},
"size": 0
}
The result returned by the server is:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 9,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"stats_age": {
"count": 9,
"min": 21.0,
"max": 56.0,
"avg": 32.0,
"sum": 288.0
}
}
}
7. Barrel polymerization
Bucket aggregation is equivalent to the group by clause in sql.
1. terms aggregation and grouping statistics
The request body is:
{
"aggs": {
"age_groupby": {
"terms": {
"field": "level"
}
}
},
"size": 0
}
The response result returned by the server is:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 9,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"age_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 3,
"doc_count": 3
},
{
"key": 4,
"doc_count": 2
},
{
"key": 5,
"doc_count": 1
},
{
"key": 6,
"doc_count": 1
},
{
"key": 7,
"doc_count": 1
},
{
"key": 8,
"doc_count": 1
}
]
}
}
}
2. Aggregate under terms group
The request body is:
{
"aggs": {
"age_groupby": {
"terms": {
"field": "age"
},
"aggs": {
"sum_age": {
"sum":{
"field": "age"
}
}
}
}
},
"size": 0
}
The result returned by the server is:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 9,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"age_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 24,
"doc_count": 2,
"sum_age": {
"value": 48.0
}
},
{
"key": 28,
"doc_count": 2,
"sum_age": {
"value": 56.0
}
},
{
"key": 56,
"doc_count": 2,
"sum_age": {
"value": 112.0
}
},
{
"key": 21,
"doc_count": 1,
"sum_age": {
"value": 21.0
}
},
{
"key": 25,
"doc_count": 1,
"sum_age": {
"value": 25.0
}
},
{
"key": 26,
"doc_count": 1,
"sum_age": {
"value": 26.0
}
}
]
}
}
}
1.2.4.17 filter query
Using filter, the correlation score will not be calculated, and the related queries will be cached, which can improve the server response performance.
Send GET request to ES server: http://localhost:9200/student/_search, the request body is as follows:
{
"query": {
"constant_score": {
"filter": { // filter
"term": {
"name.keyword": "base"
}
}
}
}
}
1.2.4.18 validation query
The validate API can verify whether a query statement is legal. Send GET request to ES server: http://localhost:9200/student/_validate/query?explain. The request body is as follows:
{
"query": {
"multi_match": {
"query": 24,
"fields":["age","phone"]
}
}
}
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-dsisuswb-1637994003612)( https://i.loli.net/2021/11/23/YiEt3UMDCXv674F.png )]
The server returned a response:
{
"_shards"[[slice information]: {
"total": 1,
"successful": 1,
"failed": 0
},
"valid"[[verification results]: true,
"explanations"[[index description]: [
{
"index": "student",
"valid": true,
"explanation": "(phone:24 | age:[24 TO 24])"
}
]
}
1.3 ES native API operation
1.3.1 create project
Create a project in IDEA, modify pom file, and add ES related dependencies:
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch Client for -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch Dependency 2.x of log4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<!-- junit unit testing -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
</dependencies>
1.3.2 connecting to ES server
public class ConnectionTest {
/**
* ES client
*/
private static RestHighLevelClient client;
/**
* The client establishes a connection with the server
*/
@Before
public void connect(){
client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
}
/**
* Close the connection between the client and the server
*/
@After
public void close(){
if(Objects.nonNull(client)){
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
Note: 9200 is the Web communication interface of ES.
1.3.3 index operation
1.3.3.1 create index
/**
* Create index
*/
@Test
public void createIndex(){
// Create index -- request object
CreateIndexRequest request = new CreateIndexRequest("user1");
try {
// Send request
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
// The server returned a response
boolean acknowledged = response.isAcknowledged();
System.out.println("Create index, server response:" + acknowledged);
} catch (IOException e) {
e.printStackTrace();
}
}
1.3.3.2 view index
@Test
public void getIndex() throws IOException {
// Query index -- request object
GetIndexRequest request = new GetIndexRequest("user");
// Server response
GetIndexResponse response = client.indices().get(request, RequestOptions.DEFAULT);
System.out.println(response.getSettings());
}
Server returned results:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-xcx9uvtr-1637994003613)( https://i.loli.net/2021/11/23/zeFfJqoaI7GbC6T.png )]
1.3.3.3 delete index
/**
* Delete index
*/
@Test
public void deleteIndex() throws IOException {
// Delete index -- request object
DeleteIndexRequest request = new DeleteIndexRequest("user1");
// The server returned a response
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
1.3.4 document operation
Create the data model first:
package com.jidi.elastic.search.test;
import lombok.Data;
/**
* @Description User entity
* @Author jidi
* @Email jidi_jidi@163.com
* @Date 2021/9/6
*/
@Data
public class UserDto {
/**
* Primary key id
*/
private Integer id;
/**
* name
*/
private String name;
/**
* nickname
*/
private String nickName;
/**
* Age
*/
private Integer age;
/**
* Gender 1: male 2: Female
*/
private byte sex;
/**
* level
*/
private Integer level;
/**
* phone number
*/
private String phone;
@Override
public String toString() {
return "UserDto{" +
"id=" + id +
", name='" + name + '\'' +
", nickName='" + nickName + '\'' +
", age=" + age +
", sex=" + sex +
", level=" + level +
", phone='" + phone + '\'' +
'}';
}
}
1.3.4.1 create document
/**
* Create a document (if the document exists, the whole document will be modified)
*/
@Test
public void createDocument() throws IOException {
// Create document -- request object
IndexRequest request = new IndexRequest();
// Set index and unique identification
request.index("user").id("10001");
// Create data object
UserDto user = new UserDto();
user.setId(10001);
user.setName("base");
user.setAge(24);
user.setLevel(3);
user.setSex((byte)1);
user.setNickName("Chicken brother");
user.setPhone("15071833124");
// Add document data
String userJson = new ObjectMapper().writeValueAsString(user);
request.source(userJson, XContentType.JSON);
// The server returned a response
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// Print result information
System.out.println("_index: " + response.getIndex());
System.out.println("_id: " + response.getId());
System.out.println("result: " + response.getResult());
System.out.println("_version: " + response.getVersion());
System.out.println("_seqNo: " + response.getSeqNo());
System.out.println("_shards: " + response.getShardInfo());
}
Execution results:
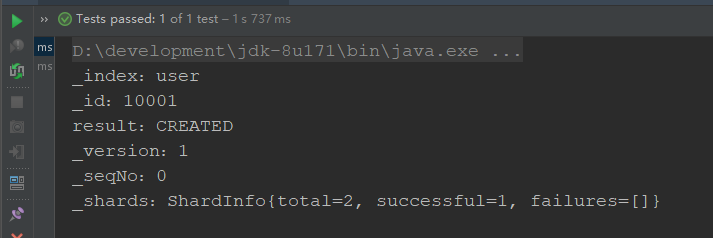
####1.3.4.3 document modification
/**
* Modify document
*/
@Test
public void updateDocument() throws IOException {
// Modify document -- request object
UpdateRequest request = new UpdateRequest();
// Configuration modification parameters
request.index("user").id("10001");
// Set request body
request.doc(XContentType.JSON, "sex", 1, "age", 24, "phone", "15071833124");
// Send request and get response
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println("_index: " + response.getIndex());
System.out.println("_id: " + response.getId());
System.out.println("result: " + response.getResult());
}
Execution results:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-87susfug-1637994003614)( https://i.loli.net/2021/11/27/hpd3t8myvCHuEbN.png )]
1.3.4.4 query documents
/**
* consult your documentation
*/
@Test
public void searchDocument() throws IOException {
// Create request object
GetRequest request = new GetRequest().id("10001").index("user");
// Return response body
GetResponse response = client.get(request, RequestOptions.DEFAULT);
System.out.println(response.getIndex());
System.out.println(response.getType());
System.out.println(response.getId());
System.out.println(response.getSourceAsString());
}
Execution results:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-gyg5n1hq-1637994003615)( https://i.loli.net/2021/11/23/OFDLZf3uJWkc1lA.png )]
1.3.4.5 delete document
/**
* remove document
*/
@Test
public void deleteDocument() throws IOException {
// Create request object
DeleteRequest request = new DeleteRequest();
// Build request body
request.index("user");
request.id("10001");
// Send request and return response
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println(response.toString());
}
Execution results:

1.3.4.6 batch creation of documents
/**
* Batch create documents
*/
@Test
public void batchCreateDocument() throws IOException {
// Create request object
BulkRequest request = new BulkRequest();
request.add(
new IndexRequest()
.index("user")
.id("10001")
.source(
XContentType.JSON,
"id", 10001, "name", "base", "nickName", "Chicken brother", "age", 24, "sex", 1, "level", 3, "phone", "15071833124"));
request.add(
new IndexRequest()
.index("user")
.id("10002")
.source(
XContentType.JSON,
"id", 10002, "name", "Huai Jing", "nickName", "Brother Yongzi", "age", 23, "sex", 1, "level", 3, "phone", "15071831234"));
// Send request and return response
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
System.out.println(responses.getTook());
System.out.println(responses.getItems());
}
The execution results are:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-v7kjtrm7-1637994003617)( https://i.loli.net/2021/11/23/WG6yu8LcjkNnigx.png )]
1.3.4.7 deleting documents in batch
/**
* Batch delete documents
*/
@Test
public void batchDeleteDocument() throws IOException {
// Create request object
BulkRequest request = new BulkRequest();
request.add(new DeleteRequest("user").id("10001"));
request.add(new DeleteRequest("user").id("10002"));
// Send request and return response
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
System.out.println(responses.getTook());
System.out.println(responses.getItems());
}
The execution results are:

1.3.5 advanced query
1.3.5.1 query all document data
/**
* Query all document data
*/
@Test
public void getAllDocument() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build query request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// Query all data
sourceBuilder.query(QueryBuilders.matchAllQuery());
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit: hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:

1.3.5.2 matching query
/**
* Single field matching query
*/
@Test
public void getDocumentByMatch() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build query request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// Single field matching data
sourceBuilder.query(new MatchQueryBuilder("name", "base"));
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit: hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-xh0b4cqf-1637994003619)( https://i.loli.net/2021/11/23/xWRfHMNeCdm84U1.png )]
1.3.5.3 multi field matching query
/**
* Single field matching query
*/
@Test
public void getDocumentByMatchMultiField() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build query request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// Single field matching data
sourceBuilder.query(new MultiMatchQueryBuilder("base", "name", "nickName"));
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit: hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:

1.3.5.4 keyword accurate query
/**
* Keyword exact query
*/
@Test
public void getDocumentByKeWorld() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(new TermQueryBuilder("name", "base"));
sourceBuilder.query(new TermQueryBuilder("age", "26"));
sourceBuilder.query(new TermQueryBuilder("level", "7"));
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-svnmidkt-1637994003621)( https://i.loli.net/2021/11/27/LufN5edpD4SF186.png )]
1.3.5.5 multi keyword accurate query
/**
* Multi keyword exact query
*/
@Test
public void getDocumentByMultiKeyWorld() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Create request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(new TermsQueryBuilder("name", "2", "123"));
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-c5hp84aa-1637994003622)( https://i.loli.net/2021/11/27/TvruZzpiXmh2ctP.png )]
1.3.5.6 filter fields
/**
* Filter field
*/
@Test
public void getDocumentByFetchField() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(new MatchAllQueryBuilder());
// Specify query fields
sourceBuilder.fetchSource(new String[]{"id", "name"}, null);
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:
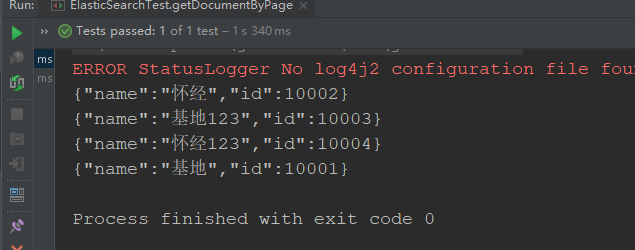
1.3.5.7 combined query
/**
* Combined query
*/
@Test
public void getDocumentByBool() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// Combined query
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
// Must contain
boolQueryBuilder.must(new MatchQueryBuilder("name", "base"));
boolQueryBuilder.must(new TermQueryBuilder("nickName", "brother"));
// Must not contain
boolQueryBuilder.mustNot(new TermQueryBuilder("level", 7));
// May contain
boolQueryBuilder.should(new MatchQueryBuilder("sex", 1));
sourceBuilder.query(boolQueryBuilder);
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:

1.3.5.8 range query
/**
* Range query
*/
@Test
public void getDocumentByRange() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// Range query
RangeQueryBuilder rangeQueryBuilder = new RangeQueryBuilder("age");
// Greater than or equal to
rangeQueryBuilder.gte(24);
// Less than or equal to
rangeQueryBuilder.lte(35);
sourceBuilder.query(rangeQueryBuilder);
sourceBuilder.from(0);
sourceBuilder.size(10);
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-m03uitwn-1637994003624)( https://i.loli.net/2021/11/23/ZYgA9HMo1LxDtPU.png )]
1.3.5.9 fuzzy query
/**
* Fuzzy query
*/
@Test
public void getDocumentByLike() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// Fuzzy query
sourceBuilder.query(new FuzzyQueryBuilder("name", "base").fuzziness(Fuzziness.AUTO));
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:

1.3.5.10 Sorting Query
/**
* Sort query
*/
@Test
public void getDocumentByOrder() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(new MatchAllQueryBuilder());
// Ascending order
sourceBuilder.sort("age", SortOrder.ASC);
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-eql4iilx-1637994003626)( https://i.loli.net/2021/11/23/PFRjJzZray65Ivc.png )]
1.3.5.11 highlight query
/**
* Highlight query
*/
@Test
public void getDocumentByHighLight() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(new TermQueryBuilder("name", "base"));
// Highlight query
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("name");
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
sourceBuilder.highlighter(highlightBuilder);
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
// Get highlighted results
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
System.out.println(highlightFields);
}
}
Execution results:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-zyr7ooxw-1637994003627)( https://i.loli.net/2021/11/23/hfYNH5g7iIktQsc.png )]
1.3.5.12 paging query
/**
* Paging query
*/
@Test
public void getDocumentByPage() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(new MatchAllQueryBuilder());
// paging
sourceBuilder.from(0);
sourceBuilder.size(2);
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
Execution results:

1.3.5.13 aggregate query
/**
* Aggregate query
*/
@Test
public void getDocumentByAggregation() throws IOException {
// Create request object
SearchRequest request = new SearchRequest();
request.indices("user");
// Build request body
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// Oldest
sourceBuilder.aggregation(AggregationBuilders.max("maxAge").field("age"));
sourceBuilder.size(0);
request.source(sourceBuilder);
// Send request and return response
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(new ObjectMapper().writeValueAsString(response.getAggregations().getAsMap().values()));
}
Execution results:

1.4 Elasticsearch environment
1.4.1 interpretation of terms
1.4.1.1 single machine & cluster
When a single Elasticsearch server provides services, it often has the maximum load capacity. If it exceeds this threshold, the server performance will be greatly reduced or even unavailable. Therefore, in the production environment, it generally runs in the specified server cluster. In addition to load capacity, single point servers have other problems:
1. The storage capacity of a single machine is limited;
2. Single server is prone to single point of failure and cannot achieve high availability;
3. The concurrent processing capacity of a single server is limited.
When configuring a server cluster, there is no limit on the number of nodes in the cluster. If there are more than or equal to 2 nodes, it can be regarded as a cluster. Generally, considering high performance and high availability, the number of nodes in the cluster is more than 3.
1.4.1.2 Cluster
A cluster is organized by multiple server nodes to jointly hold the whole data and provide indexing and search functions together. An elasticsearch cluster has a unique name ID, which is elasticsearch by default. Nodes can only join a cluster by specifying its name.
In Elasticsearch cluster, you can monitor and count a lot of information, but only one is the most important: cluster health. Cluster health has three states:
1. green: all master slices and replica slices are available;
2. yellow: all primary partitions are available, but not all replica partitions are available;
3. red: not all primary partitions are available.
1.4.1.3 Node
A node is an Elasticsearch instance, and a cluster is composed of one or more nodes with the same cluster.name. They work together to share data and load. When a new node is added or a node is deleted, the cluster will sense and balance the data. As a part of the cluster, it stores data and participates in the indexing and search functions of the cluster.
A node is also identified by a name. By default, this name is the name of a random Marvel comic character. This name will be given to the node at startup. A node can join a specified cluster by configuring the cluster name. By default, each node is scheduled to join a cluster called elastic search.
Each node saves the status of the cluster, but only the Master node can modify the status information of the cluster (all node information, all indexes and related Mapping and Setting information, fragment routing information). The Master node does not participate in document level change or search, which means that the Master node will not become the bottleneck of the cluster when the traffic increases. Any node can be the Master node.
After each node is started, it is a Master eligible node by default. A Master eligible node can participate in the selected main process and become a Master node, which can be prohibited by setting node.master:false.
Node classification
Nodes can be divided into:
1. Master Node: the Master Node, which is responsible for modifying the cluster status information;
2. Data Node: a Data Node, which is responsible for saving fragment data;
3. Ingrest node: preprocessing node, which is responsible for preprocessing files before actually indexing documents;
4. Coordinating Node: the Coordinating Node is responsible for receiving the client's request, distributing the request to the appropriate node, and finally collecting the results and returning them to the client. Each node is responsible for coordinating nodes by default.
Other node types
1,Hot & Warm Node: Hot and cold node , data nodes with different hardware configurations are used to implement the hot & warm architecture and reduce the cost of cluster deployment;
2. Machine learning node: the node responsible for running machine learning tasks;
3. Triple node: the triple node (Deprecated) can be connected to different elasticsearch clusters and can be treated as a separate cluster.
1.4.1.4 Node configuration
Generally, a node in the development environment can assume multiple roles; In a production environment, in order to improve performance, nodes should be set to a single role.
| Node type | configuration parameter | Default value |
|---|---|---|
| master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| coordinating only | nothing | Each node is a coordination node by default. |
| machine learning | node.ml | true (you need to enable x-pack, which includes security, alarm, monitoring, reporting and graphics functions in an easy to install package) |
1.4.2 Windows cluster deployment
1. Create the elasticsearch-7.8.0-cluster folder and internally copy three elasticsearch services
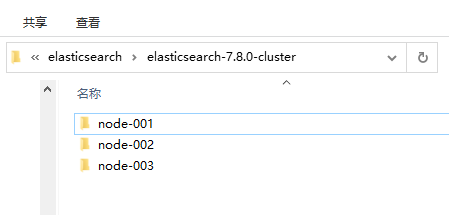
2. Modify the configuration information of each node (config/elasticsearch.yml)
node-001 node configuration:
# ---------------------------------- Cluster ----------------------------------- # Cluster name cluster.name: my-application # ------------------------------------ Node ------------------------------------ # Node name node.name: node-001 node.master: true node.data: true # ---------------------------------- Network ----------------------------------- # ip address network.host: localhost # # Set a custom port for HTTP: # http port http.port: 9201 # tcp listening port transport.tcp.port: 9301 # Cross domain configuration http.cors.enabled: true http.cors.allow-origin: "*" # --------------------------------- Discovery ---------------------------------- # The address of the candidate master node can be selected as the master node after the service is started discovery.seed_hosts: ["localhost:9301", "localhost:9302", "localhost:9303"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # List of nodes in the cluster that can be selected as the master node cluster.initial_master_nodes: ["node-001", "node-002", "node-003"]
node-002 node configuration:
# ---------------------------------- Cluster ----------------------------------- # Cluster name cluster.name: my-application # ------------------------------------ Node ------------------------------------ # Node name node.name: node-002 node.master: true node.data: true # ---------------------------------- Network ----------------------------------- # ip address network.host: localhost # # Set a custom port for HTTP: # http port http.port: 9202 # tcp listening port transport.tcp.port: 9302 # Cross domain configuration http.cors.enabled: true http.cors.allow-origin: "*" # --------------------------------- Discovery ---------------------------------- # The address of the candidate master node can be selected as the master node after the service is started discovery.seed_hosts: ["localhost:9301", "localhost:9302", "localhost:9303"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # List of nodes in the cluster that can be selected as the master node cluster.initial_master_nodes: ["node-001", "node-002", "node-003"]
node-003 node configuration:
# ---------------------------------- Cluster ----------------------------------- # Cluster name cluster.name: my-application # ------------------------------------ Node ------------------------------------ # Node name node.name: node-003 node.master: true node.data: true # ---------------------------------- Network ----------------------------------- # ip address network.host: localhost # # Set a custom port for HTTP: # http port http.port: 9203 # tcp listening port transport.tcp.port: 9303 # Cross domain configuration http.cors.enabled: true http.cors.allow-origin: "*" # --------------------------------- Discovery ---------------------------------- # The address of the candidate master node can be selected as the master node after the service is started discovery.seed_hosts: ["localhost:9301", "localhost:9302", "localhost:9303"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # List of nodes in the cluster that can be selected as the master node cluster.initial_master_nodes: ["node-001", "node-002", "node-003"]
3. Start the cluster (you need to delete all data under the data directory first), enter the bin directory respectively, and click the elasticsearch.bat script
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-rzrh5grj-1637994003631)( https://i.loli.net/2021/11/23/37eSQ4LitbVKxYE.png )]
4. Test the cluster and send GET requests to the nodes respectively: http://localhost:9201/_cluster/health, 9201 is the port of the access node
2 Elasticsearch advanced
2.1 core concepts
2.1.1 Index
An index is a collection of documents with similar characteristics. In fact, an index is just a "logical namespace" used to point to one or more shards. An index is identified by a name (which must be all lowercase letters), and we should use this name when we want to index, search, update and delete the documents in this index.
In a cluster, any number of indexes can be defined, and the data that can be searched must be indexed.
The essence of elastic search index: everything is designed to improve the performance of search.
2.1.2 Type
One or more types can be defined in an index. One type is a logical classification / partition of the index, and its semantics are completely user-defined. Typically, a type is defined for a document that has a common set of fields. Different versions and types change differently:
| elasticsearch version | Type support |
|---|---|
| 5.x | Support multiple type s |
| 6.x | There can only be one type |
| 7.x | By default, the self setting index type is no longer supported (the default type is _doc) |
2.1.3 Document
Most entities or objects in the program can be serialized into JSON objects containing key value pairs. The key is the name of a field or property. The value can be a string, number, boolean type, another object, value array or other special types, such as a string representing a date or an object representing a geographical location.
{
"name": "John Smith",
"age": 42,
"confirmed": true,
"join_date": "2014-06-01",
"home": {
"lat": 51.5,
"lon": 0.1
},
"accounts": [
{
"type": "facebook",
"id": "johnsmith"
},
{
"type": "twitter",
"id": "johnsmith"
}
]
}
Generally, it can be considered that an object and a document are equivalent and interlinked. However, they are different: an object is a JSON structure; Objects may also contain other objects.
In elastic search, the term document has a special meaning. It specifically refers to JSON data (identified by unique ID and stored in Elasticsearch) serialized from the top-level structure or root object.
A document does not have only data. It also contains metadata -- information about the document. The three required metadata nodes are:
1,_ index: where documents are stored;
2,_ type: the class of the object represented by the document;
3,_ id: the unique identification of the document. It's just a string, which is associated with_ index and_ When type is combined, a document can be uniquely identified in elastic search.
2.1.4 Field
It is equivalent to the field of the data table, which classifies and identifies the document data according to different attributes. If there is an upper limit on the number of fields in an index, an error will be reported if the upper limit is exceeded.
2.1.5 Mapping
mapping (mapping) mechanism is used to confirm the field type and match each field to a certain data type (string, number, Boolean, date, etc.).
Mapping is some restrictions on the way and rules of processing data, such as the data type, default value, analyzer, whether to be indexed, etc. These can be set in the mapping. A mapping defines the field type, the data type of each field, and how the field is processed by Elasticsearch. Mappings are also used to set metadata associated to types.
mapping can be divided into the following three types (specifically controlled by the dynamic attribute):
1. Dynamic mapping (dynamic: true): it can infer the data type of the field according to the document information, and then dynamically add new fields;
2. Static mapping (dynamic: false): Based on the original mapping, when there is a new field, it will not actively add a new mapping relationship, but only appear in the query as the query result;
3. Strict mapping (dynamic: strict): if a new field is encountered, an exception will be thrown.
Change mapping
The modification of field types in mapping can be divided into two cases:
1. Newly added field: different processing methods are adopted according to different mapping types;
2. Existing field: once the existing data is written, it is no longer supported to modify the field definition, because the inverted index implemented by Lucene cannot be modified once it is generated. If you want to change the field type, you must Reindex and rebuild the index.
2.1.6 Index Template
Index template , is a reuse mechanism provided by ES. When you create an index, you can automatically match the template to complete the basic part of the index.
Here is a typical example:
// PUT http://localhost:9200/_template/test_template
{
"order": 1 ,
"index_patterns" : "tes*",
"settings" : {
"index": {
"number_of_shards" : 2,
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and"]
},
"|_to_or": {
"type": "mapping",
"mappings": ["|=> or"]
},
"replace_dot": {
"pattern": "\\.",
"type": "pattern_replace",
"replacement": " "
},
"html": {
"type": "html_strip"
}
},
"filter": {
"my_stop": {
"type": "stop",
"stopwords": ["of"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["&_to_and", "|_to_or", "replace_dot"],
"tokenizer": "ik_max_word",
"filter": ["lowercase", "my_stop"]
}
}
}
}
},
"mappings" : {
"date_detection": true,
"numeric_detection": true,
"dynamic_templates": [
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"fielddata": {
"fromat": "disabled"
},
"analyzer": "my_analyzer",
"index": "analyzed",
"omit_norms": true,
"type": "string",
"fields": {
"raw": {
"ignore_above": 256,
"index": "not_analyzed",
"type": "string",
"doc_values": true
}
}
}
}
}
],
"properties": {
"money": {
"type": "double",
"doc_values": true
}
}
},
"aliases": {}
}
At first glance, the above example is very complex. In terms of splitting, it mainly includes the following parts:
{
"order": 0, // Template priority
"index_patterns": [], // Name method of template matching
"settings": {...}, // Index settings
"mappings": {...}, // Index mapping
"aliases": {...} // Index alias
}
2.1.6.1 template priority
The priority of the template is defined by the order field in the template. The higher the number, the higher the priority. The template with high priority can overwrite the template with low priority.
Here is a template that matches an index beginning with te:
// PUT http://localhost:9200/_template/test_template_1
{
"order": 0 ,
"index_patterns" : "te*",
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"_source" : { "enabled" : false }
}
}
Index templates are merged in order. If you want to modify some index settings, you can add a template with higher priority:
// PUT http://localhost:9200/_template/test_template_2
{
"order": 1 ,
"index_patterns" : "tes*",
"settings" : {
"number_of_shards" : 2
},
"mappings" : {
"date_detection": true,
"numeric_detection": true
}
}
2.1.6.2 template matching
Index in index template_ The patterns field defines the index applied by the index template. For example, "index_patterns": "teS *" means that when an index is created, all indexes starting with tes will automatically match the index template. Use this template to make corresponding settings and add fields
Based on the two templates created above, create an index named test1, and it will automatically match to test_template_1 and test_template_2. Two pre-defined index templates:
// Create index test1
// PUT http://localhost:9200/test1
// View index test1
// GET http://localhost:9200/test1
{
"test1": {
"aliases": {},
"mappings": {
"_source": {
"enabled": false
},
"date_detection": true,
"numeric_detection": true
},
"settings": {
"index": {
"creation_date": "1633230450431",
"number_of_shards": "2",
"number_of_replicas": "1",
"uuid": "Ucg4fPEaTv6pPtS6-twK6g",
"version": {
"created": "7080099"
},
"provided_name": "test1"
}
}
}
}
2.1.6.3 template setting
The setting part of the index template generally defines the setting information of the index, such as main slice, copy slice, refresh time, user-defined analyzer, etc. The common structure of setting part is as follows:
"settings": {
"index": {
"analysis": {...}, // Custom analyzer
"number_of_shards": "32", // Number of main segments
"number_of_replicas": "1", // Number of copy slices of master slice
"refresh_interval": "5s" // Refresh time
}
}
In the setting of setting, the focus is to customize the settings of the analyzer. The parser is a combination of three sequentially executed components. They are character filter, word splitter and tag filter. The following is the structure of a custom analyzer:
"settings": {
"index": {
"analysis": {
"char_filter": { ... }, // User defined character filter
"tokenizer": { ... }, // User defined word splitter
"filter": { ... }, // User defined tag filter
"analyzer": { ... } // User defined analyzer
},
...
}
}
1. Character filter
At present, there are three types of character filters: mapping char filter, HTML Strip char filter and Pattern Replace char filter. The HTML filter removes all HTML tags.
Define a mapping character filter as follows, and replace & with and:
"char_filter": {
"&_to_and": {
"type": "mapping", // The filter type is character mapping filter
"mappings": [ "&=> and"] // Character to replace
}
}
A format replacement filter is defined as follows. Replace the dot with a space:
"char_filter": {
"replace_dot": {
"pattern": "\\.", // Match replaced characters
"type": "pattern_replace", // The filter type is format replacement filter
"replacement": " " // Replaced character
}
}
2. Word splitter
Common word splitters include standard, keyword, whitespace, pattern, etc. For Chinese word segmentation, you can use IK word segmentation.
Here is an example of using the IK word breaker:
"tokenizer": "ik_max_word" // Using the IK word breaker
3. Mark filter
Common tag filters are lowercase and stop. The lowercase tag filter converts words to lowercase, and the stop tag filter removes some user-defined stop words or stop words defined in the language.
The common structure of stop tag filter is as follows:
"filter": {
"my_stopwords": {
"type": "stop", // The type is stop filter
"stopwords": [ "the", "a" ] // Characters to filter
}
}
4. Analyzer combination
The user-defined analyzer is composed of custom character filter, word splitter and tag filter in order.
"analyzer": {
"my_analyzer": { // Custom analyzer name
"type": "custom", // The type is custom
"char_filter": ["&_to_and", "|_to_or", "replace_dot"], // Character filter
"tokenizer": "ik_max_word", // Tokenizer
"filter": ["lowercase", "my_stop"] // Tag filter
}
}
Each part of the custom analyzer is fully represented as follows:
"settings" : {
"index": {
"number_of_shards" : 2,
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and"]
},
"|_to_or": {
"type": "mapping",
"mappings": ["|=> or"]
},
"replace_dot": {
"pattern": "\\.",
"type": "pattern_replace",
"replacement": " "
},
"html": {
"type": "html_strip"
}
},
"filter": {
"my_stop": {
"type": "stop",
"stopwords": ["of"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["&_to_and", "|_to_or", "replace_dot"],
"tokenizer": "ik_max_word",
"filter": ["lowercase", "my_stop"]
}
}
}
}
}
2.1.6.4 field mapping
In the index template, the common structure corresponding to the mapping field is:
"mappings": {
"dynamic_templates": [ ... ], // Dynamic mapping section for undefined my_ Field under type
"properties": { ... } // Mapping of custom fields
}
1. Dynamic mapping
Dynamic mapping_ The templates field corresponds to an array, and the elements in the array are the mapping templates of each field. The mapping template for each field has a name describing the purpose of the template, a mapping field indicating how the mapping is used, and at least one parameter (such as match) to define which field the template applies to.
dynamic_ The field template structure corresponding to the templates field is as follows:
{
"string_fields": { // The name of the field mapping template is generally the naming method of "type _fields"
"match": "*", // The matching field names are all
"match_mapping_type": "string", // Limit the matching field type, which can only be string type
"mapping": { ... } // How fields are handled
}
Here is an example:
"mappings": {
"dynamic_templates": [
{
"string_fields": { // The name of the field mapping template is generally the naming method of "type _fields"
"match": "*", // The matching field names are all
"match_mapping_type": "string", // Limit the matching field type, which can only be string type
"mapping": {
"fielddata": { "format": "disabled" }, // fielddata is not available. For analysis fields, its default value is available
"analyzer": "only_words_analyzer", // Field. The default value is standard analyzer
"index": "true", // The index method is defined as index, and the default value is true
"omit_norms": true, // omit_ Normals is true, which means that considering the weighting of the field, the default value of the field can be analyzed as false
"type": "string", // The field type is limited to string
"fields": { // Define a nested field and apply it to scenes that are not analyzed
"raw": {
"ignore_above": 256, // Ignore fields with a value length greater than 256 corresponding to the field
"index": "false",
"type": "string", // The type of the field is string
"doc_values": true // For fields that are not parsed, doc_values corresponds to a columnar storage structure. The default is false
}
}
}
}
},
"float_fields": {
"match": "*",
"match_mapping_type": "flaot",
"mapping": {
"type": "flaot",
"doc_values": true
}
}
],
"properties": { ... }
}
2. User defined field mapping
The fields in the index type can be defined in addition to dynamic templates. The common user-defined structures are as follows:
"mappings": {
"dynamic_templates": [ ... ],
"properties": {
"user_city": { // Field name
"analyzer": "lowercase_analyzer", // Field analyzer
"index": "analyzed", // Field index method defines the index
"type": "string", // The field data type is defined as string
"fields": { // Define a user_ Embedded unparsed field of city.raw
"raw": {
"ignore_above": 512,
"index": "not_analyzed",
"type": "string"
}
}
},
"money":{
"type": "double",
"doc_values": true
}
...
}
}
2.1.7 Shards
To solve the problem of data horizontal expansion, elastic search provides the ability to divide the index into multiple copies, each of which is called sharding.
A shard is a minimum level work unit, which only saves a part of all the data in the index. Slicing is an instance of Lucene, and it itself is a complete search engine. Documents are stored in shards and indexed in shards, but applications do not communicate directly with them. Instead, they communicate directly with the index.
When the cluster expands or shrinks, Elasticsearch will automatically migrate partitions between nodes to keep the cluster balanced.
When creating an index, you can specify the number of slices. Shards can be primary shard s or replica Shards. Each document in the index belongs to a separate primary partition, so the number of primary partitions determines how much data the index can store at most. Theoretically, there is no limit to the size of data that the main partition can store, which depends on the actual use: the size of hardware storage, the size and complexity of documents, how to index and query documents, and the expected response time.
Advantages of slicing:
1. Allow horizontal partition / expansion of memory capacity;
2. Allow distributed and parallel operations on shards to improve performance / throughput.
How a fragment is distributed, how its documents aggregate and search requests are completely managed by Elasticsearch. For users, these are transparent and do not need to care too much.
An Elasticsearch index is a collection of fragments. When elastic search searches in the index, it sends a query to each partition belonging to the index, and then combines the results of each partition into a global result set.
Slice setting
For the setting of fragmentation in the production environment, the capacity needs to be planned in advance:
1. The number of slices is set too small: subsequent nodes cannot be added to achieve horizontal expansion, the amount of data in a single slice is too large, and data redistribution takes time;
2. The number of slices is set too large: it will affect the relevance scoring and accuracy of search results. At the same time, too many slices on a single node will lead to a waste of resources and affect the performance.
2.1.8 Replicas
Elastic search allows you to create one or more copies of shards, which are called replica shards (replicas). Replication shard is only a copy of the primary shard to solve the problem of high data availability.
Advantages of replication fragmentation:
1. High availability is provided in case of fragmentation / node failure;
2. Expand the search volume / throughput, because the search can run in parallel on all replicas.
In short, each index can be divided into multiple slices. A fragment can also be copied 0 or more times. Once replicated, each index has a primary shard (the shard that is the replication source) and a replication shard (the primary shard)
The difference between sliced copies). The number of shards and replicas can be specified when the index is created. After the index is created, the number of replicas can be changed dynamically at any time, but the number of shards cannot be changed. By default, each index in Elasticsearch is partitioned into 1 master partition and 1 replica,
2.1.9 relevance
By default, the returned results are arranged in reverse order of relevance. But what is relevance? How is the correlation calculated?
Each document has a correlation score, using a relative floating-point number segment_ Score_ The higher the score, the higher the correlation.
The query statement adds one for each document_ Score field. The calculation method of score depends on different query types, and different query statements are used for different purposes: fuzzy query will calculate the spelling similarity with keywords, and terms query will calculate the percentage of content found matching with keyword components. However, in a general sense, full-text search refers to calculating the similarity between content and keywords.
The similarity algorithm of ElasticSearch is defined as TF/IDF, that is, search word frequency / reverse document frequency, including:
1. Search term frequency (TF): the frequency of search terms in a document. The higher the frequency, the higher the correlation;
2. Reverse document frequency (IDF): the frequency of each search term in all documents. The higher the frequency, the lower the relevance. The weight of search words in most documents will be lower than that in a few documents, i.e
Check the general importance of a search term in the document;
3. Field length criteria: the longer the field length, the lower the correlation. The relevance of a search term appearing in a short title is higher than that of the same word appearing in a long content field.
If multiple query clauses are merged into a composite query statement, such as bool query, the score calculated by each query clause will be merged into the total correlation score.
TF/IDF scoring formula in Lucene:
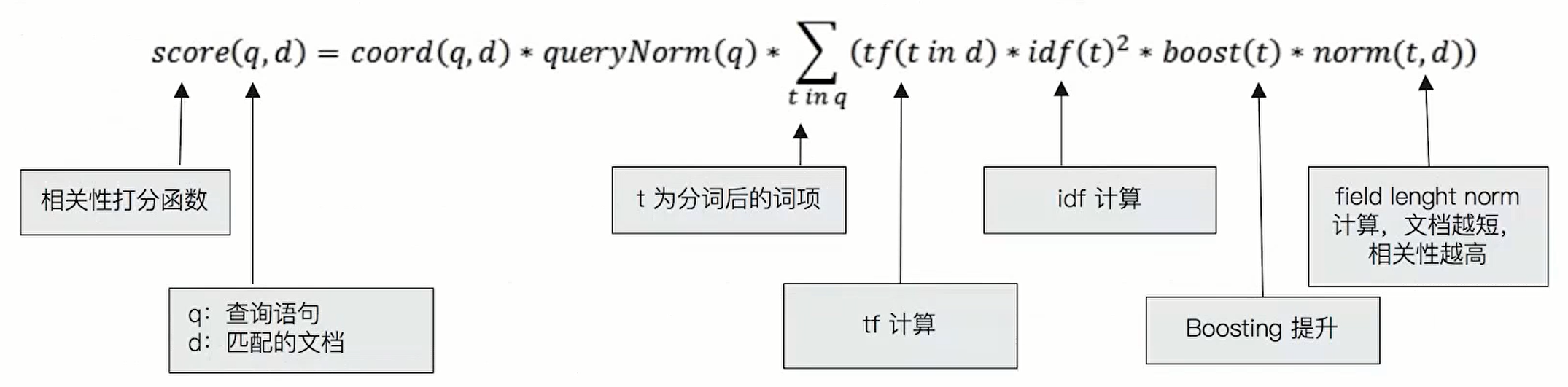
Starting from ES5.X, the default similarity algorithm is modified to BM25. Compared with the classical TF/IDF, when TF increases infinitely, the calculation branch of BM25 tends to a stable value.
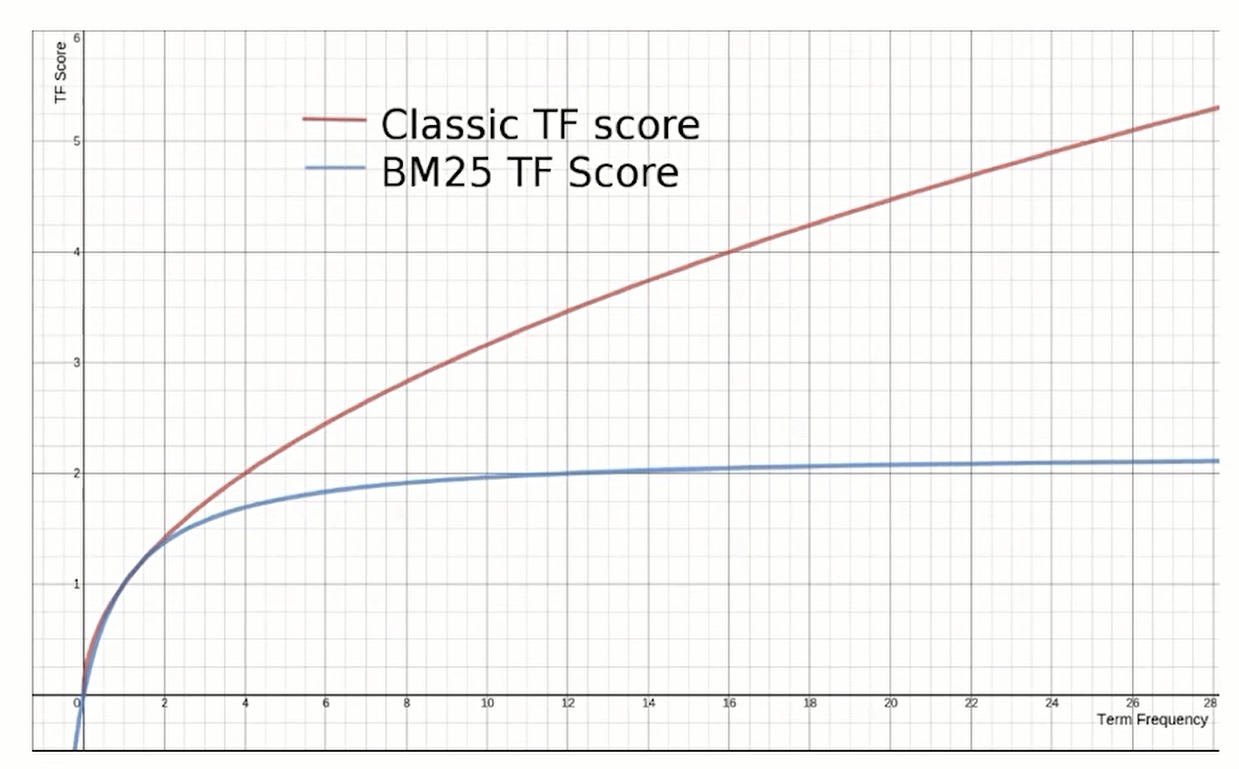
The scoring formula of BM25 algorithm is as follows:
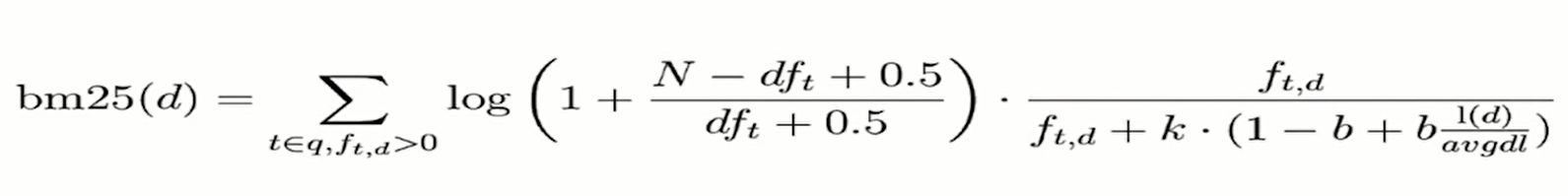
Note: the default value of k is 1.2. The smaller the value, the higher the saturation. The default value of b is 0.75.
2.2 system architecture
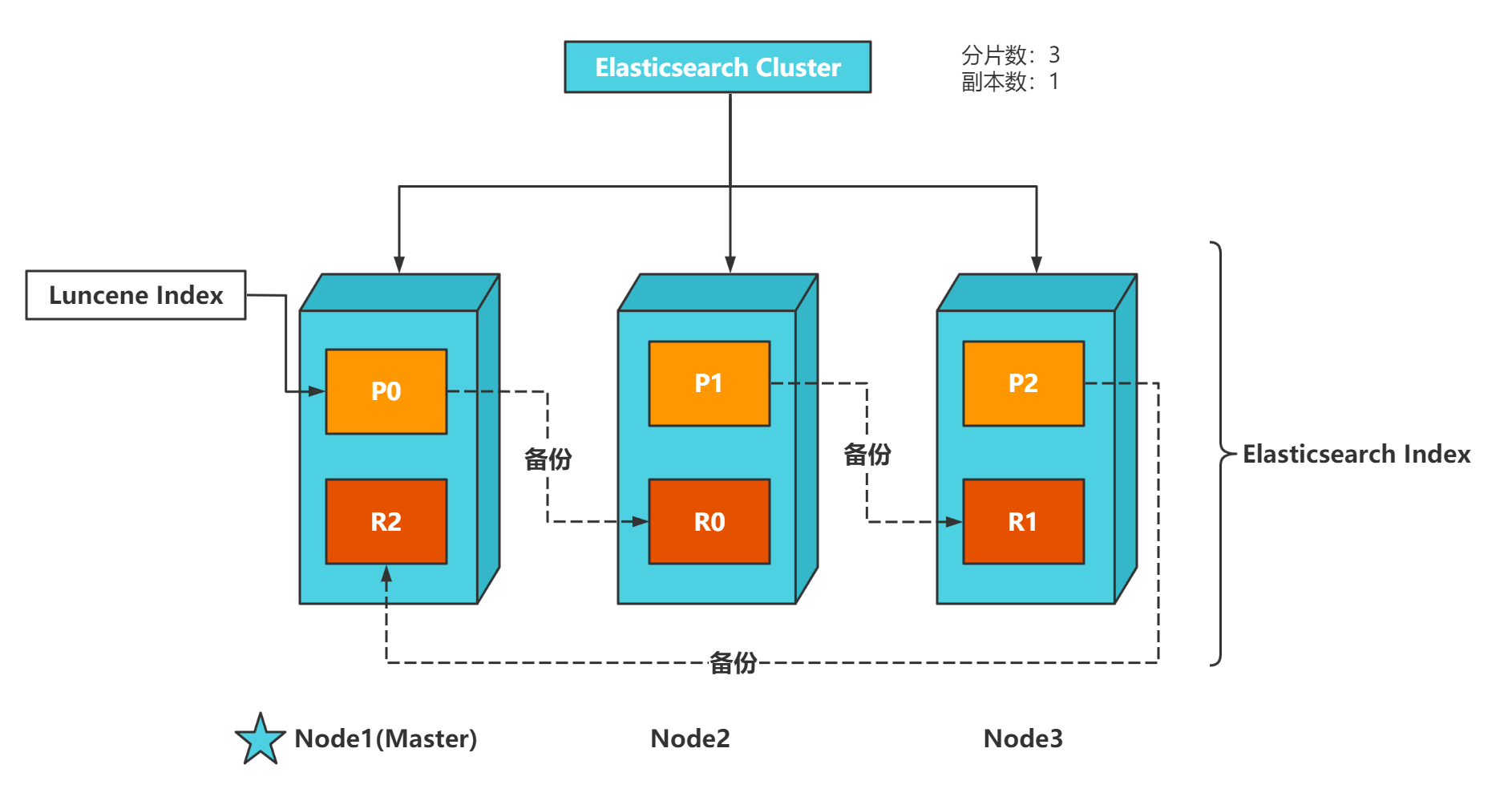
A running Elasticsearch instance is called a node, and a cluster is composed of one or more nodes with the same cluster.name configuration, which jointly bear the pressure of data and load. When nodes join the cluster or remove nodes from the cluster, the cluster will redistribute all data equally.
When a node is elected as the primary node, it will be responsible for managing all changes within the cluster, such as adding and deleting indexes, or adding and deleting nodes. The primary node does not need to involve document level changes, search and other operations, so when the cluster has only one primary node, it will not become a bottleneck even if the traffic increases. Any node can be the master node.
Users can send requests to any node in the cluster, including the master node. Each node knows the location of any document and can forward our request directly to the node where we store the documents we need. No matter which node we send the request to, it can collect data from each node containing the documents we need, and return the final result to the client. Elasticsearch's management of all this is transparent.
2.3 distributed cluster
2.3.1 single node cluster
Create an index named users in a cluster with an empty node, which will allocate 3 primary partitions and 1 replica. Send GET request to ES server: http://localhost:9200/users , the request body is as follows:
{
"settings": {
"number_of_shards": 3, # Number of main segments 3
"number_of_replicas": 1 # Number of copies 1
}
}
Currently, a single node cluster has an index users, and all three primary partitions will be allocated on node1. You can view the cluster status through the elasticsearch head plug-in:

Cluster health value: yellow (9 of 18): indicates that all primary partitions of the current cluster are in normal operation, but not all replica partitions are in normal state.
 : 3 main segments operate normally.
: 3 main segments operate normally.
 : the three replica shards are Unassigned, and they are not assigned to any node. It is meaningless to save metadata and copies on the same node. Once the node is abnormal, all the data stored in the node will be lost.
: the three replica shards are Unassigned, and they are not assigned to any node. It is meaningless to save metadata and copies on the same node. Once the node is abnormal, all the data stored in the node will be lost.
2.3.2 failover
When only one node in the cluster is running, it means that there will be a single point of failure - no redundancy. You can start another node to prevent data loss. When the second node is started on the same machine, as long as it has the same cluster.name configuration as the first node, it will automatically discover the cluster and join it. However, when starting nodes on different machines, in order to join the same cluster, you need to configure a list of unicast hosts that can be connected to. It is configured to use unicast discovery to prevent nodes from inadvertently joining the cluster. Only nodes running on the same machine will automatically form a cluster.
The index of the document will be stored in the primary partition first, and then copied to the corresponding replication node concurrently. This ensures that data can be retrieved on both the primary and replication nodes.
If multiple nodes are started, all primary and replica tiles will be assigned:
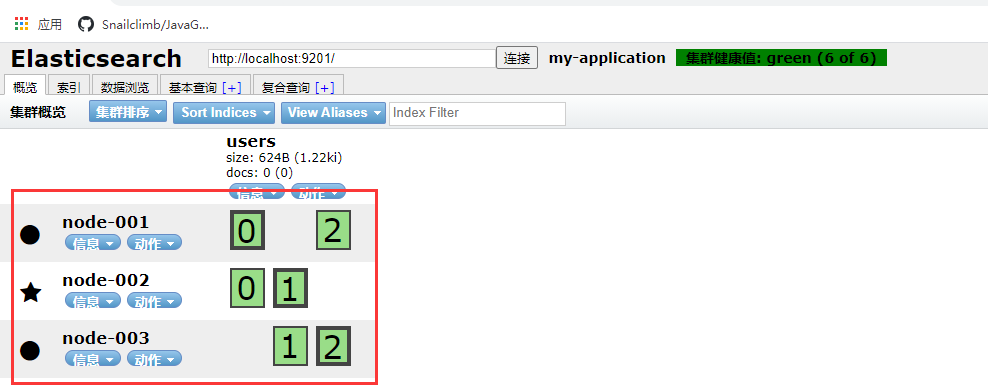
 : indicates that all 6 partitions (3 master partitions and 3 replica partitions) are running normally.
: indicates that all 6 partitions (3 master partitions and 3 replica partitions) are running normally.
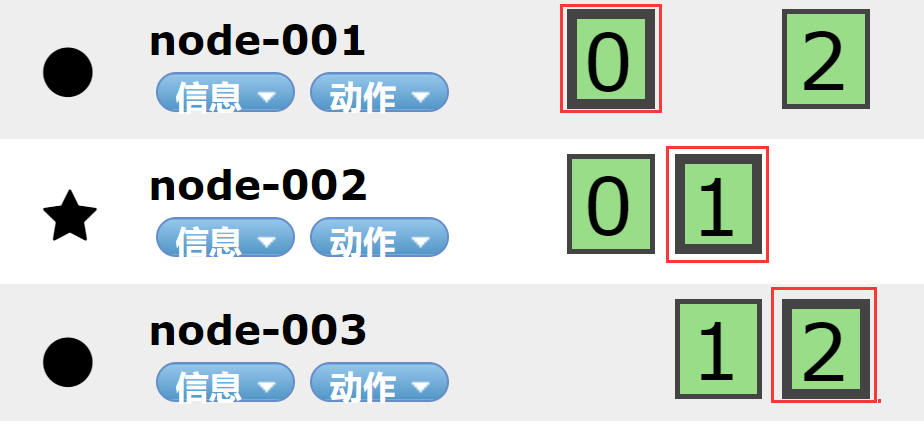 : the three main segments are normal.
: the three main segments are normal.
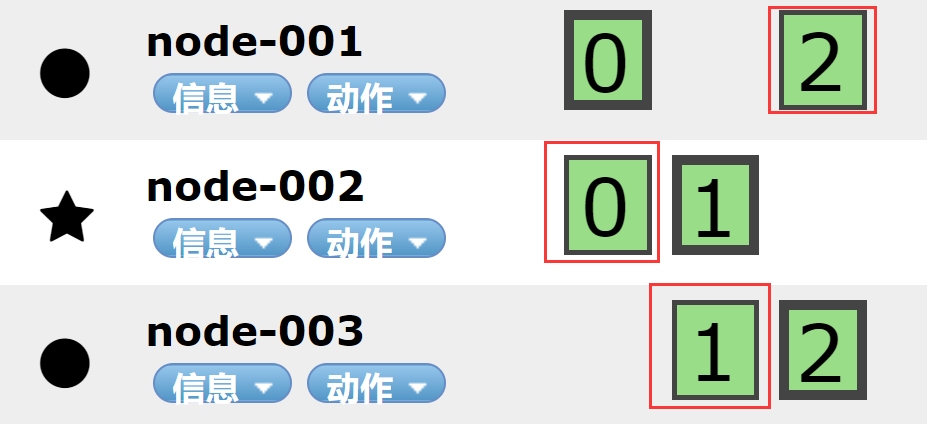 : three replica tiles and master tiles will be allocated to three nodes, and the same master tile and its replica tiles will not be allocated to the same node at the same time.
: three replica tiles and master tiles will be allocated to three nodes, and the same master tile and its replica tiles will not be allocated to the same node at the same time.
2.3.3 horizontal expansion
The number of primary partitions is determined when the index is created. In fact, this number defines the maximum amount of data that the index can store (the actual size also depends on hardware and usage scenarios).
However, read operations -- searching and returning data -- can be processed by both primary and replica shards, so the more replica shards there are, the higher the throughput will be. On the running cluster, the number of replica fragments can be dynamically adjusted, and we can scale the cluster on demand.
Send PUT request to ES server: http://localhost:9201/users/_settings, the request body is as follows:
{
"number_of_replicas": 2
}
The users index now has nine shards: three primary shards and six replica Shards. This means that we can expand the cluster to 9 nodes, one partition on each node. Compared with the original three nodes, the cluster search performance can be improved by three times.
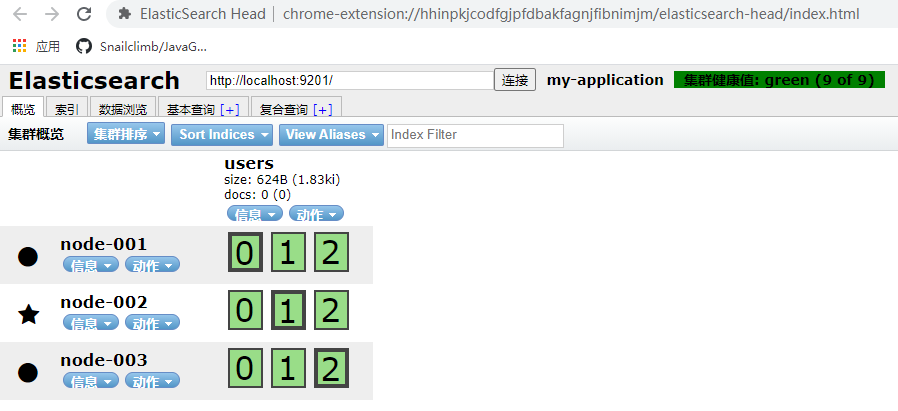
Of course, adding more replica shards to a cluster with the same number of nodes will not improve performance, because each shard will get less resources from the nodes. More hardware resources need to be added to improve throughput. However, more replica fragments improve data redundancy: according to the above node configuration, we can not lose any data without losing two nodes.
2.3.4 troubleshooting
Turn off a node of the current ES cluster. The first thing the cluster should do is to elect a new master node: node-002. After a node is closed, the primary partition and replica allocated by the node will also be lost, but there are replicas of the primary partition of the node in the other two nodes. The new primary node will promote the corresponding replicas on node-001 and node-002 to the primary partition. This process occurs instantaneously.
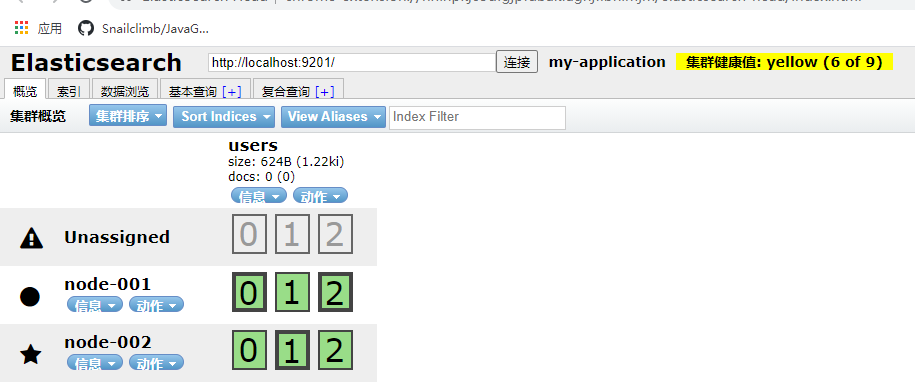
Why is the cluster state yellow instead of green?
Although node node-003 is unavailable, the cluster still has all three primary partitions. However, the cluster also sets that each primary partition needs to correspond to two replica partitions, and there is only one replica partition at this time. Therefore, the cluster cannot be in the green state. If node-002 is closed again, the program can still run without losing any data, because node-001 keeps a copy for each partition. If node-003 is restarted, the cluster can allocate the missing replica fragments again, and the state of the cluster will also be restored to the previous state. If node node-003 still has the previous shards, it will try to reuse them and copy only the modified data files from the main shard. Compared with the previous cluster, only the Master node is switched.
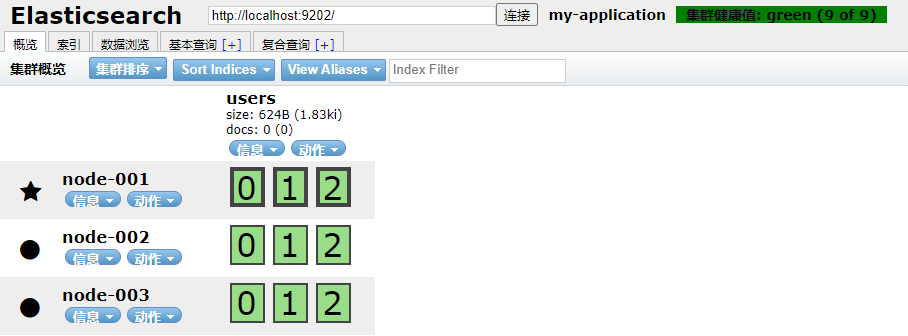
2.3.5 route calculation
When indexing a document, the document will be stored in a main partition. ES determines which partition the document should be stored in according to the result of routing calculation. Routing calculation formula:
s
h
a
r
d
=
h
a
s
h
(
r
o
u
t
i
n
g
)
%
n
u
m
b
e
r
_
o
f
_
p
r
i
m
a
r
y
_
s
h
a
r
d
s
shard = hash(routing) \% number\_of\_primary\_shards
shard=hash(routing)%number_of_primary_shards
routing is a variable value. By default, it is the id of the document. It can also be set to a user-defined value. This is also the reason why the number of primary partitions is determined when the index is created and cannot be changed later. Once the number of primary partitions is changed later, the value of the previous route will be invalid and the document cannot be obtained correctly.
All document API s (get, index, delete, bulk) receive a routing parameter, through which you can customize the mapping of documents to fragments. A custom routing parameter can ensure that all related documents are stored in the same fragment.
2.3.6 slice control
Suppose an ES cluster consists of three nodes, including an index of user, with two primary partitions, and each primary partition has two replicas. Send PUT request to es server: http://localhost:9201/user , the request body is as follows:
{
"settings": {
"number_of_shards": 2, # The main partition is 2
"number_of_replicas": 2 # Copy is 2
}
}
View the cluster status through elasticsearch head:
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-4nmmybww-1637994003640)( https://i.loli.net/2021/11/23/lTGYKjcdJMDBtEs.png )]
Requests can be sent to any node in the cluster, and each node has the ability to process any request. Each node knows any document location in the cluster, so it can forward the request directly to the required node. In the following example, all requests are sent to node-001, which we call coordinating node.
When sending requests, in order to expand the load, it is better to poll all nodes in the cluster.
2.3.6.1 write process
The write operation must be completed on the primary partition before it can be copied to the relevant replica partition.
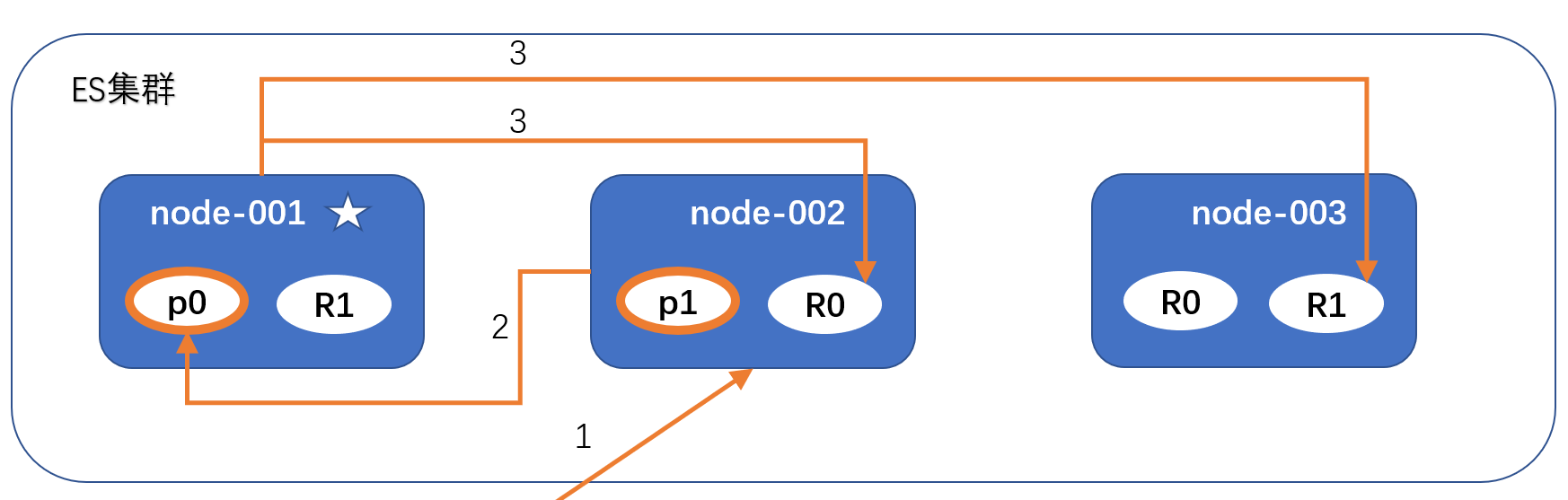
Steps:
1. The client requests the ES cluster node (any node is the coordination node), which is assumed to be node-002;
2. The coordination node calculates that the request belongs to fragment 0, and the request will be forwarded to node node-001 (fragment 0 is located at node-001);
3. Node-001 executes the request. If successful, it forwards the request to the replicas of node-002 and node-003 in parallel. Once all replica fragmentation reports success, node-001 will return a response to the coordination node and the coordination node will return a response to the client.
When the client receives a successful response, the document change has been completed in the primary partition and all replica partitions, and the change is safe. Some optional request parameters allow this process to be affected, which may improve performance at the expense of data security. These options are rarely used because Elasticsearch is fast, but for completeness, please refer to the following table:
| parameter | meaning |
|---|---|
| consistency | Consistency is consistency. By default, even before attempting to perform a write operation, the master shard requires that a specified number of shard copies (or in other words, most of them) must be active and available before performing a write operation (where the shard copy can be the master shard or copy shard). This is to avoid write operation in case of network partition failure, resulting in data inconsistency. Specified quantity: int ((primary + number_of_replicas) / 2) + 1. The value of the consistency parameter can be set to one (write operation is allowed as long as the primary partition status is ok), all (write operation is allowed only if the status of the primary partition and all replica partitions is ok), or quorum. Note that number is in the calculation formula of the specified quantity_ of_ Replicas refers to the number of replica fragments in the index setting, not the number of replica fragments in the current processing active state. If it is specified that the current index has three replica shards when creating the index, the calculation result of the specified number is: (primary + 3 replicas) / 2) + 1 = 3. If only two nodes are started at this time, the number of active replica shards will not reach the specified number, so any documents cannot be indexed and deleted. |
| timeout | If there are not enough replica shards, Elasticsearch will wait for more shards to appear. By default, wait up to 1 minute. If necessary, you can use the timeout parameter to terminate it earlier. |
| replication | The default value of replication is sync, which will cause the primary partition to return only after receiving a successful response from the replication partition. Set replication to async (not recommended), and the request will be returned to the client after being executed on the primary partition. It will still forward the request to the replication node, but it will not know whether the replication node is successful or not. The default sync replication allows Elasticsearch to force feedback transmission. async replication can overload elastic search by sending too many requests without waiting for other shards to be ready. |
2.3.6.2 reading process
Documents can be retrieved from the master shard or any other copy.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-hpubqquv-1637994003646)( https://i.loli.net/2021/11/23/8d7L2yeaUicRPfx.png )]
Steps:
1. The client requests the ES cluster node (any node is the coordination node), which is assumed to be node-002;
2. The coordination node calculates that the request belongs to fragment 0, and the copy of fragment 0 exists on three nodes. In this case, the request will be returned directly to the client.
When processing read requests, the coordination node will poll all replica fragments to achieve load balancing every time. When the document is retrieved, the indexed document may already exist on the primary partition but has not been copied to the replica partition. In this case, the replica shard may report that the document does not exist, but the master shard may successfully return the document. Once the index request is successfully returned to the user, the document is available in both primary and replica Shards.
2.3.6.3 locally updated documents
The update API combines the read and write modes mentioned earlier.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-ir67vxek-1637994003647)( https://i.loli.net/2021/11/23/i1U4K8NE7hsuQRT.png )]
Perform the necessary sequential steps for local updates:
1. The client sends an update request to Node 1;
2. It forwards the request to Node 3 where the main partition is located;
3. Node 3 retrieves the document from the main partition and modifies it_ JSON of the source field, and then rebuild the index on the main partition. If another process modifies the document, it returns retry_ on_ Repeat step 3 for the number of times conflict is set. If it fails, give up;
4. If Node 3 successfully updates the document, it forwards the new version of the document to the replication nodes on Node 1 and Node 2 to rebuild the index. When all replication nodes report success, Node 3 returns success to the requesting node and then to the client.
Note: when the master shard forwards the change to the copy shard, it does not forward the update request, but forwards the new version of the whole document. Because these modifications are forwarded to the replication node asynchronously, they do not guarantee that the order of arrival is the same as that of sending. If Elasticsearch only forwards the modification request, the modification order may be wrong, and the result is a damaged document.
2.3.7 slicing principle
Slicing is the smallest work unit of Elasticsearch. Traditional databases store a single value for each field, but this is not enough for full-text retrieval. Each word in the text field needs to be searched, which means that for the database, a single field needs the ability to index multiple values. The best data structure to support multiple values of a field is inverted index.
2.3.7.1 inverted index
Elastic search uses a structure called inverted index, which is suitable for fast full-text search. If there is an inverted index, there must be a forward index. The so-called forward index means that the search engine will correspond all the files to be searched to a file ID. during the search, the ID will correspond to the search keyword to form a K-V pair, and then the keyword will be counted.
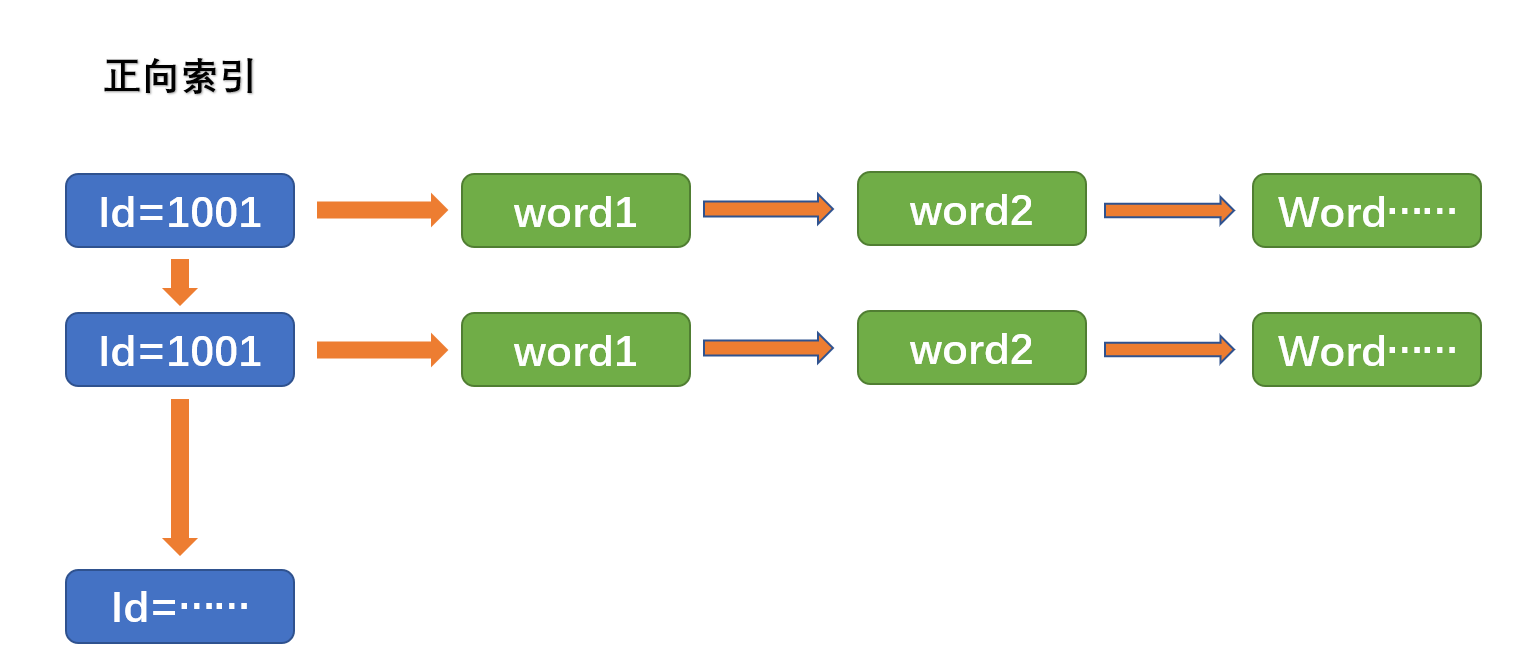
However, the number of documents included in search engines on the Internet is astronomical. Such an index structure can not meet the requirements of returning ranking results in real time. Therefore, the search engine will rebuild the forward index into an inverted index, that is, convert the mapping from file ID to keyword to keyword to file ID. each keyword corresponds to a series of files, and this keyword appears in these files.
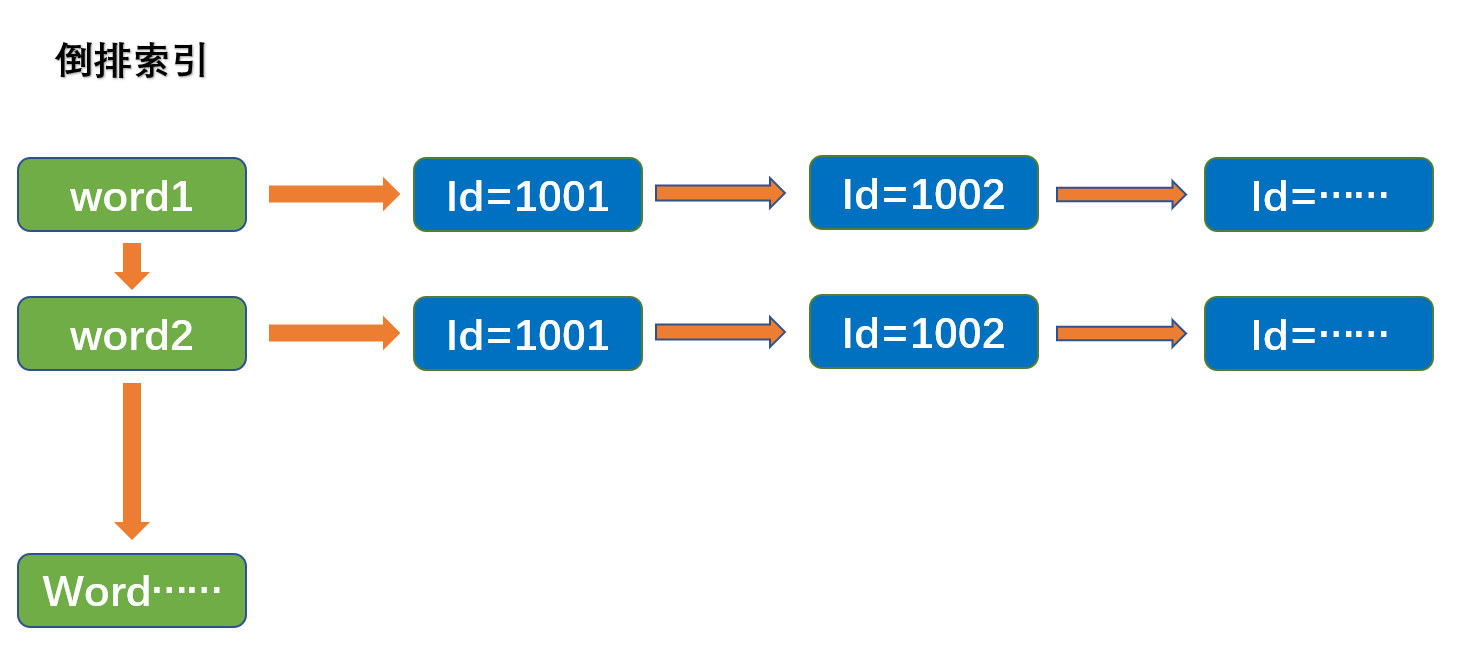
An inverted index consists of a list of all non repeating words in the document. For each word, there is a document list containing it. For example, suppose there are two documents, and the content field of each document contains the following contents:
The quick brown fox jumped over the lazy dog
Quick brown foxes leap over lazy dogs in summer
In order to create an inverted index, first split the content field of each document into separate words (called entries or tokens), create a sorted list containing all non duplicate entries, and then list which document each entry appears in. The results are as follows:
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-jil5rbkj-163794003649) (elasticsearch / image-20210913230737835. PNG)]
Now, if you want to search quick and brown, you just need to find the document containing each entry:
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-HCxjDVee-1637994003649)(Elasticsearch/image-20210913230819837.png)]
Both documents match, but the first document matches more than the second. If you use a simple similarity algorithm that only calculates the number of matching terms, it can be said that the first document is better than the second document for the relevance of the current query. However, the current inverted index has some problems:
1. Quick and quick appear as independent terms, but users may think they are the same words;
2. fox and foxes are very similar, just like dog and dogs. They have the same root;
3. Jump and leap, although they don't have the same root, they are synonyms.
Using the previous index to search + Quick and + Fox will not get any matching documents. (+ prefix indicates that this word must exist) only documents with Quick and fox can meet this query condition, but the first document contains Quick and fox, and the second document contains Quick and foxes. Users can reasonably expect the two documents to match the query. If the entries are normalized to the standard mode, you can find documents that are not completely consistent with the entries searched by users, but have enough relevance. For example:
1. Quick can be lowercase to quick;
2. foxes can extract word stems and change them into root format fox. Similarly, dogs can be extracted as dog;
3. Jump and leap are synonyms and can be indexed as the same word jump.
The processed inverted index looks like:
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-tdIj82mK-1637994003650)(Elasticsearch/image-20210913231947313.png)]
That's not enough. Our search for + quick and + fox will still fail, because there is no quick in our index. However, if we use the same standardization rules as the content field for the search string, it will become query + quick and + fox, so that both documents will match! The process of word segmentation and standardization is called analysis.
Only entries that appear in the index can be searched, so the index text and query string must be standardized to the same format.
Core composition of inverted index
The inverted index consists of two parts:
1. Term Dictionary: record the words of all documents and the association relationship between words and inverted list;
2. Posting List: records the document combination corresponding to words, which is composed of inverted index items. Inverted index entries consist of the following parts:
a. document id;
b. word frequency TF, the number of times the word appears in the document, which is used for relevance scoring;
c. position, the position of word segmentation in the document;
d. offset: record the beginning and end position of the word.
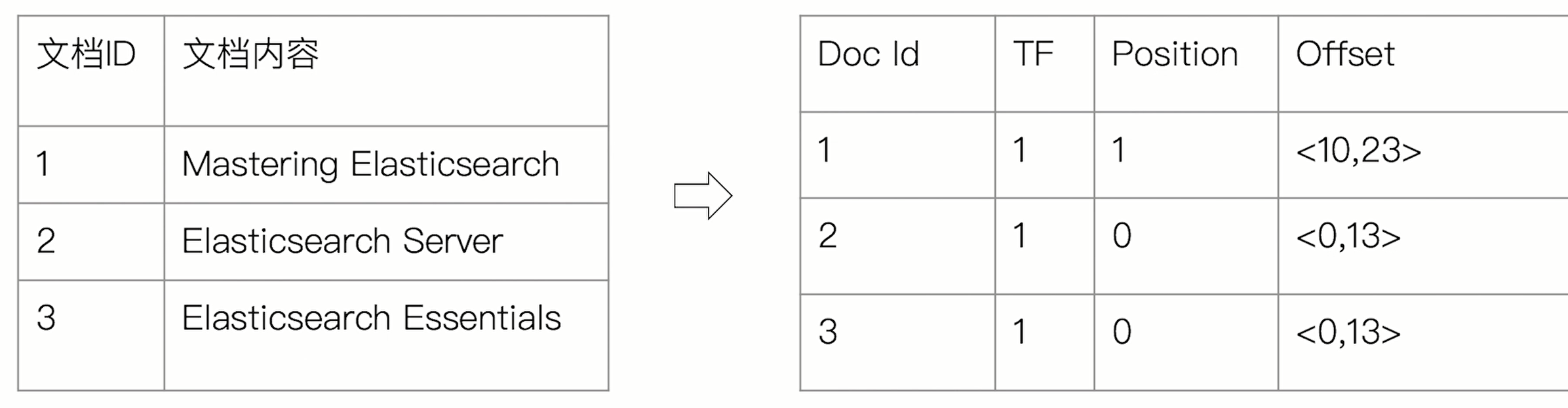
2.3.7.2 document search
Early full-text retrieval would build a large inverted index for the whole document collection and write it to disk. Once the new index is ready, the old one will be replaced by it so that the latest changes can be retrieved. The inverted index cannot be changed after it is written to disk: it will never be modified.
Invariance has important value:
1. No lock is required. If you never update the index, you don't need to worry about multiple processes modifying data at the same time;
2. Once the index is read into the kernel's file system cache, it will stay there because of its invariance. As long as there is enough space in the file system cache, most read requests will directly request memory without hitting the disk;
3. Other caches (such as filter cache) are always valid during the life cycle of the index. They do not need to be reconstructed every time the data changes because the data does not change;
4. Writing a single large inverted index allows data to be compressed, reducing the use of disk I/O and indexes that need to be cached in memory.
Of course, a constant index also has some disadvantages. The main thing is that it is immutable! It cannot be modified. If you need to make a new document searchable, you need to rebuild the entire index. This either limits the amount of data an index can contain, or limits the frequency with which the index can be updated.
2.3.7.3 dynamic update index
How to update inverted index while preserving invariance?
The answer is: use more indexes. Instead of rewriting the entire inverted index directly, add a new supplementary index to reflect the recent changes. Each inverted index will be queried in turn, and the results will be merged after the query is completed from the earliest. Elastic search is based on Lucene. This java library introduces the concept of segment search. Each segment itself is an inverted index, but the index in Lucene not only represents the collection of all segments, but also adds the concept of submission point - a file listing all known segments:
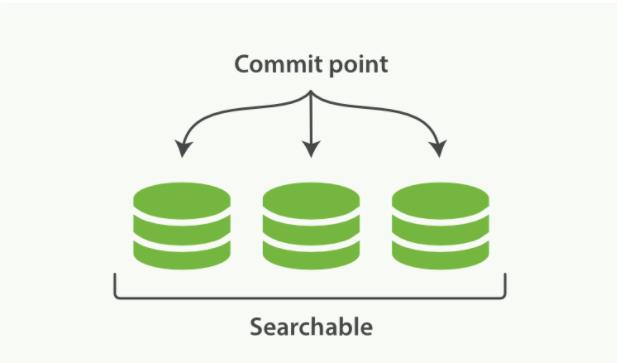
Search by segment follows the following process:
1. The new document is collected into the memory index cache;
2. The cache is submitted irregularly:
A. a new segment is written to the disk;
b. a new submission point containing the name of the new segment is written to the disk;
c. synchronize the disk, and all writes waiting in the file system cache are flushed to the disk.
3. The new segment is opened, and the documents it contains are visible to be searched;
4. The memory cache is emptied and waiting to receive new documents.
When a query is triggered, all known segments are queried in order. Word item statistics will aggregate the results of all segments to ensure that the association between each word and each document is calculated accurately. In this way, new documents can be added to the index at a relatively low cost.
Segments are immutable, so you can neither remove the document from the old segment, nor modify the old segment to reflect the update of the document. Instead, each submission point contains a. del file that lists the segment information of these deleted documents.
When a document is "deleted", it is actually only marked for deletion in the. del file. A document marked for deletion can still be matched by the query, but it will be removed from the result set before the final result is returned.
Document updating is a similar operation: when a document is updated, the old version of the document is marked for deletion, and the new version of the document is indexed into a new segment. Both versions of the document may be matched by a query, but the deleted old version of the document has been removed before the result set is returned.
2.3.7.4 near real time search
With the development of per segment search, the delay of a new document from indexing to searchable is significantly reduced. New documents can be retrieved in minutes, but it's not fast enough. Disk has become a bottleneck here. Committing a new segment to disk requires an fsync to ensure that the segment is physically written to disk so that data will not be lost in the event of a power failure. But fsync operation is expensive; If you index a document every time, it will cause great performance problems.
Between Elasticsearch and disk is the file system cache. The document in the memory index buffer is written to a new segment. But here, the new segment will be written to the file system cache first - this step will be less expensive, and then flushed to disk later - this step is more expensive. However, as long as the file is already in the cache, it can be opened and read like other files.
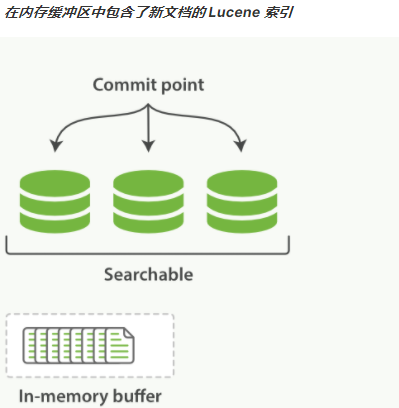
Lucene allows new segments to be written and opened -- making the documents they contain visible to the search without a full submission. This approach is much less expensive than a commit and can be performed frequently without affecting performance.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-xpsmvjzo-1637994003653)( https://i.loli.net/2021/11/23/3FuKdlbYSpJ4fkH.png )]
In elastic search, the lightweight process of writing and opening a new segment is called refresh. By default, each fragment will be refreshed automatically every second. This is why Elasticsearch is a near real-time search. Document changes are not immediately visible to the search, but become visible within a second.
These behaviors can confuse new users: they index a document and try to search it, but they don't find it. The solution to this problem is to perform a manual refresh with the refresh API: / users/_refresh although refresh is a much lighter operation than commit, it still has performance overhead. Manual refresh is useful when writing tests, but don't refresh manually every time you index a document in the production environment.
Not all cases require a refresh per second. You can set refresh_interval, reduce the refresh frequency of each index and send a PUT request to the ES server: http://localhost:9200/users/_settings, the request body is as follows:
{
"settings": {
"refresh_interval": "30s"
}
}
// Another way of writing
{
"refresh_interval": "30s"
}
refresh_interval can be dynamically updated on the existing index. In the production environment, when a large new index is being created, you can turn off the automatic refresh first, and then call them back when you start using the index:
// Turn off automatic refresh
PUT http://localhost:9200/users/_settings
{
"settings": {
"refresh_interval": -1
}
}
// Refresh every second
PUT http://localhost:9200/users/_settings
{
"refresh_interval": "1s"
}
2.3.7.5 persistent changes
If fsync is not used to flush the data from the file system cache to the hard disk, there is no guarantee that the data will still exist after power failure or even after the program exits normally. To ensure the reliability of elasticsearch, you need to ensure that data changes are persisted to disk. In dynamically updating the index, we say that a complete commit will brush the segments to disk and write a commit point containing a list of all segments. Elasticsearch uses this submission point to determine which segments belong to the current partition when starting or reopening an index.
Even if near real-time search is achieved through refresh per second, full commit is still required frequently to ensure recovery from failure. But what about documents that change between submissions? Elasticsearch adds a translog, or transaction log, which is logged every time elasticsearch is operated.
The whole process is as follows:
1. After a document is indexed, it will be added to the memory buffer and appended to the translog;
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-nxqt3wgw-1637994003653)( https://i.loli.net/2021/11/23/fRgK8O3Q75ujFhx.png )]
2. Refresh to refresh the partition once per second:
A. the document in the memory buffer is written to a new segment without fsync operation;
b. this segment is opened so that it can be searched;
c. the memory buffer is cleared.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-otdwbul3-1637994003654)( https://i.loli.net/2021/11/27/HdeE2jaWIh37bKB.png )]
3. The process continues to work, and more documents are added to the memory buffer and appended to the transaction log;
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-4o4bhi8j-1637994003655)( https://i.loli.net/2021/11/27/VElarn1fTpB4Khg.png )]
4. Every once in a while, for example, the translog becomes larger and larger; The index is flush ed; A new translog is created and a full commit is executed:
A. all documents in the memory buffer are written to a new segment;
b. the buffer is cleared;
c. A submission point is written to the hard disk;
d. the file system cache is flush ed through fsync;
e. the old translog is deleted.
Translog provides a persistent record of all operations that have not been flushed to disk. When Elasticsearch starts, it will use the last commit point from the disk to recover the known segments, and will replay all changes in the translog after the last commit.
Translog is also used to provide real-time CRUD. When you try to query, update and delete a document by ID, it will first check the translog for any recent changes before trying to retrieve it from the corresponding segment. This means that it can always get the latest version of the document in real time.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-7dfc60fk-1637994003655)( https://i.loli.net/2021/11/23/TxvcLUjrMGBFsbz.png )]
The behavior of performing a commit and truncating the translog is called a flush in elastic search. The fragments are automatically flushed every 30 minutes, or when the translog is too large.
The purpose of translog is to ensure that the operation will not be lost. Before the file is fsync to the disk, the written file will be lost after restart. By default, the translog is refreshed to the hard disk by fsync every 5 seconds or executed after each write request is completed (e.g. index, delete, update, bulk). This process occurs in both the master partition and the copy partition. This means that the client will not get a 200 OK response until the entire request is fsync to the translog of the primary partition and the replication partition.
Executing an fsync after each request brings some performance loss, although practice shows that this loss is relatively small (especially bulk import, which shares the cost of a large number of documents in one request). However, for some clusters with large capacity that occasionally lose a few seconds of data, it is beneficial to use asynchronous fsync. For example, the written data is cached in memory and fsync is executed every 5 seconds.
Paragraph 2.3.7.6 consolidation
Because the automatic refresh process will create a new segment per second, this will lead to a sharp increase in the number of segments in a short time. Too many segments will cause great trouble. Each segment consumes file handles, memory, and cpu cycles. More importantly, each search request must check each segment in turn: so the more segments, the slower the search.
Elastic search solves this problem by merging segments in the background. Small segments are merged into large segments, and then these large segments are merged into larger segments. When segments are merged, those old deleted documents will be cleared from the file system. The deleted document (or the old version of the updated document) will not be copied to the new large section.
Start segment merging automatically when indexing and searching:
1. When indexing, the refresh operation will create a new segment and open the segment for search;
2. The merge process selects a small number of segments of similar size and merges them into larger segments in the background. This does not interrupt indexing and searching;
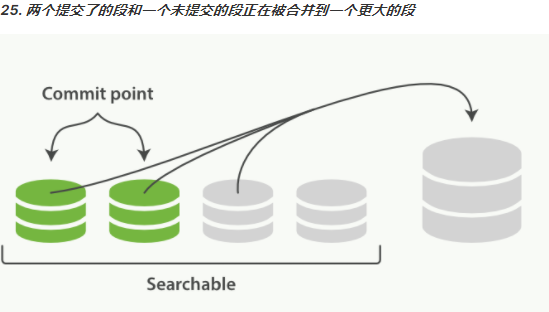
3. Once the consolidation is completed, the old segment will be deleted:
A. the new segment is flush ed to the disk. Write a new node containing new segments and excluding old and smaller segments;
b. the new segment is opened for searching;
c. The old paragraph is deleted.
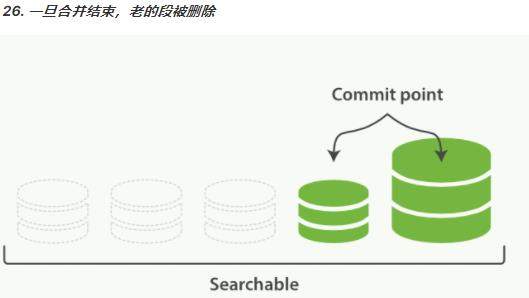
Merging large segments requires a lot of I/O and CPU resources. If it is allowed to develop, it will affect the search performance. Elastic search imposes resource constraints on the merge process by default, so there are still enough resources to perform the search well.
2.3.8 distributed search
How search is performed in a distributed environment. It is more complex than the basic addition, deletion, modification and query requests mentioned earlier.
A CRUD operation only processes a single document. The uniqueness of the document is determined by_ index ,_ type and routing value (usually the _id of the document by default). This means that we can know exactly which slice in the cluster holds the document.
Because it is not known which document will match the query (the document may be stored on any fragment in the cluster), the search needs a more complex model. A search has to query the fragmented copy of each index to see if it contains any matching documents.
However, finding all matching documents is only half the job. Before the Search API returns a page of results, the results from multiple slices must be combined into a sequential table. Therefore, the execution process of search is divided into two stages, called query then fetch.
2.3.8.1 query phase
In the initial query phase, the query is broadcast to each fragmented copy (original or copy) in the index. Each fragment performs a search locally and establishes a priority queue of matching documents. A priority queue is just an ordered list of the first n (top-n) matching documents. The size of this priority queue is determined by the paging parameters from and size.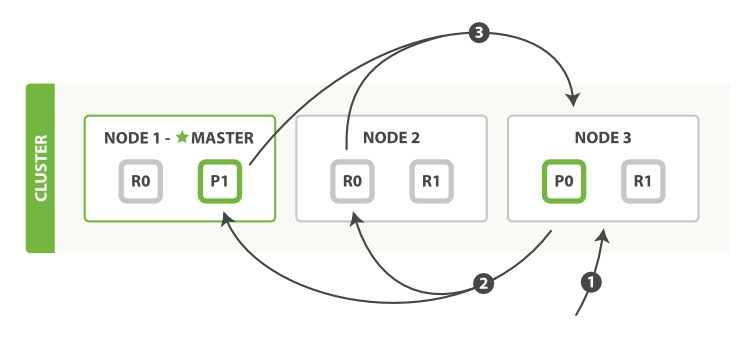
The whole query phase is divided into three steps:
1. The client sends a search request to Node 3, which creates an empty priority queue with a length of from + size;
2. Node 3 forwards the search request to the original or copy of each partition in the index. Each fragment executes the query locally, and puts the results (a lightweight result list, containing only the documentID value and the value needed for sorting) into an ordered local priority queue with the size of from + size;
3. Each partition returns the ID of the document and the sorting value of all documents in its priority queue to the coordination node node 3. Node 3 combines these values into its own priority queue to generate global sorting results, which represents the final global ordered result set. At this point, the query phase ends.
When a search request is sent to a node, the node becomes a coordination node. The job of this node is to broadcast search requests to all relevant slices and integrate their responses into a global ordered result set. This result set is returned to the client.
2.3.8.2 retrieval stage
The query phase identifies the documents that meet the search request, but it still needs to retrieve the documents themselves. This is the work of the retrieval phase. The retrieval phase of distributed search is shown in the figure:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-u1dvdhfh-1637994003658)( https://i.loli.net/2021/11/23/ON2boZlhigVA1dc.png )]
The whole retrieval stage is divided into three steps:
1. The coordination node identifies which document needs to be retrieved and sends a GET request to the relevant partition;
2. Each fragment loads documents and enrich es them as needed, and then returns the documents to the coordination node;
3. Once all document s are retrieved, the coordination node will return the results to the client.
The coordination node first determines which documents actually need to be retrieved, then establishes a multi-point get request for each fragment holding relevant documents, then sends the request to the fragment copy in the processing query stage, and finally loads the document body in fragments -_ source . If necessary, it also enriches the results and highlights the search fragments according to the metadata. Once the coordination node receives all the results, it will aggregate them into a single response, which will be returned to the client.
According to the number of document s, the number of slices and the hardware used, deep paging of 10000 to 50000 results is feasible. However, for a large enough from value, the sorting process will become very heavy, using a huge amount of CPU, memory and bandwidth. Therefore, deep paging is strongly discouraged.
2.3.8.3 search options
ES supports influencing the search process through some optional query parameters.
preference
The preference parameter allows you to control which shards or nodes are used to process search requests. She accepts the following parameters:
1,_ Primary: only query the primary partition, no matter how many copies there are;
2, _ primary_first: read the main partition first. If the main partition is invalid or fails, other partitions will be read;
3, _ replica: query only replicas;
4,_ replica_first: query the replica first. If the replica is invalid, the primary partition will be queried;
5,_ local: execute queries locally as far as possible without crossing the network;
6,_ prefer_nodes:abc,xyz: execute query on the specified node id;
7,_ shards:2,3: query the data on the specified partition;
8, _ only_nodes:1: restrict operations to specific node s.
However, usually the most useful values are random strings, which can avoid the problem of result oscillation. Result oscillation: search requests are polled between valid fragment replicas, and the order in the main fragment may be inconsistent with that in the replica. The order of results will change every time a search request is made.
search_type
Although query_then_fetch is the default search type, but other search types can also be specified for specific purposes.
1. Count: the count search type has only one query stage. You can use this query type when you don't need search results and only need to know the number of document s that meet the query;
2,query_and_fetch: query_ and_ The fetch search type combines the query and retrieval phases into one step. This is an internal optimization option. It can be used when the target of the search request is only a fragment, but it will basically have no effect;
3,dfs_query_then_fetch and dfs_query_and_fetch: the DFS search type has a pre query stage. It will retrieve the item frequency from all relevant segments to calculate the global item frequency;
4. Scan: the scan search type is used together with the scroll API, which can efficiently retrieve a large number of results. It is achieved by disabling sorting.
2.3.8.4 scanning and scrolling
The scan search type is used with the scroll API to efficiently retrieve a large number of results from elastic search without the cost of deep paging.
2.4 text analysis
Text analysis mechanism is used for word segmentation of Full Text to establish inverted index for search.
Text analysis includes the following processes:
1. Firstly, a text block is characterized as a single word suitable for inverted index;
2. Then standardize these words into standard forms to improve their "searchability" or "recall".
Text analysis is realized through an Analyzer. The Analyzer consists of three parts:
1. Character Filters: first, strings pass through the Character Filters in order. Their job is to process strings before characterization. The Character Filters can remove HTML tags or convert "&" to "and";
2. Tokenizer: the string is divided into single entries by the word splitter. A simple word splitter can separate words according to spaces or commas;
3. Token Filters: entries pass through each token filter in order. This process may change entries (for example, lowercase Quick), delete entries (for example, useless words such as a, and, the), or add entries (for example, synonyms such as jump and leap).
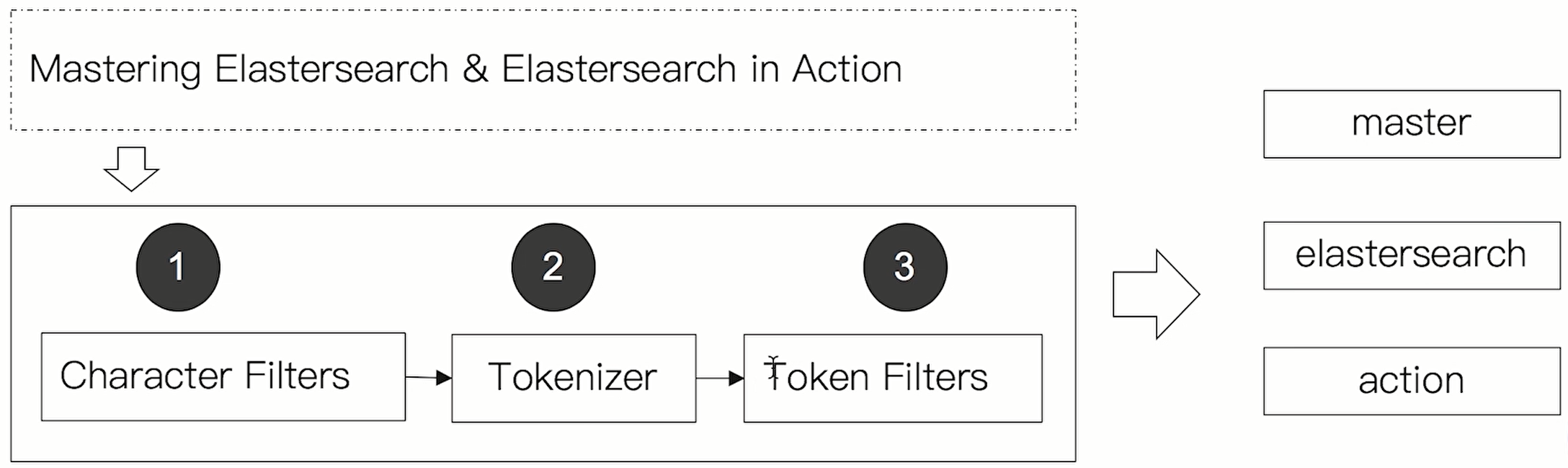
2.4.1 built in analyzer
Elasticsearch also comes with pre packaged analyzers that can be used directly:
1. Standard Analyzer: Elasticsearch is the default analyzer. It is the most commonly used choice for analyzing text in various languages. It divides text according to the word boundary defined by the Unicode Union. Delete most punctuation, and finally lower case the entry;
2. Simple Analyzer: the Simple Analyzer separates the text in any place that is not a letter and lowercases the entry;
3. Whitespace Analyzer: the Whitespace Analyzer divides text into spaces;
4. Keyword Analyzer: take input as output without word segmentation;
5. Regular expression analyzer: default non character segmentation;
6. Language analyzer: a specific language analyzer can be used for many languages. They can consider the characteristics of the specified language. For example, the English analyzer comes with a set of English useless words (such as and or the, which have little effect on relevance), which will be deleted. Because of understanding the rules of English grammar, this word splitter can extract the stem of English words.
2.4.2 analyzer usage scenario
When indexing a document, the full-text field is parsed into separate words to create an inverted index. However, when searching in the full-text domain, you need to pass the query string through the same analysis process to ensure that the search entry format is consistent with that in the index.
Full text queries understand how each domain is defined, so they can do the right thing:
1. When querying a full-text domain, the same analyzer will be applied to the query string to generate the correct search term list;
2. When querying an exact value field, the query string will not be analyzed, but the specified exact value will be searched.
2.4.3 test analyzer
You can use the analyze API to see how text is analyzed. Send GET request to ES server: http://localhost:9200/_analyze, the request body is as follows:
{
"analyzer": "standard", // The type of word breaker to use is a standard parser
"text": "This is a example for use analyzer" // Text to analyze
}
Server returned results:
{
"tokens": [
{
"token": "this",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "is",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "a",
"start_offset": 8,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "example",
"start_offset": 10,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "for",
"start_offset": 18,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "use",
"start_offset": 22,
"end_offset": 25,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "analyzer",
"start_offset": 26,
"end_offset": 34,
"type": "<ALPHANUM>",
"position": 6
}
]
}
token is the term actually stored in the index. Position indicates where the entry appears in the original text. start_offset and end_offset indicates the position of the character in the original string.
2.4.4 specify analyzer
Elasticsearch supports specified parsers in the form of plug-ins. Commonly used Chinese word splitters are: HanLp, IK, pinyin. Here is a demo of IK Chinese word splitter to analyze Chinese. The download address is: https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.8.0 , put the unzipped folder into the plugins directory under the ES root directory, and restart es to use it.
The IK word splitter supports two levels of splitting:
1,ik_max_word: split the text in the most fine-grained way;
2,ik_smart: split the text at the coarsest granularity.
Send GET request to ES server: http://localhost:9200/_analyze, using IK_ max_ The word level is split, and the request body is as follows:
{
"analyzer": "ik_max_word", # Specify ik word splitter split level
"text": "Chinese" # Text to analyze
}
The server returned a response:
{
"tokens": [
{
"token": "Chinese",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "China",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "countrymen",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 2
}
]
}
Words can also be extended in ES. Enter the ik folder under the plugins folder in the ES root directory, enter the config directory, create a custom.dic file, and write the words to be extended, such as freichrod. At the same time, open the IKAnalyzer.cfg.xml file, configure the new custom.dic in it, restart the ES server, and the extended vocabulary will take effect.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-f41lcnl3-1637994003659)( https://i.loli.net/2021/11/27/95DyMcV3dL1zerj.png )]
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-cm8sez4b-1637994003659)( https://i.loli.net/2021/11/23/I1ByVXnRMf9TUNz.png )]
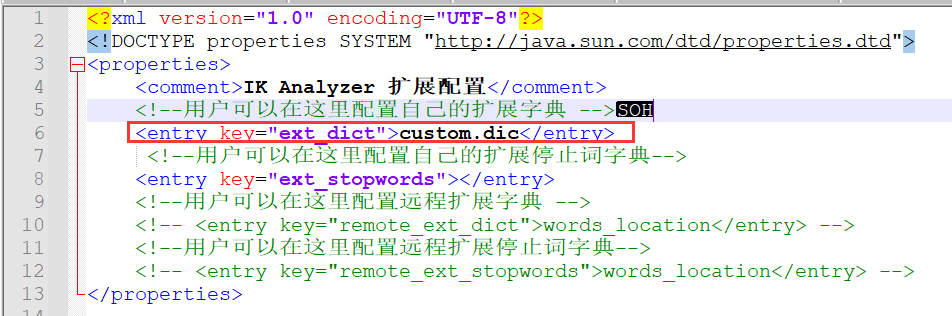
Send a request to the ES server and analyze the custom vocabulary. The results are as follows:
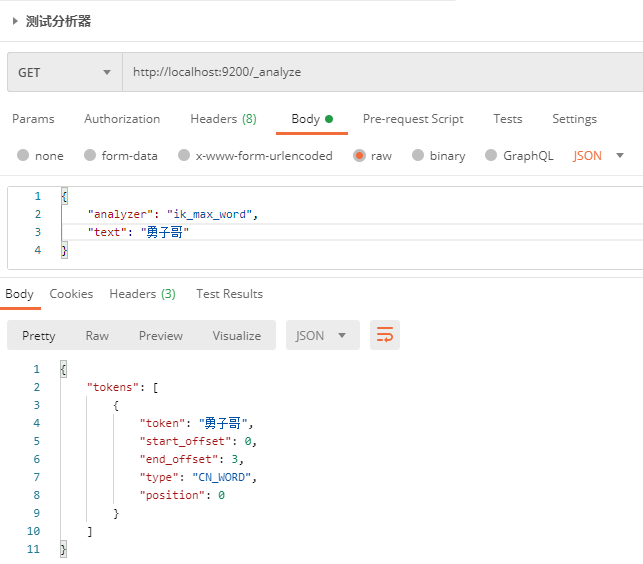
2.4.5 custom analyzer
Although Elasticsearch has some ready-made analyzers, the real strength of Elasticsearch is that it can create a custom analyzer by combining character filter, word separator and vocabulary unit filter in a specific data setting.
Send POST request to ES server: http://localhost:9200/my_custom, the request body is as follows:
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and "]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": ["the", "a", "an"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["&_to_and"],
"tokenizer": "standard",
"filter": ["my_stopwords"]
}
}
}
}
}
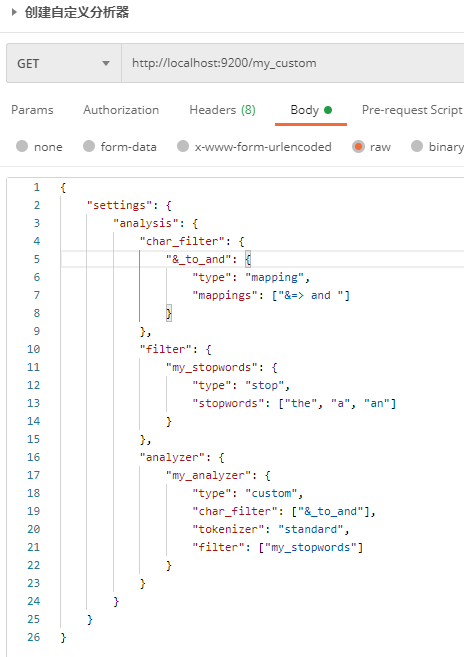
Send GET request to ES server: http://localhost:9200/my_custom to view the customized analyzer:
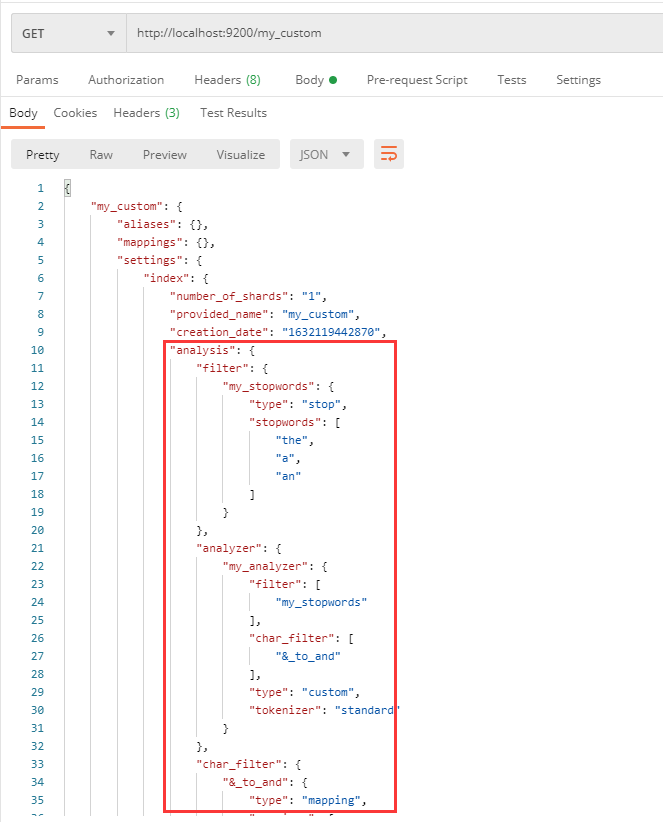
2.5 document processing
2.5.1 document conflict
When we use the index API to update the document, we can read the original document at one time, make our modifications, and then re index the whole document. The most recent index request will win: no matter which last document is indexed, it will be uniquely stored in Elasticsearch. If someone else changes this document at the same time, their changes will be lost.
Many times this is no problem. Maybe our master data store is a relational database. We just copy the data into elastic search and make it searchable. There may be little chance that two people will change the same document at the same time. Or the occasional loss of changes is not a serious problem for our business.
But sometimes losing a change is very serious. Imagine that we use Elasticsearch to store the inventory of goods in our online mall. Every time we sell a commodity, we reduce the inventory in Elasticsearch. One day, there will be a promotion. Suddenly, we have to sell several goods a second. Suppose there are two web programs running in parallel, each of which handles the sales of all goods at the same time:
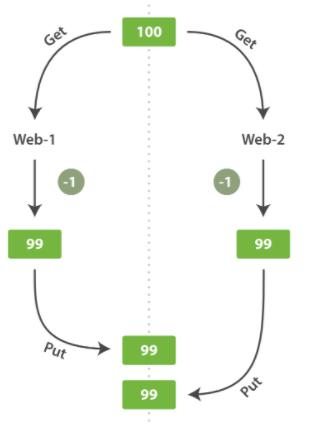
web_1 pair of stock_ The changes made by count have been lost because the web_2 don't know its stock_ The copy of count has expired. As a result, there will be oversold. The more frequent the changes, the longer the gap between reading data and updating data, and the more likely the changes will be lost.
In the database field, there are two methods commonly used to ensure that changes are not lost during concurrent updates:
1. Pessimistic concurrency control: this method is widely used in relational databases. It assumes that change conflicts may occur, so access to resources is blocked to prevent conflicts. A typical example is to lock a row of data before reading it, so as to ensure that only the thread placing the lock can modify this row of data;
2. Optimistic concurrency control: this method assumes that conflicts are impossible and will not block the attempted operation. However, if the source data is modified during reading and writing, the update will fail. The application will then decide how to resolve the conflict. For example, you can retry the update, use new data, or report the situation to the user.
2.5.2 optimistic concurrency control
Elasticsearch is distributed. When a document is created, updated, or deleted, the new version of the document must be copied to other nodes in the cluster. Elastic search is also asynchronous and concurrent, which means that these replication requests are sent in parallel and may be out of order when they arrive at the destination. Elasticsearch needs a way to ensure that the old version of the document does not overwrite the new version.
Each document has a_ Version number, which is incremented when the document is modified. Elastic search uses this version number to ensure that changes are executed in the correct order. If the old version of the document arrives after the new version, it can be simply ignored.
The version number can also be used to ensure that conflicting changes in the application will not cause data loss. This is achieved by specifying the version number of the document you want to modify. If the version is not the current version number, the request will fail.
Send PUT request to es server: http://localhost:9200/test_index_01/_doc/1?version=12, update the version by specifying the version, but the new version of ES no longer supports this usage, and an error will be reported:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-ntv0zqem-1637994003665)( https://i.loli.net/2021/11/27/lx5Sda4NTAYLyzE.png )]
The new version of ES uses if_seq_no and if_primary_term instead of version, send a PUT request to the ES server: http://localhost:9200/test_ index_ 01/_ doc/1? if_seq_no=21&if_primary_term = 16, as long as if_seq_no and if_ primary_ If term matches the document to be updated, the document will be updated successfully, otherwise it will not be updated.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-h7gav3dy-1637994003666)( https://i.loli.net/2021/11/27/dsjzngwu8tiCM6p.png )]
2.5.3 version control of external system
A common setting is to use other databases as the main data storage and Elasticsearch for data retrieval, which means that all changes to the main database need to be copied to Elasticsearch. If multiple processes are responsible for this data synchronization, they may encounter concurrency problems such as loss of updates.
If the master database already has a version number or a field value that can be used as a version number, such as timestamp, you can add version in elastic search_ Reuse these same version numbers by type = external to the query string. The version number must be an integer greater than zero and less than 9.2E+18.
The processing method of the external version number is somewhat different from that of the previous internal version number. Elasticsearch does not check the current version number_ Whether the version and the version number specified in the request are the same, but check the current version
_ Whether version is less than the specified version number. If the request is successful, the external version number is used as the new version of the document_ Version.
Send PUT request to es server: http://localhost:9200/test_ index_ 01/_ doc/1? version=12&version_ Type = external, as long as the external version number is greater than the version number of ES_ Version, the document will be updated, and the external version number will be the latest version of the document_ version.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-ulxnqybk-1637994003667)( https://i.loli.net/2021/11/27/wUQ1BCjELoh8rsW.png )]
3 Elasticsearch integration
3.1 Spring Data Elasticsearch
Spring Data for Elasticsearch is part of the Spring Data project, which aims to provide a familiar and consistent spring based programming model for new data storage, while retaining storage specific features and functions.
The Spring Data Elasticsearch project provides integration with the Elasticsearch search search engine. The key functional area of Spring Data Elasticsearch is the POJO centered model, which is used to interact with Elasticsearch documents and easily write a Repository style data access layer.
1. Create project
Create maven project and import related dependencies into pom file:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.6.RELEASE</version>
<relativePath/>
</parent>
<groupId>com.jidi.test</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>1.0.0-SNAPSHOT</version>
<name>spring-data-elasticsearch</name>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<!--elasticsearch-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!--jdbc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!--test-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.2</version>
<dependencies>
<!--Configure dependent database drivers-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
</dependencies>
<configuration>
<!--generator Profile directory-->
<configurationFile>${basedir}/src/main/resources/generatorConfig/generatorConfig.xml</configurationFile>
<overwrite>true</overwrite>
<verbose>true</verbose>
</configuration>
</plugin>
</plugins>
</build>
</project>
2. Add profile
application.yml is configured as follows:
server:
port: 8081
# Log related configuration
logging:
level:
com:
jidi:
test:
elasticsearch:
domain:
mapper: debug
level.root: INFO
# Log profile
config: classpath:logback-spring.xml
file:
max-size: 256MB
name: ${user.home}/work/logs/spring-data-elasticsearch.log
spring:
profiles:
active: dev #Configure environment as development environment
datasource:
name: db
url: jdbc:mysql://localhost:3306/mlxg?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: root
password: 123456
hikari:
connection-timeout: 60000
validation-timeout: 3000
idle-timeout: 60000
login-timeout: 5
max-lifetime: 60000
maximum-pool-size: 10
minimum-idle: 10
read-only: false
# elasticsearch related configurations
elasticsearch:
rest:
uris: localhost:9200
read-timeout: 30s
connection-timeout: 5s
# mybatis related configuration
mybatis:
mapper-locations: classpath*:mapper/*Mapper.xml
type-aliases-package: com.jidi.test.elasticsearch.domain.model
configuration:
call-setters-on-nulls: true
# Turn on hump mapping
map-underscore-to-camel-case: true
The log file logback-spring.xml is configured as follows:
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<!--<include resource="org/springframework/boot/logging/logback/base.xml"/>-->
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<property name="LOG_FILE" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/spring.log}"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread][%X{requestId}][%X{traceId}] %-5level %logger{36} - %msg%n</pattern>
</encoder>
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
</appender>
<springProfile name="dev,uat,docker">
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
</root>
</springProfile>
<springProfile name="test, prod">
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
</root>
</springProfile>
</configuration>
Mybatis generator configuration file generatorConfig.xml configuration:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<!-- Configuration Generator -->
<generatorConfiguration>
<context id="MysqlTables" targetRuntime="MyBatis3">
<commentGenerator>
<property name="suppressDate" value="true"/>
<!-- Remove automatically generated comments true: Yes: false:no -->
<property name="suppressAllComments" value="true"/>
</commentGenerator>
<!-- Database link URL,User name and password -->
<jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/mlxg?serverTimezone=GMT%2B8"
userId="root" password="123456">
</jdbcConnection>
<!-- Type conversion -->
<javaTypeResolver>
<!-- Whether to use BigDecimals,false The following types can be automatically converted(Long Integer Short etc.) -->
<property name="forceBigDecimals" value="false"/>
</javaTypeResolver>
<!-- Package name and location of the build model-->
<javaModelGenerator targetPackage="com.jidi.test.elasticsearch.domain.model" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
<property name="trimStrings" value="true"/>
</javaModelGenerator>
<!-- Package name and location of the generated mapping file-->
<sqlMapGenerator targetPackage="mapper" targetProject="src/main/resources">
<property name="enableSubPackages" value="true"/>
</sqlMapGenerator>
<!-- generate DAO Package name and location of -->
<javaClientGenerator type="XMLMAPPER" targetPackage="com.jidi.test.elasticsearch.domain.mapper" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
</javaClientGenerator>
<!-- Table to generate tableName Is the name of a table or view in the database domainObjectName Is the entity class name-->
<table tableName="item" domainObjectName="Item" enableCountByExample="false" enableUpdateByExample="false"
enableDeleteByExample="false" enableSelectByExample="false" selectByExampleQueryId="false">
<property name="useActualColumnNames" value="false"/>
<!-- Database table primary key -->
<generatedKey column="id" sqlStatement="Mysql" identity="true"/>
</table>
</context>
</generatorConfiguration>
If mybatis generator config_ 1_ 0.dtd file failed to load. You can create it manually. The file contents are as follows:
<?xml version="1.0" encoding="UTF-8"?>
<!--
Copyright 2006-2019 the original author or authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!--
This DTD defines the structure of the MyBatis generator configuration file.
Configuration files should declare the DOCTYPE as follows:
<!DOCTYPE generatorConfiguration PUBLIC
"-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
Please see the documentation included with MyBatis generator for details on each option
in the DTD. You may also view documentation on-line here:
http://www.mybatis.org/generator/
-->
<!--
The generatorConfiguration element is the root element for configurations.
-->
<!ELEMENT generatorConfiguration (properties?, classPathEntry*, context+)>
<!--
The properties element is used to define a standard Java properties file
that contains placeholders for use in the remainder of the configuration
file.
-->
<!ELEMENT properties EMPTY>
<!ATTLIST properties
resource CDATA #IMPLIED
url CDATA #IMPLIED>
<!--
The context element is used to describe a context for generating files, and the source
tables.
-->
<!ELEMENT context (property*, plugin*, commentGenerator?, (connectionFactory | jdbcConnection), javaTypeResolver?,
javaModelGenerator, sqlMapGenerator?, javaClientGenerator?, table+)>
<!ATTLIST context id ID #REQUIRED
defaultModelType CDATA #IMPLIED
targetRuntime CDATA #IMPLIED
introspectedColumnImpl CDATA #IMPLIED>
<!--
The connectionFactory element is used to describe the connection factory used
for connecting to the database for introspection. Either connectionFacoty
or jdbcConnection must be specified, but not both.
-->
<!ELEMENT connectionFactory (property*)>
<!ATTLIST connectionFactory
type CDATA #IMPLIED>
<!--
The jdbcConnection element is used to describe the JDBC connection that the generator
will use to introspect the database.
-->
<!ELEMENT jdbcConnection (property*)>
<!ATTLIST jdbcConnection
driverClass CDATA #REQUIRED
connectionURL CDATA #REQUIRED
userId CDATA #IMPLIED
password CDATA #IMPLIED>
<!--
The classPathEntry element is used to add the JDBC driver to the run-time classpath.
Repeat this element as often as needed to add elements to the classpath.
-->
<!ELEMENT classPathEntry EMPTY>
<!ATTLIST classPathEntry
location CDATA #REQUIRED>
<!--
The property element is used to add custom properties to many of the generator's
configuration elements. See each element for example properties.
Repeat this element as often as needed to add as many properties as necessary
to the configuration element.
-->
<!ELEMENT property EMPTY>
<!ATTLIST property
name CDATA #REQUIRED
value CDATA #REQUIRED>
<!--
The plugin element is used to define a plugin.
-->
<!ELEMENT plugin (property*)>
<!ATTLIST plugin
type CDATA #REQUIRED>
<!--
The javaModelGenerator element is used to define properties of the Java Model Generator.
The Java Model Generator builds primary key classes, record classes, and Query by Example
indicator classes.
-->
<!ELEMENT javaModelGenerator (property*)>
<!ATTLIST javaModelGenerator
targetPackage CDATA #REQUIRED
targetProject CDATA #REQUIRED>
<!--
The javaTypeResolver element is used to define properties of the Java Type Resolver.
The Java Type Resolver is used to calculate Java types from database column information.
The default Java Type Resolver attempts to make JDBC DECIMAL and NUMERIC types easier
to use by substituting Integral types if possible (Long, Integer, Short, etc.)
-->
<!ELEMENT javaTypeResolver (property*)>
<!ATTLIST javaTypeResolver
type CDATA #IMPLIED>
<!--
The sqlMapGenerator element is used to define properties of the SQL Map Generator.
The SQL Map Generator builds an XML file for each table that conforms to MyBatis'
SQL Mapper DTD.
-->
<!ELEMENT sqlMapGenerator (property*)>
<!ATTLIST sqlMapGenerator
targetPackage CDATA #REQUIRED
targetProject CDATA #REQUIRED>
<!--
The javaClientGenerator element is used to define properties of the Java client Generator.
The Java Client Generator builds Java interface and implementation classes
(as required) for each table.
If this element is missing, then the generator will not build Java Client classes.
-->
<!ELEMENT javaClientGenerator (property*)>
<!ATTLIST javaClientGenerator
type CDATA #IMPLIED
targetPackage CDATA #REQUIRED
targetProject CDATA #REQUIRED>
<!--
The table element is used to specify a database table that will be the source information
for a set of generated objects.
-->
<!ELEMENT table (property*, generatedKey?, domainObjectRenamingRule?, columnRenamingRule?, (columnOverride | ignoreColumn | ignoreColumnsByRegex)*) >
<!ATTLIST table
catalog CDATA #IMPLIED
schema CDATA #IMPLIED
tableName CDATA #REQUIRED
alias CDATA #IMPLIED
domainObjectName CDATA #IMPLIED
mapperName CDATA #IMPLIED
sqlProviderName CDATA #IMPLIED
enableInsert CDATA #IMPLIED
enableSelectByPrimaryKey CDATA #IMPLIED
enableSelectByExample CDATA #IMPLIED
enableUpdateByPrimaryKey CDATA #IMPLIED
enableDeleteByPrimaryKey CDATA #IMPLIED
enableDeleteByExample CDATA #IMPLIED
enableCountByExample CDATA #IMPLIED
enableUpdateByExample CDATA #IMPLIED
selectByPrimaryKeyQueryId CDATA #IMPLIED
selectByExampleQueryId CDATA #IMPLIED
modelType CDATA #IMPLIED
escapeWildcards CDATA #IMPLIED
delimitIdentifiers CDATA #IMPLIED
delimitAllColumns CDATA #IMPLIED>
<!--
The columnOverride element is used to change certain attributes of the column
from their default values.
-->
<!ELEMENT columnOverride (property*)>
<!ATTLIST columnOverride
column CDATA #REQUIRED
property CDATA #IMPLIED
javaType CDATA #IMPLIED
jdbcType CDATA #IMPLIED
typeHandler CDATA #IMPLIED
isGeneratedAlways CDATA #IMPLIED
delimitedColumnName CDATA #IMPLIED>
<!--
The ignoreColumn element is used to identify a column that should be ignored.
No generated SQL will refer to the column, and no property will be generated
for the column in the model objects.
-->
<!ELEMENT ignoreColumn EMPTY>
<!ATTLIST ignoreColumn
column CDATA #REQUIRED
delimitedColumnName CDATA #IMPLIED>
<!--
The ignoreColumnsByRegex element is used to identify a column pattern that should be ignored.
No generated SQL will refer to the column, and no property will be generated
for the column in the model objects.
-->
<!ELEMENT ignoreColumnsByRegex (except*)>
<!ATTLIST ignoreColumnsByRegex
pattern CDATA #REQUIRED>
<!--
The except element is used to identify an exception to the ignoreColumnsByRegex rule.
If a column matches the regex rule, but also matches the exception, then the
column will be included in the generated objects.
-->
<!ELEMENT except EMPTY>
<!ATTLIST except
column CDATA #REQUIRED
delimitedColumnName CDATA #IMPLIED>
<!--
The generatedKey element is used to identify a column in the table whose value
is calculated - either from a sequence (or some other query), or as an identity column.
-->
<!ELEMENT generatedKey EMPTY>
<!ATTLIST generatedKey
column CDATA #REQUIRED
sqlStatement CDATA #REQUIRED
identity CDATA #IMPLIED
type CDATA #IMPLIED>
<!--
The domainObjectRenamingRule element is used to specify a rule for renaming
object domain name before the corresponding domain object name is calculated
-->
<!ELEMENT domainObjectRenamingRule EMPTY>
<!ATTLIST domainObjectRenamingRule
searchString CDATA #REQUIRED
replaceString CDATA #IMPLIED>
<!--
The columnRenamingRule element is used to specify a rule for renaming
columns before the corresponding property name is calculated
-->
<!ELEMENT columnRenamingRule EMPTY>
<!ATTLIST columnRenamingRule
searchString CDATA #REQUIRED
replaceString CDATA #IMPLIED>
<!--
The commentGenerator element is used to define properties of the Comment Generator.
The Comment Generator adds comments to generated elements.
-->
<!ELEMENT commentGenerator (property*)>
<!ATTLIST commentGenerator
type CDATA #IMPLIED>
The structure of the whole project configuration file is as follows:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-2j4wrykr-1637994003668)( https://i.loli.net/2021/11/27/SOmiWrF6xGhYfLZ.png )]
3. Use the mybatis generator plug-in to automatically generate dao, mapper, and model.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-1txcfxlq-1637994003669)( https://i.loli.net/2021/11/27/e46A5DrmaYviKGL.png )]
4. Create ES interactive entity
package com.jidi.test.elasticsearch.domain.model;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.*;
import java.util.Date;
/**
* @Description
* @Author jidi
* @Email jidi_jidi@163.com
* @Date 2021/9/20
*/
@Data
@Document(indexName = "product", shards = 3, replicas = 1, createIndex = true)
public class Product {
@Id
private Long id;
@MultiField(mainField = @Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word" ),
otherFields = @InnerField(type = FieldType.Keyword, suffix = "keyword"))
private String name;
private Long brandId;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String type;
private String measurementUnit;
private String purchaseCondition;
@MultiField(mainField = @Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word" ),
otherFields = @InnerField(type = FieldType.Keyword, suffix = "keyword"))
private String tagsJson;
private Boolean check;
@MultiField(mainField = @Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word" ),
otherFields = @InnerField(type = FieldType.Keyword, suffix = "keyword"))
private String desc;
private String photoJson;
private Long categoryId;
private Long companyId;
private Long enterpriseId;
private Date upShelfTime;
private Byte status;
private String refusedReason;
private String refusedAttach;
private String commonAttributesJson;
private String customAttributesJson;
private Date createdAt;
private Date updatedAt;
private String customSalesAttributeJson;
private String salesAttributeJson;
@Override
public String toString() {
return "Product{" +
"id=" + id +
", name='" + name + '\'' +
", brandId=" + brandId +
", type='" + type + '\'' +
", measurementUnit='" + measurementUnit + '\'' +
", purchaseCondition='" + purchaseCondition + '\'' +
", tagsJson='" + tagsJson + '\'' +
", check=" + check +
", desc='" + desc + '\'' +
", photoJson='" + photoJson + '\'' +
", categoryId=" + categoryId +
", companyId=" + companyId +
", enterpriseId=" + enterpriseId +
", upShelfTime=" + upShelfTime +
", status=" + status +
", refusedReason='" + refusedReason + '\'' +
", refusedAttach='" + refusedAttach + '\'' +
", commonAttributesJson='" + commonAttributesJson + '\'' +
", customAttributesJson='" + customAttributesJson + '\'' +
", createdAt=" + createdAt +
", updatedAt=" + updatedAt +
", customSalesAttributeJson='" + customSalesAttributeJson + '\'' +
", salesAttributeJson='" + salesAttributeJson + '\'' +
'}';
}
}
5. Create Repository interaction object
The strength of Spring Data is that you don't need to write any DAO processing, and automatically perform CRUD operations according to the method name or class information. As long as you define an interface and inherit some sub interfaces provided by the Repository, you can have various basic crud functions.
package com.jidi.test.elasticsearch.domain.repository;
import com.jidi.test.elasticsearch.domain.model.Product;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
/**
* @Description
* @Author jidi
* @Email jidi_jidi@163.com
* @Date 2021/9/20
*/
@Repository
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {
}
6. Testing
package com.jidi.test.elasticsearch;
import com.jidi.test.elasticsearch.domain.mapper.ItemMapper;
import com.jidi.test.elasticsearch.domain.model.Item;
import com.jidi.test.elasticsearch.domain.model.Product;
import com.jidi.test.elasticsearch.domain.repository.ProductRepository;
import org.apache.ibatis.session.SqlSessionFactory;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.junit.jupiter.api.Test;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Optional;
@SpringBootTest
class SpringDataElasticsearchApplicationTests {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Autowired
private ProductRepository productRepository;
@Autowired
private ItemMapper itemMapper;
/**
* Create index
*/
@Test
void createIndex(){
boolean success = elasticsearchRestTemplate.createIndex(Product.class);
if(success){
System.out.println("Index creation succeeded!");
}
}
/**
* Delete index
*/
@Test
void deleteIndex(){
boolean success = elasticsearchRestTemplate.deleteIndex(Product.class);
if(success){
System.out.println("Index deleted successfully!");
}
}
/**
* newly added
*/
@Test
void insert(){
Product product = new Product();
product.setId(1L);
product.setName("Commodity information");
product.setType("Commodity type");
product.setTagsJson("Commodity label");
product.setDesc("Product description information");
productRepository.save(product);
}
/**
* Modify (there is modification but no addition)
*/
@Test
void update(){
Product product = new Product();
product.setId(1L);
product.setName("Product information 12");
product.setType("Commodity type 12");
product.setTagsJson("Product label 12");
product.setDesc("Product description information 12");
productRepository.save(product);
}
/**
* Batch add
*/
@Test
void batchInsert() {
List<Item> itemList = itemMapper.select();
List<Product> productList = new ArrayList<>(itemList.size());
itemList.forEach(item -> {
Product product = new Product();
product.setId(item.getId());
product.setName(item.getName());
product.setType(item.getType());
product.setTagsJson(item.getTagsJson());
product.setDesc(item.getDesc());
productList.add(product);
});
productRepository.saveAll(productList);
}
/**
* Delete data
*/
@Test
void delete(){
productRepository.deleteById(1L);
}
/**
* Query all
*/
@Test
void selectAll(){
// Sort descending by id
Iterable<Product> products = productRepository.findAll(Sort.by(Sort.Direction.DESC, "id"));
products.forEach(product -> System.out.println(product));
}
/**
* Query by id
*/
@Test
void selectById(){
Optional<Product> productOptional = productRepository.findById(1L);
System.out.println(productOptional.get());
}
/**
* Query by criteria
*/
@Test
void selectByCondition(){
Pageable pageable = PageRequest.of(0, 100);
MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("name", "floret");
Page<Product> productPage = productRepository.search(matchQueryBuilder, pageable);
productPage.forEach(System.out::println);
}
}
4. Elasticsearch optimization
4.1 hardware selection
Elasticsearch is based on Lucene. All index and document data are stored on local disks. The specific path can be configured in the ES configuration file.. / config/elasticsearch.yml, as follows:

Elasticsearch heavily uses disks. The greater the throughput that disks can handle, the more stable the node will be. Disk I/O can be optimized by:
1. SSD (solid state disk) is used. Compared with mechanical hard disk, SSD has faster reading and writing speed;
2. Use multiple hard disks and allow Elasticsearch to allocate data striping to them through multiple path.data directory configurations;
4.2 slicing strategy
Reasonably set the number of slices
The design of sharding and replica provides ES with the characteristics of supporting distribution and failover, but it does not mean that sharding and replica can be allocated indefinitely. Moreover, after the partition of the index is allocated, the number of partitions cannot be modified due to the routing mechanism of the index.
There is a price for fragmentation in Elasticsearch:
1. The underlying layer of a partition is a Lucene index, which will consume a certain file handle, memory and CPU;
2. Each search request needs to hit each partition of the index. If multiple partitions need to compete on the same node, the performance will be affected;
3. The word item statistics used to calculate the correlation degree are based on slices. If there are many slices, each slice has only a small amount of data, and the correlation degree of the response will be low;
4. The number of nodes needs to be considered. If the number of partitions is too large, which greatly exceeds the number of nodes, multiple partitions may exist on a node. Once the node fails, qualitative data may be lost and the cluster cannot recover.
Delayed allocation fragmentation
For the problem of instantaneous interruption of nodes, by default, the cluster will wait one minute to check whether the node will rejoin. If the node rejoins during this period, the rejoined node will maintain its existing partition data and will not trigger new partition allocation. This can reduce the huge overhead of ES in automatically rebalancing available fragments.
By modifying the parameter dalayed_timeout, which can extend the rebalancing time, can be set globally or at the index level. Send PUT request to ES server: http://localhost:9200/_all/_settings, the request body is as follows:
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "3m"
}
}
4.3 routing
ES determines the partition on which the document should be stored according to the result of routing calculation. Routing calculation formula:
s
h
a
r
d
=
h
a
s
h
(
r
o
u
t
i
n
g
)
%
n
u
m
b
e
r
_
o
f
_
p
r
i
m
a
r
y
_
s
h
a
r
d
s
shard = hash(routing) \% number\_of\_primary\_shards
shard=hash(routing)%number_of_primary_shards
routing is a variable value. By default, it is the id of the document. It can also be set to a user-defined value.
The query can be divided into two types according to whether it contains routing:
1. Query without routing: the whole process is divided into two steps because you don't know which slice the data to be queried is on:
a. distribution: after the request reaches the coordination node, the coordination node distributes the query request to each partition;
b. aggregation: the coordination node collects the query results on each slice, sorts the query results, and then returns the results to the user.
2. Query with routing: when querying, you can directly locate an allocation query according to the routing information. You do not need to query all the allocations, but sort through the coordination node.
4.4 write speed optimization
The default configuration of ES integrates data reliability, writing speed, real-time search and other factors. In practical use, biased optimization can be carried out.
For scenarios with low search performance requirements but high write requirements, appropriate write optimization strategies should be selected as far as possible:
1. Increase Translog Flush;
2. Increase the index Refresh interval and reduce the number of segment merging;
3. Adjust the Bulk thread pool and queue
4.4.1 batch submission of data
ES provides Bulk API to support batch operations. When there are a large number of write tasks, Bulk can be used for batch writing.
The general policy is as follows: the volume of data submitted in batch cannot exceed 100M by default. The number of data pieces is generally determined according to the size of the document and the performance of the server, but the data size of a single batch should gradually increase from 5MB to 15MB. When the performance is not improved, take this data amount as the maximum.
4.4.2 reasonable use and consolidation
Lucene stores data in segments. When new data is written to the index, Lucene will automatically create a new segment. As the amount of data changes, the number of segments will increase, the number of file handles and CPU consumed will increase, and the query efficiency will decrease.
Because Lucene segment merging requires a large amount of computation and consumes a large amount of I/O, ES adopts a more conservative strategy by default to allow the background to merge segments regularly
4.4.3 reduce Refresh times
When Lucene adds data, it adopts the strategy of delayed writing. By default, the index is refreshed_ The interval is 1 second. Lucene writes the data to be written to memory first. When it exceeds 1 second (default), Refresh will be triggered once, and then Refresh will Refresh the data in memory to the file cache system of the operating system.
If the effectiveness of the search is not high, you can extend the Refresh cycle, for example, 30 seconds. This can effectively reduce the number of segment refreshes, but it also means that more Heap memory needs to be consumed.
4.4.4 increase Flush
The main purpose of Flush is to persist the segments in the file cache system to the hard disk. When the data volume of Translog reaches 512MB or 30 minutes, Flush will be triggered once. index.Translog.Flush_ threshold_ The default value of the size parameter is 512MB. Increasing the parameter value means that more data may need to be stored in the file cache system, so enough space needs to be left for the file cache system of the operating system.
4.4.5 reduce the number of copies
In order to ensure the availability of the cluster, ES provides replica support. However, each replica will also perform analysis, indexing and possible merging processes. Therefore, the number of Replicas will seriously affect the efficiency of writing indexes. When writing an index, you need to synchronize the written data to the replica node. The more replica nodes, the slower the efficiency of writing an index.
4.5 memory settings
The default memory set after ES installation is 1GB. If the ES is installed by decompressing, include a jvm.option file in the ES installation file, and add the following commands to set the heap size of the es: Xms represents the initial size of the heap, Xmx represents the maximum memory that can be allocated, both of which are 1GB.
Ensure that the sizes of Xmx and Xms are the same. The purpose is to waste resources without re separating and calculating the size of the heap area after the Java garbage collection mechanism has cleaned up the heap area, so as to reduce the pressure caused by scaling the heap size.
The allocation of ES heap memory needs to meet the following two principles:
1. Do not exceed 50% of physical memory: Lucene is designed to cache the data in the underlying OS into memory. Lucene's segments are stored in a single file. These files will not change, so it is convenient for caching. At the same time, the operating system will cache these segment files for faster access. If the heap memory set is too large, Lucene's available memory will be reduced, which will seriously affect Lucene's full-text query performance.
2. The size of heap memory should not exceed 32GB.
4.6 single responsibility
By default, a node will act simultaneously: eligaible master node, coordinate node, data node and ingest node. In order to improve program performance, a node only plays one role.
| Node type | to configure |
|---|---|
| master node | node.master:true node.ingest:false node.data:false |
| data node | node.master:false node.ingest:false node.data:true |
| ingest node | node.master:false node.ingest:true node.data:false |
| coordinate node | node.master:false node.ingest:false node.data:false |
4.7 important configuration
| Parameter name | Parameter value | explain |
|---|---|---|
| cluster.name | elasticsearch | The name of the es cluster is elasticsearch by default. es will automatically discover nodes with the same cluster name under the same network segment. |
| node.name | node_001 | Node name. The node name of the same cluster cannot be duplicate. Once the node name is set, it cannot be changed. |
| node.master | true | Specifies whether the node is eligible to be elected as a Master. The default is true. |
| node.data | true | Specify whether the node stores index data. The default value is true. Data addition, deletion, modification and query are all completed in the data node. |
| index.number_of_shards | 1 | Number of index slices. |
| index.number_of_replcas | 1 | Number of index copies. |
| transport.tcp.compress | true | Whether to compress data transmission between nodes. It is not compressed by default. |
| discovery.zen.minimum_master_nodes | 1 | Set the minimum number of candidate Master nodes to participate in the election of Master nodes. The default value is 1. When the default value is used, brain fissure may occur when the network is unstable. The reasonable value is: number of candidate main nodes / 2 + 1 |
| discovery.zen.ping.timeout | 3s | Set the timeout of Ping connection when automatically discovering other nodes in the cluster. The default is 3 seconds. |
5. References
https://doc.codingdict.com/elasticsearch/125/