Learn the second of the notes made by Elasticsearch.
catalogue
2, Comparison and selection of Solr and elasticsearch.
3. Applicable scenarios and comparison of Solr and elasticsearch.
4, Understanding of ES core concepts.
1. Comparison between ES and relational database.
2. ES physical design, logic design.
1. Why do I need an IK word breaker.
2. Install the IK word breaker.
4. Customize thesaurus and configure IK extended dictionary.
2. elasticsearch basic Rest command.
2. Common field types of Elasticsearch.
3. Manually specify the type of field.
4. To view the default information, ES automatically configures the field type by default.
8, Basic operations on documents.
2. Use GET to query data and obtain data.
(1) Query according to a field.
(6) The filter queries the data.
(7) Match multiple criteria queries.
(9) Multiple values match an exact query.
1, elasticsearch overview.
Elastic search, abbreviated as es, is an open source and highly extended distributed full-text retrieval engine, which stores and retrieves data in near real time. It can be extended to hundreds of servers to process PB level data. Using Lucene as the core to realize all indexing and search functions, hide the complexity of Lucene through a simple restful api, and make full-text search simple.
Elasticsearch is a real-time distributed search and analysis engine.
2, Comparison and selection of Solr and elasticsearch.
1. solr overview.
Solr is a top open source project under Apache. It is developed in java. The full-text search server based on Lucene encapsulates Lucene. Solr provides a richer query language than Lucene, which is configurable and extensible, and optimizes the index and search performance.
Solr can run in containers such as jetty and Tomcat.
Solr generates an index and uses the post method to send an xml document describing the field and its contents to the Solr server. Solr adds, deletes and updates the index according to the xml document.
Search, find, send http get request, parse the query results in xml, json and other formats returned by solr, and organize the page layout.
2. Lucene overview.
Lucene is a sub project of Apache Software Foundation. It is an open source full-text search engine toolkit. It provides developers with a simple and easy-to-use toolkit. It is the architecture of a full-text search engine and provides a complete query engine and index engine.
3. Applicable scenarios and comparison of Solr and elasticsearch.
(1) solr is faster when searching existing and existing data.
(2) When establishing indexes in real time, solr will cause io congestion and poor query performance. Elastic search has obvious advantages.
(3) With the increase of data volume, the search efficiency of solr will become lower, while elastic search has no obvious change.
(4) Elasticsearch is available out of the box and can be decompressed. solr installation is a little complicated.
(5) Solr uses zookeeper for distributed management, while elastic search itself has distributed coordination function.
(6) Data formats supported by Solr, such as json, xml and CSV. Elasticsearch supports json data format.
(7) There are many functions officially provided by Solr. Elasticsearch focuses on core functions and can extend advanced functions through third-party plug-ins. For example, kibana provides a graphical interface.
(8) Solr query is fast, and updating index is slow during insertion and deletion. Elasticsearch is fast in indexing and real-time query.
4,elasticsearch-head.
elasticsearch interface tool is generally used to view data records.
Download address: https://github.com/mobz/elasticsearch-head/
Installation and startup commands:
cd elasticsearch-head
npm install
npm run start
elasticsearch-7.15.0\config\elasticsearch.yml
Add content to address cross domain access.
http.cors.enabled: true
http.cors.allow-origin: "*"
3, Kibana overview.
1. kibana overview.
Kibana is an open source analysis and visualization platform for elasticsearch, which is used to search and view the data interactively stored in the elasticsearch index. Kibana can be used for advanced data analysis and display through various charts. Kibana makes massive data easy to understand. The operation is simple. Based on the browser user interface, you can quickly create a dashboard to display the dynamic of elasticsearch query in real time.
2. kibana is sinicized.
kibana-7.15.1\config
kibana.yml file, modify the configuration content.
i18n.locale: "zh-CN"
4, Understanding of ES core concepts.
1. Comparison between ES and relational database.
Relational database
| Database database | Elasticsearch |
| Database database | Index indexes |
| Table tables | types |
| Row rows | documents |
| Field columns | fields |
Elasticsearch cluster can contain multiple indexes (databases), each index can contain multiple types (tables), each type contains multiple documents (rows), and each document contains multiple fields (rows).
2. ES physical design, logic design.
Physical design.
Elastic search divides each index into multiple shards, and each shard is migrated between different servers in the cluster.
Logic design.
An index type contains multiple documents. Find a document, index -- > type -- > document ID.
document:
Elastic search is document oriented, and the smallest unit of indexing and searching data is document.
A document is a piece of data.
Type:
Types are logical containers for documents. Just like relational databases, tables are containers for rows.
The definition of fields in type is called mapping, and field type mapping. For example: name is mapped to a string type.
The document is modeless. ES can automatically identify the field type according to the data value, or manually define the mapping in advance.
Indexes:
When indexing, it is a container of mapping type. It is a very large collection of documents. The index stores the fields and other settings of mapping type. Is stored on each slice.
A cluster has at least one node, and one node is an elasticsearch process. When creating an index, there are five primary shard primary shards by default, and each primary shard will have a replica shard replica shard.
A fragment is a Lucene index and a file directory containing inverted indexes. The inverted index structure enables elastic search to know which documents contain specific keywords without scanning all documents.
Inverted index:
ES uses a structure called inverted index, which uses Lucene inverted index as the bottom layer. It is suitable for fast full-text search. An index consists of all non duplicate lists in the document. For each word, there is a document list containing it.
Create an inverted index, split each document into independent words (entries or tokens), create a sorted list containing all non duplicate entries, and then list which document each entry appears in.
5, IK word breaker plug-in.
1. Why do I need an IK word breaker.
Word segmentation: divide a paragraph of Chinese or English into keywords one by one. When searching, you will segment your own information, segment the data in the database or index library, and perform a matching operation.
The default Chinese word segmentation is to treat each Chinese character as a word.
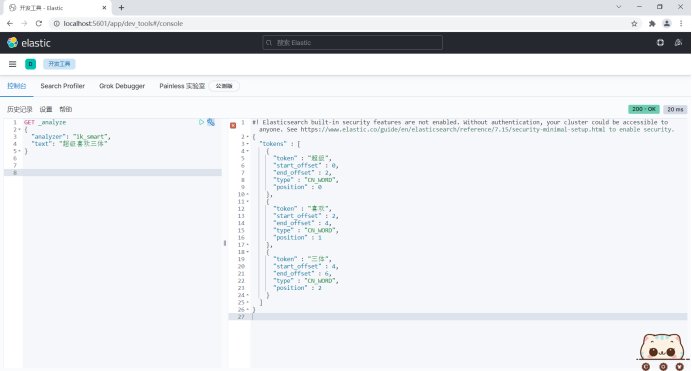
For example, "super like three bodies" will be divided into "super", "level", "joy", "joy", "three bodies".
GET _analyze
{
"text": "Super like trisomy"
} 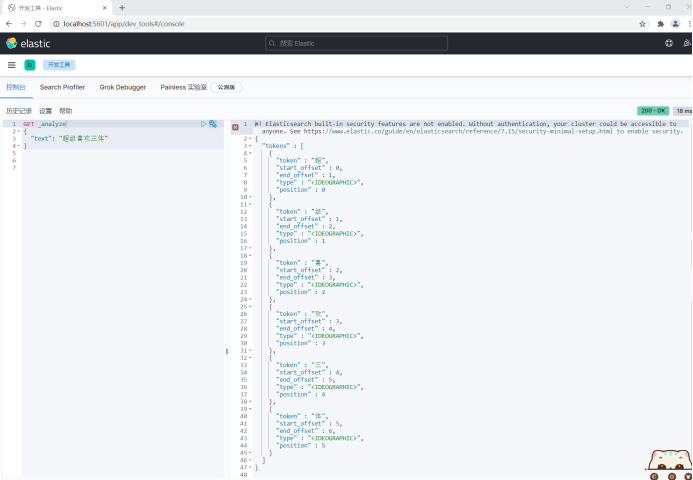
This does not meet the needs, so you need to install Chinese word splitter IK to solve this problem.
2. Install the IK word breaker.
IK download address: Releases · medcl/elasticsearch-analysis-ik · GitHub
Download the IK word breaker of the corresponding version of elasticsearch, and the version must correspond to it. Create a new IK folder in elasticsearch\plugins \ directory, extract it and copy it to the IK folder. Then restart ES.
For example, download the IK word breaker elasticsearch-analysis-ik-7.15.0.zip of elasticsearch-7.15.0
Check which plug-in commands ES has installed elasticsearch plugin list.
\elasticsearch-7.15.0\bin>elasticsearch-plugin list
3. Use the IK word breaker.
IK provides two word segmentation algorithms: ik_smart and ik_max_word.
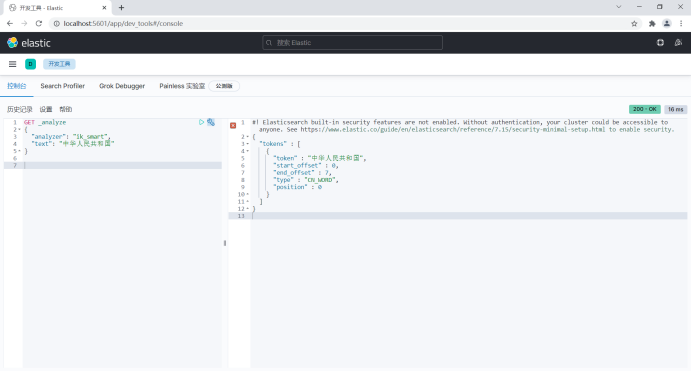
(1)ik_smart will do the coarsest granularity splitting, and the separated words will not be occupied by other words again. For the least segmentation, only one is cut at the most fine granularity. There is no duplicate data. Open it according to the breakpoint and type it into understandable words.
For example:
GET _analyze
{
"analyzer": "ik_smart",
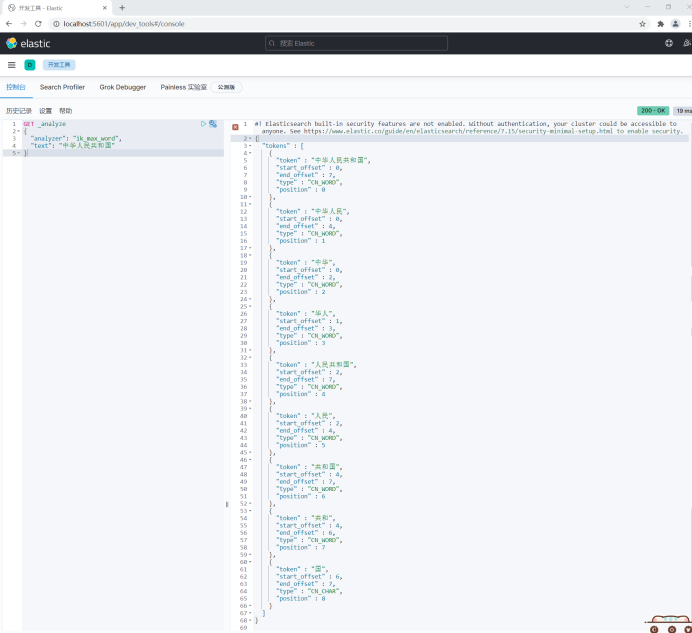
"text": "The People's Republic of China"
}
GET _analyze
{
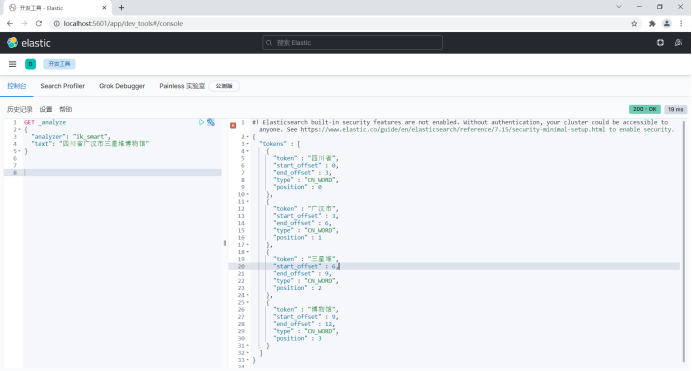
"analyzer": "ik_smart",
"text": "Sanxingdui Museum, Guanghan City, Sichuan Province"
}
(2)ik_max_word will split the text into the most fine-grained words as much as possible. For the most fine-grained division, exhaust the possibility of thesaurus and dictionary.
For example:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "The People's Republic of China"
} 
GET _analyze
{
"analyzer": "ik_max_word",
"text": "Sanxingdui Museum, Guanghan City, Sichuan Province"
} 
4. Customize thesaurus and configure IK extended dictionary.
If a word is taken apart and you don't want to take it apart, you need to add it to the dictionary of the word splitter.
For example:
GET _analyze
{
"analyzer": "ik_smart",
"text": "Super like trisomy"
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": "Super like trisomy"
}
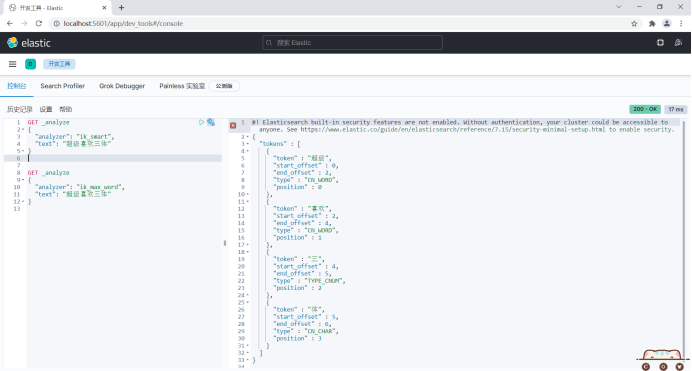
The word "Santi" has been taken apart. I don't want to take it apart. Add the word to the thesaurus.
In the \ elasticsearch-7.15.0\plugins\ik\config folder, create a new file zidingyi.dic with any name, and add the word "three bodies" in it.
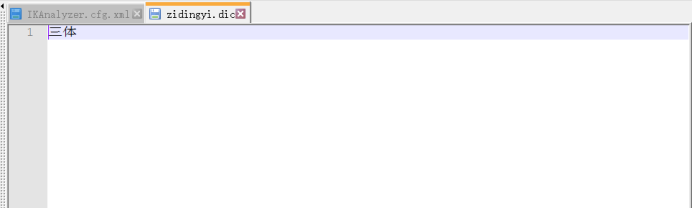
Configure this file in the IKAnalyzer.cfg.xml file.
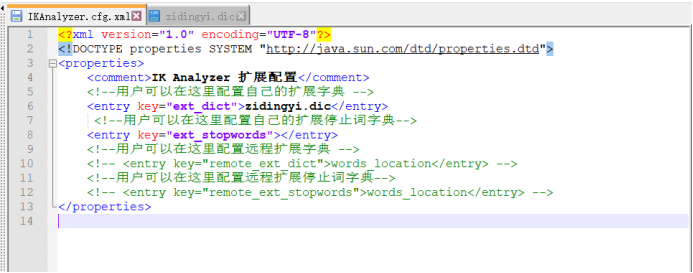
Restart elasticsearch.
The display effect is as follows. The display "three bodies" becomes a word.
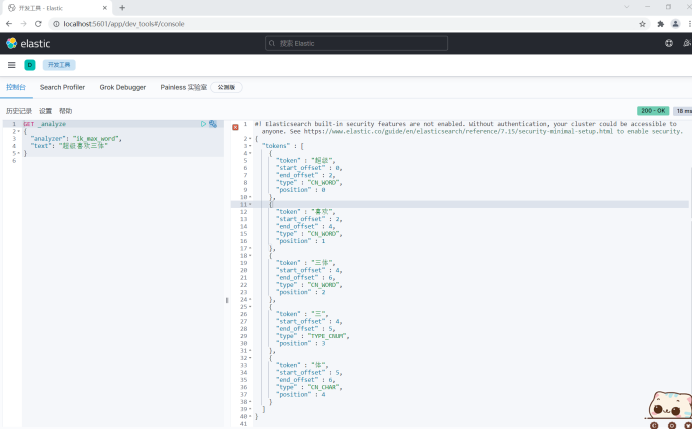
6, Rest style.
1. Overview of Rest style.
A software architecture style that provides a set of design principles and constraints. Not a standard. The software designed based on this style can be more concise, more hierarchical, and easy to implement caching and other mechanisms. It is mainly used for the program of client and server interaction class.
2. elasticsearch basic Rest command.
| Method | Address url | describe |
| PUT | Index name / type name / document id | Create a document and specify the document id. |
| POST | Index name / type name | Create a document with a random document id. |
| POST | Index name / type name / document id/_update | Modify the document. |
| POST | Index name / type name/_ search | Query all data. |
| DELETE | Index name / type name / document id | Delete document. |
| GET | Index name / type name / document id | Query the document by document id. |
7, Basic operations on index.
1. Create an index.
PUT / index name / type name / document id
8.0 removes the type name.
In version 5.X, multiple type s can be created under one index;
In version 6.X, only one type can exist under an index;
In version 7.X, the concept of type is directly removed, that is, index will no longer have type.
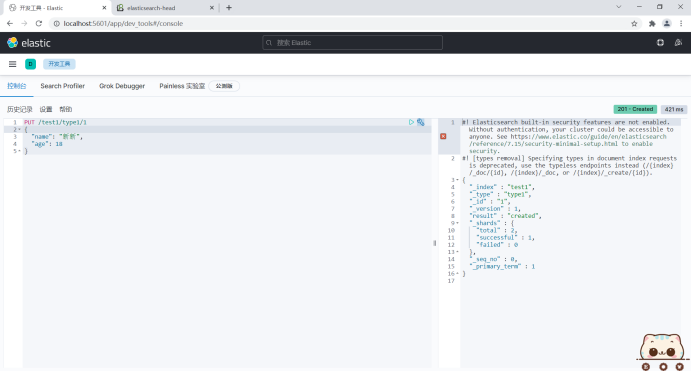
PUT /test1/type1/1
{
"name": "Xinxin",
"age": 18
} 
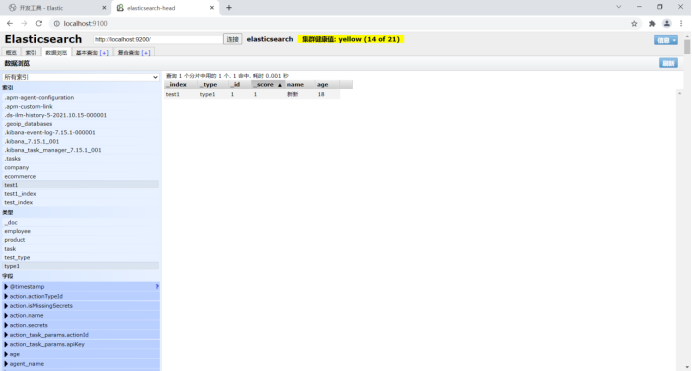
2. Common field types of Elasticsearch.
String type: text, keyword.
Value types: long, integer, short, byte, double, float, half, float, scaled, float.
Date type: date.
boolean value type: boolean.
Binary type: binary.
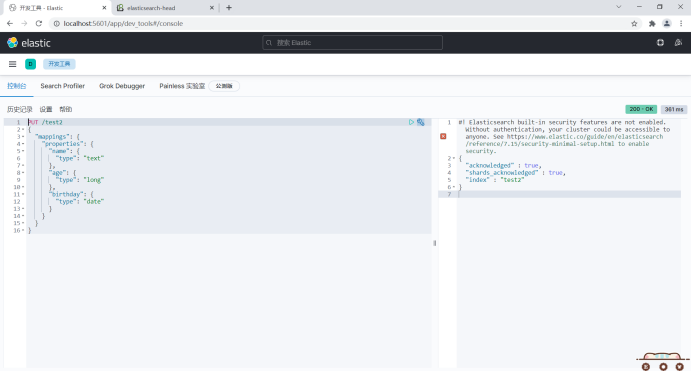
3. Manually specify the type of field.
For example:
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
View index details.
For example:
GET /test1
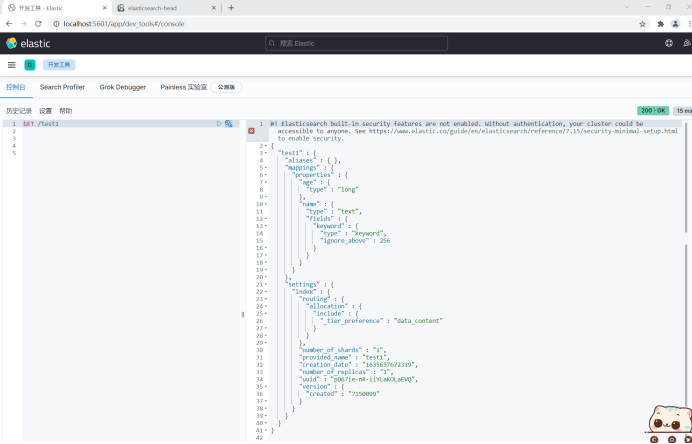
4. To view the default information, ES automatically configures the field type by default.
ES 8.0 discards type names. Type name defaults to_ doc.
If the document field type is not specified when creating a document, ES will configure the field type by default.
For example:
PUT /test3/_doc/1
{
"name": "Xinxin 1",
"age": 18,
"birth": "2021-10-31"
}View records.
GET /test3/_doc/1
View index information.
GET /test3
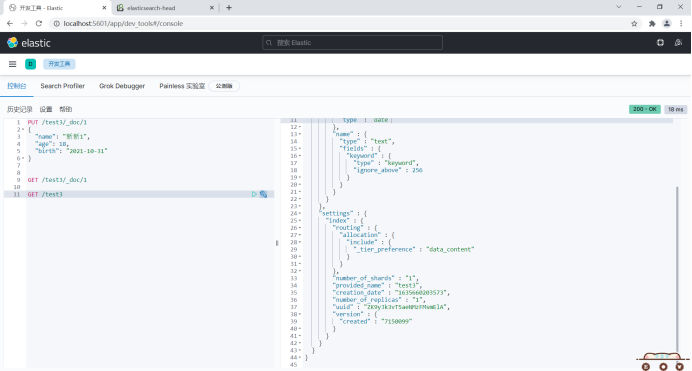
5. View ES information.
Use_ cat view ES information.
View ES health.
GET /_cat/health
View the ES index.
GET /_cat/indice
6. Modify the index.
Use PUT to overwrite data. All fields are required when overwriting. Otherwise, field data will be lost and a new document object will be generated.
PUT /test3/_doc/1
{
"name": "Xinxin 2",
"age": 18,
"birth": "2021-10-31"
}When you modify an index by POST, you can specify to modify a field, which will be displayed when you POST_ update.
POST /test3/_doc/1/_update
{
"doc": {
"name": "Xinxin 3"
}
}7. Delete index.
Use the DELETE command to DELETE.
Delete index.
DELETE /test1
Delete the document and delete the record.
DELETE /test3/_doc/1
8, Basic operations on documents.
1. Add data.
For example:
PUT /corp/user/1
{
"name": "Zhang San",
"age": 18,
"desc": "Outlaw maniac.",
"tags": ["make friends", "Travel", "Caring guy"]
}
PUT /corp/user/2
{
"name": "Li Si",
"age": 18,
"desc": "A meal is as fierce as a tiger. At a glance, the salary is 2500.",
"tags": ["technical nerd", "warm", "Straight man"]
}
PUT /corp/user/3
{
"name": "Wang Wu",
"age": 18,
"desc": "Last year I bought a watch.",
"tags": ["Pretty girl", "Travel", "sing"]
}
PUT /corp/user/4
{
"name": "Zhang Sanshan",
"age": 3,
"desc": "Crazy stone.",
"tags": ["make friends", "Travel", "Caring guy"]
}2. Use GET to query data and obtain data.
GET /corp/user/1
3. Update data.
Use PUT mode to overwrite the modified data.
For example:
PUT /corp/user/3
{
"name": "Wang Wu",
"age": 18,
"desc": "I bought a watch last year, bought a watch last year, bought a watch in, bought a watch, bought a watch, bought a watch, a watch, a watch, a watch.",
"tags": ["Pretty girl", "Travel", "sing"]
}It is recommended to modify data by POST. Need to bring_ update.
For example:
POST /corp/user/3/_update
{
"doc": {
"name": "Liu Liu"
}
}4. Simple search data.
(1) Simple search.
For example:
Query a record or a document.
GET /corp/user/3
Query all records.
GET /corp/user/_search
Query according to a field.
GET /corp/user/_search?q=name:Zhang
Query according to a field.
GET /corp/user/_search?q=name:Li Si
5. Complex search data.
(1) Query according to a field.
For example:
GET /corp/user/_search
{
"query": {
"match": {
"name": "Zhang San"
}
}
}return:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.4523083,
"hits" : [
{
"_index" : "corp",
"_type" : "user",
"_id" : "1",
"_score" : 1.4523083,
"_source" : {
"name" : "Zhang San",
"age" : 18,
"desc" : "Outlaw maniac.",
"tags" : [
"make friends",
"Travel",
"Caring guy"
]
}
},
{
"_index" : "corp",
"_type" : "user",
"_id" : "4",
"_score" : 1.2199391,
"_source" : {
"name" : "Zhang Sanshan",
"age" : 3,
"desc" : "Crazy stone.",
"tags" : [
"make friends",
"Travel",
"Caring guy"
]
}
}
]
}
}Response return resolution.
Hits includes: index and document information; Total quantity of query results; Specific documents queried; You can traverse the data.
_ Score score, degree of conformity with search results, matching degree.
(2) Specify the field query.
The query returns several fields and the results are filtered.
For example:
GET /corp/user/_search
{
"query": {
"match": {
"name": "Zhang San"
}
},
"_source": ["name", "desc"]
}(3) Query sorting.
sort, desc descending, asc ascending.
GET /corp/user/_search
{
"query": {
"match": {
"name": "Zhang San"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}(4) Paging query.
From starts the query from the first data, and the data subscript starts from 0. size how many records are displayed on each page and how many data are returned.
GET /corp/user/_search
{
"query": {
"match": {
"name": "Zhang San"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}(5) Boolean query.
- Multi conditional Boolean query.
Must, all conditions must be met, which is equivalent to and in sql.
For example:
GET /corp/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "Zhang San"
}
},
{
"match": {
"age": 3
}
}
]
}
}
}should, which is equivalent to or in sql.
GET /corp/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "Zhang San"
}
},
{
"match": {
"age": 3
}
}
]
}
}
}must_not, not equal to. All unqualified items are queried, which is equivalent to not in sql.
For example:
GET /corp/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "Zhang San"
}
},
{
"match": {
"age": 3
}
}
]
}
}
}(6) The filter queries the data.
Query records that match a certain interval.
gt: greater than.
lt: less than.
gte: greater than or equal to.
lte: less than or equal to.
For example:
GET /corp/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "Zhang San"
}
}
],
"filter": [
{
"range": {
"age": {
"gt": 10,
"lt": 20
}
}
}
]
}
}
}(7) Match multiple criteria queries.
Multiple conditions are separated by spaces. As long as one of the conditions is met, it can be found and judged by score.
GET /corp/user/_search
{
"query": {
"match": {
"tags": "Female singing"
}
}
}
GET /corp/user/_search
{
"query": {
"match": {
"tags": "Male Technology"
}
}
}(8) Precise query.
term query is to find the specified terms directly through the inverted index.
About participle:
term, because the inverted index is used to directly query accurate records.
match, which is parsed using a word splitter. First analyze the document, and then query through the analyzed document.
text and keyword.
The text field type is normally parsed by the word breaker.
Keyword does not separate words, and the whole content is taken as a value. The field type will not be parsed by the word splitter. There is no word segmentation in the stored process. The keyword field will not be word segmentation. As a whole, it cannot be split. Avoid using the keyword field for full text search. Use the text field type instead.
For example:
Indexing.
PUT /testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}Add two pieces of data.
PUT /testdb/_doc/1
{
"name": "Xinxin talk show name",
"desc": "Xinxin talk show desc"
}
PUT /testdb/_doc/2
{
"name": "Xinxin talk show name",
"desc": "Xinxin talk show desc2"
}The word splitter is generally parsed and divided into multiple.
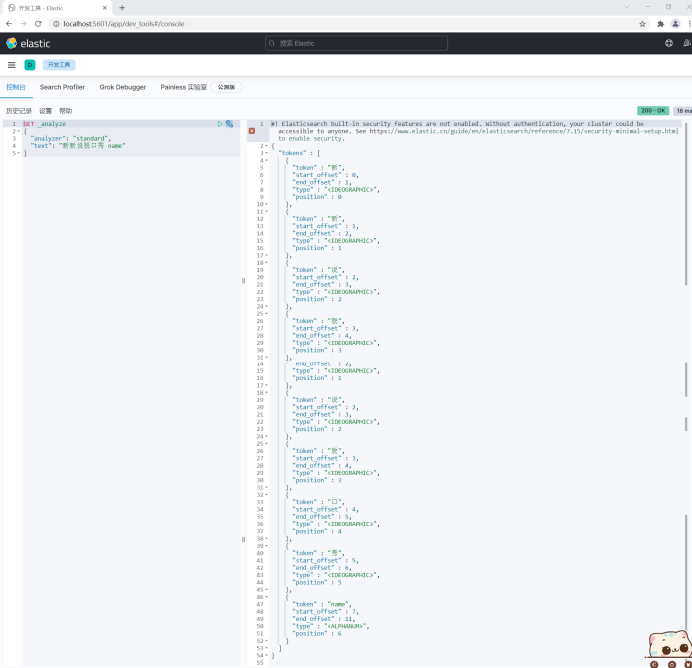
GET _analyze
{
"analyzer": "standard",
"text": "Xinxin talk show name"
}
The keyword will not be parsed by the word breaker as a whole.
GET _analyze
{
"analyzer": "keyword",
"text": "Xinxin talk show name"
} 
Query resolution.
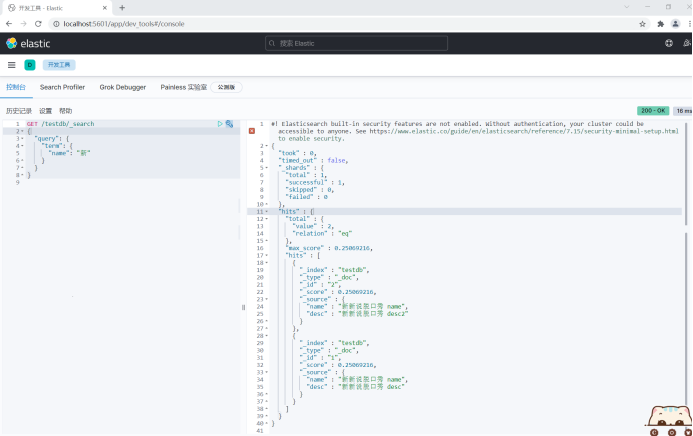
The name field is of text type and will be split during query.
GET /testdb/_search
{
"query": {
"term": {
"name": "new"
}
}
} 
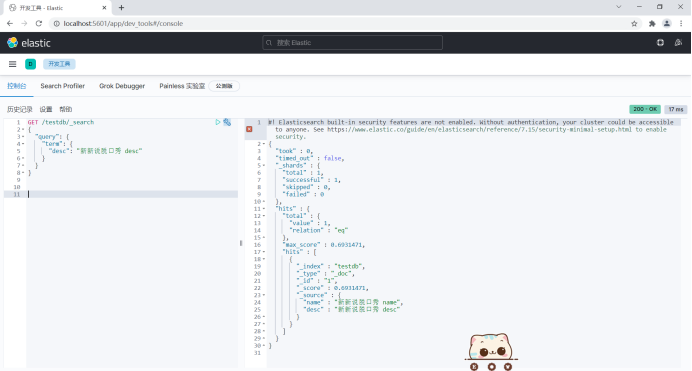
The desc field is of keyword type and will not be split during query. It is queried as a whole.
GET /testdb/_search
{
"query": {
"term": {
"desc": "Xinxin talk show desc"
}
}
} 
(9) Multiple values match an exact query.
For example:
Add two pieces of data.
PUT /testdb/_doc/3
{
"t1": "11",
"t2": "2020-11-11"
}
PUT /testdb/_doc/4
{
"t1": "22",
"t2": "2021-11-11"
}Multi valued exact query.
GET /testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": "11"
}
},
{
"term": {
"t1": "22"
}
}
]
}
}
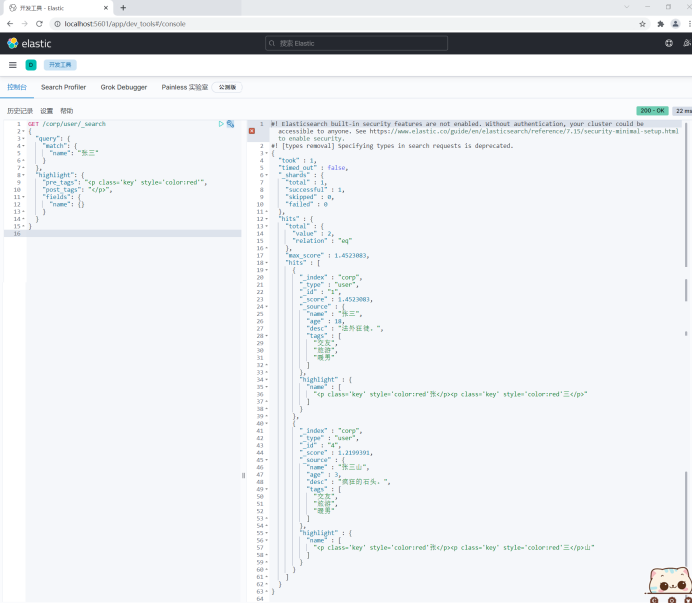
}(10) Highlight the query.
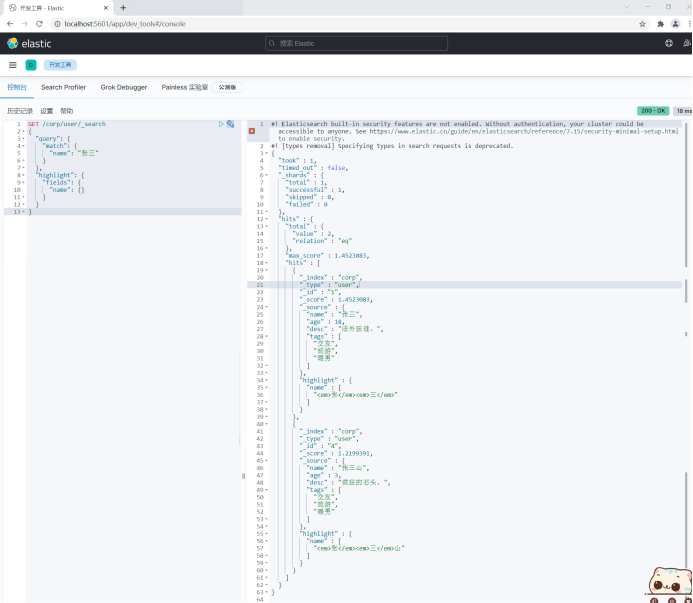
- Use the default highlighted label.
Search related results can be highlighted, and the < EM > < / EM > tag of HTML is used by default.
For example:
GET /corp/user/_search
{
"query": {
"match": {
"name": "Zhang San"
}
},
"highlight": {
"fields": {
"name": {}
}
}
} 
- Customize highlighted labels.
Highlight using your own defined HTML tags.
For example:
GET /corp/user/_search
{
"query": {
"match": {
"name": "Zhang San"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}