Article catalog
Image loading plays an important role in computer vision when writing optimized code. This process can be a bottleneck for many CV tasks and can often be the cause of poor performance. We need to get images from disk as quickly as possible.
The most obvious example of the importance of this task is to implement the Dataloader class in any CNN training framework. Fast image loading is critical. If not, the training process will be limited by CPU and waste precious GPU time.
Today, we'll look at some Python libraries that enable us to read images most efficiently. They are:
- OpenCV
- Pillow
- Pillow-SIMD
- TurboJpeg
In addition, we'll cover the following alternatives to loading images from a database:
- LMDB
- TFRecords
Finally, we will compare the loading time of each picture and find out which one is the winner!
1 installation
Before we start, we need to create a virtual environment:
$ virtualenv -p python3.7 venv
$ source venv/bin/activate
Then, install the required libraries:
$ pip install -r requirements.txt
2 how to load images
2.1 Structure
In general, we need to load multiple images stored in the database or as folders. In our scenario, the abstract image loader should be able to store the path to such a database or folder and load one image at a time from it. In addition, we need to measure the time of some parts of the code. (optional) some initialization may be required before loading starts. Our ImageLoader class is as follows:
import os from abc import abstractmethod class ImageLoader: extensions: tuple = \ (".png", ".jpg", ".jpeg", ".tiff", ".bmp", ".gif", ".tfrecords") def __init__(self, path: str, mode: str = "BGR"): self.path = path self.mode = mode self.dataset = self.parse_input(self.path) self.sample_idx = 0 def parse_input(self, path): # single image or tfrecords file if os.path.isfile(path): assert path.lower().endswith( self.extensions, ), f"Unsupportable extension, please, use one of {self.extensions}" return [path] if os.path.isdir(path): # lmdb environment if any([file.endswith(".mdb") for file in os.listdir(path)]): return path else: # folder with images paths = \ [os.path.join(path, image) for image in os.listdir(path)] return paths def __iter__(self): self.sample_idx = 0 return self def __len__(self): return len(self.dataset) @abstractmethod def __next__(self): pass
Image decoding functions in different libraries can return images of different formats - RGB or BGR. In our case, we use BGR color mode by default, but we can always convert it to the desired format. If you want to know OpenCV uses BGR format For interesting reasons, click here link.
Now we can inherit the new class from the base class and use it for our tasks.
2.2 OpenCV
The first is the OpenCV library. We can use a simple function to read the image from disk - cv2.imread.
import cv2 class CV2Loader(ImageLoader): def __next__(self): start = timer() # get image path by index from the dataset path = self.dataset[self.sample_idx] # read the image image = cv2.imread(path) full_time = timer() - start if self.mode == "RGB": start = timer() # change color mode image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) full_time += timer() - start self.sample_idx += 1 return image, full_time
Before image visualization, we need to mention that OpenCV's cv2.imshow function requires an image in BGR format. Some libraries use RGB image mode by default. In this case, we convert the image to BGR for correct visualization.
To test the OpenCV library, use the following command:
python3 show_image.py --path images/cat.jpg --method cv2
This command and the next command in the text will use different libraries to show you the image and its load time.
If all goes well, you will see the following image in the window:

In addition, you can display all the images in the folder. In addition to using specific images, you can also use the path of the folder that contains the images:
$ python3 show_image.py --path images/pexels --method cv2
This will display all the images in the folder and their load times at once. To stop the presentation, press the ESC button.
2.3 Pillow
Now let's try the PIL library. We can use Image.open Function to read an image.
import numpy as np from PIL import Image class PILLoader(ImageLoader): def __next__(self): start = timer() # get image path by index from the dataset path = self.dataset[self.sample_idx] # read the image as numpy array image = np.asarray(Image.open(path)) full_time = timer() - start if self.mode == "BGR": start = timer() # change color mode image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) full_time += timer() - start self.sample_idx += 1 return image, full_time
We also convert the Image object to a Numpy array, because the next step may require some enhancement or preprocessing, so Numpy is its default choice.
To check on a single image, you can use:
$ python3 show_image.py --path images/cat.jpg --method pil
If you want to use it in a folder with images:
$ python3 show_image.py --path images/pexels --method pil
2.4 Pillow-SIMD
The fork follower of the pilot library has higher performance. With new technology, pilot SIMD can read and convert images faster using the same API as the standard pilot.
You cannot use both pilot and pilot SIMD in the same virtual environment. By default, pilot SIMD will be used.
To use pilot SIMD and avoid errors caused by the combination of pilot and pilot SIMD, you need to create a new virtual environment and use:
$ pip install pillow-simd
Alternatively, you can uninstall the previous version of pilot and install pilot SIMD:
$ pip uninstall pillow $ pip install pillow-simd
You don't need to change anything in the code, the previous example is still valid. To check that everything is OK, use the command in the previous pilot section:
$ python3 show_image.py --path images/cat.jpg --method pil $ python3 show_image.py --path images/pexels --method pil
2.5 TurboJpeg
There is another library called TurboJpeg. As the title shows, it can only read images compressed using JPEG.
Let's use TurboJpeg to create an image loader.
from turbojpeg import TurboJPEG class TurboJpegLoader(ImageLoader): def __init__(self, path, **kwargs): super(TurboJpegLoader, self).__init__(path, **kwargs) # create TurboJPEG object for image reading self.jpeg_reader = TurboJPEG() def __next__(self): start = timer() # open the input file as bytes file = open(self.dataset[self.sample_idx], "rb") full_time = timer() - start if self.mode == "RGB": mode = 0 elif self.mode == "BGR": mode = 1 start = timer() # decode raw image image = self.jpeg_reader.decode(file.read(), mode) full_time += timer() - start self.sample_idx += 1 return image, full_time
TurboJpeg needs to decode the input image and store it as a byte string.
You can try using the following command. Remember, however, that TurboJpeg only allows processing of. jpeg images:
$ python3 show_image.py --path images/cat.jpg --method turbojpeg $ python3 show_image.py --path images/pexels --method turbojpeg
2.6 LMDB
When speed is a priority, the usual image loading method is to convert the data to a better representation (database or serialized buffer) in advance. One of the biggest advantages of this "database" is that they have zero system calls per data access, while the file system requires multiple system calls per data access. We can create an LMDB database that will collect all images in key format.
The following functions allow us to create an LMDB environment using images. The "environment" of LMDB is essentially a folder containing special files created by the LMDB library. This function only needs to contain a list of image paths and save paths:
import cv2 import lmdb import numpy as np def store_many_lmdb(images_list, save_path): # number of images in our folder num_images = len(images_list) # all file sizes file_sizes = [os.path.getsize(item) for item in images_list] # the maximum file size index max_size_index = np.argmax(file_sizes) # maximum database size in bytes map_size = num_images * cv2.imread(images_list[max_size_index]).nbytes * 10 # create lmdb environment env = lmdb.open(save_path, map_size=map_size) # start writing to environment with env.begin(write=True) as txn: for i, image in enumerate(images_list): with open(image, "rb") as file: # read image as bytes data = file.read() # get image key key = f"{i:08}" # put the key-value into database txn.put(key.encode("ascii"), data) # close the environment env.close()
There is a Python script that uses images to create an LMDB environment:
- --The path parameter should contain the path of the image folder you collected
- --The output parameter is the directory in which the LMDB will be created
$ python3 create_lmdb.py --path images/pexels --output lmdb/images
Now, with the creation of the LMDB environment, we can load images from it. Let's create a new loader class.
In the case of loading images from the database, we need to open the database for reading. There is one called open_ New function for database. It returns an iterator to browse the open database. In addition, when this iterator reaches the end of the data, we need to use the_ iter_ Function returns it to the beginning of the database.
LMDB allows us to store data, but there is no built-in image decoder. Due to the lack of a decoder, we will use the cv2.imdecode function here.
class LmdbLoader(ImageLoader): def __init__(self, path, **kwargs): super(LmdbLoader, self).__init__(path, **kwargs) self.path = path self._dataset_size = 0 self.dataset = self.open_database() # we need to open the database to read images from it def open_database(self): # open the environment by path lmdb_env = lmdb.open(self.path) # start reading lmdb_txn = lmdb_env.begin() # create cursor to iterate through the database lmdb_cursor = lmdb_txn.cursor() # get number of items in full dataset self._dataset_size = lmdb_env.stat()["entries"] return lmdb_cursor def __iter__(self): # set the cursor to the first database element self.dataset.first() return self def __next__(self): start = timer() # get raw image raw_image = self.dataset.value() # convert it to numpy image = np.frombuffer(raw_image, dtype=np.uint8) # decode image image = cv2.imdecode(image, cv2.IMREAD_COLOR) full_time = timer() - start if self.mode == "RGB": start = timer() image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) full_time += timer() - start start = timer() # step to the next element in database self.dataset.next() full_time += timer() - start return image, full_time def __len__(self): # get dataset length return self._dataset_size
After creating the environment and loader classes, we can check their correctness and display the images in them. Now, in the -- path parameter, we need to mention the path of the LMDB environment. Remember that you can use the ESC button to stop the display.
$ python3 show_image.py --path lmdb/images --method lmdb
2.7 TFRecords
Another useful database is TFRecords. In order to read data efficiently, it is helpful to serialize the data and store it in a set of files (100-200MB each) that can be read linearly( TensorFlow manual).
Before creating tfrecords files, we need to choose the structure of the database. Tfrecords allows you to keep items with many other features. If necessary, you can save the file name or the width and height of the image. All these things should be collected in the python dictionary, namely:
image_feature_description = { "height" :tf.io.FixedLenFeature([], tf.int64), "width" :tf.io.FixedLenFeature([], tf.int64), "filename": tf.io.FixedLenFeature([], tf.string), "label": tf.io.FixedLenFeature([], tf.int64), "image_raw": tf.io.FixedLenFeature([], tf.string), }
In our example, we will use only images in the original byte format and their unique keys, called "tags.".
import os import tensorflow as tf def _byte_feature(value): """Convert string / byte into bytes_list.""" if isinstance(value, type(tf.constant(0))): # BytesList can't unpack string from EagerTensor. value = value.numpy() return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) def _int64_feature(value): """Convert bool / enum / int / uint into int64_list.""" return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) def image_example(image_string, label): feature = { "label": _int64_feature(label), "image_raw": _byte_feature(image_string), } return tf.train.Example(features=tf.train.Features(feature=feature)) def store_many_tfrecords(images_list, save_file): assert save_file.endswith( ".tfrecords" ), 'File path is wrong, it should contain "*myname*.tfrecords"' directory = os.path.dirname(save_file) if not os.path.exists(directory): os.makedirs(directory) # start writer with tf.io.TFRecordWriter(save_file) as writer: # cycle by each image path for label, filename in enumerate(images_list): # read the image as bytes string image_string = open(filename, "rb").read() # save the data as tf.Example object tf_example = image_example(image_string, label) # and write it into database writer.write(tf_example.SerializeToString())
Please note that since all our images are stored as JPEG files, we use tf.image.decode_ The JPEG function converts the image. You can also tf.image.decode_image is used as a universal decoder.
To check the correctness of the created database, you can display the images in it:
$ python3 show_image.py --path tfrecords/images.tfrecords --method tfrecords
3 load time comparison
We will use the pexels.com Some open images with different shapes and jpeg extensions. And all time measurements will average 5000 iterations. In addition, the impact of OS / hardware specific logic (such as data caching) will be mitigated on average. It can be expected that the first iteration of the first method being evaluated will suffer from an initial load of data from disk to cache, while the other methods will not.
All experiments were run for BGR and RGB image modes to cover all potential needs and different tasks. Keep in mind that pilot and pilot SIMD cannot be used in the same virtual environment. In order to create the final comparison table, we did two separate experiments on pilot and pilot SIMD.
To run a survey, use:
python3 benchmark.py --path images/pexels --method cv2 pil turbojpeg lmdb tfrecords --iters 100 --mode BGR
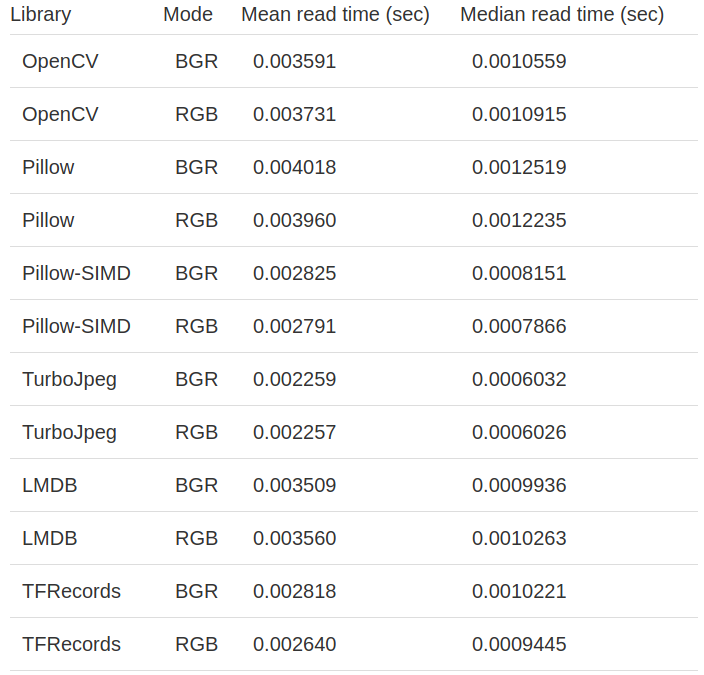
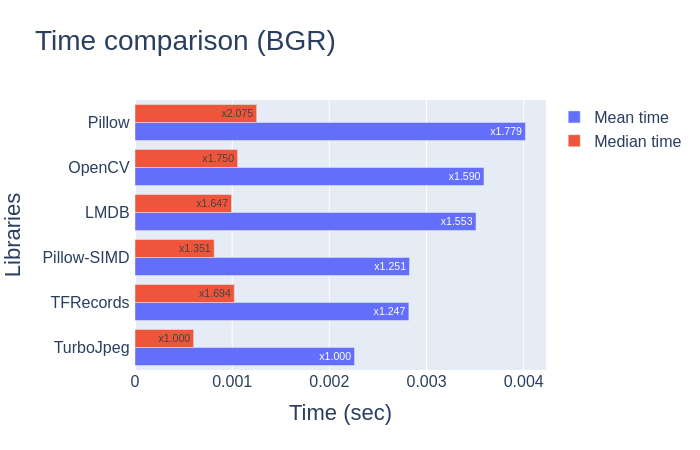
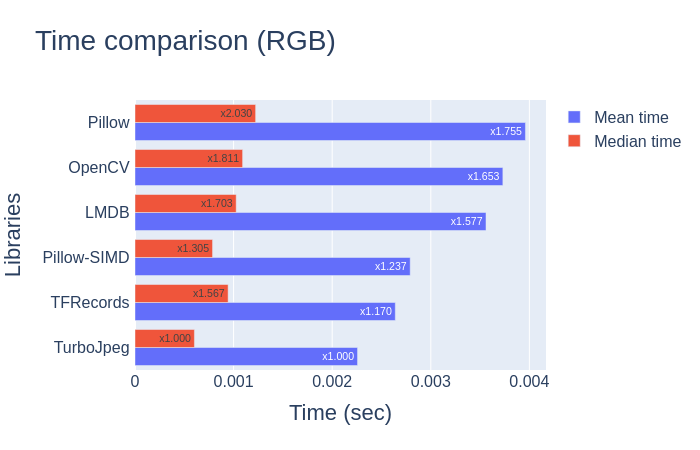
Moreover, it will be interesting to compare the read speed of the database with the same decoder function. It shows which database loads its data faster. In this case, we use the cv2.imdecode function for TFRecords and LMDB.
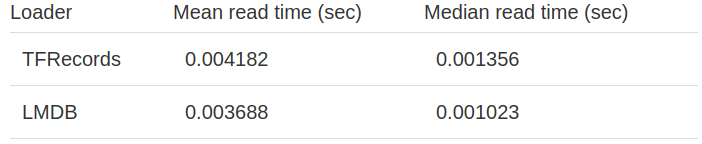
Calculation basis of all experiments:
- Intel® Core™ i7-2600 CPU @ 3.40GHz × 8
- Ubuntu 16.04 64-bit
- Python 3.7
4 Summary
In this blog, we consider some image loading methods and compare them with each other. The comparison results on JPEG images are very interesting. We can see that TurboJpeg is the fastest library to load images as numpy, with one exception - it can only read files with JPEG extensions.
Another thing worth mentioning is that the pilot SIMD is faster than the original pilot. In our mission, the loading speed increased by nearly 40%.
If you plan to use an image database, especially due to the built-in decoder function, TFRecords will produce better average results than LMDB. On the other hand, LMDB enables us to read images faster. Of course, you can always combine decoder functions with a database, for example, using TurboJpeg as the decoder and LMDB as the image store.