Preface
As a girl, I like to read novels in Jinjiang. However, the website of Jinjiang is very magical. The article says that we can only write a crawler program to save novels
At first, I chose the format of txt to save the novel. Later, I decided to save the novel in the format of epub. Because I found that it is also a novel. epub format not only has rich functions and beautiful interface, but also is much smaller than the file in TXT format If the novel is saved in ASCII code, the size is much smaller Some characters will be lost
I will also download the source code of the txt file, but that version hasn't been updated for a long time, so there are many bug s.
The project is stored in github, and it is planned to write the program again in c.
(I pieced together this program. It was originally written for my own use. I didn't expect to write a blog at all. Although it can run well, but the naming is very irregular. Please don't follow me.)
https://github.com/7325156/jjdown
python Library
The following libraries need to be installed
- pip install requests
- pip install lxml
- pip install selenium is used to obtain cookie s. It can not be installed
- PIP install opencc Python reimplemented - simple conversion, can not be installed
Get cookie
The cookie stores the user's login information. If you want to crawl the purchased vip chapter, you must add the cookie to the header.
There are many ways to get cookies. It is recommended to log in to Jinjiang website, press F12 to enter developer mode, enter document.cookie in console interface, and press enter to get cookies.
Note: cookies in Jinjiang sometimes fail. If they fail, it is recommended to use IE browser or Edge browser to retrieve the cookies again. If not, delete the "timeoffset" item in the cookies.
Here is the procedure for obtaining cookie s. I don't think it's very useful. It's troublesome to use, and the optimization is not enough. Just have a look, and you can use it if you want.
Before using, you need to download the chord driver, which is placed in the python path.
from selenium import webdriver
import time
#You need to install chormedriver and store it in the python path
driver=webdriver.Chrome()
driver.delete_all_cookies()
driver.get("http://my.jjwxc.net/login.php")
username=input("Please enter the user name:")
passwd=input("Please input a password:")
driver.find_element_by_id("loginname").send_keys(username)
driver.find_element_by_id("loginpassword").send_keys(passwd)
driver.find_element_by_xpath("//*[@id='login_submit_tr']/input").click()
cookies = driver.get_cookies()
cookies_list= []
for cookie_dict in cookies:
cookie =cookie_dict['name']+'='+cookie_dict['value']
cookies_list.append(cookie)
header_cookie = ';'.join(cookies_list)
headers = {
'cookie':header_cookie,
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
print(headers)
driver.quit()Add cookie s to the header to get all chapters and volume labels
Paste the obtained cookie directly in the colon after the cookie
headerss={'cookie': ' ',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}Txt? ID is the article number. Every novel in Jinjiang has a number. The number is the number following the website. Let me give you a random example. If the website of the novel is http://www.jjwxc.net/onebook.php?novelid=2710871 , then 2710871 is the novel number.
Use requests to add a header to send a request to the web address, and then re code the article. If you don't code, you will output a heap of garbled code.
#Get article URL
req_url=req_url_base+ids
#Get article information through cookie s
res=requests.get(req_url,headers=headerss).content
#Code the article
ress=etree.HTML(res.decode("GB18030","ignore").encode("utf-8","ignore").decode('utf-8'))
Next, use xpath to get the article information. You are interested in the rules of xpath, but I use the simplest and rudest method here.
Use Google browser to move the mouse to the location of the element to be acquired, right-click to check to move the mouse to the label to be acquired, right-click to copy to copy XPath. Get it done.
Just paste the obtained xpath to the specified location and replace the double quotation mark with the single quotation mark.
Note: Google browser should remove the tbody tag.
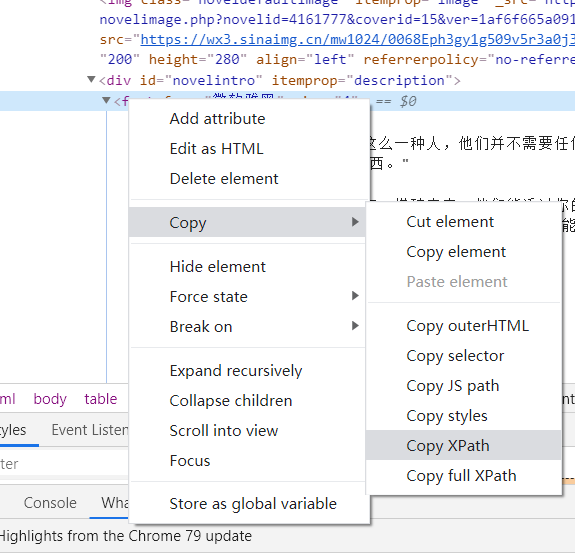
Here, use xpath to get information. If you want to get more information, you can also modify it appropriately. Non vip chapters and vip chapters should be obtained separately.
#Getting copywriting
intro=ress.xpath("//html/body/table/tr/td[1]/div[2]/div[@id='novelintro']//text()")
#Get Tags
info=ress.xpath("string(/html/body/table[1]/tr/td[1]/div[3])")
#Get article information
infox=[]
for i in range(1,7):
infox.append(ress.xpath("string(/html/body/table[1]/tr/td[3]/div[2]/ul/li["+str(i)+"])"))
#Get cover
cover=ress.xpath("string(/html/body/table[1]/tr/td[1]/div[2]/img/@src)")
#Get title
titlem=ress.xpath("//html/head/title/text()")
#Get all chapter links
#Non vip
href_list=ress.xpath("//html/body/table[@id='oneboolt']//tr/td[2]/span/div[1]/a/@href")
#vip
hhr=ress.xpath("//html/body/table[@id='oneboolt']//tr/td[2]/span/div[1]/a[1]/@rel")
As chapters are often locked in Jinjiang, it is necessary to operate after obtaining the content summary and volume label. Personally, I don't think this place has been dealt with enough. I will continue to optimize it later.
#Summary of each chapter
#loc: locked chapter
loc=ress.xpath("//*[@id='oneboolt']//tr/td[2]/span/div[1]/span/ancestor-or-self::tr/td[3]/text()")
Summary=ress.xpath("//*[@id='oneboolt']//tr/td[3]/text()")
for i in Summary:
if i.strip()=='[This chapter is locked]':
del Summary[Summary.index(i)]
for i in Summary:
if i.strip()=='[This chapter is locked]':
del Summary[Summary.index(i)]
for i in Summary:
if i in loc:
del Summary[Summary.index(i)]
for i in Summary:
if i in loc:
del Summary[Summary.index(i)]
for i in Summary:
if i in loc:
del Summary[Summary.index(i)]
#Get volume label name
rollSign=ress.xpath("//*[@id='oneboolt']//tr/td/b[@class='volumnfont']/text()")
#Get label location
rollSignPlace=ress.xpath("//*[@id='oneboolt']//tr/td/b/ancestor-or-self::tr/following-sibling::tr[1]/td[2]/span/div[1]/a[1]/@href")
rollSignPlace+=ress.xpath("//*[@id='oneboolt']//tr/td/b/ancestor-or-self::tr/following-sibling::tr[1]/td[2]/span/div[1]/a[1]/@rel")
Next, the acquired information is processed and stored.
(so many first, the rest later)

