Before concurrent.futures libraries are summarized, three questions need to be clarified:
(1) Is python multithreading useful?
(2) How does the python virtual machine mechanism control code execution?
(3) What is the principle of multi-process processing in python?
1. Let's start with two examples.
(1) Case 1
The maximum common divisor is calculated by three methods: single thread, multi-thread and multi-process.
'''
//Nobody answered the question? Editor created a Python learning and communication QQ group: 857662006
//Look for like-minded friends, help each other, there are good video learning tutorials and PDF e-books in the group!
'''
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import time
def gcd(pair):
a, b = pair
low = min(a, b)
for i in range(low, 0, -1):
if a % i == 0 and b % i == 0:
return i
numbers = [
(1963309, 2265973), (1879675, 2493670), (2030677, 3814172),
(1551645, 2229620), (1988912, 4736670), (2198964, 7876293)
if __name__ == '__main__':
# Do not use multithreading and multiprocesses
start = time.time()
results = list(map(gcd,numbers))
end = time.time()
print('not used--timestamp:{:.3f} second'.format(end-start))
#Using multithreading
start = time.time()
pool = ThreadPoolExecutor(max_workers=3)
results = list(pool.map(gcd,numbers))
end = time.time()
print('Using multithreading--timestamp:{:.3f} second'.format(end-start))
#Using multiple processes
start = time.time()
pool = ProcessPoolExecutor(max_workers=3)
results = list(pool.map(gcd,numbers))
end = time.time()
print('Using multiprocess processes--timestamp:{:.3f} second'.format(end-start))
Output:

The number of threads and processes used to be 3, but now it's 4 retest.

To better illustrate the problem, continue to increase the number of threads and the process theory to 5

As for the difference, we feel that the test conditions (calculation is too simple), the test environment will affect the test results.
(2) Case 2
Similarly, we use single thread, multi-thread and multi-process methods to crawl web pages, but simply return status_code.
'''
//Nobody answered the question? Editor created a Python learning and communication QQ group: 857662006
//Look for like-minded friends, help each other, there are good video learning tutorials and PDF e-books in the group!
'''
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import time
import requests
def download(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Connection':'keep-alive',
'Host':'example.webscraping.com'}
response = requests.get(url, headers=headers)
return(response.status_code)
if __name__ == '__main__':
urllist = ['http://example.webscraping.com/places/default/view/Afghanistan-1',
'http://example.webscraping.com/places/default/view/Aland-Islands-2',
'http://example.webscraping.com/places/default/view/Albania-3',
'http://example.webscraping.com/places/default/view/Algeria-4',
'http://example.webscraping.com/places/default/view/American-Samoa-5']
start = time.time()
result = list(map(download, urllist))
end = time.time()
print('status_code:',result)
print('not used--timestamp:{:.3f}'.format(end-start))
pool = ThreadPoolExecutor(max_workers = 3)
start = time.time()
result = list(pool.map(download, urllist))
end = time.time()
print('status_code:',result)
print('Using multithreading--timestamp:{:.3f}'.format(end-start))
pool = ProcessPoolExecutor(max_workers = 3)
start = time.time()
result = list(pool.map(download, urllist))
end = time.time()
print('status_code:',result)
print('Using multiprocess processes--timestamp:{:.3f}'.format(end-start))
Output:
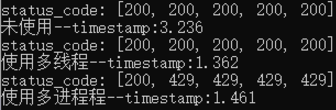
You can see the difference in a moment.
2. How does the python virtual machine mechanism control code execution?
For python, as an interpretive language, Python's interpreter must be both safe and efficient. We all know the problems that multithreaded programming will encounter. The interpreter should pay attention to avoiding sharing data among different threads. At the same time, it should ensure that there is always maximum computing resources when managing user threads. Python protects data security by using global interpreter locks.
The execution of Python code is controlled by Python virtual machine, that is, Python compiles the code (.py file) into bytecode (bytecode corresponds to PyCodeObject object in Python virtual machine program, and. pyc file is the form of bytecode on disk), gives it to bytecode virtual machine, and then the virtual machine executes one bytecode by one. Save code instructions to complete the execution of the program. Python was designed in a virtual machine with only one thread to execute at the same time. Similarly, although multiple threads can be run in the python interpreter, only one thread runs in the interpreter at any time. Access to the python virtual machine is controlled by the global interpreter lock, which ensures that only one thread is running at the same time.
In a multi-threaded environment, the python virtual machine executes in one click:
(1) Setting GIL(global interpreter lock)
(2) Switch to a thread for execution
(3) Running: a specified number of bytecode instructions, threads voluntarily relinquish control (you can call time.sleep(0))
(4) Setting threads to sleep
(5) Unlock GIL
(6) Repeat the above steps again.
The characteristics of GIL also result in python not making full use of multi-core cpu. For I/O-oriented programs (which call the built-in operating system C code), GIL is released before the I/O call to allow other threads to run while the thread waits for I/O. If a thread does not use many I/O operations, it will occupy the processor and GIL in its own time slice.
3. Is Python multithreading useful?
The use of multithreading should be clear through the previous examples and the understanding of Python virtual mechanism. I/O-intensive Python programs can make better use of the benefits of multithreading than computing-intensive programs. In a word, if Python multithreading is not used in computationally intensive programs and python multiprocesses are used for concurrent programming, there will be no GIL problem and multi-core cpu can be fully utilized.
(1) GIL is not a bug, nor is Guido a limited level to leave such a thing behind. Uncle Tortoise once said that trying to do thread safety without GIL in other ways resulted in the overall efficiency of python language doubled, weighing the pros and cons, GIL is the best choice - not to go away, but deliberately retained.
(2) If you want python to be faster and you don't want to write C, use pypy. That's the real killer.
(3) Collaboration can be used to improve cpu utilization, using multiprocessing and gevent
4. python multiprocess execution principle
The ProcessPoolExecutor class takes advantage of the underlying mechanism provided by the multiprocessing module to describe the multiprocess execution process in Example 2.
(1) Pass each input data in the urllist list to the map
(2) Serialize the data with pickle module and convert it into binary form
(3) Through local sockets, the serialized data is sent from the process in which the interpreter is located to the process in which the sub-interpreter is located.
(4) In the sub-process, the binary data is deserialized by pickle and reduced to python object.
(5) Introducing python module containing download function
(6) Each subprocess computes its input data in parallel
(7) Serialize the results of the run and convert them into bytes
(8) Copy these bytes to the main process via socket
(9) The main process deserializes these bytes and restores them to python objects
(10) Finally, the calculated results of each subprocess are merged into a list and returned to the caller.
multiprocessing overhead is high because the communication between the main process and the sub-process must be serialized and deserialized.