Guide reading
- Articles published the other day Spring boot multi data source dynamic switch and Spring boot: a huge pit for integrating multiple data sources In, it is mentioned that adding @ Primary interface to dynamic data source will cause circular dependency exception, as shown in the following figure:
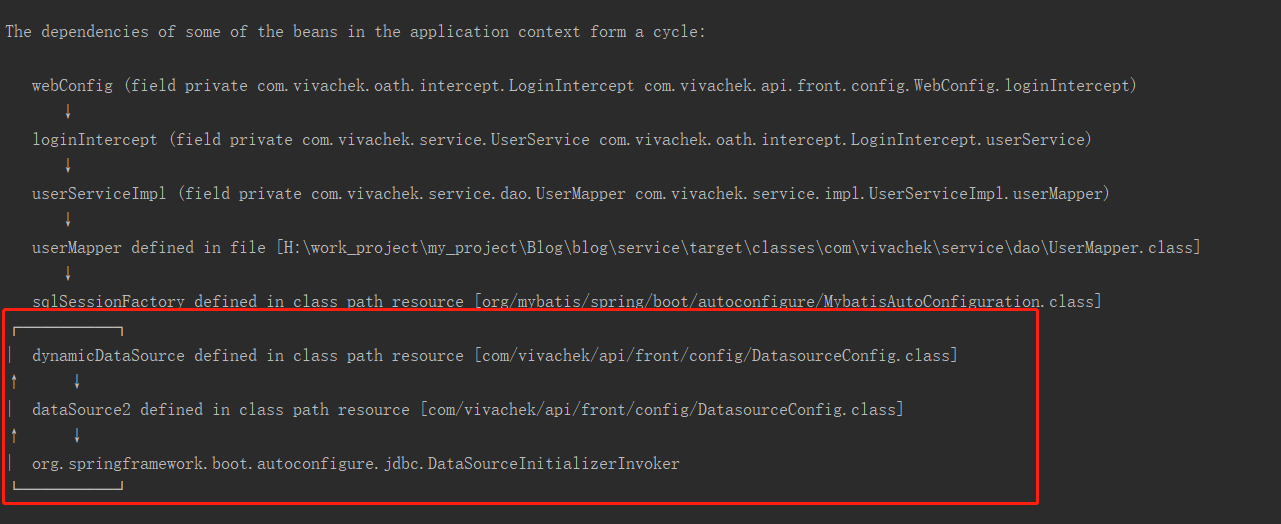
- This is a typical constructor dependency. Please refer to the above two articles for details, which will not be described in detail here. This article will deeply analyze how Spring solves circular dependency from the source code? Why can't we solve the cyclic dependency of constructors?
What is circular dependence
- In short, A depends on B, B depends on C, and C depends on A, which constitutes A circular dependency.
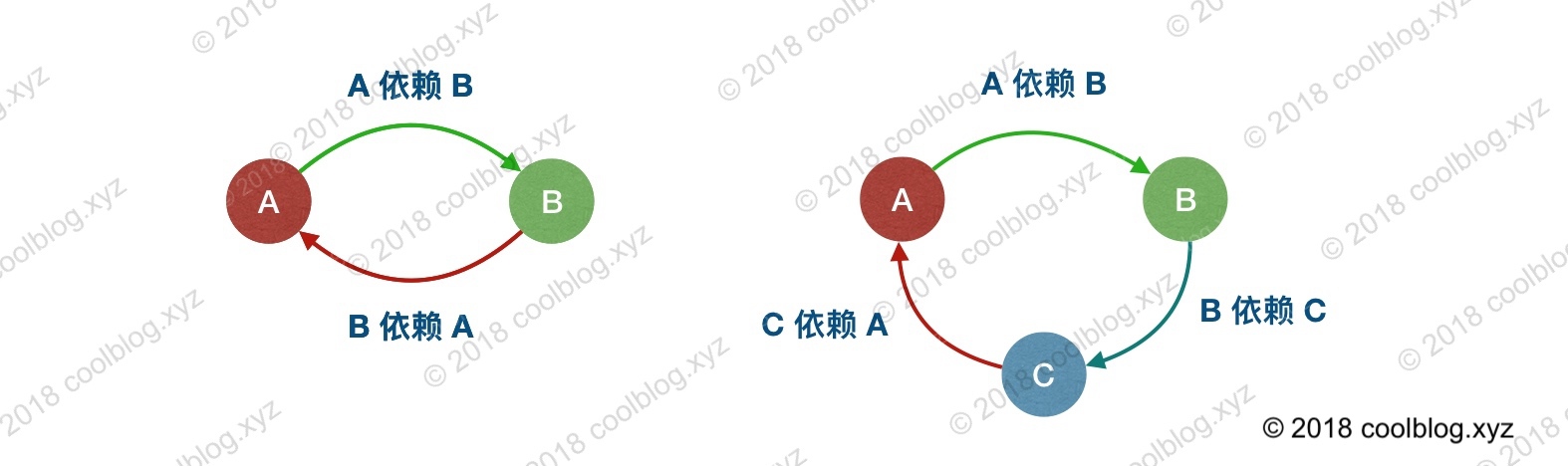
- Circular dependency can be divided into constructor dependency and attribute dependency. It is well known that Spring can solve the circular dependency (set injection) of attributes. The following will analyze how Spring solves the circular dependency of attributes from the source point of view.
thinking
- How to solve the circular dependency? Spring's main idea is to call doGetBean when instantiating a and find the instance of B on which a depends. At this time, it calls doGetBean to go to instance B, and when instantiating B, it finds and depends on A. if this circular dependency is not solved, then the doGetBean at this time will cycle indefinitely, resulting in memory overflow and program crash. Spring refers to an early object, and injects the "early reference" into the container. Let B complete the instantiation first, and then a will get the reference of B and complete the instantiation.
Three level cache
- Spring can easily solve the circular dependency of attributes by using the three-level cache, which has detailed comments in AbstractBeanFactory.
/**The first level cache is used to store the fully initialized beans. The beans taken from the cache can be used directly*/
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/**The three-level cache stores bean factory objects to solve circular dependency*/
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/**The second level cache holds the original bean object (properties have not been filled) to solve the circular dependency*/
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);- Level 1 cache: singletonObjects, which is used to store the fully instantiated Bean.
- Second level cache: earlySingletonObjects, which stores references of earlier beans and beans that have not been attribute assembled
- Three level cache: Singleton factories, which stores the Bean factory after instantiation.
Open and close
- Let's take a look at the previous flowchart to see how Spring solves circular dependency
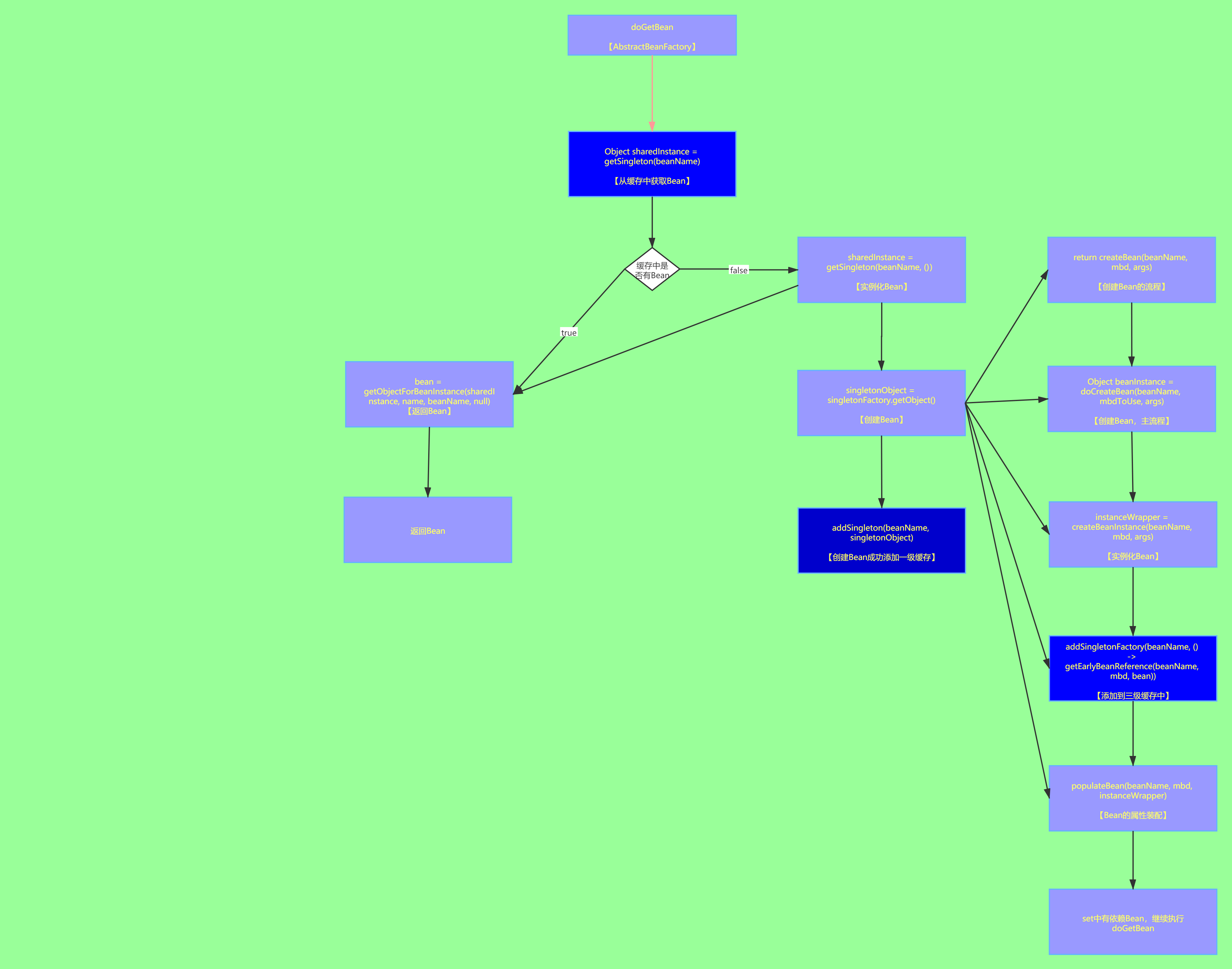
- The blue part of the above figure is related to the operation of level 3 cache. Let's analyze it one by one
[1] getSingleton(beanName): the source code is as follows:
//Query cache
Object sharedInstance = getSingleton(beanName);
//Exists in cache and args is null
if (sharedInstance != null && args == null) {
//...... Omit some codes
//Get Bean instance directly
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
//getSingleton source code, defaultsingletonbeanregistry × getSingleton
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//First, get the Bean whose property assignment has been instantiated from the first level cache
Object singletonObject = this.singletonObjects.get(beanName);
//The first level cache does not exist and the Bean is in the process of being created
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//Query from the secondary cache, get the early reference of the Bean, instantiate the Bean that is completed but not assigned
singletonObject = this.earlySingletonObjects.get(beanName);
//Does not exist in the L2 cache and allows creation of early references (added in the L2 cache)
if (singletonObject == null && allowEarlyReference) {
//Query from the three-level cache, instantiation complete, attribute not assembled complete
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
//Add in L2 cache
this.earlySingletonObjects.put(beanName, singletonObject);
//Remove from L3 cache
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
- It can be seen from the source code that doGetBean is initially a query cache, with all queries in the first, second and third level cache. If the third level cache exists, the Bean's early references will be stored in the second level cache and the third level cache will be removed. (upgrade to L2 cache)
[2] Addsingleton factory: the source code is as follows
//Omit some code in the middle.....
//The source code of creating Bean, in the abstractautowirecapablebeanfactory ා docreatebean method
if (instanceWrapper == null) {
//Instantiate Bean
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
//Allow early exposure
if (earlySingletonExposure) {
//Add to L3 cache
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
try {
//During attribute assembly and attribute assignment, if the attribute references another Bean, the getBean method is called
populateBean(beanName, mbd, instanceWrapper);
//Initialize Bean, call init method, afterproperties method and other operations
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
//The source code added to the level 3 cache can be found in the defaultsingletonbeanregistry ා addsingletonfactory
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
//Level 1 cache does not exist
if (!this.singletonObjects.containsKey(beanName)) {
//Put into Level 3 cache
this.singletonFactories.put(beanName, singletonFactory);
//Remove from L2 cache,
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}- According to the source code, beans will directly store the unassembled Bean factory in the third level cache after instantiation, and remove the second level cache
[3] addSingleton: the source code is as follows:
//Get the method of singleton object, defaultsingletonbeanregistry × getsingleton
//Call createBean to instantiate Bean
singletonObject = singletonFactory.getObject();
//... Code omitted in the middle
//The beans that are called, instantiated, and attribute assigned after doCreateBean are loaded into the first level cache. The beans that can be used directly
addSingleton(beanName, singletonObject);
//addSingleton source code, in the defaultsingletonbeanregistry ා addSingleton method
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
//Add in L1 cache
this.singletonObjects.put(beanName, singletonObject);
//Remove L3 cache
this.singletonFactories.remove(beanName);
//Remove L2 cache
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
- In a word, beans are added to the first level cache and removed from the second and third level cache.
extend
[1] Why can't Spring solve the loop dependency of constructors?
- It should not be hard to see from the flow chart that before the Bean calls the constructor for instantiation, the level-1, level-2 and level-3 cache does not have any information about the Bean, and it is put into the level-3 cache after instantiation. Therefore, when getBean is used, the cache fails to hit, thus throwing the exception of circular dependency.
[2] Why can't multi instance beans solve circular dependency?
- Multiple instance Bean calls the doGetBean method every time it is created. It does not use the level-1, level-2, and level-3 cache at all. It certainly cannot solve the circular dependency.
summary
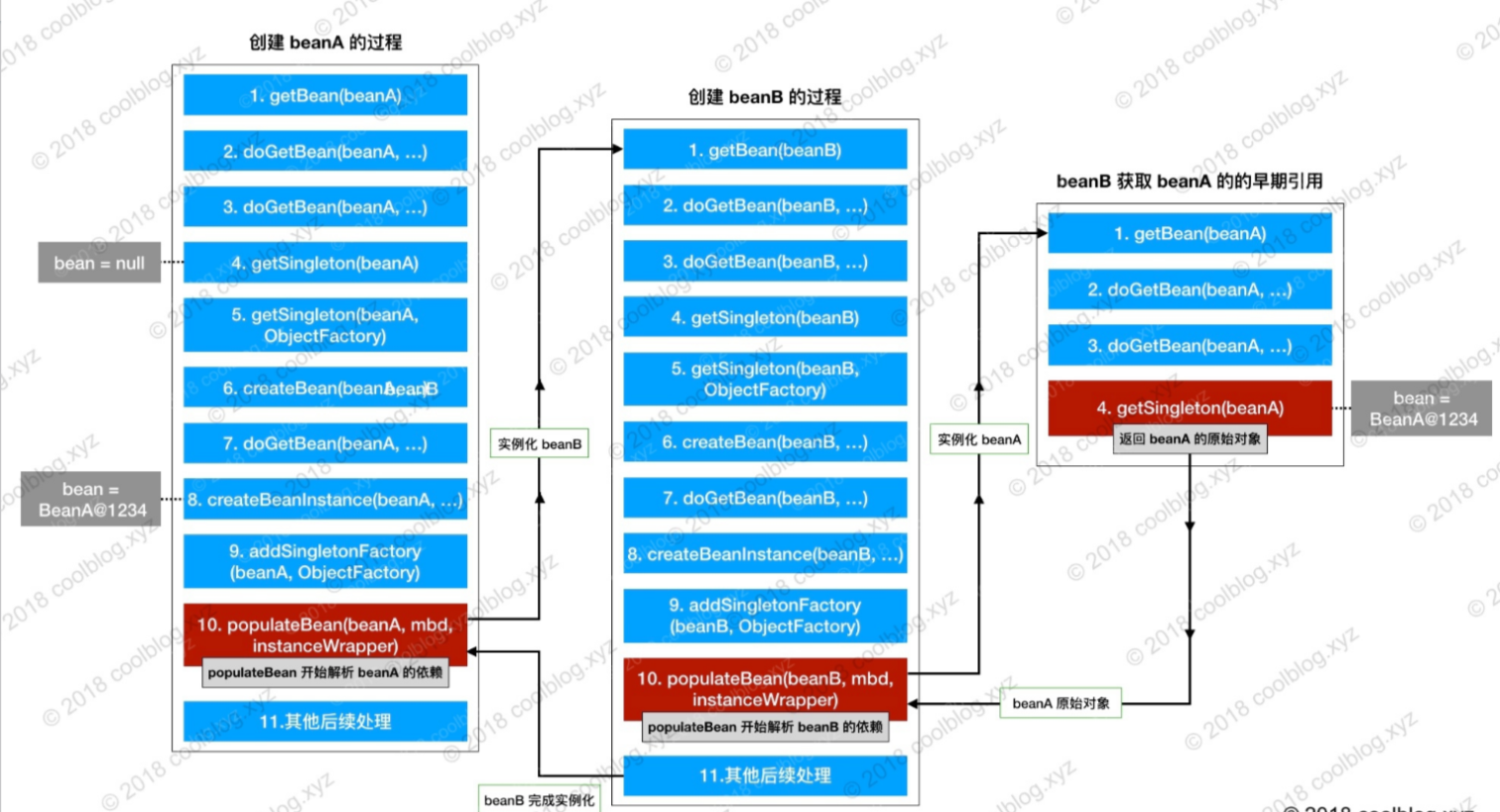
- Based on the above analysis, it is probably clear how Spring solves circular dependency. Suppose that A depends on B, and B depends on A (Note: here is set attribute dependency). The steps are as follows:
- A executes doGetBean, query cache, and createBean to create the instance in turn. After instantiation, it is put into singletonfactors of the three-level cache. Then, it executes populateBean method to assemble the attribute. However, it is found that there is an object whose attribute is B.
- Therefore, we call the doGetBean method again to create an instance of B, and then execute doGetBean, query cache, and createBean to create the instance. After the instantiation, we put it into the three-level cache singletonfactors, and execute the populateBean assembly attribute. However, at this time, we find that there is an attribute of A object.
- Therefore, call doGetBean again to create an instance of a, but when executing the getSingleton query cache, the instance of a is queried from the three-level cache (early reference, Incomplete Attribute assembly). At this time, it directly returns to A. without executing the subsequent process to create a, then B completes the attribute assembly. At this time, a complete object is put into the singletonObjects of the first level cache.
- When the creation of B is completed, A naturally completes the attribute assembly and puts it into the first level cache singletonObjects.
- The application of Spring three-level cache perfectly solves the problem of circular dependency. The following is the flow chart of circular dependency solution.
- If you think the author wrote well and got something, please pay attention and recommend it!!!
