origin
Why suddenly talk about distributed unique ids? The reason is that we are preparing to use the global unique ID recently. The project needs to be microserviced. Look at the introduction on the official website.
The same business scenario needs to be globally unique. The requirement of this id is either locally unique or globally unique. Because this id is unique, it can be used as the primary key of the database.
Then the id needs two features:
- Local and global uniqueness.
- The trend is increasing.
snowflake algorithm
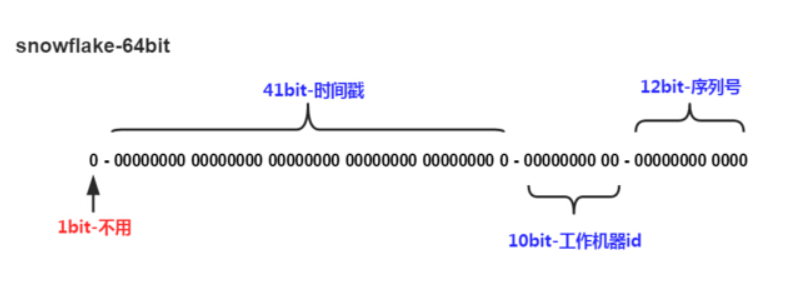
snowflake is an open source distributed ID generation algorithm for Twitter. The result is a long ID. The core idea is to use 41 bits as milliseconds, 10 bits as machine ID (5 bits as data center, 5 bits as machine ID), 12 bits as pipeline number in milliseconds (meaning that each node can generate 4096 IDs per millisecond), and finally a symbol bit, always 0.
The basic implementation of this algorithm is binary operation. If the binary system is unfamiliar, you can see the related articles I wrote before: the basic of java binary correlation, binary combat skills.
This algorithm can theoretically generate up to 1000 * (2 ^ 12), or 4096,000 ID s per second (roar, this is fast).
java implementation code is basically similar to this, but I changed it to meet the requirements of our business scenario, I will focus on the content of changes (almost, basically binary operation):
package com.ztesoft.res.gid.worker;
import org.springframework.stereotype.Component;
@Component
public class SnowflakeIdWorker {
// ==============================Fields===========================================
/** Start time cut-off (2015-01-01) */
private final long twepoch = 1420041600000L;
//(2010-01-01)
// private final long twepoch = 1262275200000L;
/** Number of digits occupied by resource type id */
private final long resTypeIdits = 14L;
/** Number of digits occupied by local network id */
private final long regionIdBits = 6L;
/** Number of digits occupied by machine device id */
private final long machineIdBits = 2L;
/** The maximum resource type id supported, as a result (the shift algorithm can quickly calculate the maximum decimal number represented by several bits of binary number) */
private final long maxResTypeId = -1L ^ (-1L << resTypeIdits);
/** Supported maximum data local network id, resulting in 31 */
private final long maxRegionId = -1L ^ (-1L << regionIdBits);
/** Supported maximum data machine device ID, resulting in 31 */
private final long maxMachineId = -1L ^ (-1L << machineIdBits);
/** Number of digits in id of sequence */
private final long sequenceBits = 3L;
/** Machine ID moved 3 bits to the left */
private final long machineIdShift = sequenceBits;
/** Resource Specification ID moved 5 bits to the left (3 + 2) */
private final long resTypeIdShift = sequenceBits + machineIdBits;
/** Local network ID moves left 19 bits (3 + 2 + 14) */
private final long regionIdShift = sequenceBits + machineIdBits + resTypeIdits;
/** Time truncation moves 25 bits to the left (3+2+14+6) */
private final long timestampLeftShift = sequenceBits + machineIdBits + resTypeIdits + regionIdBits;
/** Generate a sequence mask, here 7 */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** Local Network ID (0-63)*/
private long regionId;
/** Resource type ID (0-16383) */
private long resTypeId;
/** Machine Equipment ID(0~3) */
private long machineId;
/** Sequences in milliseconds (0-7) */
private long sequence = 0L;
/** Time cut of last ID generation */
private long lastTimestamp = -1L;
//==============================Constructors=====================================
public SnowflakeIdWorker(){}
/**
* Constructor
* @param resTypeId Resource type ID
* @param machineId machine ID
* @param regionId Local Network
*/
public SnowflakeIdWorker(long resTypeId, long machineId, long regionId) {
if (regionId > maxRegionId || regionId < 0) {
throw new IllegalArgumentException(String.format("region Id can't be greater than %d or less than 0", maxRegionId));
}
if (resTypeId > maxResTypeId || resTypeId < 0) {
throw new IllegalArgumentException(String.format("resTypeId can't be greater than %d or less than 0", maxResTypeId));
}
if (machineId > maxMachineId || machineId < 0) {
throw new IllegalArgumentException(String.format("machine Id can't be greater than %d or less than 0", maxMachineId));
}
this.regionId = regionId;
this.resTypeId = resTypeId;
this.machineId = machineId;
}
// ==============================Methods==========================================
/**
* Get the next ID (this method is thread-safe)
* @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
//If the current time is less than the time stamp generated by the last ID, the system clock should throw an exception when it falls back.
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//If it is generated at the same time, the sequence in milliseconds is performed.
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//Sequence overflow in milliseconds
if (sequence == 0) {
//Blocking to the next millisecond to get a new timestamp
timestamp = tilNextMillis(lastTimestamp);
}
}
//Time stamp change, sequence reset in milliseconds
else {
sequence = 0L;
}
//Time cut of last ID generation
lastTimestamp = timestamp;
//Shift and assemble 64-bit ID s together by operation or operation
return ((timestamp - twepoch) << timestampLeftShift)
| (regionId << regionIdShift)
| (resTypeId << resTypeIdShift)
| (machineId << machineIdShift)
| sequence;
}
/**
* Block to the next millisecond until a new timestamp is obtained
* @param lastTimestamp Time cut of last ID generation
* @return Current timestamp
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* Returns the current time in milliseconds
* @return Current time (milliseconds)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
private String lpad(String value, int maxLength){
StringBuffer sb = new StringBuffer(value);
for(int i = 0; i < (maxLength - value.length());i++){
sb.insert(0, "0");
}
return sb.toString();
}
//==============================Test=============================================
/** test */
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(200, 1, 22);
for (int i = 0; i < 100000; i++) {
Long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id)+" W:"+ Long.toBinaryString(id).length()+" ID:"+id);
}
}
}
Advantage:
Quick (Ha-ha, the world's martial arts can only be quickly broken).
There is no dependency, and implementation is particularly simple.
After knowing the principle, each section can be adjusted according to the actual situation, which is convenient and flexible.
Disadvantages:
The trend can only increase. (Some are not called shortcomings, some online if absolutely increasing, competitors order at noon, the next day in order can roughly judge the company's order volume, dangerous!!!)
Depending on machine time, if a callback occurs, id duplication may be generated.
The following focuses on the issue of time callback.
Analysis of the Reasons for Time Callback
Firstly, character manipulation, in the real environment, there is usually no fool to do this kind of thing, so it can be basically ruled out.
Secondly, due to some business and other needs, the machine needs to synchronize the time server (in this process there may be time callback, check our server generally within 10 ms (2 hours synchronization once).
Solution
Because it is distributed on each machine itself, if you want several centralized machines (and do not do time synchronization), then basically there is no possibility of callback (curve salvation is also national salvation, haha), but it does bring new problems, each node needs to access the centralized machine, to ensure performance, Baidu The uid-generator generation is based on this situation (every time a batch is taken back, good ideas, good performance) https://github.com/baidu/uid-generator.
If you adopt it here, there will be no problem at all. You don't need to read it. If you want to see Zero's own thinking, you can continue to look down. (Zero's thinking is just a kind of thinking, maybe not necessarily good, looking forward to your communication.) I haven't looked at the uid-generator yet, but it's very good to see the test report. It's good to see it when you have time.
Let's talk about Zero's own thinking. I also talked with the author of Leaf of the Art Corps before. Zero can solve some problems, but it introduces some other problems and dependencies. It's zero-degree thinking, looking forward to more big guys to give some advice.
Solutions to time problem callback:
When the callback time is less than 15 ms, wait for time to catch up and continue to generate.
When the time is longer than 15ms, we can solve the callback problem by replacing the workid which has not been generated before.
Firstly, the number of digits of workid is adjusted (15 digits can reach more than 30,000, generally enough).
Snowflake algorithm adjusts the lower segment slightly:
- sign(1bit)
Fixed 1 bit symbol identifier, that is, the generated smooth path distributed unique id is positive. - delta seconds (38 bits)
Current time, relative to the incremental value of the time base point "2017-12-21", in milliseconds, can support up to 8.716 years. - worker id (15 bits)
The machine id can support up to 328,000 nodes. - sequence (10 bits)
Concurrent sequence per second, 10 bits, this algorithm can theoretically generate up to 1000* (2 ^ 10) per second, that is, 100W ID, which can fully meet the needs of business.
Because of the stateless relationship of services, so the general workid is not configured in the specific configuration file. Look at my thinking in this article, why statelessness is needed. Some thoughts and understandings about high availability, here we choose redis for central storage (zk, db) are the same, as long as it is centralized.
Here's the key:
Now I put more than 30,000 workids in a queue (based on redis), because there is a need for a centralized place to manage workId. Whenever the node starts (first look at the local somewhere to see if there is a weak dependency zk local first saved), if there is a value, it will be used as a workid, if not, in the queue. Take one when the workid is used (the queue is taken away, it's gone), and when we find that there are too many callbacks, we go to the queue to get another when the new workid is used, and store the workid of the case we just used the callback into the queue (the queue is always taken from the beginning, inserted from the tail, so as to avoid rigidity). The possibility of Gang A machine being used and acquired by b machine.
There are several questions worth pondering:
- If redis is introduced, why don't redis send id? (Looking at the unique ID generation solution pool of distributed systems will always get the answer, we are here only for consistency queues, can do the basic consistency queues can be).
- Introducing redis means introducing other third-party architectures. It's better not to use redis as a basic framework (the simpler, the better, we are still learning to improve).
- How can redis consistency be guaranteed? (redis hang up how to do, how to synchronize, it is really worth discussing. It may introduce many new minor problems.