1 Demand analysis
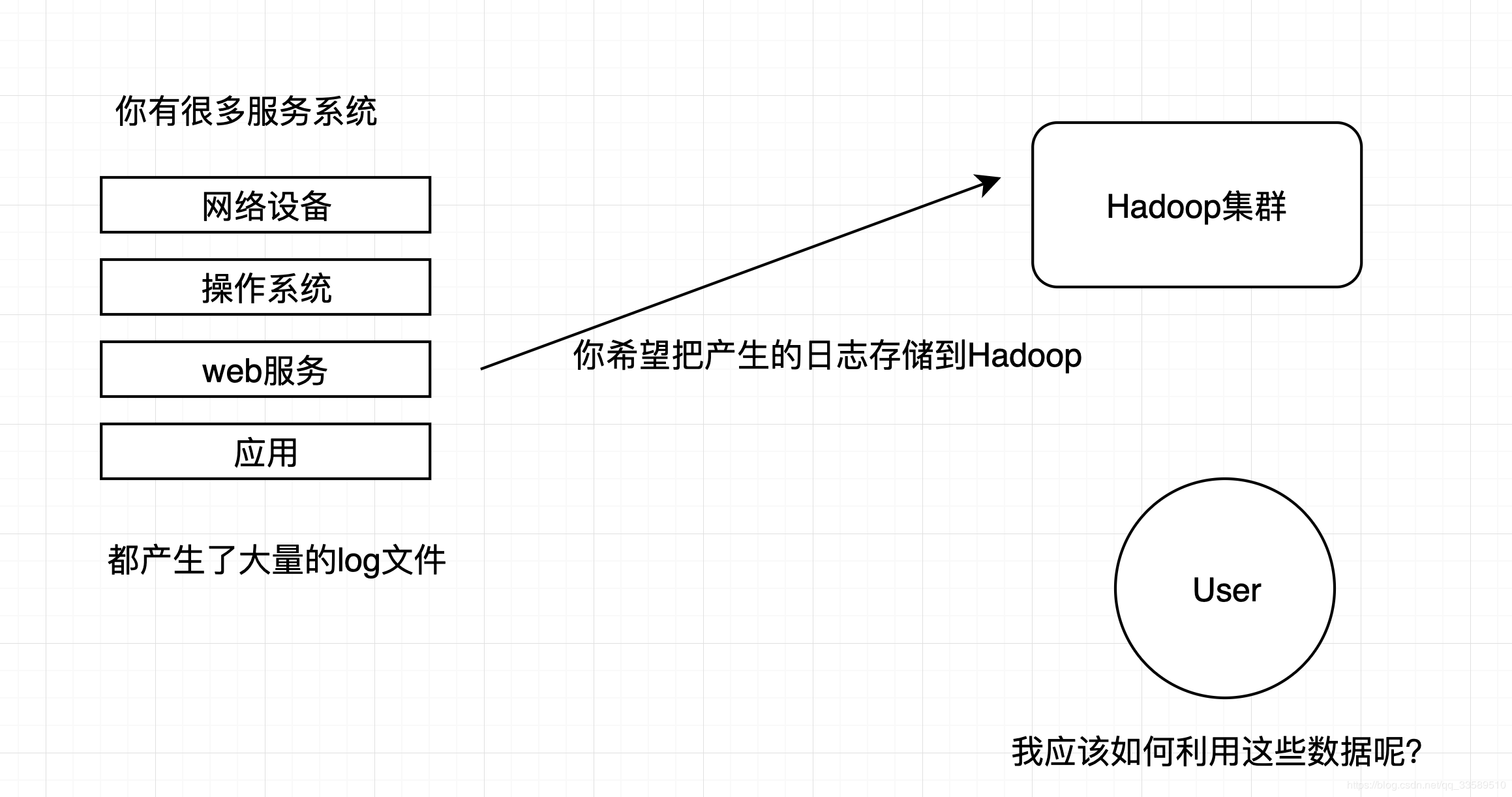 WebServer/Application Server is scattered across machines, but we still want to do statistical analysis on the Hadoop platform. How do we collect logs on the Hadoop platform?
WebServer/Application Server is scattered across machines, but we still want to do statistical analysis on the Hadoop platform. How do we collect logs on the Hadoop platform?
- Is that simple?
shell cp hadoop Clustered machines; hadoop fs -put ... /
Obviously, this method is facing a series of problems such as fault tolerance, load balancing, high latency, data compression, and so on. This is obviously not enough anymore!
Why not ask the magic Flume???
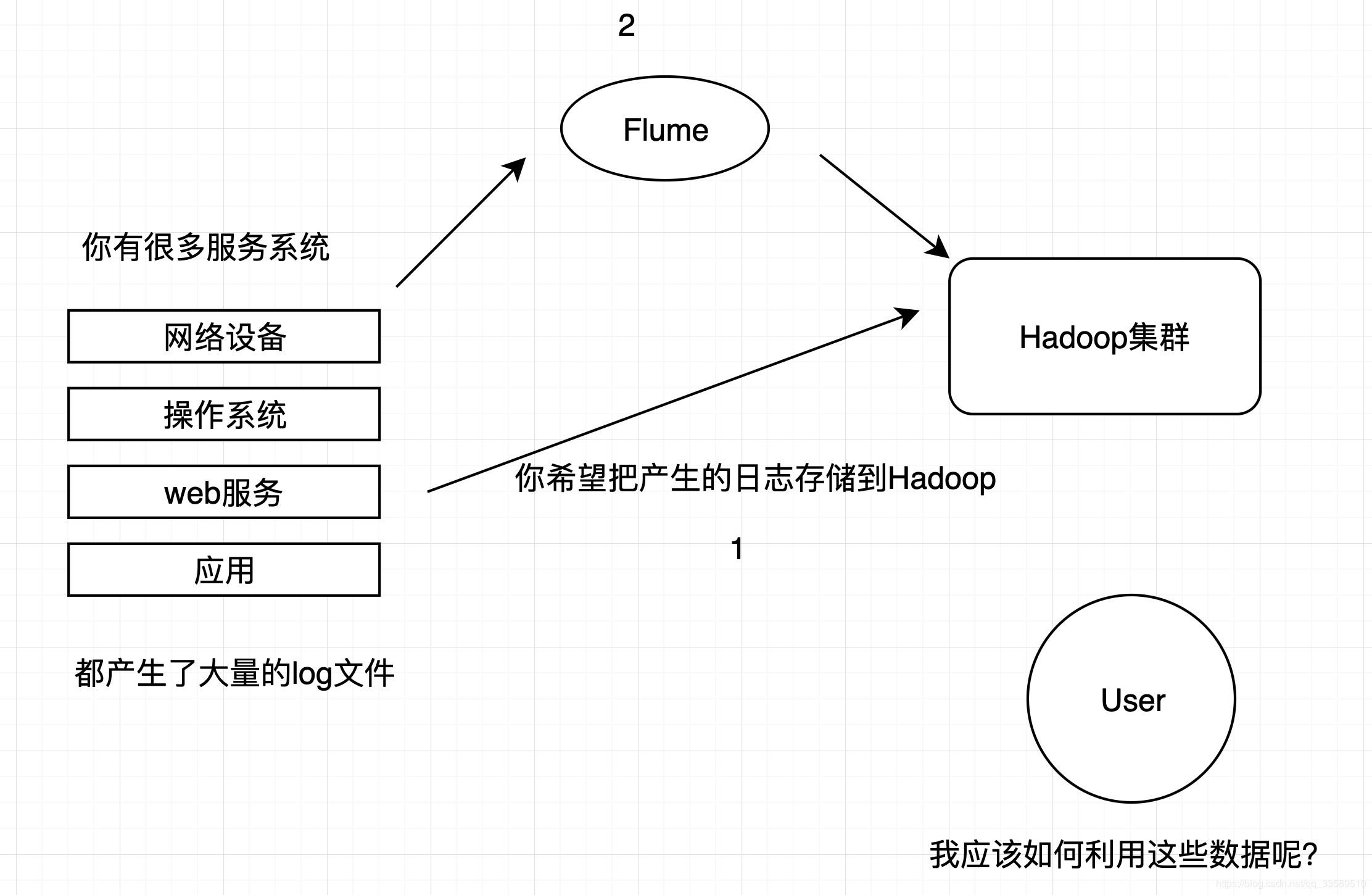
All you need is a configuration file to solve these problems easily!
2 Flume Overview
2.1 Official Web
- Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
- It has a simple and flexible architecture based on streaming data streams.
- It has reliable reliability mechanisms and many failover and recovery mechanisms, and has strong fault tolerance.
- It uses a simple, extensible data model that allows online analysis of applications.
2.2 Design objectives
-
reliability When a node fails, the log can be transferred to other nodes without loss.Flume provides three levels of reliability, from strong to weak: end-to-end (an agent that receives data writes event s to disk first, deletes them when the data transfer is successful, and resends if the data transfer fails.), Store on failure (which is also the strategy used by scribe to write data locally when the data receiver crash, and continue sending when it is recovered), and Best effort (data is sent to the receiver without confirmation).
-
Extensibility Flume uses a three-tier architecture, agent, collector, and storage, each of which can be scaled horizontally. All agent s and collector s are managed by the master, which makes the system easy to monitor and maintain, and the master allows multiple (ZooKeeper for management and load balancing), which avoids a single point of failure.
-
Administrative All agent s and colletor s are managed by the master, which makes the system easy to maintain.In the case of multiple masters, Flume uses ZooKeeper and gossip to ensure consistency of dynamic configuration data.Users can view the execution of individual data sources or streams on the master and configure and dynamically load individual data sources.Flume provides web and shell script command s for managing data streams.
-
Functional scalability Users can add their own agent, collector or storage as needed.In addition, Flume comes with many components, including agents (files, syslog, and so on), collectors, and storage (files, HDFS, and so on).
2.3 Mainstream Competition Comparison
 Other examples are:
Other examples are:
- Logstash: ELK(ElasticsSearch, Logstash, Kibana)
- Chukwa: Yahoo/Apache, developed in the Java language, has poor load balancing and is no longer maintained.
- Fluentd: Like Flume, Ruby was developed.
2.4 History of Development
- Cloudera proposed 0.9.2, called Flume-OG
- 2011 Flume-728 Number, Important Milestone (Flume-NG), Contributed to Apache Community
- July 1.0, 2012
- May 1.6, 2015
- ~ Version 1.9
3 Core Architecture and Its Components
3.1 core architecture
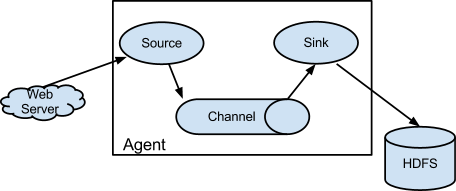
3.2 Core Components
By the way Official Documents
3.2.1 Source - Collection
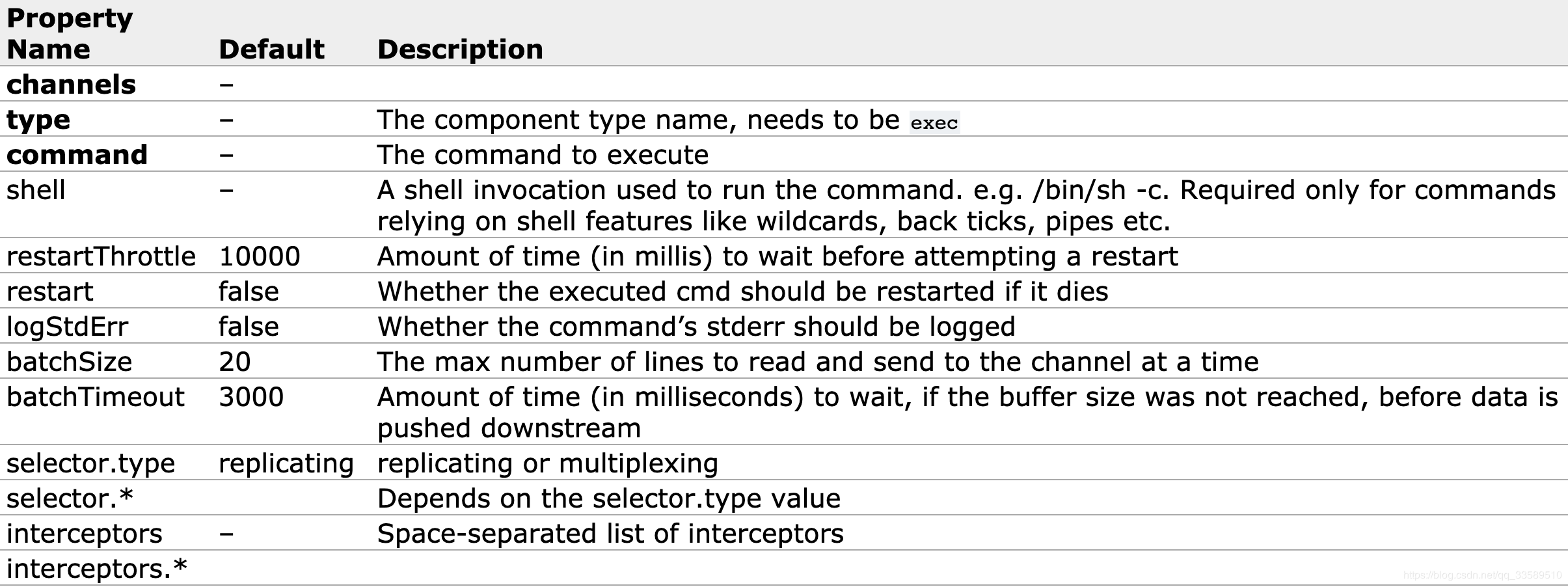
Specify the data source (Avro, Thrift, Spooling, Kafka, Exec)
3.2.2 Channel - Aggregation
Temporary storage of data (Memory, File, Kafka, etc.)

3.2.3 Sink - Output
Write data somewhere (HDFS, Hive, Logger, Avro, Thrift, File, ES, HBase, Kafka, etc.)

multi-agent flow
 In order to cross multiple agents or hop data streams, the receiver of the previous proxy and the source of the current hop need to be of avro type, with the receiver pointing to the host name (or IP address) and port of the source.
In order to cross multiple agents or hop data streams, the receiver of the previous proxy and the source of the current hop need to be of avro type, with the receiver pointing to the host name (or IP address) and port of the source.
Consolidation Consolidation
A common occurrence in log collection is when a large number of log generation clients send data to a small number of consumer agents connected to the storage subsystem.For example, logs collected from hundreds of Web servers are sent to more than a dozen agents writing to the HDFS cluster.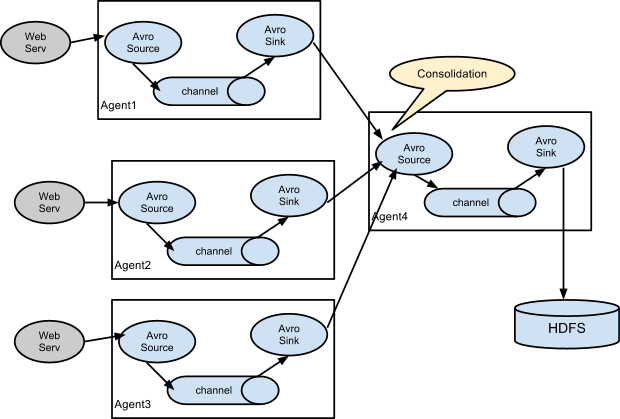 This can be achieved in Flume by configuring multiple first-tier proxies with an avro receiver, all pointing to a single proxy's avro source (again, you can use a thrift source/receiver/client in this case).This source on the second-tier proxy merges received events into a single channel consumed by the host to its final destination.
This can be achieved in Flume by configuring multiple first-tier proxies with an avro receiver, all pointing to a single proxy's avro source (again, you can use a thrift source/receiver/client in this case).This source on the second-tier proxy merges received events into a single channel consumed by the host to its final destination.
Multiplexing the flow
Flume supports multiplexing event streams to one or more destinations.This is achieved by defining a streaming multiplexer that can replicate or selectively route events to one or more channels.
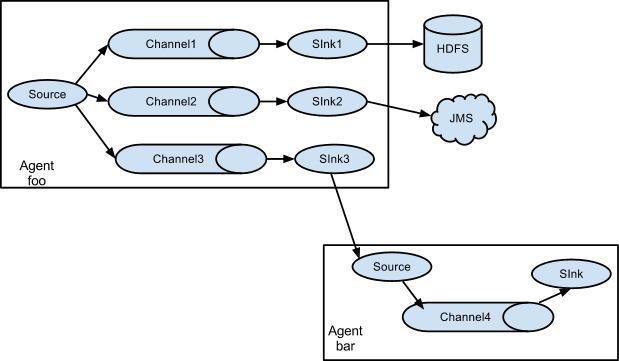 The example above shows that the source code from the proxy "foo" extends the process to three different channels.Fan out can be duplicated or multiplexed.In the case of replicating streams, each event is sent to all three channels.In the case of multiplexing, when the properties of the event match the preconfigured values, the event is passed to a subset of available channels.For example, if an event property named "txnType" is set to "customer", it should go to channel1 and channel3, and if it is "vendor", it should go to channel2, otherwise it should go to channel3.Mapping can be set in the proxy's configuration file.
The example above shows that the source code from the proxy "foo" extends the process to three different channels.Fan out can be duplicated or multiplexed.In the case of replicating streams, each event is sent to all three channels.In the case of multiplexing, when the properties of the event match the preconfigured values, the event is passed to a subset of available channels.For example, if an event property named "txnType" is set to "customer", it should go to channel1 and channel3, and if it is "vendor", it should go to channel2, otherwise it should go to channel3.Mapping can be set in the proxy's configuration file.
4 Environment Configuration and Deployment
4.1 System Requirements
- system macOS 10.14.14
- Java Runtime Environment Java 1.8 or later
- Memory Source Sufficient memory configured for channel or receiver use
- disk space Sufficient disk space configured for channel or receiver use
- directory right Read/Write permissions for directories used by agents
4.2 Download and Install

4.3 Configuration
- View Installation Path

- configuration system file
export FLUME_VERSION=1.9.0 export FLUME_HOME=/usr/local/Cellar/flume/1.9.0/libexec export FLUME_CONF_DIR=$FLUME_HOME/conf export PATH=$FLUME_HOME/bin:$PATH
- flume profile
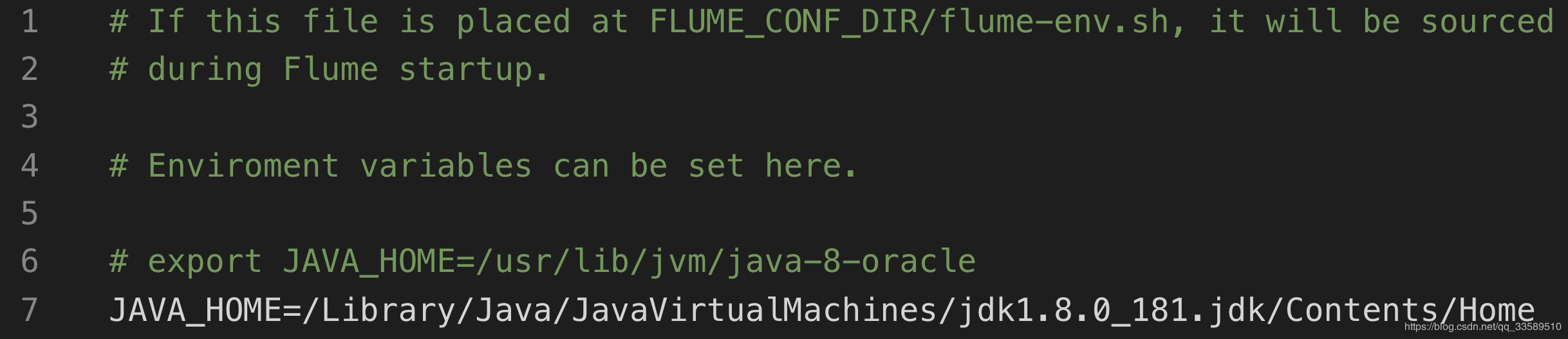
Configure JAVA_HOME
- Verification
Command Execution File under bin

Installation Successful

5 Actual Warfare
Configuration files are the core of using Flume
- Configure Source
- Configure Channel
- Configure Sink
- Group together
5.1 Scenario 1 - Collect data from a specified network port and output to the console
Look at the first one on the official website case
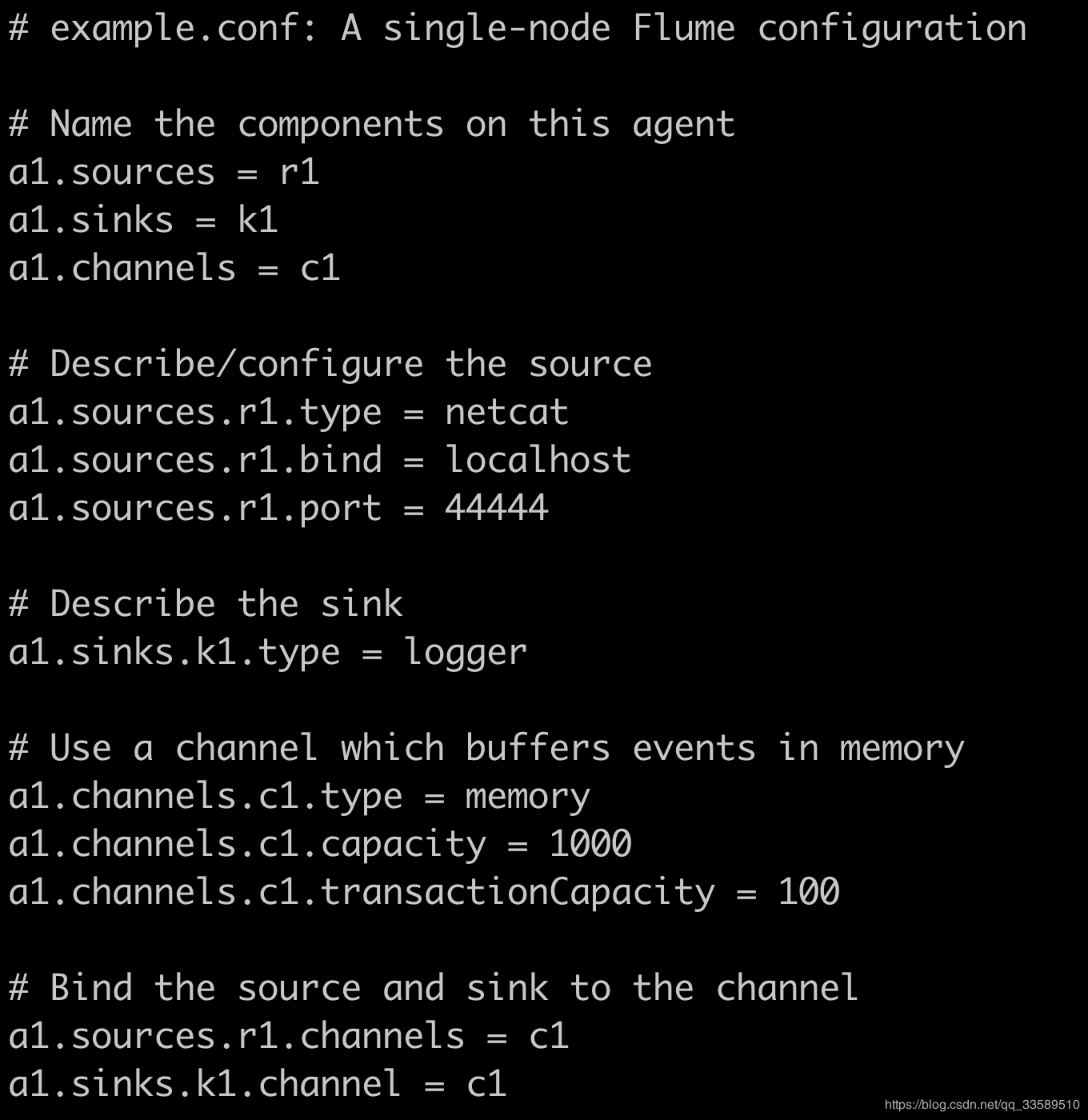
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
a1:agent name r1:Source name k1:Sink name c1:Channel name
Look at the
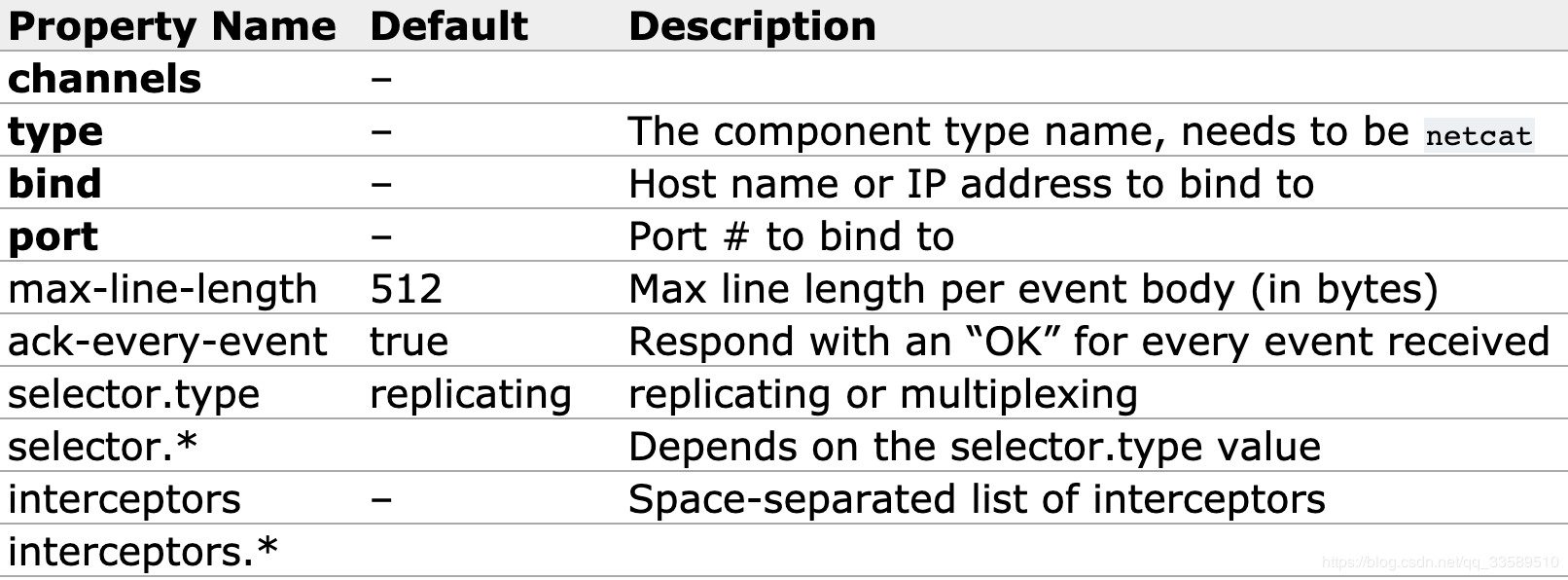
Sources : netcat
Like a netcat source, it listens for a given port and converts each line of text into an event.Behavior like nc-k-l [host] [port].In other words, it opens a specified port and listens for data.Expect the data provided to be line-break delimited text.Each line of text is converted to a Flume event and sent over a connected channel.
Required properties are shown in bold.
Sinks: logger
Log events at the INFO level.Usually used for testing/debugging purposes.Required properties are shown in bold.The only exception is this receiver, which does not require additional configuration as described in the Recording Raw Data section.

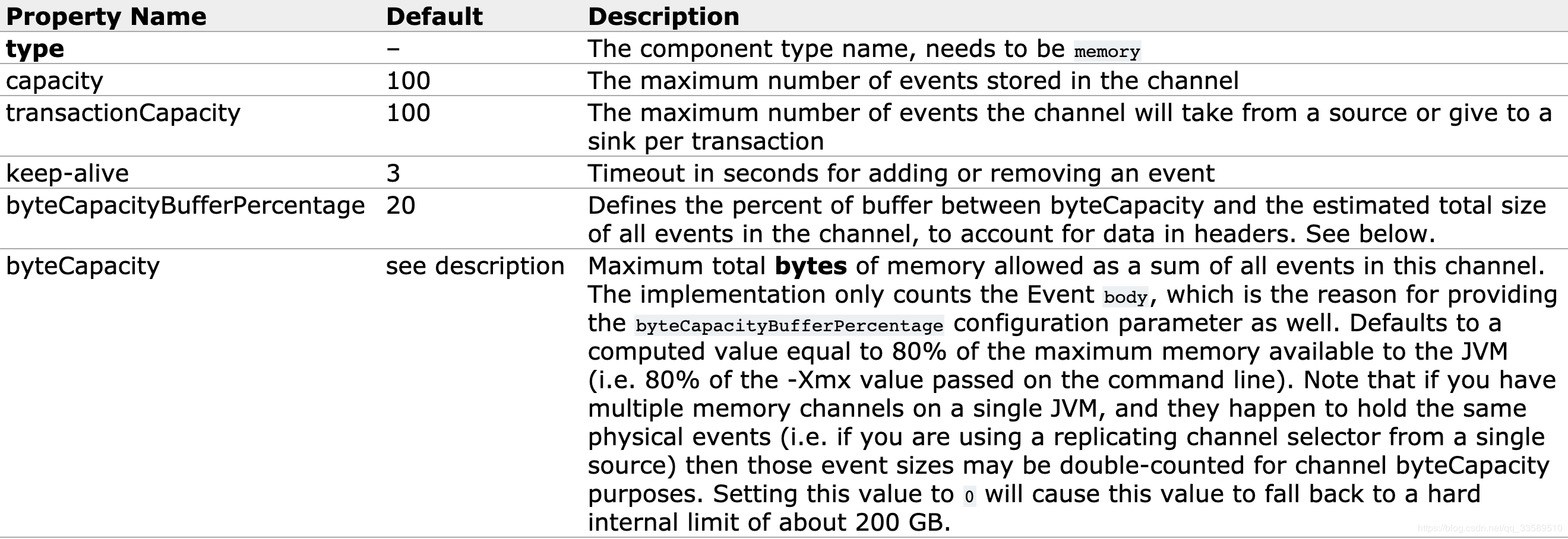
channel: memor
Events are stored in an in-memory queue with a maximum configurable size.It is ideal for traffic that requires higher throughput and is ready to lose phased data in the event of agent failure.Required properties are shown in bold.
actual combat
New example.conf configuration
Under conf directory
Start an agent
Start the agent using a shell script named flume-ng, which is located in the bin directory of the Flume distribution.You need to specify the proxy name, config directory, and configuration file on the command line:
bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
- Review the significance of command parameters
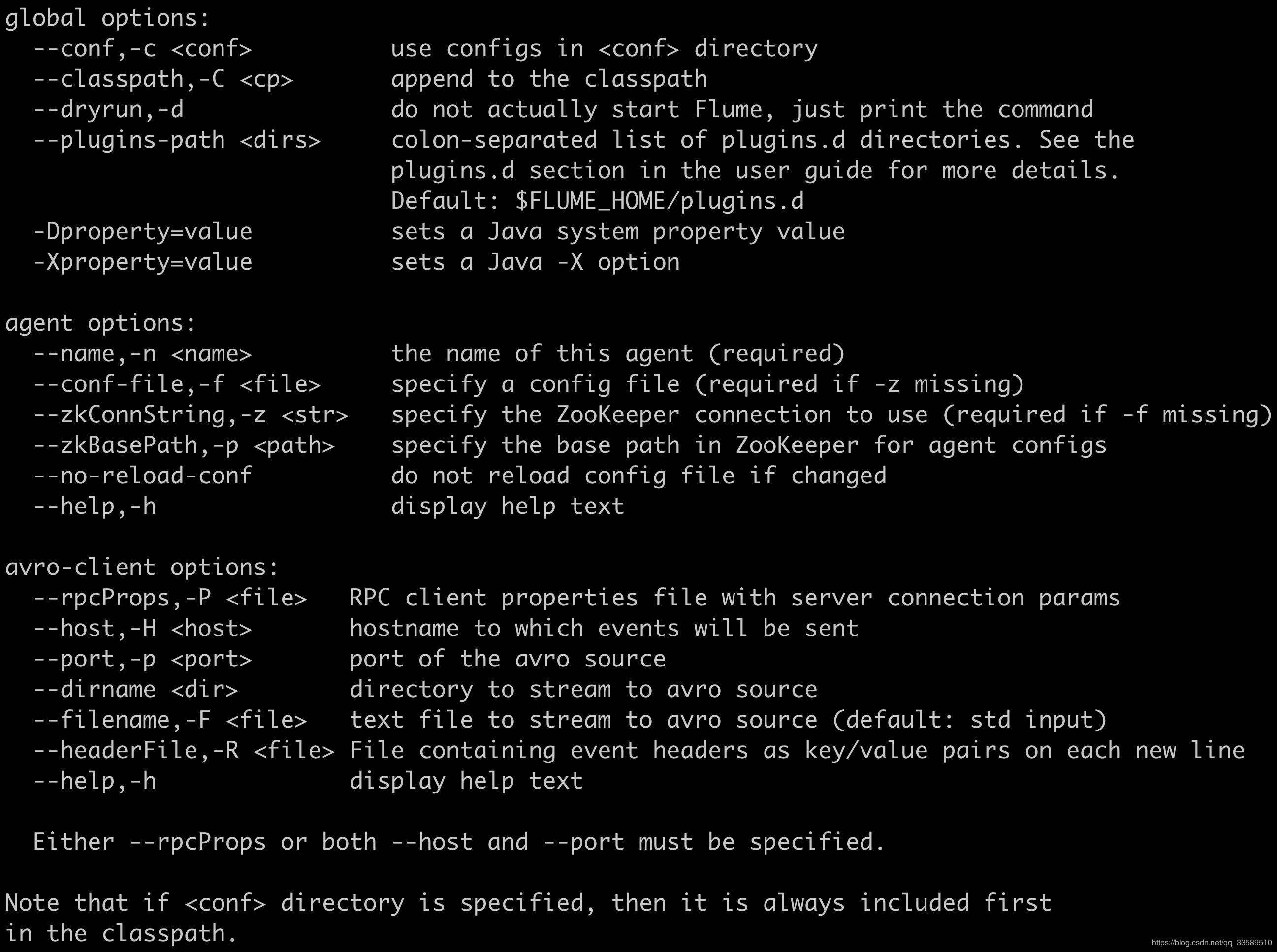
bin/flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/conf/example.conf \ -Dflume.root.logger=INFO,console
The agent will now start running the source and receiver configured in the given properties file.
Use telnet for test validation
- Be careful

telnet 127.0.0.1 44444
- Two pieces of data were sent
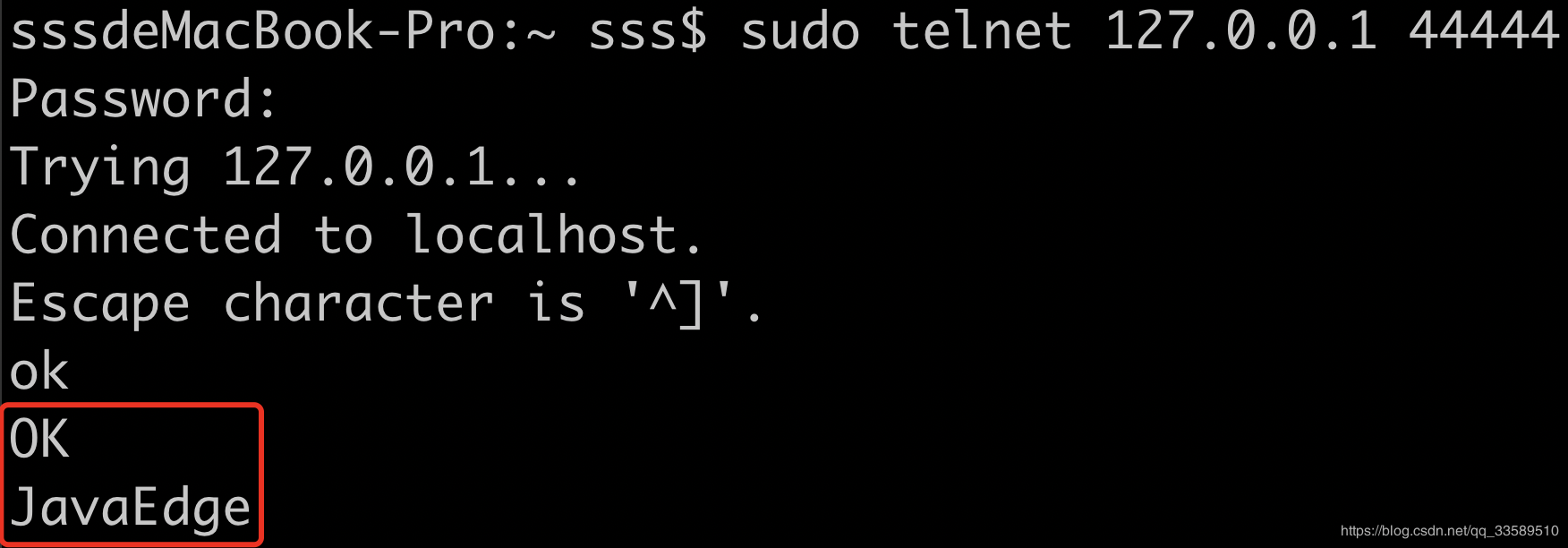
- Received data here
 Let's take a closer look at the data in the figure below
Let's take a closer look at the data in the figure below
2019-06-12 17:52:39,711 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 4A 61 76 61 45 64 67 65 0D JavaEdge. }
Event is the basic unit of Fluem data transmission Event = optional header + byte array
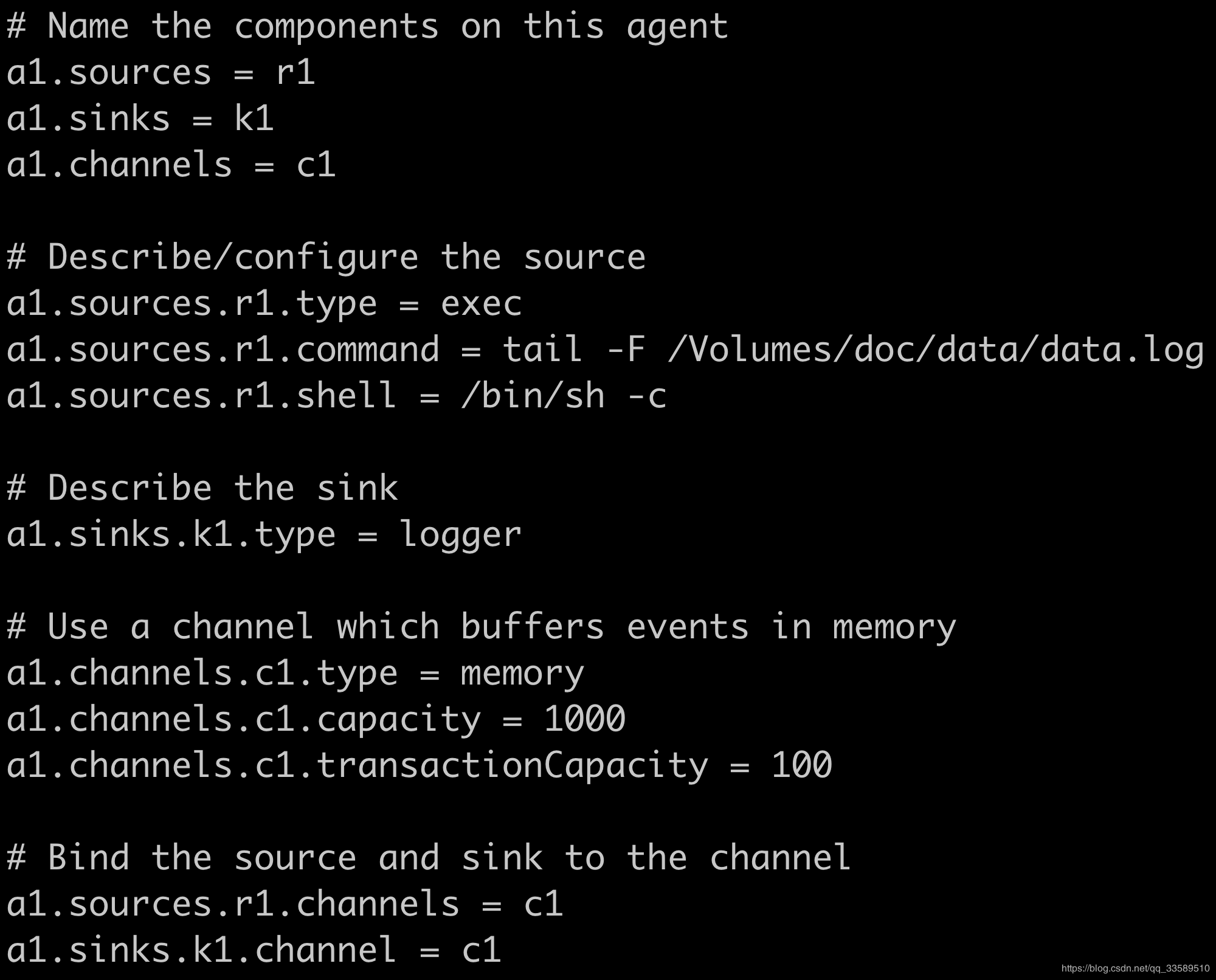
5.2 Scenario 2 - Monitor a file to collect new data in real time and output it to the console
Exec Source
The Exec source runs the given Unix command at startup and expects the process to continuously generate data on standard output (stderr is simply discarded unless the property logStdErr is set to true).If the process exits for any reason, the source also exits and no other data is generated.This means that configurations such as cat [named pipe] or tail-F [file] will produce the desired results, while the date may not - the first two commands produce data streams, which produce a single event and exit
Agent Selection
exec source + memory channel + logger sink
configuration file
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /Volumes/doc/data/data.log a1.sources.r1.shell = /bin/sh -c # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Create a new configuration file under conf as follows:
-
data.log file content

-
Successful Receive

5.3 Scenario 3 - Collect logs from server A to server B in real time
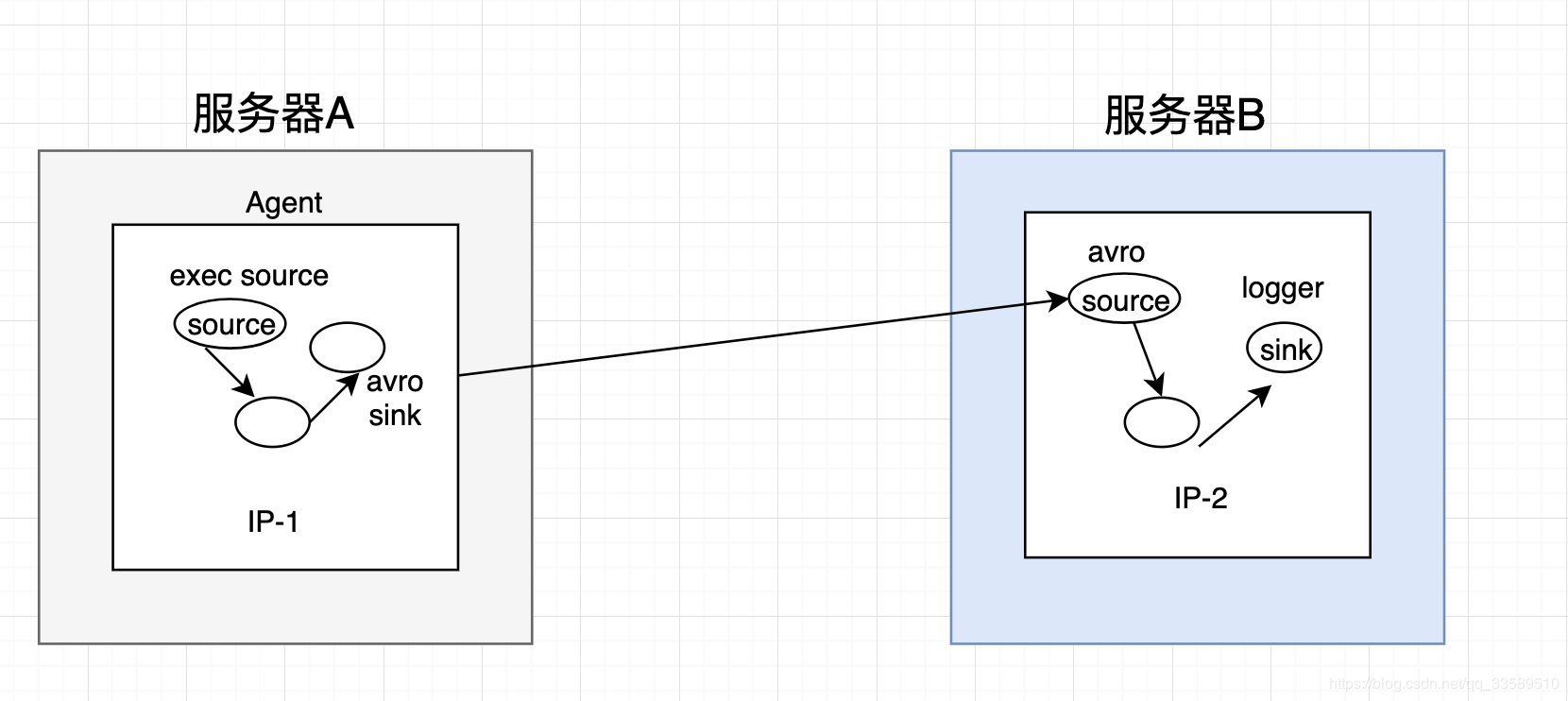
Technical Selection
exec s + memory c + avro s avro s + memory c + loger s
configuration file
exec-memory-avro.conf
# Name the components on this agent exec-memory-avro.sources = exec-source exec-memory-avro.sinks = avro-sink exec-memory-avro.channels = memory-channel # Describe/configure the source exec-memory-avro.sources.exec-source.type = exec exec-memory-avro.sources.exec-source.command = tail -F /Volumes/doc/data/data.log exec-memory-avro.sources.exec-source.shell = /bin/sh -c # Describe the sink exec-memory-avro.sinks.avro-sink.type = avro exec-memory-avro.sinks.avro-sink.hostname = localhost exec-memory-avro.sinks.avro-sink.port = 44444 # Use a channel which buffers events in memory exec-memory-avro.channels.memory-channel.type = memory exec-memory-avro.channels.memory-channel.capacity = 1000 exec-memory-avro.channels.memory-channel.transactionCapacity = 100 # Bind the source and sink to the channel exec-memory-avro.sources.exec-source.channels = memory-channel exec-memory-avro.sinks.avro-sink.channel = memory-channel
# Name the components on this agent exec-memory-avro.sources = exec-source exec-memory-avro.sinks = avro-sink exec-memory-avro.channels = memory-channel # Describe/configure the source exec-memory-avro.sources.exec-source.type = exec exec-memory-avro.sources.exec-source.command = tail -F /Volumes/doc/data/data.log exec-memory-avro.sources.exec-source.shell = /bin/sh -c # Describe the sink exec-memory-avro.sinks.avro-sink.type = avro exec-memory-avro.sinks.avro-sink.hostname = localhost exec-memory-avro.sinks.avro-sink.port = 44444 # Use a channel which buffers events in memory exec-memory-avro.channels.memory-channel.type = memory exec-memory-avro.channels.memory-channel.capacity = 1000 exec-memory-avro.channels.memory-channel.transactionCapacity = 100 # Bind the source and sink to the channel exec-memory-avro.sources.exec-source.channels = memory-channel exec-memory-avro.sinks.avro-sink.channel = memory-channel
Reference resources
https://tech.meituan.com/2013/12/09/meituan-flume-log-system-architecture-and-design.html