problem
(1) How does redis implement distributed locks?
(2) What are the advantages of redis distributed locks?
(3) What are the disadvantages of redis distributed locks?
(4) Are there wheels available for redis to implement distributed locks?
brief introduction
Redis (full name: Remote Dictionary Server Remote Dictionary Service) is an open source log-based, Key-Value database written in ANSI C language, supporting network, memory-based and persistent, and providing multi-language API s.
In this chapter, we will introduce how to implement distributed locks based on redis, and explain the evolution history of their implementation from beginning to end, so that when we interview, we can clearly explain the redis distributed locks.
Conditions for realizing locks
Based on the previous study of locks (distributed locks), we know that there are three conditions for realizing locks:
(1) State (shared) variable, which is stateful, whose value identifies whether it has been locked, is implemented in ReentrantLock by controlling the value of state, and in ZookeeperLock by controlling the child nodes.
(2) Queue, which is used to store queued threads, is realized by AQS queue in ReentrantLock and by orderliness of sub-nodes in ZookeeperLock.
(3) Wake-up, wake-up the next waiting thread after the last thread releases the lock, and automatically wake-up the next thread when the queue releases in ReentrantLock combined with AQS. In ZookeeperLock, it is realized through its listening mechanism.
So are the above three conditions necessary?
In fact, the only necessary condition to realize the lock is the first. To control the shared variable, if the value of the shared variable is null, set a value to it (CAS can be used to operate the shared variable in the process in java). If the shared variable has value, repeatedly check whether it has value (retry), and then set the value of the shared variable back to null after the lock logic has been executed.
To put it bluntly, just have a place to store this shared variable, and make sure that only one share of the whole system (multiple processes) is available.
This is also the key for redis to implement distributed locks.
Distributed Lock Evolution History of redis
History of Evolution I - set
Since the above mentioned implementation of distributed locks requires only the control of shared variables in place, how do we control the shared variables redis?
First of all, we know that the basic command of redis is get/set/del. Can distributed locks be implemented through these three commands? Certainly.
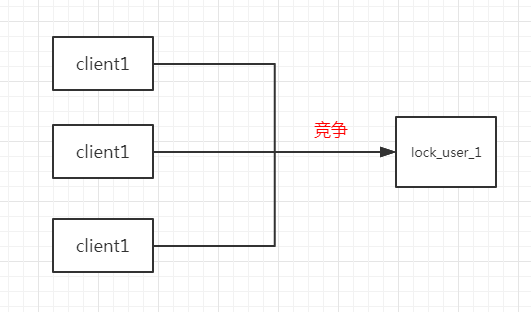
Before acquiring the lock, get lock_user_1 to see that the lock does not exist. If it does not exist, set lock_user_1 value. If it exists, wait for a period of time and try again. Finally, delete the lock del lock_user_1 after using it.
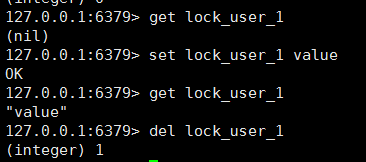
However, there is a problem with this scheme. If at first the lock does not exist and two threads get at the same time, then both threads return null (nil), and then both threads go to set, then the problem arises. Both threads can set successfully, which is equivalent to two threads acquiring the same lock.
Therefore, this scheme is not feasible!
History of Evolution II - setnx
The main reason why the above scheme is not feasible is that multiple threads set at the same time can be successful, so later the command setnx, which is the abbreviation of set if not exist, is set if it does not exist.
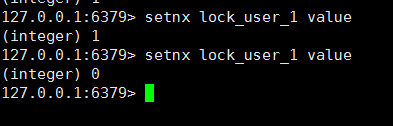
As you can see, when setnx is repeated on the same key, only the first time is successful.
Therefore, the second scenario is to use the setnx lock_user_1 value command first, if return 1 indicates successful lock, if return 0 indicates successful execution of other threads first, then wait for a period of time and try again, and finally release the lock with dellock_user_1.
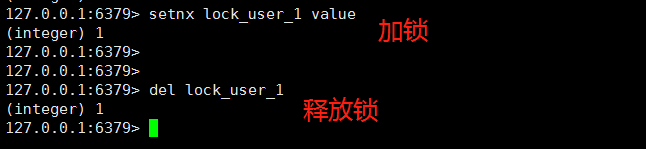
However, there is a problem with this scheme. What if the client that acquires the lock is disconnected? Isn't this lock never released? Yes, it is.
So, this scheme is not feasible!
History of Evolution III - setnx + setex
The main reason why the above scheme is infeasible is that the client can't release the lock after getting the lock. So, can I execute setex immediately after setnx?
The answer is yes. Previous versions of 2.6.12 used redis to implement distributed locks.
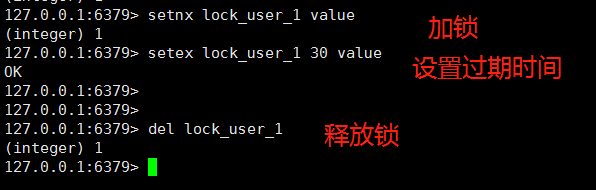
Therefore, the third scheme is to use the setnx lock_user_1 value command to get the lock first, then immediately set the expiration time with setex lock_user_1 30 value, and finally release the lock with del lock_user_1.
After the setnx acquires the lock, the setex setup expiration time is executed, which solves the problem that the client will not release the lock when the client disconnects after acquiring the lock.
However, there are still problems with this solution. What if the client is disconnected before setex after setnx? Well, it seems that there is no solution, but this probability is really very small, so the previous version of 2.6.12 is also used by everyone, and there are hardly any problems.
So, this scheme is basically available, but not very good!
History of Evolution IV-set nx ex
The main reason why the above scheme is not so good is that setnx/setex is two separate commands, which can not solve the problem of client disconnection after the former is successful. So, can't we just combine the two commands?
Yes, redis officials are aware of this problem, so version 2.6.12 adds some parameters to the set command:
SET key value [EX seconds] [PX milliseconds] [NX|XX]
EX, expiration time, unit second
PX, expiration time, unit milliseconds
NX, not exist, if not set up successfully
XX, exist? Successful setup if it exists
Through this command, we are no longer afraid that the client will break without reason.
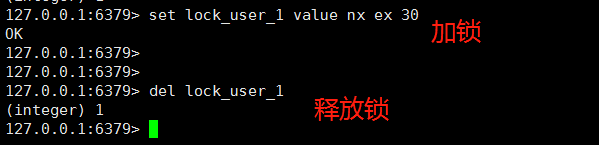
Therefore, the fourth scheme is to use set lock_user_1 value nx ex 30 to acquire the lock first, then use it after acquiring the lock, and use the last del lock_user_1 to release the lock.
However, is there no problem with this scheme?
Of course, there is a problem. In fact, the release lock here can simply execute dellock_user_1, and does not check whether the lock is acquired by the current client.
Therefore, this scheme is not perfect.
Evolutionary History V - random value + lua script
The main reason for the incompleteness of the above scheme is that the release lock is not well controlled here, so is there any other way to control the release lock thread and the lock thread must be the same client?
The official plan given by redis is as follows:
// Lock up
SET resource_name my_random_value NX PX 30000
// Release lock
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
endWhen locking, set a random value to ensure that the random value is known only by the current client itself.
When releasing the lock, execute a lua script, treat the lua script as a complete command. First check whether the corresponding value of the lock is the random value set above, and then execute the del release lock, otherwise the release lock will fail directly.
We know that redis is single-threaded, so there is no concurrency problem with get and del in this lua script, but we can't get first and then del in java. This will be regarded as two commands, and there will be concurrency problem. The lua script is equivalent to a command transmitted to redis together.
This scheme is perfect, but there is a small flaw, that is, how appropriate is the expiration time set?
If the settings are too small, it is possible that the lock will be released automatically before the last thread has finished executing the logic in the lock, which leads to the problem of concurrency when another thread can acquire the lock.
If the settings are too large, it is necessary to consider that the client is disconnected. This lock will wait a long time.
So, a new problem arises here. I set the expiration time a little bit smaller, but it can automatically renew as soon as it expires.
History of Evolution VI - redisson (redis 2.8+)
The defect of the above scheme is that the expiration time is not easy to grasp. Although we can also start a monitoring thread to handle the renewal, the code is not very easy to write. Fortunately, the existing wheel redisson has helped us to implement this logic, so we can take it and use it directly.
Moreover, redisson fully considers all the problems left behind in the evolution of redis, such as single-machine mode, sentry mode and cluster mode, which are all handled well. Whether it evolves from single-machine mode to cluster mode or from sentry mode to cluster mode, it only needs to modify the configuration simply. Without changing any code, it can be said that it is right (industry) and normal (boundary) side (conscience) convenient (conscience). )
Redlock algorithm is used in redisson distributed lock, which is officially recommended.
In addition, redisson also provides many distributed objects (distributed atomic classes), distributed collections (distributed Map/List/Set/Queue, etc.), distributed synchronizers (distributed CountDownLatch/Semaphore, etc.), distributed locks (distributed fair locks/unfair locks/read-write locks, etc.), which can be viewed with interest. The following links are posted:

Introduction to Redlock: https://redis.io/topics/distlock
Introduction to redisson: https://github.com/redisson/redisson/wiki
code implementation
Because the first five schemes are out of date, so we don't want to achieve the goal of redisson.
pom.xml file
Adding spring redis and redisson dependencies, I use Springboot version 2.1.6 here, Springboot version 1.x under your own attention, check the github above to find a way.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-data-21</artifactId>
<version>3.11.0</version>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.11.0</version>
</dependency>application.yml file
Configure redis's connection information. Tong Ge here gives three ways.
spring:
redis:
# standalone mode
#host: 192.168.1.102
#port: 6379
# password: <your passowrd>
timeout: 6000ms # Connection timeout length (milliseconds)
# Sentinel mode [this article is written by the public number "Tong Ge read the source code" original).
# sentinel:
# master: <your master>
# nodes: 192.168.1.101:6379,192.168.1.102:6379,192.168.1.103:6379
# Cluster Model (Three Principals, Three Subordinates and Pseudo Clusters)
cluster:
nodes:
- 192.168.1.102:30001
- 192.168.1.102:30002
- 192.168.1.102:30003
- 192.168.1.102:30004
- 192.168.1.102:30005
- 192.168.1.102:30006Locker interface
Define the Locker interface.
public interface Locker {
void lock(String key, Runnable command);
}RedisLocker implementation class
Use RedissonClient to get locks directly. Note that there is no need to configure the RedissonClient bean separately. The redisson framework automatically generates instances of RedissonClient according to the configuration. We will talk about how it is implemented later.
@Component
public class RedisLocker implements Locker {
@Autowired
private RedissonClient redissonClient;
@Override
public void lock(String key, Runnable command) {
RLock lock = redissonClient.getLock(key);
try {
// This article is from the public number "Tong Ge read the source code" original.
lock.lock();
command.run();
} finally {
lock.unlock();
}
}
}Test class
Start 1000 threads, print a sentence inside each thread, and sleep for 1 second.
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class RedisLockerTest {
@Autowired
private Locker locker;
@Test
public void testRedisLocker() throws IOException {
for (int i = 0; i < 1000; i++) {
new Thread(()->{
locker.lock("lock", ()-> {
// Re-entrant lock test
locker.lock("lock", ()-> {
System.out.println(String.format("time: %d, threadName: %s", System.currentTimeMillis(), Thread.currentThread().getName()));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
});
}, "Thread-"+i).start();
}
System.in.read();
}
}Operation results:
You can see that a sentence is printed stably around 1000ms, indicating that the lock is available and reentrant.
time: 1570100167046, threadName: Thread-756 time: 1570100168067, threadName: Thread-670 time: 1570100169080, threadName: Thread-949 time: 1570100170093, threadName: Thread-721 time: 1570100171106, threadName: Thread-937 time: 1570100172124, threadName: Thread-796 time: 1570100173134, threadName: Thread-944 time: 1570100174142, threadName: Thread-974 time: 1570100175167, threadName: Thread-462 time: 1570100176180, threadName: Thread-407 time: 1570100177194, threadName: Thread-983 time: 1570100178206, threadName: Thread-982 ...
RedissonAutoConfiguration
Just now I said that RedissonClient does not need to be configured. In fact, it is automatically configured in RedissonAutoConfiguration. Let's take a brief look at its source code and mainly look at redisson() as a method:
@Configuration
@ConditionalOnClass({Redisson.class, RedisOperations.class})
@AutoConfigureBefore(RedisAutoConfiguration.class)
@EnableConfigurationProperties({RedissonProperties.class, RedisProperties.class})
public class RedissonAutoConfiguration {
@Autowired
private RedissonProperties redissonProperties;
@Autowired
private RedisProperties redisProperties;
@Autowired
private ApplicationContext ctx;
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<Object, Object>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean(StringRedisTemplate.class)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean(RedisConnectionFactory.class)
public RedissonConnectionFactory redissonConnectionFactory(RedissonClient redisson) {
return new RedissonConnectionFactory(redisson);
}
@Bean(destroyMethod = "shutdown")
@ConditionalOnMissingBean(RedissonClient.class)
public RedissonClient redisson() throws IOException {
Config config = null;
Method clusterMethod = ReflectionUtils.findMethod(RedisProperties.class, "getCluster");
Method timeoutMethod = ReflectionUtils.findMethod(RedisProperties.class, "getTimeout");
Object timeoutValue = ReflectionUtils.invokeMethod(timeoutMethod, redisProperties);
int timeout;
if(null == timeoutValue){
// Time-out is not set to 0
timeout = 0;
}else if (!(timeoutValue instanceof Integer)) {
// Millisecond transfer
Method millisMethod = ReflectionUtils.findMethod(timeoutValue.getClass(), "toMillis");
timeout = ((Long) ReflectionUtils.invokeMethod(millisMethod, timeoutValue)).intValue();
} else {
timeout = (Integer)timeoutValue;
}
// See if you've written a separate configuration file for redisson
if (redissonProperties.getConfig() != null) {
try {
InputStream is = getConfigStream();
config = Config.fromJSON(is);
} catch (IOException e) {
// trying next format
try {
InputStream is = getConfigStream();
config = Config.fromYAML(is);
} catch (IOException e1) {
throw new IllegalArgumentException("Can't parse config", e1);
}
}
} else if (redisProperties.getSentinel() != null) {
// If it's Sentinel mode
Method nodesMethod = ReflectionUtils.findMethod(Sentinel.class, "getNodes");
Object nodesValue = ReflectionUtils.invokeMethod(nodesMethod, redisProperties.getSentinel());
String[] nodes;
// Look at sentinel.nodes. Is this node a list configuration or a comma-separated configuration?
if (nodesValue instanceof String) {
nodes = convert(Arrays.asList(((String)nodesValue).split(",")));
} else {
nodes = convert((List<String>)nodesValue);
}
// Configuration of Generating Sentinel Mode
config = new Config();
config.useSentinelServers()
.setMasterName(redisProperties.getSentinel().getMaster())
.addSentinelAddress(nodes)
.setDatabase(redisProperties.getDatabase())
.setConnectTimeout(timeout)
.setPassword(redisProperties.getPassword());
} else if (clusterMethod != null && ReflectionUtils.invokeMethod(clusterMethod, redisProperties) != null) {
// If it is cluster mode
Object clusterObject = ReflectionUtils.invokeMethod(clusterMethod, redisProperties);
Method nodesMethod = ReflectionUtils.findMethod(clusterObject.getClass(), "getNodes");
// Cluster mode cluster.nodes are list configurations
List<String> nodesObject = (List) ReflectionUtils.invokeMethod(nodesMethod, clusterObject);
String[] nodes = convert(nodesObject);
// Configuration of Generating Cluster Patterns
config = new Config();
config.useClusterServers()
.addNodeAddress(nodes)
.setConnectTimeout(timeout)
.setPassword(redisProperties.getPassword());
} else {
// Configuration of stand-alone mode
config = new Config();
String prefix = "redis://";
Method method = ReflectionUtils.findMethod(RedisProperties.class, "isSsl");
// Judging whether to go ssl
if (method != null && (Boolean)ReflectionUtils.invokeMethod(method, redisProperties)) {
prefix = "rediss://";
}
// Configuration of generating stand-alone mode
config.useSingleServer()
.setAddress(prefix + redisProperties.getHost() + ":" + redisProperties.getPort())
.setConnectTimeout(timeout)
.setDatabase(redisProperties.getDatabase())
.setPassword(redisProperties.getPassword());
}
return Redisson.create(config);
}
private String[] convert(List<String> nodesObject) {
// Converting Sentinel or Cluster Mode nodes into Standard Configuration
List<String> nodes = new ArrayList<String>(nodesObject.size());
for (String node : nodesObject) {
if (!node.startsWith("redis://") && !node.startsWith("rediss://")) {
nodes.add("redis://" + node);
} else {
nodes.add(node);
}
}
return nodes.toArray(new String[nodes.size()]);
}
private InputStream getConfigStream() throws IOException {
// Read redisson configuration file
Resource resource = ctx.getResource(redissonProperties.getConfig());
InputStream is = resource.getInputStream();
return is;
}
}Many of the configurations found on the Internet are redundant (possibly version problems). Looking at the source code is very clear, which is also a benefit of looking at the source code.
summary
(1) redis has three modes due to historical reasons: single aircraft, sentry and cluster;
(2) The evolution history of redis implementing distributed locks: set-> set nx-> setnx + set ex-> set NX ex (or px) -> set NX ex (or px) + Lua script-> redisson;
(3) redis distributed locks have ready-made wheel redisson to use;
(4) redisson also provides many useful components, such as distributed collections, distributed synchronizers and distributed objects.
Egg
What are the advantages of redis distributed locks?
Answer: 1) Most systems rely on redis for caching, and do not need to rely on other components (as opposed to zookeeper);
2) redis can be deployed in clusters, which is more reliable than mysql.
3) It will not occupy the number of connections of MySQL and increase the pressure of mysql.
4) The redis community is relatively active, and the realization of redisson is more stable and reliable.
5) Using expiration mechanism to solve the problem of client disconnection, although not in time;
6) The existing wheel redisson can be used, and the types of locks are quite complete.
What are the disadvantages of redis distributed locks?
Answer: 1) Locking commands will be executed on all master nodes in cluster mode. Most (2N+1) locks will be acquired if they succeed. The more nodes, the slower the process of locking.
2) In the case of high concurrency, threads without locks will sleep retry, and if the competition for the same lock is very fierce, it will occupy a lot of system resources.
3) There are so many pits caused by historical reasons that it is difficult to implement robust redis distributed locks.
In short, the advantages of redis distributed locks outweigh the disadvantages, and the community is active, which is why most of our systems use redis as distributed locks.
Recommended reading
1,The Beginning of the Dead java Synchronization Series
2,Unsafe Analysis of Dead java Magic
3,JMM (Java Memory Model) of Dead java Synchronization Series
4,volatile analysis of dead java synchronization series
5,synchronized analysis of dead-end java synchronization series
6,Write a Lock by Hand in Dead java Synchronization Series
7,AQS Beginning of the Dead java Synchronization Series
9,ReentrantLock Source Code Resolution of Dead java Synchronization Series (2) - Conditional Lock
10,ReentrantLock VS synchronized
11,ReentrantReadWriteLock Source Parsing of Dead java Synchronization Series
12,Semaphore Source Parsing of Dead java Synchronization Series
13,CountDownLatch Source Parsing of Dead java Synchronization Series
14,The Final AQS of the Dead java Synchronization Series
15,StampedLock Source Parsing of Dead java Synchronization Series
16,Cyclic Barrier Source Parsing of Dead java Synchronization Series
17,Phaser Source Parsing of Dead java Synchronization Series
18,mysql distributed lock of deadly java synchronization series
19,zookeeper Distributed Lock of Dead java Synchronization Series
Welcome to pay attention to my public number "Tong Ge read the source code", see more source series articles, and swim together with brother Tong's source ocean.
