hi, Hello, I'm Lao Tian
Today we share distributed locks. This paper uses five cases + diagrams + source code analysis to analyze them.
Common synchronized locks and locks are implemented based on a single JVM. What should I do in a distributed scenario? Then the distributed Lock appears.
There are three popular distributed implementation schemes in the industry:
1. Database based
2. Redis based
3. Based on Zookeeper
In addition, it is implemented by etcd and consumer.
Main contents of this paper
Distributed lock scenario
It is estimated that some friends do not know the distributed usage scenarios. Here are three types:
Case 1
The following code simulates the scenario of ordering and inventory reduction. Let's analyze the problems in the high concurrency scenario
@RestController
public class IndexController {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* Simulate the scenario of reducing inventory under an order
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
// Get the current inventory value from redis
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("Deduction succeeded, remaining inventory:" + realStock);
}else{
System.out.println("Deduction failed, insufficient inventory");
}
return "end";
}
}
Suppose the initial value of stock in Redis is 100.
Now that five clients request the interface at the same time, there may be simultaneous execution
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
Case 2 - using synchronized to implement single machine lock
After encountering the problem of case 1, most people think of locking to control the atomicity of transactions in their first reaction, as shown in the following code:
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
synchronized (this){
// Get the current inventory value from redis
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("Deduction succeeded, remaining inventory:" + realStock);
}else{
System.out.println("Deduction failed, insufficient inventory");
}
}
return "end";
}
Now, when multiple requests access the interface, only one request can enter the method body for inventory deduction at the same time, and the other requests wait.
But we all know that synchronized locks belong to the JVM level, which is commonly known as "stand-alone locks". But now most companies use cluster deployment. Now let's consider whether the above code can ensure the consistency of inventory data in the case of cluster deployment?

The answer is No. as shown in the figure above, after the request is distributed by Nginx, there may be multiple services that obtain inventory data from Redis at the same time. At this time, only adding synchronized (single lock) is invalid. The higher the concurrency, the greater the probability of problems.
Case 3 - implementing distributed locks using SETNX
setnx: set the value of the key to value if and only if the key does not exist.
If the given key already exists, setnx will not do anything.
Using setnx to implement simple distributed locks:
/**
* Simulate the scenario of reducing inventory under an order
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
// Adding distributed locks using setnx
// If true is returned, it means that no key in redis is the value of lockKey and has been set successfully
// Returning false indicates that the lock key already exists in redis
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "wangcp");
if(!result){
// It means it's locked
return "error_code";
}
// Get the current inventory value from redis
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("Deduction succeeded, remaining inventory:" + realStock);
}else{
System.out.println("Deduction failed, insufficient inventory");
}
// Release lock
stringRedisTemplate.delete(lockKey);
return "end";
}
We know that redis is executed in a single thread. Now when we look at the flowchart in case 2, even if multiple requests are executed to setnx code in a high concurrency scenario, redis will be arranged according to the order of requests. Only the requests arranged at the head of the queue can be set successfully. Other requests can only return "error_code".
Let's think again. Has the above code perfectly implemented the distributed lock? Can it support high concurrency scenarios? The answer is not that there are still many problems in the above code, which is far from a real distributed lock.
Let's analyze the problems in the above code:
Deadlock: if an exception occurs when executing the business code after the first request is locked by setnx, the code that releases the lock cannot be executed, and all subsequent requests cannot be operated.
To solve the deadlock problem, we optimize the code again, add try finally, and add the lock release code in finally, so that the lock release code will be executed anyway, as shown below:
/**
* Simulate the scenario of reducing inventory under an order
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
try{
// Adding distributed locks using setnx
// If true is returned, it means that no key in redis is the value of lockKey and has been set successfully
// Returning false indicates that the lock key already exists in redis
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "wangcp");
if(!result){
// It means it's locked
return "error_code";
}
// Get the current inventory value from redis
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("Deduction succeeded, remaining inventory:" + realStock);
}else{
System.out.println("Deduction failed, insufficient inventory");
}
}finally {
// Release lock
stringRedisTemplate.delete(lockKey);
}
return "end";
}
Are there any problems with the improved code? We think that there should be no problem under normal execution, but let's assume that the service suddenly goes down when the request is executed to the business code, or your o & M colleagues happen to reissue the version and the rough kill -9 falls off. Can the code be executed finally?
Case 4 - add expiration time
To solve the problems, optimize the code again and add the expiration time, so that even if the above problems occur, the lock will be released automatically after the time expires“ deadlock ”The situation.
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
try{
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey,"wangcp",10,TimeUnit.SECONDS);
if(!result){
// It means it's locked
return "error_code";
}
// Get the current inventory value from redis
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("Deduction succeeded, remaining inventory:" + realStock);
}else{
System.out.println("Deduction failed, insufficient inventory");
}
}finally {
// Release lock
stringRedisTemplate.delete(lockKey);
}
return "end";
}
Now let's think again. Can we add an expiration time to the lock? Can it run perfectly without problems?
Is the 10s timeout really appropriate? If not, how many seconds? As shown in the figure below
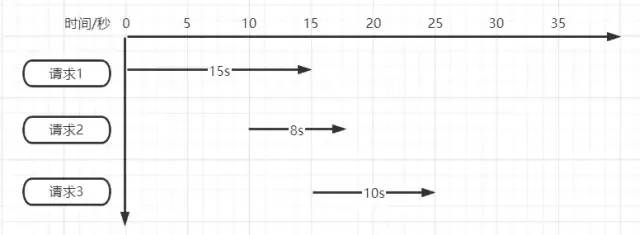
Suppose there are three requests at the same time.
- Request 1 needs to be executed for 15 seconds after locking first, but when it is executed for 10 seconds, the lock fails and is released.
- After request 2 enters, it is locked and executed. When request 2 is executed for 5 seconds, request 1 is completed to release the lock, but at this time, the lock of request 2 is released.
- Request 3 starts to execute when request 2 executes for 5 seconds, but when it executes for 3 seconds, request 2 completes to release the lock of request 3.
We can only simulate three requests to see the problem. If the real high concurrency scenario, the lock may face "permanent failure" or "permanent failure".
So what's the specific problem? It can be summarized as follows:
- 1. It is not your own lock that is released when you request to release the lock
- 2. The timeout is too short, and the code will be released automatically before it is executed
We think about the corresponding solutions to the problems:
- To solve problem 1, we think of generating a unique id when the request enters, using the unique id as the value value of the lock. When releasing, we first obtain the comparison, and then release it at the same time. In this way, we can solve the problem of releasing other request locks.
- In response to question 2, is it really appropriate for us to continuously extend the expiration time? If the setting is short, there will be a problem of timeout automatic release. If the setting is long, there will be a problem that the lock cannot be released for a period of time after downtime, although there will be no "deadlock" again. How to solve this problem?
Case 5 redisson distributed lock
Spring Boot integration Redisson steps
Introduce dependency
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>
Initialize client
@Bean
public RedissonClient redisson(){
// standalone mode
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.3.170:6379").setDatabase(0);
return Redisson.create(config);
}
Redisson implements distributed locks
@RestController
public class IndexController {
@Autowired
private RedissonClient redisson;
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* Simulate the scenario of reducing inventory under an order
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
// 1. Get lock object
RLock redissonLock = redisson.getLock(lockKey);
try{
// 2. Lock
redissonLock.lock(); // Equivalent to setIfAbsent(lockKey,"wangcp",10,TimeUnit.SECONDS);
// Get the current inventory value from redis
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("Deduction succeeded, remaining inventory:" + realStock);
}else{
System.out.println("Deduction failed, insufficient inventory");
}
}finally {
// 3. Release the lock
redissonLock.unlock();
}
return "end";
}
}
Schematic diagram of Redisson distributed lock implementation

Redisson underlying source code analysis
We click the lock() method to view the source code, and finally see the following code
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
Yes, the final execution of locking is the lua scripting language.
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
The main logic of the script is:
- Exists determines whether the key exists
- Set the key when it is judged that it does not exist
- Then add the expiration time to the set key
In this way, it seems to be no different from the implementation method in our previous case, but it is not.
When this lua script command is executed in Redis, it will be executed as a command to ensure atomicity, so it will either succeed or fail.
We can see from the source code that lua scripts are used in many of the implementation methods of redsession, which can greatly ensure the atomicity of command execution.
The following is the source code of Redisson lock automatic "life renewal":
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), task) != null) {
task.cancel();
}
}
This code starts a daemon thread to listen after locking. The reisson timeout is set to 30s by default. The thread calls every 10s to determine whether the lock still exists. If it exists, the timeout of the lock will be extended.
Now, let's look back at the locking code and schematic diagram in case 5. In fact, it can be used by many companies to this extent, and many companies do. But let's think about whether there are still problems? For example, the following scenarios:
- As we all know, Redis is deployed in clusters when it is actually deployed. In high concurrency scenarios, we lock it. When the key is written to the master node and the master is not synchronized to the slave node, the Master goes down. The original slave node is elected to a new master node, and the lock failure may occur.
- Through the implementation mechanism of distributed locks, we know that in high concurrency scenarios, only successful requests can continue to process business logic. Then everyone came to lock, but there was only one successful lock, and the rest were waiting. In fact, distributed locking is semantically contrary to high concurrency. Although our requests are concurrent, Redis helps us queue our requests for execution, that is, turn our parallel into serial. There must be no concurrency problem in the code executed serially, but the performance of the program will certainly be affected.
In view of these problems, we think about the solutions again
- When thinking about the solution, we first think of the CAP principle (consistency, availability and partition fault tolerance). Now Redis meets the AP (availability and partition fault tolerance). If we want to solve this problem, we need to find a distributed system that meets the CP (consistency and partition fault tolerance). The first thing I think of is zookeeper. Zookeeper's inter cluster data synchronization mechanism is that when the master node receives data, it will not immediately return the successful feedback to the client. It will synchronize the data with the child nodes first, and more than half of the nodes will notify the client of the successful reception after completing the synchronization. Moreover, if the primary node is down, the primary node re elected according to zookeeper's Zab protocol (zookeeper atomic broadcasting) must have been synchronized successfully. So the question is, how do we choose Redisson and Zookeeper distributed locks? The answer is that if the concurrency is not so high, Zookeeper can be used as a distributed lock, but its concurrency is far inferior to Redis. If you have high requirements for concurrency, use Redis. The occasional failure of master-slave architecture lock is actually tolerable.
- For the second problem of improving performance, we can refer to the idea of lock segmentation technology of ConcurrentHashMap. For example, the inventory of our code is currently 1000, so we can divide it into 10 segments, each segment is 100, and then lock each segment separately. In this way, we can lock and process 10 requests at the same time. Of course, students with requirements can continue to subdivide. But in fact, Redis's Qps has reached 10W +, which is fully sufficient in scenarios without particularly high concurrency.
Well, that's all for today's sharing. I look forward to your third consecutive: like + watching + forwarding.
Reference: www.jianshu.com/p/bc4ff4694cf3