
Author: successwang (Wang Cheng), R & D Engineer of Tencent CSIG, Kubernetes member.
1. General
Entering the world of K8s, you will find many interfaces that are convenient for expansion, including CNI, CSI, CRI, etc. these interfaces are abstracted to better provide opening, expansion, specification and other capabilities.
K8s network model adopts CNI(Container Network Interface) protocol. As long as a standard interface is provided, it can provide network functions for all container platforms that also meet the protocol.
CNI is a container network specification proposed by CoreOS. At present, it has been adopted by many open source projects such as Apache Mesos, cloud foundation, Kubernetes, Kurma and rkt. At the same time, it is also a CNCF(Cloud Native Computing Foundation) project. It can be predicted that CNI will become the standard of container network in the future.
This paper will analyze the CNI implementation mechanism from the core processes such as kubelet startup, Pod creation / deletion, Docker creation / deletion of Container, CNI RPC call, Container network configuration and so on.
The process overview is as follows:
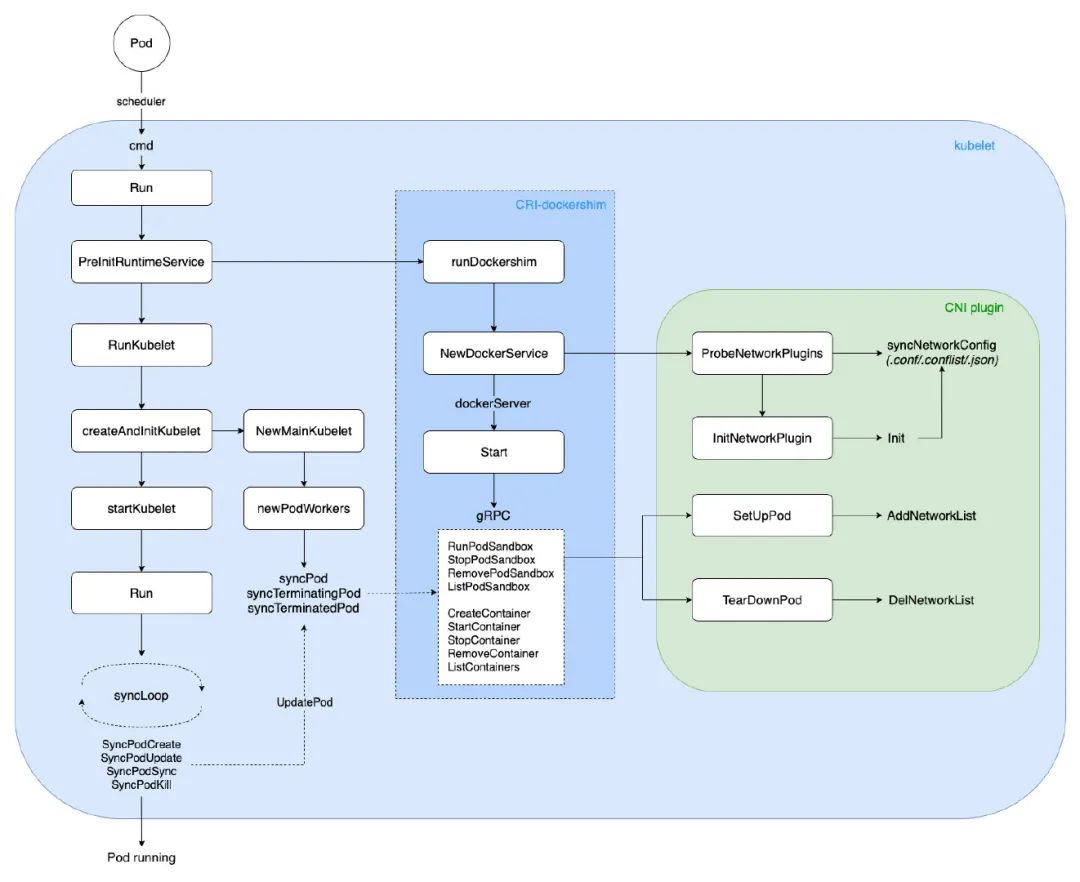
K8s-CNI
This article and subsequent related articles are based on K8s v1.22
2. Start with the network model
Container network technology changes with each passing day. After years of development, the industry has gradually focused on Docker's CNM(Container Network Model) and CoreOS's CNI(Container Network Interface).
2.1 CNM model
CNM is a specification proposed by Docker. It has been adopted by Cisco Contiv, Kuryr, Open Virtual Networking (OVN), Project Calico, VMware and Weave.
Libnetwork is the native implementation of CNM. It provides an interface between Docker daemon and network driver. The network controller is responsible for interfacing the driver with a network. Each driver is responsible for managing the network it owns and various services provided for the network, such as IPAM, etc. Multiple networks supported by multiple drivers can coexist at the same time. Native drivers include none, bridge, overlay and MACvlan.
However, the container runtime uses different plug-ins in different situations, which brings complexity. In addition, CNM needs to use a distributed storage system to store network configuration information, such as etcd.
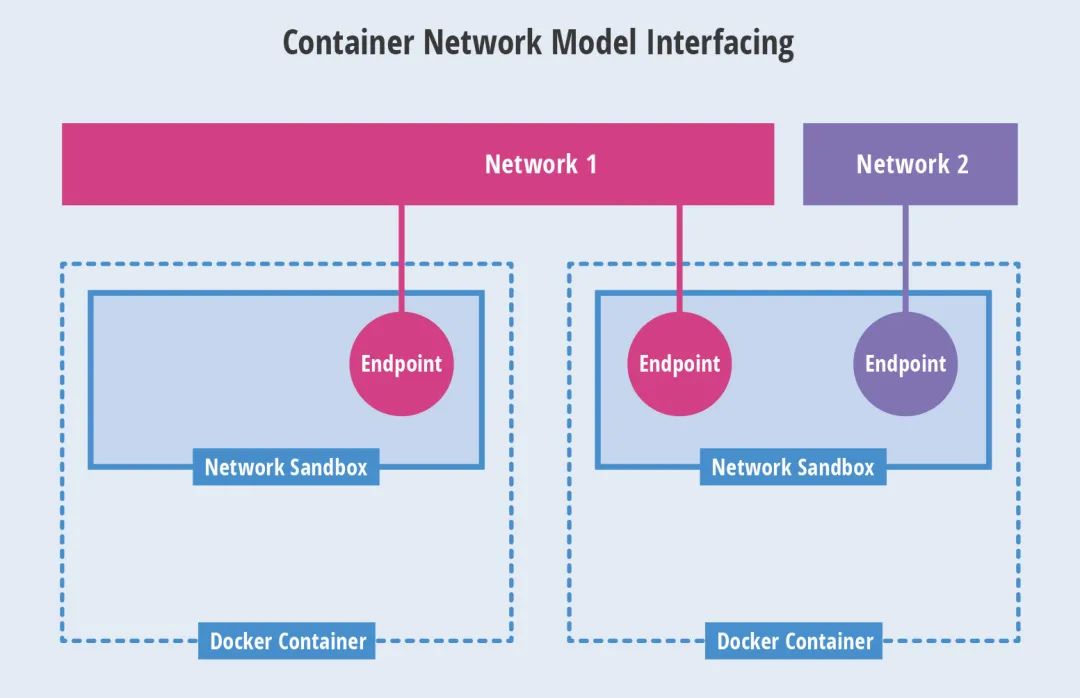
CNM-model
- Network Sandbox: the network stack inside the container, including the management of network interface, routing table, DNS and other configurations. Sandbox can be implemented by Linux Network namespace, FreeBSD, jail and other mechanisms. A sandbox can contain multiple endpoints.
- Endpoint: the Network interface used to connect the Sandbox in the container to the external Network. It can be implemented using veth pair, internal port of Open vSwitch and other technologies. An endpoint can only join one Network.
- Network: a collection of endpoints that can be directly interconnected. It can be implemented through Linux bridge, VLAN and other technologies. A network contains multiple endpoints.
2.2 CNI model
CNI is a container network specification proposed by CoreOS. The modified specifications have been adopted by Apache Mesos, Cloud Foundry, Kubernetes, Kurma and rkt. In addition, Contiv Networking, Project Calico and Weave also provide plug-ins for CNI.
CNI exposes the interface for adding and removing containers from a network. CNI uses a json configuration file to save network configuration information. Unlike CNM, CNI does not require an additional distributed storage engine.
A container can be added to multiple networks driven by different plug-ins. A network has its own plug-in and unique name. CNI plug-in needs to provide two commands: ADD is used to join the network interface to the specified network, and DEL is used to remove it. These two interfaces are called when the container is created and destroyed respectively.
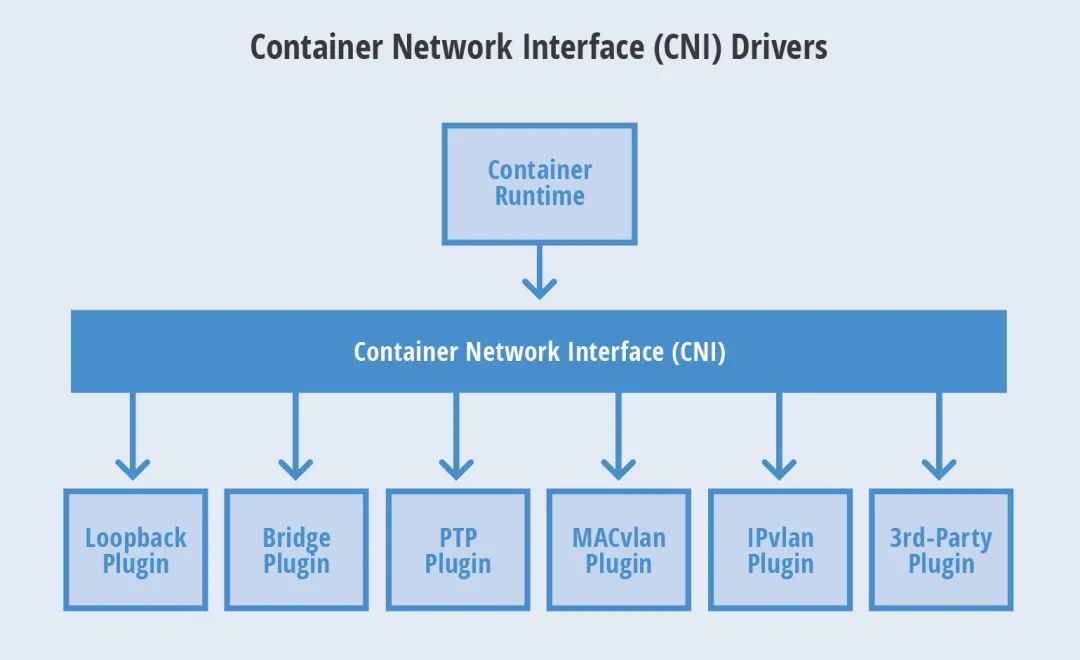
CNI-model
CNI supports integration with third-party IPAM and can be used for any container runtime. CNM is only designed to support Docker. Due to the simple design of CNI, many people think that writing CNI plug-ins will be easier than writing CNM plug-ins.
3. CNI plug-in
The CNI plug-in is a binary executable file that will be called by kubelet. Start kubelet -- Network plugin = CNI, -- CNI conf dir to specify the networkconfig configuration. The default path is: / etc/cni/net.d. In addition, -- CNI bin dir specifies the path to the plugin executable. The default path is: / opt/cni/bin.
Look at a CNI Demo: in the default network configuration directory, configure two xxx.conf: one type: "bridge" network bridge and the other type: "loopback" loopback network card.
$ mkdir -p /etc/cni/net.d
$ cat >/etc/cni/net.d/10-mynet.conf <<EOF
{
"cniVersion": "0.2.0", // CNI Spec edition
"name": "mynet", // Custom name
"type": "bridge", // Plug in type bridge
"bridge": "cni0", // Bridge name
"isGateway": true, // As gateway
"ipMasq": true, // Set IP camouflage
"ipam": {
"type": "host-local", // IPAM type host-local
"subnet": "10.22.0.0/16", // subnet
"routes": [
{ "dst": "0.0.0.0/0" } // Destination routing segment
]
}
}
EOF
$ cat >/etc/cni/net.d/99-loopback.conf <<EOF
{
"cniVersion": "0.2.0", // CNI Spec edition
"name": "lo", // Custom name
"type": "loopback" // Plug in type loopback
}
EOFCNI plug-ins can be divided into three categories:
- Main plug-in: used to create binary files of specific network devices. For example, bridge, ipvlan, loopback, macvlan, PTP (point-to-point, vet pair device), and vlan. For example, open source projects such as Flannel and Weave are CNI plug-ins of bridge type. In specific implementation, they often call the binary file bridge.
- Meta plug-in: a built-in CNI plug-in maintained by the CNI community. It cannot be used as an independent plug-in. Other plug-ins need to be called. tuning is a binary file that adjusts network device parameters through sysctl; portmap is a binary file that configures port mapping through iptables; bandwidth is a binary file that uses Token Bucket Filter (TBF) to limit current.
- IPAM plug-in: IP Address Management, which is a binary file responsible for assigning IP addresses. For example, DHCP, this file will send a request to the DHCP server; Host local, the pre configured IP address segment will be used for allocation.
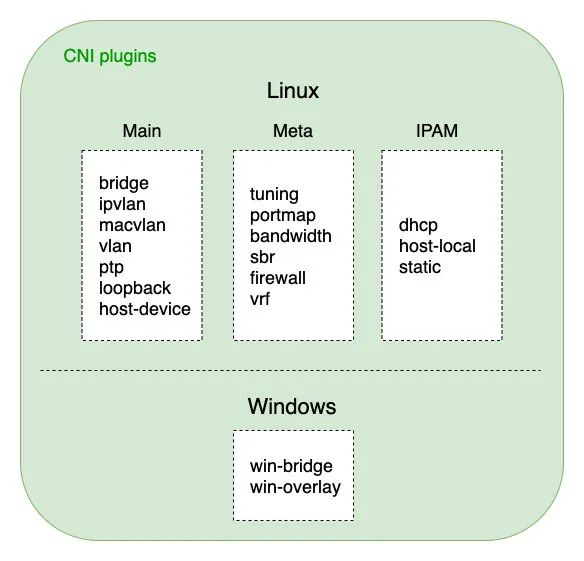
K8s-CNI-plugins
4. kubelet startup
kubelet is responsible for the core processes such as creation, destruction, monitoring and reporting of Pod on the Node node, and starts the binary executable file through Cobra command line parsing parameters.
The startup inlet is as follows:
// kubernetes/cmd/kubelet/kubelet.go
func main() {
command := app.NewKubeletCommand()
// kubelet uses a config file and does its own special
// parsing of flags and that config file. It initializes
// logging after it is done with that. Therefore it does
// not use cli.Run like other, simpler commands.
code := run(command)
os.Exit(code)
}Then, initialize all the way down:
cmd -> Run -> PreInitRuntimeService -> RunKubelet -> createAndInitKubelet -> startKubelet -> Run
The PreInitRuntimeService will further initialize dockershim. On the one hand, it will probe the network configuration file in the environment (the default path is: / etc / CNI / net. D / *. Conf /. Conf list /. JSON) to configure the CNI network; On the other hand, start gRPC docker server to listen to client requests and carry out specific operations, such as creation and deletion of PodSandbox and Container.
When a Pod event is heard, create or delete the corresponding Pod. The process is as follows:
Run -> syncLoop -> SyncPodCreate/Kill -> UpdatePod -> syncPod/syncTerminatingPod -> dockershim gRPC -> Pod running/teminated
5. Pod creation / deletion
The tuning of Pod in K8s is realized by channel producer consumer model. Specifically, Pod life cycle event management is carried out through PLEG (Pod life cycle event generator).
// kubernetes/pkg/kubelet/pleg/pleg.go
// adopt PLEG conduct Pod Lifecycle event management
type PodLifecycleEventGenerator interface {
Start() // adopt relist Get all Pods And calculate the event type
Watch() chan *PodLifecycleEvent // monitor eventChannel, passed to downstream consumers
Healthy() (bool, error)
}Pod event producer - related code:
// kubernetes/pkg/kubelet/pleg/generic.go
// Producer: get the list of all Pods, calculate the corresponding event type, and Sync
func (g *GenericPLEG) relist() {
klog.V(5).InfoS("GenericPLEG: Relisting")
...
// Get all current Pods list
podList, err := g.runtime.GetPods(true)
if err != nil {
klog.ErrorS(err, "GenericPLEG: Unable to retrieve pods")
return
}
for pid := range g.podRecords {
allContainers := getContainersFromPods(oldPod, pod)
for _, container := range allContainers {
// Calculation event type: running / existing / unknown / non-existing
events := computeEvents(oldPod, pod, &container.ID)
for _, e := range events {
updateEvents(eventsByPodID, e)
}
}
}
// Traverse all events
for pid, events := range eventsByPodID {
for i := range events {
// Filter out events that are not reliable and no other components use yet.
if events[i].Type == ContainerChanged {
continue
}
select {
case g.eventChannel <- events[i]: // Producer: send to the event channel, and the goroutine that corresponds to listening will consume
default:
metrics.PLEGDiscardEvents.Inc()
klog.ErrorS(nil, "Event channel is full, discard this relist() cycle event")
}
}
}
...
}Pod event consumer - related code:
// kubernetes/pkg/kubelet/kubelet.go
// Consumer: perform Pod Sync according to various events obtained by channel
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
...
// Consumer: monitoring plegCh events
case e := <-plegCh:
if e.Type == pleg.ContainerStarted {
// Last start time of update container
kl.lastContainerStartedTime.Add(e.ID, time.Now())
}
if isSyncPodWorthy(e) {
if pod, ok := kl.podManager.GetPodByUID(e.ID); ok {
klog.V(2).InfoS("SyncLoop (PLEG): event for pod", "pod", klog.KObj(pod), "event", e)
// Related Pod Event Sync
handler.HandlePodSyncs([]*v1.Pod{pod})
} else {
// If the pod no longer exists, ignore the event.
klog.V(4).InfoS("SyncLoop (PLEG): pod does not exist, ignore irrelevant event", "event", e)
}
}
// Container destruction event processing: clear the related containers in the Pod
if e.Type == pleg.ContainerDied {
if containerID, ok := e.Data.(string); ok {
kl.cleanUpContainersInPod(e.ID, containerID)
}
}
...
}
return true
}6. Docker gets busy
After the last step of production and consumption transfer of Pod events, PodWorkers transforms events into gRPC client requests, and then calls dockershim gRPC server to create PodSandbox and infra-container (also called pause containers).
Then, the CNI interface SetUpPod will be called for related network configuration and startup. At this time, the established container network can be directly used for the shared network of business containers created later, such as initContainers and containers.
Relevant codes are as follows:
// kubernetes/pkg/kubelet/dockershim/docker_sandbox.go
// Start operation Pod Sandbox
func (ds *dockerService) RunPodSandbox(ctx context.Context, r *runtimeapi.RunPodSandboxRequest) (*runtimeapi.RunPodSandboxResponse, error) {
config := r.GetConfig()
// Step 1: Pull the underlying image (infra container: k8s.gcr.io/pause:3.6)
image := defaultSandboxImage
if err := ensureSandboxImageExists(ds.client, image); err != nil {
return nil, err
}
// Step 2: establish Sandbox container
createConfig, err := ds.makeSandboxDockerConfig(config, image)
if err != nil {
return nil, fmt.Errorf("failed to make sandbox docker config for pod %q: %v", config.Metadata.Name, err)
}
createResp, err := ds.client.CreateContainer(*createConfig)
if err != nil {
createResp, err = recoverFromCreationConflictIfNeeded(ds.client, *createConfig, err)
}
// Step 3: establish Sandbox Checkpoint (used to record which step is currently executed)
if err = ds.checkpointManager.CreateCheckpoint(createResp.ID, constructPodSandboxCheckpoint(config)); err != nil {
return nil, err
}
// Step 4: start-up Sandbox container
err = ds.client.StartContainer(createResp.ID)
if err != nil {
return nil, fmt.Errorf("failed to start sandbox container for pod %q: %v", config.Metadata.Name, err)
}
// Step 5: yes Sandbox Container for network configuration
err = ds.network.SetUpPod(config.GetMetadata().Namespace, config.GetMetadata().Name, cID, config.Annotations, networkOptions)
if err != nil {
// Rollback if network configuration fails: delete the established Pod network
err = ds.network.TearDownPod(config.GetMetadata().Namespace, config.GetMetadata().Name, cID)
if err != nil {
errList = append(errList, fmt.Errorf("failed to clean up sandbox container %q network for pod %q: %v", createResp.ID, config.Metadata.Name, err))
}
// Stop container operation
err = ds.client.StopContainer(createResp.ID, defaultSandboxGracePeriod)
...
}
return resp, nil
}The flow chart is summarized as follows:
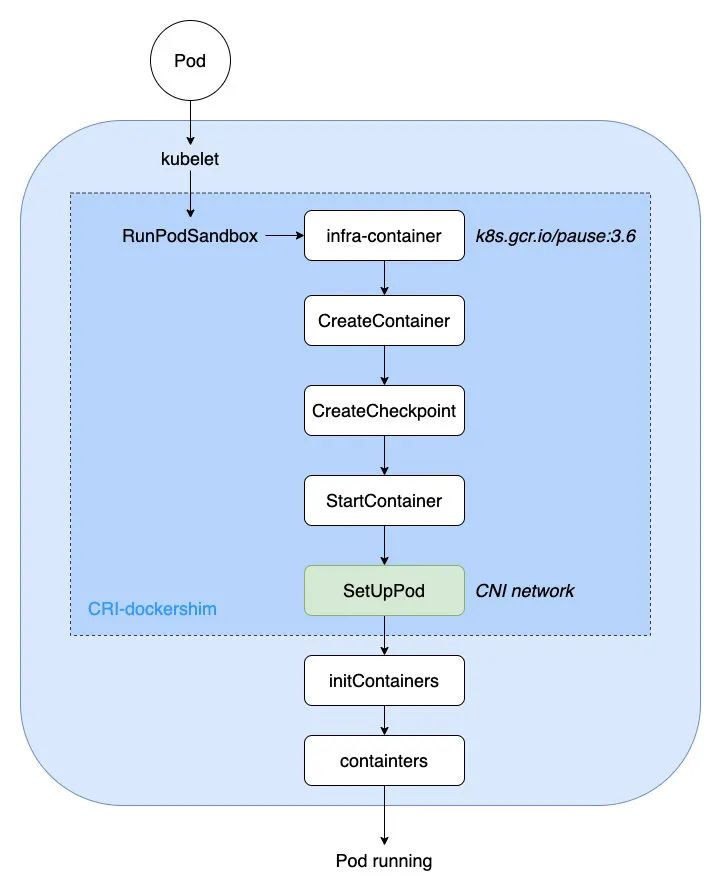
K8s-CNI-flow
According to community discussion Dockershim Deprecation FAQ , the dockership related code will be moved out of the K8s trunk code around the end of 2021, and then CRI(Container Runtime Interface) will be used for container life cycle management.
7. CNI RPC interface
CNI standard specification interface includes interfaces for adding, checking, verifying and deleting networks, and provides two groups of interfaces for network configuration by list or single, which is convenient for users to use flexibly.
CNI obtains the container runtime information from the container management system, including the path of the network namespace, the container ID and the network interface name, then loads the network configuration information from the container network configuration file, and then passes these information to the corresponding plug-in, which performs the specific network configuration, And return the configuration results to the container management system.

K8s-CNI-RPC
If users want to write their own CNI plug-ins, they can focus on implementing these RPC interfaces in the figure, and then they can freely combine with the three types of basic plug-ins officially maintained to form a variety of container network solutions.
8. Summary
By analyzing the core processes such as kubelet startup, Pod creation / deletion, Docker creation / deletion of Container, CNI RPC call and Container network configuration in K8s, this paper analyzes the CNI implementation mechanism, and explains the relevant process logic through source code and graphics, in order to better understand the K8s CNI operation process.
K8s network model adopts CNI(Container Network Interface) protocol. As long as a standard interface is provided, it can provide network functions for all container platforms that also meet the protocol. CNI has been adopted by many open source projects, and it is also a CNCF(Cloud Native Computing Foundation) project. It can be predicted that CNI will become the standard of container network in the future.
reference material
- CNI specification
- Kubernetes source code
- Introduction to CNI plug-in
- CNI plug-in source code
- CNI and CNM model
Recent hot posts:
Speed up 30%! Tencent TQUIC network transmission protocol
Daniel book list | a good book in the direction of message queue
Best practices of wechat ClickHouse real-time data warehouse
Live video of Tencent programmer
