This article has been launched in my public number, Hongyang Android.
For reprinting, please indicate the source:
http://blog.csdn.net/lmj623565791/article/details/60874334
This article is from Zhang Hongyang's Blog
In the last article, we introduced Android Hot Repair Tinker Access and Source Code Analysis It contains some background knowledge of hot repair. From the processing of dex files by tinker, the source code can be read in three parts.
- The merging and loading of patch es in applications has been described in detail in the previous article. Android Hot Repair Tinker Access and Source Code Analysis
- Detailed dex patch, dex diff algorithm
- Knowledge of tinker gradle plugin
tinker has a very big bright spot is the development of a set of dex diff, patch related algorithms. The main purpose of this paper is to analyze the algorithm. Of course, it is worth noting that the premise of analysis is to have a certain understanding of the format of dex files, otherwise it may be confused.
Therefore, this paper will first do a simple analysis of the dex file format, but also do some simple experiments, and finally enter the dex diff,patch algorithm part.
A Brief Analysis of Dex File Format
First of all, a brief understanding of dex file, when you decompile, it is clear that apk will contain one or more *. dex files, which store the code we write, in general, we will also convert to jar through tools, and then decompile through some tools to view.
jar files should be clear to all, similar to the class file compression package, in general, we can directly decompress to see a class file. The dex file can not be decompressed to obtain the internal class files, indicating that the dex file has its own specific format:
DEX rearranges JAVA class files, decomposes the constant pools in all JAVA class files, eliminates redundant information, and rearranges them to form a constant pool. All class files share the same constant pool, making the same string and constant appear only once in DEX file, thus reducing the volume of the file. From: http://blog.csdn.net/jason0539/article/details/50440669
Next, let's look at the internal structure of the dex file.
To analyze the composition of a file, it is better to write a simple dex file to analyze.
(1) Write code to generate dex
First we write a class Hello.java:
public class Hello{
public static void main(String[] args){
System.out.println("hello dex!");
}
}Then compile:
javac -source 1.7 -target 1.7 Hello.javaFinally, it is converted into dex file through dx work:
dx --dex --output=Hello.dex Hello.classDX path in android-sdk/build-tools / version number / dx, if you can not identify the DX command, remember to put the path under path, or use absolute path.
So we get a very simple dex file.
(2) View the internal structure of dex files
Firstly, the general internal structure of an dex file is shown.
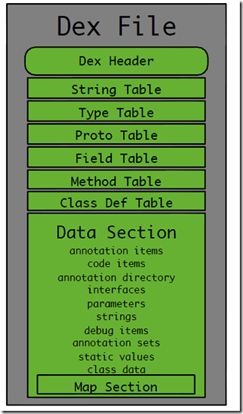
The graph is derived from dodola's tinker article->Alone Monkey's blog
Of course, it is not enough to explain it simply from a graph, because we need to study the diff and patch algorithm in the future. In theory, we should know more details, and even be careful about what each byte of an dex file represents.
For a binary-like file, the best way is certainly not to rely on memory. Fortunately, there is a software that can help us analyze:
- Software name: 010 Editor
- Download address: http://www.sweetscape.com/010editor/
After downloading and installing, open our dex file, which will guide you to install the parsing template of dex file.
The final result is as follows:
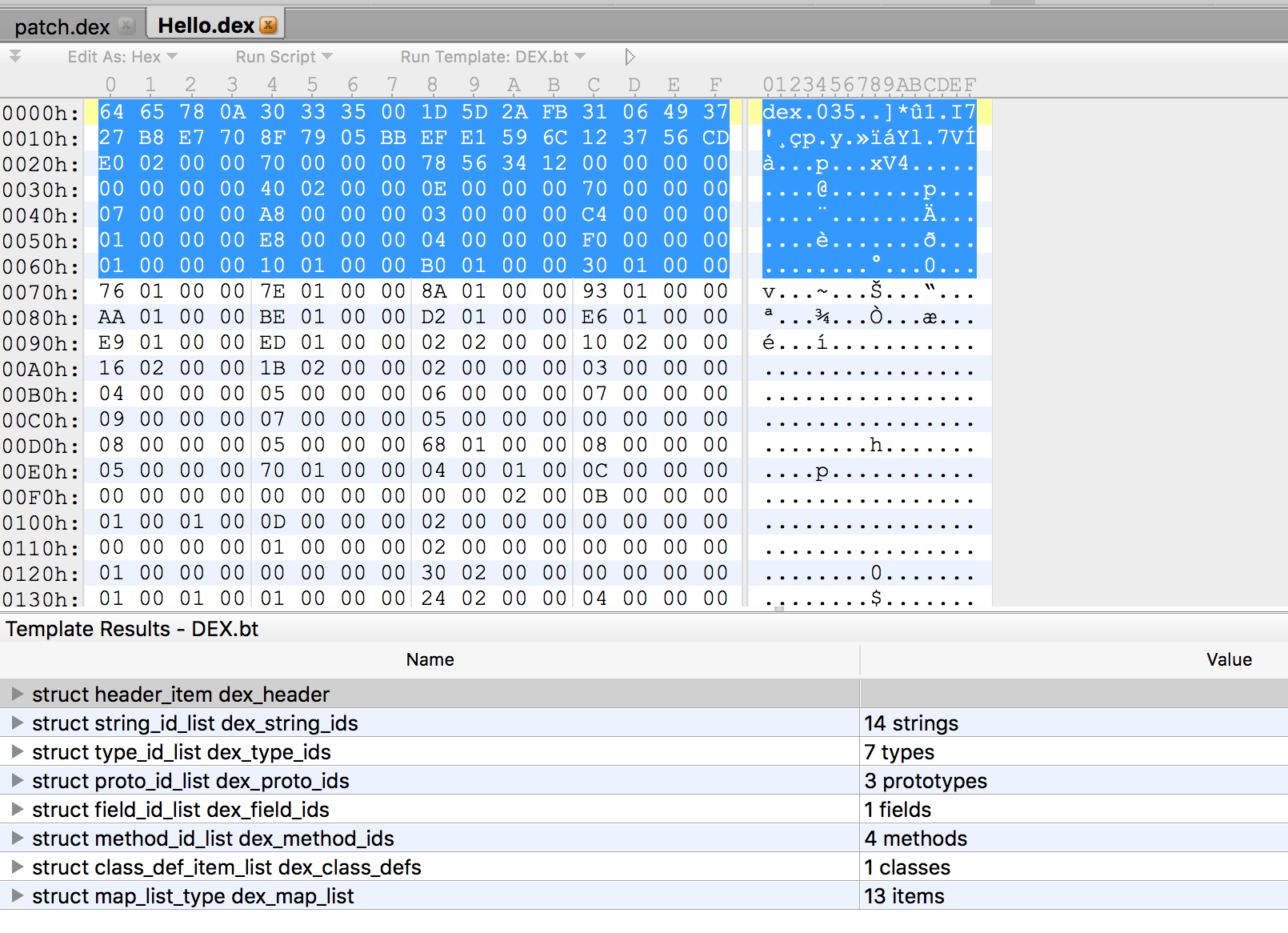
The above section represents the content of the dex file (displayed in hexadecimal mode). The following section shows the various areas of the dex file. You can click on the following section to see the corresponding content area and content.
Of course, it is also highly recommended to read some special articles to deepen the understanding of dex files:
This article will only do a simple format analysis of dex files.
(3) Simple Analysis of the Internal Structure of dex Files
dex_header
First, our team dex_header does a general analysis. The header contains the following fields:
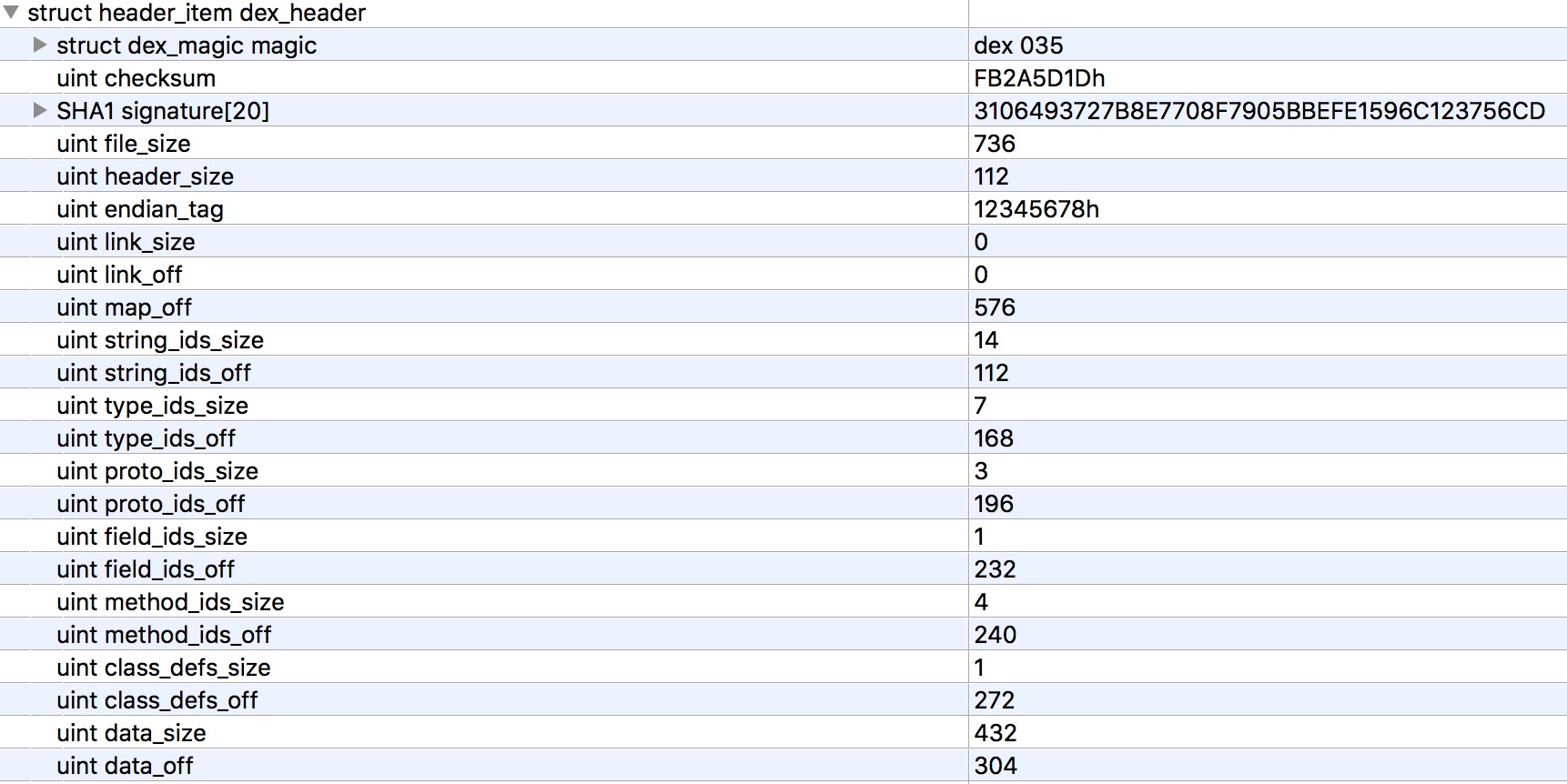
Firstly, we guess the function of header. We can see that it contains some validation related fields, and the distribution of blocks in the whole dex file (off is offset).
The advantage is that when the virtual machine reads the dex file, it only needs to read the header part to know the general block distribution of the dex file, and can check whether the file format is correct, whether the file has been tampered with, etc.
- magic can prove that the file is dex
- checksum and signature are mainly used to verify the integrity of files
- file_size is the size of dex file
- head_size is the size of the header file
- The default value of endian_tag is 12345678, and the default identifier is Little-Endian (self-search).
Almost all the remaining sizes and off occur in pairs, mostly representing the number and offset of specific data structures contained in each block. For example, string_ids_off is 112, which means that the offset 112 starts in the string_ids region, and string_ids_size is 14, which means the number of string_id_item s is 14. The rest are similar and not introduced.
Combining with 010 Editor, you can see the data structure and corresponding values in each area. Just take your time.
dex_map_list
In addition to header, another important part is dex_map_list. First, look at a graph:
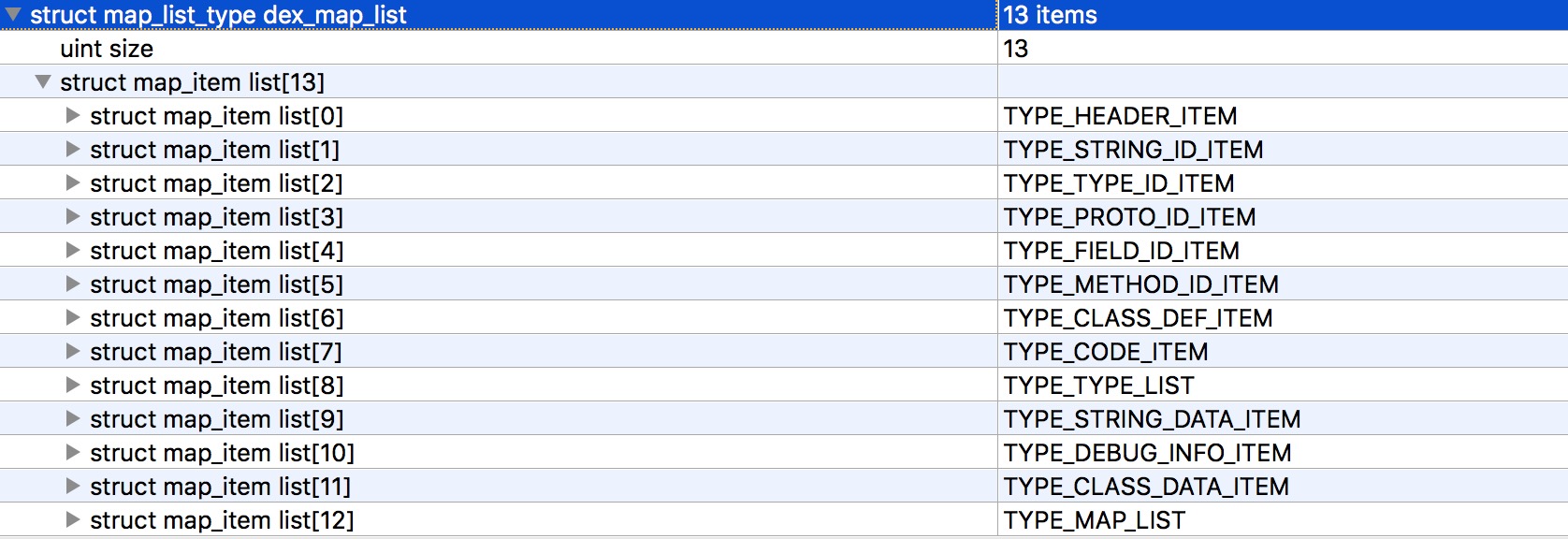
First, the number of map_item_lists, followed by the description of each map_item_list.
What's the use of map_item_list?
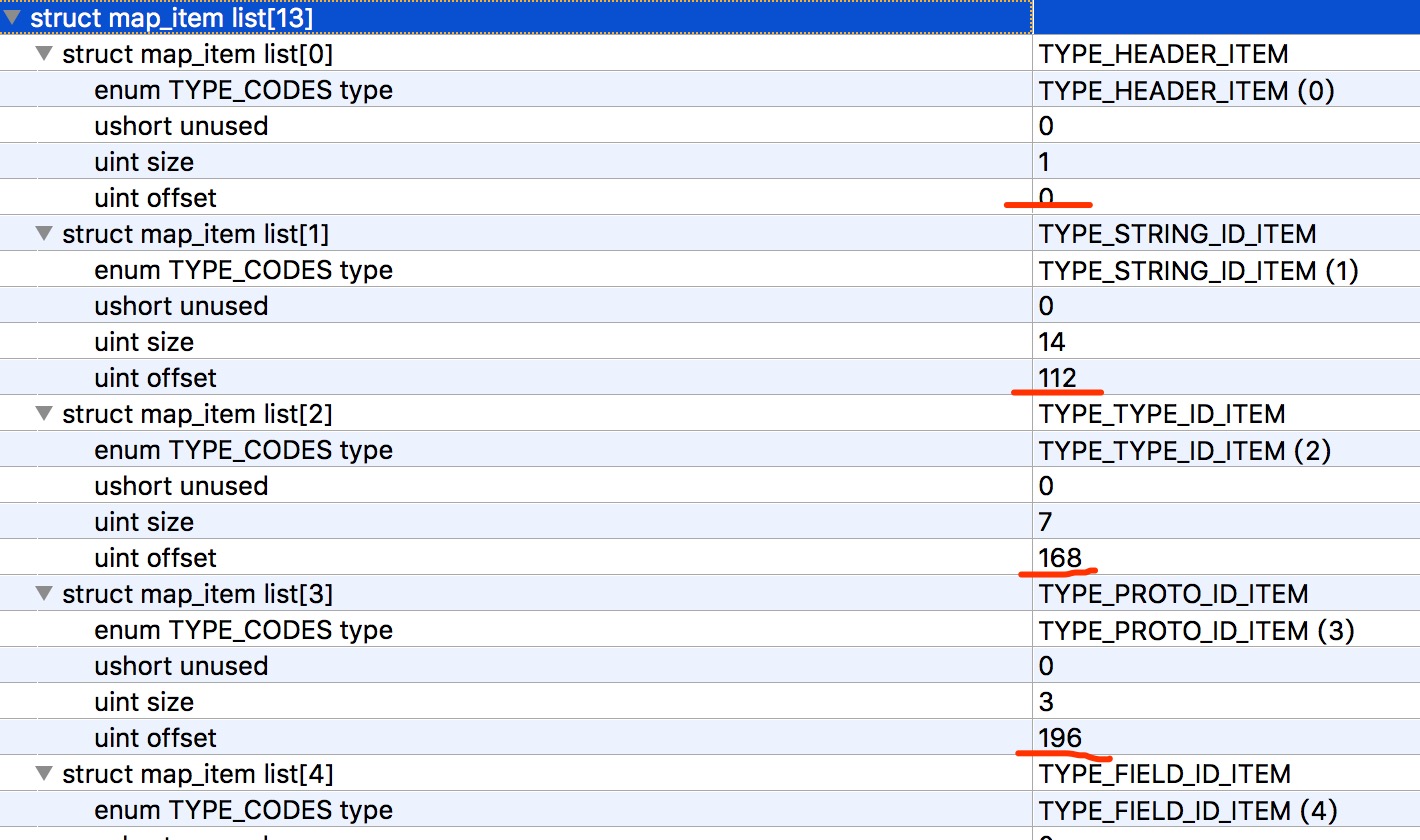
You can see that each map_list_item contains an enumeration type, a 2-byte unused member, a size indicating the number of current types, and offset indicating the current type offset.
For example:
- The first is the TYPE_HEADER_ITEM type, which contains a header(size=1) with an offset of 0.
- Next comes TYPE_STRING_ID_ITEM, which contains 14 string_id_items (size=14) with an offset of 112 (header length is 112, followed by header if impressed).
The rest is analogous in turn~~
In this way, you can see that through map_list, a complete dex file can be divided into fixed areas (in this case, 13), and know the beginning of each area, as well as the number of data formats corresponding to that area.
Find the beginning of each region through map_list, and each region will correspond to a specific data structure, just look through 010 Editor.
2. Thoughts before Analysis
Now that we understand the basic format of dex, let's consider how to do dex diff and patch.
The first thing to consider is what we have:
- old dex
- new dex
We want to generate a patch file, which and old dex can also generate new dex through the patch algorithm.
- So what should we do?
Based on the analysis above, we know that there are roughly three parts of dex file (three parts here are mainly used for analysis, not truthful):
- header
- Various regions
- map list
In fact, the header can determine its content according to the following data, and the length is 112; after each region, the map list can actually locate the beginning of each region;
We finally patch + old DEX - > New dex; for the three parts mentioned above,
- header can not be processed because it can be generated from other data.
- Maplist, in fact, what we want is the beginning of each region.
- After knowing the offset of each region, when we generate new dex, we can locate the start and end positions of each region, so we only need to write data to each region.
So let's look at the diff for a region, assuming that there is a string region, which is mainly used to store strings:
The old dex strings in this region are: Hello, World, zhy
new dex The strings in this region are: Android, World, zhy
As you can see, for this region, we deleted Hello and added Android and zhy.
Then the following records can be recorded in the patch for this region:
"Del Hello, add Android, zhy" (the actual situation needs to be converted into binary).
Think of an application that reads out old dex directly, that is, you know:
- Originally, the region included: Hello, World, zhy
- The area in the patch contains: "del Hello, add Android, zhy"
Then, it is very easy to calculate the inclusion of new dex:
Android,World,zhy.
In this way, we have completed a region roughly diff and patch algorithm, and other regions diff and patch are similar to the above.
In this way, do you think the diff and patch algorithms are not so complex, in fact, tinker's approach is similar to the above, the actual situation may be more complex than the above description, but generally similar?
With a rough idea of the algorithm, we can look at the source code.
3. Analysis of Tinker DexDiff Source Code
tinker's address:
It's also tricky to look at the code here. There's a lot of tinker code, and you can get stuck in a bunch of code. We can consider this, for example, diff algorithm, input parameters are old dex, new dex, output is patch file.
Then there must be a class, or a method that accepts and outputs the above parameters. In fact, this class is DexPatchGenerator:
The API code for diff is:
@Test
public void testDiff() throws IOException {
File oldFile = new File("Hello.dex");
File newFile = new File("Hello-World.dex");
File patchFile = new File("patch.dex");
DexPatchGenerator dexPatchGenerator
= new DexPatchGenerator(oldFile, newFile);
dexPatchGenerator.executeAndSaveTo(patchFile);
}The code is under tinker-patch-lib of tinker-build.
Write a unit test or main method, and these lines of code are diff algorithms.
So look at the code with pertinence, such as diff algorithm, find the entrance of diff algorithm, don't tangle in gradle plugin.
(1)dex file => Dex
public DexPatchGenerator(File oldDexFile, File newDexFile) throws IOException {
this(new Dex(oldDexFile), new Dex(newDexFile));
}The DEX file we passed in is converted into a Dex object.
public Dex(File file) throws IOException {
// Deleted a bunch of code
InputStream in = new BufferedInputStream(new FileInputStream(file));
loadFrom(in, (int) file.length());
}
private void loadFrom(InputStream in, int initSize) throws IOException {
byte[] rawData = FileUtils.readStream(in, initSize);
this.data = ByteBuffer.wrap(rawData);
this.data.order(ByteOrder.LITTLE_ENDIAN);
this.tableOfContents.readFrom(this);
}First we read our files as byte [] arrays (which are still memory-intensive here), then we wrap them by ByteBuffer, and set the byte order to the small end (which shows that ByteBuffer is quite convenient here). Then the tableOfContents of the Dex object are assigned by the readFrom method.
#TableOfContents
public void readFrom(Dex dex) throws IOException {
readHeader(dex.openSection(header));
// special case, since mapList.byteCount is available only after
// computeSizesFromOffsets() was invoked, so here we can't use
// dex.openSection(mapList) to get dex section. Or
// an {@code java.nio.BufferUnderflowException} will be thrown.
readMap(dex.openSection(mapList.off));
computeSizesFromOffsets();
}
readHeader and readMap are executed internally. Above, we analyzed the correlation between header and map list. In fact, we translated these two areas into a certain data structure, read them and store them in memory.
First look at readHeader:
private void readHeader(Dex.Section headerIn) throws UnsupportedEncodingException {
byte[] magic = headerIn.readByteArray(8);
int apiTarget = DexFormat.magicToApi(magic);
if (apiTarget != DexFormat.API_NO_EXTENDED_OPCODES) {
throw new DexException("Unexpected magic: " + Arrays.toString(magic));
}
checksum = headerIn.readInt();
signature = headerIn.readByteArray(20);
fileSize = headerIn.readInt();
int headerSize = headerIn.readInt();
if (headerSize != SizeOf.HEADER_ITEM) {
throw new DexException("Unexpected header: 0x" + Integer.toHexString(headerSize));
}
int endianTag = headerIn.readInt();
if (endianTag != DexFormat.ENDIAN_TAG) {
throw new DexException("Unexpected endian tag: 0x" + Integer.toHexString(endianTag));
}
linkSize = headerIn.readInt();
linkOff = headerIn.readInt();
mapList.off = headerIn.readInt();
if (mapList.off == 0) {
throw new DexException("Cannot merge dex files that do not contain a map");
}
stringIds.size = headerIn.readInt();
stringIds.off = headerIn.readInt();
typeIds.size = headerIn.readInt();
typeIds.off = headerIn.readInt();
protoIds.size = headerIn.readInt();
protoIds.off = headerIn.readInt();
fieldIds.size = headerIn.readInt();
fieldIds.off = headerIn.readInt();
methodIds.size = headerIn.readInt();
methodIds.off = headerIn.readInt();
classDefs.size = headerIn.readInt();
classDefs.off = headerIn.readInt();
dataSize = headerIn.readInt();
dataOff = headerIn.readInt();
}If you open 010 Editor now, or look at the front figure, you actually define all the fields in the header, read the response bytes and assign values.
Next, look at readMap:
private void readMap(Dex.Section in) throws IOException {
int mapSize = in.readInt();
Section previous = null;
for (int i = 0; i < mapSize; i++) {
short type = in.readShort();
in.readShort(); // unused
Section section = getSection(type);
int size = in.readInt();
int offset = in.readInt();
section.size = size;
section.off = offset;
previous = section;
}
header.off = 0;
Arrays.sort(sections);
// Skip header section, since its offset must be zero.
for (int i = 1; i < sections.length; ++i) {
if (sections[i].off == Section.UNDEF_OFFSET) {
sections[i].off = sections[i - 1].off;
}
}
}Note here that when you read the header, you actually read offset in the area other than map list and store it in mapList.off. So the map list actually starts at this location. First read the number of map_list_items, and then read the actual data corresponding to each map_list_item.
As you can see, read in turn: type,unused,size,offset. If you still have an impression, we described map_list_item as corresponding to this, and the corresponding data structure is TableContents.Section object.
computeSizesFromOffsets() assigns the byteCount (occupying multiple bytes) parameter of the section.
This completes the initialization of dex file to Dex object.
Once you have two Dex objects, you need to do the diff operation.
(2)dex diff
Go back to the source code:
public DexPatchGenerator(File oldDexFile, InputStream newDexStream) throws IOException {
this(new Dex(oldDexFile), new Dex(newDexStream));
}Constructor directly to two Dex objects:
public DexPatchGenerator(Dex oldDex, Dex newDex) {
this.oldDex = oldDex;
this.newDex = newDex;
SparseIndexMap oldToNewIndexMap = new SparseIndexMap();
SparseIndexMap oldToPatchedIndexMap = new SparseIndexMap();
SparseIndexMap newToPatchedIndexMap = new SparseIndexMap();
SparseIndexMap selfIndexMapForSkip = new SparseIndexMap();
additionalRemovingClassPatternSet = new HashSet<>();
this.stringDataSectionDiffAlg = new StringDataSectionDiffAlgorithm(
oldDex, newDex,
oldToNewIndexMap,
oldToPatchedIndexMap,
newToPatchedIndexMap,
selfIndexMapForSkip
);
this.typeIdSectionDiffAlg = ...
this.protoIdSectionDiffAlg = ...
this.fieldIdSectionDiffAlg = ...
this.methodIdSectionDiffAlg = ...
this.classDefSectionDiffAlg = ...
this.typeListSectionDiffAlg = ...
this.annotationSetRefListSectionDiffAlg = ...
this.annotationSetSectionDiffAlg = ...
this.classDataSectionDiffAlg = ...
this.codeSectionDiffAlg = ...
this.debugInfoSectionDiffAlg = ...
this.annotationSectionDiffAlg = ...
this.encodedArraySectionDiffAlg = ...
this.annotationsDirectorySectionDiffAlg = ...
}See that it first assigns oldDex,newDex, and then initializes 15 algorithms in turn. Each algorithm represents each region. The purpose of the algorithm is to know what has been deleted and what has been added, as we described earlier.
Let's continue with the code:
dexPatchGenerator.executeAndSaveTo(patchFile);With the dexPatchGenerator object, it points directly to the executeAndSaveTo method.
public void executeAndSaveTo(File file) throws IOException {
OutputStream os = null;
try {
os = new BufferedOutputStream(new FileOutputStream(file));
executeAndSaveTo(os);
} finally {
if (os != null) {
try {
os.close();
} catch (Exception e) {
// ignored.
}
}
}
}To the executeAndSaveTo method:
public void executeAndSaveTo(OutputStream out) throws IOException {
int patchedheaderSize = SizeOf.HEADER_ITEM;
int patchedStringIdsSize = newDex.getTableOfContents().stringIds.size * SizeOf.STRING_ID_ITEM;
int patchedTypeIdsSize = newDex.getTableOfContents().typeIds.size * SizeOf.TYPE_ID_ITEM;
int patchedProtoIdsSize = newDex.getTableOfContents().protoIds.size * SizeOf.PROTO_ID_ITEM;
int patchedFieldIdsSize = newDex.getTableOfContents().fieldIds.size * SizeOf.MEMBER_ID_ITEM;
int patchedMethodIdsSize = newDex.getTableOfContents().methodIds.size * SizeOf.MEMBER_ID_ITEM;
int patchedClassDefsSize = newDex.getTableOfContents().classDefs.size * SizeOf.CLASS_DEF_ITEM;
int patchedIdSectionSize =
patchedStringIdsSize
+ patchedTypeIdsSize
+ patchedProtoIdsSize
+ patchedFieldIdsSize
+ patchedMethodIdsSize
+ patchedClassDefsSize;
this.patchedHeaderOffset = 0;
this.patchedStringIdsOffset = patchedHeaderOffset + patchedheaderSize;
this.stringDataSectionDiffAlg.execute();
this.patchedStringDataItemsOffset = patchedheaderSize + patchedIdSectionSize;
this.stringDataSectionDiffAlg.simulatePatchOperation(this.patchedStringDataItemsOffset);
// A bunch of code for the remaining 14 algorithms has been omitted
this.patchedDexSize
= this.patchedMapListOffset
+ patchedMapListSize;
writeResultToStream(out);
}Because there are 15 algorithms involved, the code here is very long. Let's just take one of them for illustration.
Each algorithm executes the execute and simulatePatchOperation methods:
First look at execute:
public void execute() {
this.patchOperationList.clear();
// 1. Get the itemList of oldDex and newDex
this.adjustedOldIndexedItemsWithOrigOrder = collectSectionItems(this.oldDex, true);
this.oldItemCount = this.adjustedOldIndexedItemsWithOrigOrder.length;
AbstractMap.SimpleEntry<Integer, T>[] adjustedOldIndexedItems = new AbstractMap.SimpleEntry[this.oldItemCount];
System.arraycopy(this.adjustedOldIndexedItemsWithOrigOrder, 0, adjustedOldIndexedItems, 0, this.oldItemCount);
Arrays.sort(adjustedOldIndexedItems, this.comparatorForItemDiff);
AbstractMap.SimpleEntry<Integer, T>[] adjustedNewIndexedItems = collectSectionItems(this.newDex, false);
this.newItemCount = adjustedNewIndexedItems.length;
Arrays.sort(adjustedNewIndexedItems, this.comparatorForItemDiff);
int oldCursor = 0;
int newCursor = 0;
// 2. Traversing, comparing, and collecting patch operations
while (oldCursor < this.oldItemCount || newCursor < this.newItemCount) {
if (oldCursor >= this.oldItemCount) {
// rest item are all newItem.
while (newCursor < this.newItemCount) {
// ADD the rest of the newItem
}
} else if (newCursor >= newItemCount) {
// rest item are all oldItem.
while (oldCursor < oldItemCount) {
// DEL the remaining oldItem
}
} else {
AbstractMap.SimpleEntry<Integer, T> oldIndexedItem = adjustedOldIndexedItems[oldCursor];
AbstractMap.SimpleEntry<Integer, T> newIndexedItem = adjustedNewIndexedItems[newCursor];
int cmpRes = oldIndexedItem.getValue().compareTo(newIndexedItem.getValue());
if (cmpRes < 0) {
int deletedIndex = oldIndexedItem.getKey();
int deletedOffset = getItemOffsetOrIndex(deletedIndex, oldIndexedItem.getValue());
this.patchOperationList.add(new PatchOperation<T>(PatchOperation.OP_DEL, deletedIndex));
markDeletedIndexOrOffset(this.oldToPatchedIndexMap, deletedIndex, deletedOffset);
++oldCursor;
} else if (cmpRes > 0) {
this.patchOperationList.add(new PatchOperation<>(PatchOperation.OP_ADD,
newIndexedItem.getKey(), newIndexedItem.getValue()));
++newCursor;
} else {
int oldIndex = oldIndexedItem.getKey();
int newIndex = newIndexedItem.getKey();
int oldOffset = getItemOffsetOrIndex(oldIndexedItem.getKey(), oldIndexedItem.getValue());
int newOffset = getItemOffsetOrIndex(newIndexedItem.getKey(), newIndexedItem.getValue());
if (oldIndex != newIndex) {
this.oldIndexToNewIndexMap.put(oldIndex, newIndex);
}
if (oldOffset != newOffset) {
this.oldOffsetToNewOffsetMap.put(oldOffset, newOffset);
}
++oldCursor;
++newCursor;
}
}
}
// Unfinished
}You can see that you first read the data of the corresponding regions of oldDex and newDex and sort them, adjustedOld Indexed Items and adjusted New Indexed Items, respectively.
Next, I'm going to go through it. Look directly at the else section.
According to the current cursor, the old Item and the new Item are obtained, and their value s are compared.
- If < 0, the old Item is considered deleted and recorded as PatchOperation.OP_DEL, and the old Item index is recorded into the PatchOperation object and added to the patchOperationList.
- If > 0, the new Item is considered to be new, recorded as PatchOperation.OP_ADD, and recorded as the new Item index and value to the PatchOperation object and added to the PatchOperation List.
- If = 0, the PatchOperation is not generated.
After that, we get a patchOperationList object.
Continue with the second half of the code:
public void execute() {
// Connect...
// Sort by index, if index is the same, then DEL firstADD
Collections.sort(this.patchOperationList, comparatorForPatchOperationOpt);
Iterator<PatchOperation<T>> patchOperationIt = this.patchOperationList.iterator();
PatchOperation<T> prevPatchOperation = null;
while (patchOperationIt.hasNext()) {
PatchOperation<T> patchOperation = patchOperationIt.next();
if (prevPatchOperation != null
&& prevPatchOperation.op == PatchOperation.OP_DEL
&& patchOperation.op == PatchOperation.OP_ADD
) {
if (prevPatchOperation.index == patchOperation.index) {
prevPatchOperation.op = PatchOperation.OP_REPLACE;
prevPatchOperation.newItem = patchOperation.newItem;
patchOperationIt.remove();
prevPatchOperation = null;
} else {
prevPatchOperation = patchOperation;
}
} else {
prevPatchOperation = patchOperation;
}
}
// Finally we record some information for the final calculations.
patchOperationIt = this.patchOperationList.iterator();
while (patchOperationIt.hasNext()) {
PatchOperation<T> patchOperation = patchOperationIt.next();
switch (patchOperation.op) {
case PatchOperation.OP_DEL: {
indexToDelOperationMap.put(patchOperation.index, patchOperation);
break;
}
case PatchOperation.OP_ADD: {
indexToAddOperationMap.put(patchOperation.index, patchOperation);
break;
}
case PatchOperation.OP_REPLACE: {
indexToReplaceOperationMap.put(patchOperation.index, patchOperation);
break;
}
}
}
}- First, the patchOperationList is sorted by index. If index is consistent, DEL is first followed by ADD.
- The next iteration for all operations mainly transforms index consistent and continuous DEL and ADD into REPLACE operations.
- Finally, the patchOperationList is transformed into three Maps: indexToDelOperationMap, indexToAddOperationMap and indexToReplace OperationMap.
ok, after execute, our main product is three Map s, which record which index es need to be deleted in oldDex, which items need to be added in newDex, and which items need to be replaced by new items.
I just said that each algorithm has a simulatePatchOperation() besides execute().
this.stringDataSectionDiffAlg
.simulatePatchOperation(this.patchedStringDataItemsOffset);
The input offset is the offset of the data region.
public void simulatePatchOperation(int baseOffset) {
int oldIndex = 0;
int patchedIndex = 0;
int patchedOffset = baseOffset;
while (oldIndex < this.oldItemCount || patchedIndex < this.newItemCount) {
if (this.indexToAddOperationMap.containsKey(patchedIndex)) {
//Some code has been omitted
T newItem = patchOperation.newItem;
int itemSize = getItemSize(newItem);
++patchedIndex;
patchedOffset += itemSize;
} else if (this.indexToReplaceOperationMap.containsKey(patchedIndex)) {
//Some code has been omitted
T newItem = patchOperation.newItem;
int itemSize = getItemSize(newItem);
++patchedIndex;
patchedOffset += itemSize;
} else if (this.indexToDelOperationMap.containsKey(oldIndex)) {
++oldIndex;
} else if (this.indexToReplaceOperationMap.containsKey(oldIndex)) {
++oldIndex;
} else if (oldIndex < this.oldItemCount) {
++oldIndex;
++patchedIndex;
patchedOffset += itemSize;
}
}
this.patchedSectionSize = SizeOf.roundToTimesOfFour(patchedOffset - baseOffset);
}Traverse the old Index and the new Index, respectively, in the index ToAddOperationMap, index ToReplace OperationMap, and index ToDel OperationMap.
One final product of concern here is this.patchedSectionSize, derived from patchedOffset-baseOffset.
There are several scenarios that cause patchedOffset+=itemSize:
- The indexToAddOperationMap contains patchIndex
- IndexToReplace OperationMap contains patchIndex
- Old Dex is not in indexToDel OperationMap and indexToReplace OperationMap.
It's easy to understand that this patched Section Size actually corresponds to the size of this area of newDex. Therefore, Items containing ADD will be replaced, and Items not deleted or replaced in OLD ITEMS. The addition of these three is the itemList of newDex.
At this point, an algorithm is executed.
After such an algorithm, we get the PatchOperationList and the corresponding section Size. When all the algorithms are executed, the PatchOperationList for each algorithm and the sectionSize for each region should be obtained; the sectionSize for each region is actually converted to the offset for each region.
The algorithm of each region, execute and simulatePatchOperation code are reusable, so the others are only slightly changed, you can see for yourself.
Next, look at the writeResultToStream method after executing all the algorithms.
(3) Generating patch files
private void writeResultToStream(OutputStream os) throws IOException {
DexDataBuffer buffer = new DexDataBuffer();
buffer.write(DexPatchFile.MAGIC); // DEXDIFF
buffer.writeShort(DexPatchFile.CURRENT_VERSION); /0x0002
buffer.writeInt(this.patchedDexSize);
// we will return here to write firstChunkOffset later.
int posOfFirstChunkOffsetField = buffer.position();
buffer.writeInt(0);
buffer.writeInt(this.patchedStringIdsOffset);
buffer.writeInt(this.patchedTypeIdsOffset);
buffer.writeInt(this.patchedProtoIdsOffset);
buffer.writeInt(this.patchedFieldIdsOffset);
buffer.writeInt(this.patchedMethodIdsOffset);
buffer.writeInt(this.patchedClassDefsOffset);
buffer.writeInt(this.patchedMapListOffset);
buffer.writeInt(this.patchedTypeListsOffset);
buffer.writeInt(this.patchedAnnotationSetRefListItemsOffset);
buffer.writeInt(this.patchedAnnotationSetItemsOffset);
buffer.writeInt(this.patchedClassDataItemsOffset);
buffer.writeInt(this.patchedCodeItemsOffset);
buffer.writeInt(this.patchedStringDataItemsOffset);
buffer.writeInt(this.patchedDebugInfoItemsOffset);
buffer.writeInt(this.patchedAnnotationItemsOffset);
buffer.writeInt(this.patchedEncodedArrayItemsOffset);
buffer.writeInt(this.patchedAnnotationsDirectoryItemsOffset);
buffer.write(this.oldDex.computeSignature(false));
int firstChunkOffset = buffer.position();
buffer.position(posOfFirstChunkOffsetField);
buffer.writeInt(firstChunkOffset);
buffer.position(firstChunkOffset);
writePatchOperations(buffer, this.stringDataSectionDiffAlg.getPatchOperationList());
// Omit others14individual writePatch...
byte[] bufferData = buffer.array();
os.write(bufferData);
os.flush();
}
- First, MAGIC is written. CURRENT_VERSION is mainly used to check that the file is a valid tinker patch file.
- Then write to patchedDexSize
- The fourth place to write is the offset of the data area. You can see that the offset of all map list s is written to the current location by using 0-bit first.
- Next, write all offset s related to each region of the maplist (where the ordering of each region is not important, read and write alike)
- Then each algorithm is executed to write the information of the corresponding region.
- Finally generate the patch file
We're still looking at the string Data Section DiffAlg algorithm.
private <T extends Comparable<T>> void writePatchOperations(
DexDataBuffer buffer, List<PatchOperation<T>> patchOperationList
) {
List<Integer> delOpIndexList = new ArrayList<>(patchOperationList.size());
List<Integer> addOpIndexList = new ArrayList<>(patchOperationList.size());
List<Integer> replaceOpIndexList = new ArrayList<>(patchOperationList.size());
List<T> newItemList = new ArrayList<>(patchOperationList.size());
for (PatchOperation<T> patchOperation : patchOperationList) {
switch (patchOperation.op) {
case PatchOperation.OP_DEL: {
delOpIndexList.add(patchOperation.index);
break;
}
case PatchOperation.OP_ADD: {
addOpIndexList.add(patchOperation.index);
newItemList.add(patchOperation.newItem);
break;
}
case PatchOperation.OP_REPLACE: {
replaceOpIndexList.add(patchOperation.index);
newItemList.add(patchOperation.newItem);
break;
}
}
}
buffer.writeUleb128(delOpIndexList.size());
int lastIndex = 0;
for (Integer index : delOpIndexList) {
buffer.writeSleb128(index - lastIndex);
lastIndex = index;
}
buffer.writeUleb128(addOpIndexList.size());
lastIndex = 0;
for (Integer index : addOpIndexList) {
buffer.writeSleb128(index - lastIndex);
lastIndex = index;
}
buffer.writeUleb128(replaceOpIndexList.size());
lastIndex = 0;
for (Integer index : replaceOpIndexList) {
buffer.writeSleb128(index - lastIndex);
lastIndex = index;
}
for (T newItem : newItemList) {
if (newItem instanceof StringData) {
buffer.writeStringData((StringData) newItem);
}
// Other types of else, write other types of Data
}
}First, we transform our patchOperationList into three OpIndexList s, corresponding to DEL,ADD,REPLACE, and store all item s in the new ItemList.
Then write in turn:
- The number of del operations, the index of each del
- The number of add operations, the index of each add
- Number of replacement operations, each index requiring replacement
- Finally, write the new ItemList in turn.
Here index is done (an index - last index operation is done here)
Other algorithms perform similar operations.
It's better to see what our generated patch looks like:
- First, it contains several fields to prove that you are tinker patch
- Containing offset s that generate each area of the new Dex, you can divide the new Dex into several areas and locate it at the starting point.
- Deleted index (oldDex), new index and value, replaced index and value of Item containing new Dex regions
So, when we guess Patch's logic, it's like this:
- Firstly, according to offset of each region, the starting point of each region is determined.
- Read the items in each area of oldDex, then remove the items that need to be deleted and replaced in oldDex according to the patch, and add the new items and replaced items to form the items in the new Old area.
That is, a region of newDex contains:
oldItems - del - replace + addItems + replaceItemsIt's clear. Look at the code below.~
4. Analysis of Tinker DexPatch Source Code
(1) Looking for entrance
Like diff, there must be a class or method that accepts old dex File and patch File and finally generates new Dex. Don't get stuck in a bunch of security checks, apk decompressed code.
This class is called DexPatchApplier in tinker-commons.
The code for patch is as follows:
@Test
public void testPatch() throws IOException {
File oldFile = new File("Hello.dex");
File patchFile = new File("patch.dex");
File newFile = new File("new.dex");
DexPatchApplier dexPatchGenerator
= new DexPatchApplier(oldFile, patchFile);
dexPatchGenerator.executeAndSaveTo(newFile);
}You can see that it's similar to diff code. Let's look at the code below.
(2) Source code analysis
public DexPatchApplier(File oldDexIn, File patchFileIn) throws IOException {
this(new Dex(oldDexIn), new DexPatchFile(patchFileIn));
}Old Dex will be converted into Dex objects, which are analyzed above, mainly readHeader and readMap. Note that our patchFile is converted to a DexPatchFile object.
public DexPatchFile(File file) throws IOException {
this.buffer = new DexDataBuffer(ByteBuffer.wrap(FileUtils.readFile(file)));
init();
}First read the patch file as byte [], and then call init
private void init() {
byte[] magic = this.buffer.readByteArray(MAGIC.length);
if (CompareUtils.uArrCompare(magic, MAGIC) != 0) {
throw new IllegalStateException("bad dex patch file magic: " + Arrays.toString(magic));
}
this.version = this.buffer.readShort();
if (CompareUtils.uCompare(this.version, CURRENT_VERSION) != 0) {
throw new IllegalStateException("bad dex patch file version: " + this.version + ", expected: " + CURRENT_VERSION);
}
this.patchedDexSize = this.buffer.readInt();
this.firstChunkOffset = this.buffer.readInt();
this.patchedStringIdSectionOffset = this.buffer.readInt();
this.patchedTypeIdSectionOffset = this.buffer.readInt();
this.patchedProtoIdSectionOffset = this.buffer.readInt();
this.patchedFieldIdSectionOffset = this.buffer.readInt();
this.patchedMethodIdSectionOffset = this.buffer.readInt();
this.patchedClassDefSectionOffset = this.buffer.readInt();
this.patchedMapListSectionOffset = this.buffer.readInt();
this.patchedTypeListSectionOffset = this.buffer.readInt();
this.patchedAnnotationSetRefListSectionOffset = this.buffer.readInt();
this.patchedAnnotationSetSectionOffset = this.buffer.readInt();
this.patchedClassDataSectionOffset = this.buffer.readInt();
this.patchedCodeSectionOffset = this.buffer.readInt();
this.patchedStringDataSectionOffset = this.buffer.readInt();
this.patchedDebugInfoSectionOffset = this.buffer.readInt();
this.patchedAnnotationSectionOffset = this.buffer.readInt();
this.patchedEncodedArraySectionOffset = this.buffer.readInt();
this.patchedAnnotationsDirectorySectionOffset = this.buffer.readInt();
this.oldDexSignature = this.buffer.readByteArray(SizeOf.SIGNATURE);
this.buffer.position(firstChunkOffset);
}Remember when we wrote the operation of patch, we first wrote MAGIC and Version to verify that the file was a patch file, then assigned values to patched DexSize and various offsets, and finally located in the first Chunk offset. Remember when we wrote, the field was in the fourth place.
After locating at this location, the data will be read later. When the data is stored, it will be stored in the following format:
- The number of del operations, the index of each del
- The number of add operations, the index of each add
- Number of replacement operations, each index requiring replacement
- Finally, write the new ItemList in turn.
In brief, let's continue with source code analysis.
public DexPatchApplier(File oldDexIn, File patchFileIn) throws IOException {
this(new Dex(oldDexIn), new DexPatchFile(patchFileIn));
}
public DexPatchApplier(
Dex oldDexIn,
DexPatchFile patchFileIn) {
this.oldDex = oldDexIn;
this.patchFile = patchFileIn;
this.patchedDex = new Dex(patchFileIn.getPatchedDexSize());
this.oldToPatchedIndexMap = new SparseIndexMap();
}
In addition to oldDex,patchFile, we also initialized a patchedDex as our final output Dex object.
After the construction is completed, the executeAndSaveTo method is executed directly.
public void executeAndSaveTo(File file) throws IOException {
OutputStream os = null;
try {
os = new BufferedOutputStream(new FileOutputStream(file));
executeAndSaveTo(os);
} finally {
if (os != null) {
try {
os.close();
} catch (Exception e) {
// ignored.
}
}
}
}Direct to execute AndSaveTo (os), the method code is relatively long, we will explain in three sections:
public void executeAndSaveTo(OutputStream out) throws IOException {
TableOfContents patchedToc = this.patchedDex.getTableOfContents();
patchedToc.header.off = 0;
patchedToc.header.size = 1;
patchedToc.mapList.size = 1;
patchedToc.stringIds.off
= this.patchFile.getPatchedStringIdSectionOffset();
patchedToc.typeIds.off
= this.patchFile.getPatchedTypeIdSectionOffset();
patchedToc.typeLists.off
= this.patchFile.getPatchedTypeListSectionOffset();
patchedToc.protoIds.off
= this.patchFile.getPatchedProtoIdSectionOffset();
patchedToc.fieldIds.off
= this.patchFile.getPatchedFieldIdSectionOffset();
patchedToc.methodIds.off
= this.patchFile.getPatchedMethodIdSectionOffset();
patchedToc.classDefs.off
= this.patchFile.getPatchedClassDefSectionOffset();
patchedToc.mapList.off
= this.patchFile.getPatchedMapListSectionOffset();
patchedToc.stringDatas.off
= this.patchFile.getPatchedStringDataSectionOffset();
patchedToc.annotations.off
= this.patchFile.getPatchedAnnotationSectionOffset();
patchedToc.annotationSets.off
= this.patchFile.getPatchedAnnotationSetSectionOffset();
patchedToc.annotationSetRefLists.off
= this.patchFile.getPatchedAnnotationSetRefListSectionOffset();
patchedToc.annotationsDirectories.off
= this.patchFile.getPatchedAnnotationsDirectorySectionOffset();
patchedToc.encodedArrays.off
= this.patchFile.getPatchedEncodedArraySectionOffset();
patchedToc.debugInfos.off
= this.patchFile.getPatchedDebugInfoSectionOffset();
patchedToc.codes.off
= this.patchFile.getPatchedCodeSectionOffset();
patchedToc.classDatas.off
= this.patchFile.getPatchedClassDataSectionOffset();
patchedToc.fileSize
= this.patchFile.getPatchedDexSize();
Arrays.sort(patchedToc.sections);
patchedToc.computeSizesFromOffsets();
// To be continued
} In fact, this is to read the values recorded in the patchFile and assign values to various Sections (roughly corresponding to each map_list_item in the map list) in the TableOfContent of patchedDex.
Next, set the byteCount and other field information.
Continue:
public void executeAndSaveTo(OutputStream out) throws IOException {
// Omit the first part of the code
// Secondly, run patch algorithms according to sections' dependencies.
this.stringDataSectionPatchAlg = new StringDataSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.typeIdSectionPatchAlg = new TypeIdSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.protoIdSectionPatchAlg = new ProtoIdSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.fieldIdSectionPatchAlg = new FieldIdSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.methodIdSectionPatchAlg = new MethodIdSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.classDefSectionPatchAlg = new ClassDefSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.typeListSectionPatchAlg = new TypeListSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.annotationSetRefListSectionPatchAlg = new AnnotationSetRefListSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.annotationSetSectionPatchAlg = new AnnotationSetSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.classDataSectionPatchAlg = new ClassDataSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.codeSectionPatchAlg = new CodeSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.debugInfoSectionPatchAlg = new DebugInfoItemSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.annotationSectionPatchAlg = new AnnotationSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.encodedArraySectionPatchAlg = new StaticValueSectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.annotationsDirectorySectionPatchAlg = new AnnotationsDirectorySectionPatchAlgorithm(
patchFile, oldDex, patchedDex, oldToPatchedIndexMap
);
this.stringDataSectionPatchAlg.execute();
this.typeIdSectionPatchAlg.execute();
this.typeListSectionPatchAlg.execute();
this.protoIdSectionPatchAlg.execute();
this.fieldIdSectionPatchAlg.execute();
this.methodIdSectionPatchAlg.execute();
this.annotationSectionPatchAlg.execute();
this.annotationSetSectionPatchAlg.execute();
this.annotationSetRefListSectionPatchAlg.execute();
this.annotationsDirectorySectionPatchAlg.execute();
this.debugInfoSectionPatchAlg.execute();
this.codeSectionPatchAlg.execute();
this.classDataSectionPatchAlg.execute();
this.encodedArraySectionPatchAlg.execute();
this.classDefSectionPatchAlg.execute();
//To be continued
}This part obviously initializes a bunch of algorithms and then executes them separately. We still use string Data Section PatchAlg for analysis.
public void execute() {
final int deletedItemCount = patchFile.getBuffer().readUleb128();
final int[] deletedIndices = readDeltaIndiciesOrOffsets(deletedItemCount);
final int addedItemCount = patchFile.getBuffer().readUleb128();
final int[] addedIndices = readDeltaIndiciesOrOffsets(addedItemCount);
final int replacedItemCount = patchFile.getBuffer().readUleb128();
final int[] replacedIndices = readDeltaIndiciesOrOffsets(replacedItemCount);
final TableOfContents.Section tocSec = getTocSection(this.oldDex);
Dex.Section oldSection = null;
int oldItemCount = 0;
if (tocSec.exists()) {
oldSection = this.oldDex.openSection(tocSec);
oldItemCount = tocSec.size;
}
// Now rest data are added and replaced items arranged in the order of
// added indices and replaced indices.
doFullPatch(
oldSection, oldItemCount, deletedIndices, addedIndices, replacedIndices
);
}Stick up the rules when we write:
- The number of del operations, the index of each del
- The number of add operations, the index of each add
- Number of replacement operations, each index requiring replacement
- Finally, write the new ItemList in turn.
Look at the code, read in the following order:
- The number of del, all index es of del are stored in an int [].
- The number of adds, and all index es of adds are stored in an int [].
- The number of replaces, and all index of replaces are stored in an int [].
Is it the same as when writing?
Continue, and then get oldItems and oldItemCount in oldDex.
Now there are:
- del count and indices
- add count add indices
- replace count and indices
- oldItems and oldItemCount
Take what we have and continue to implement doFull Patch
private void doFullPatch(
Dex.Section oldSection,
int oldItemCount,
int[] deletedIndices,
int[] addedIndices,
int[] replacedIndices) {
int deletedItemCount = deletedIndices.length;
int addedItemCount = addedIndices.length;
int replacedItemCount = replacedIndices.length;
int newItemCount = oldItemCount + addedItemCount - deletedItemCount;
int deletedItemCounter = 0;
int addActionCursor = 0;
int replaceActionCursor = 0;
int oldIndex = 0;
int patchedIndex = 0;
while (oldIndex < oldItemCount || patchedIndex < newItemCount) {
if (addActionCursor < addedItemCount && addedIndices[addActionCursor] == patchedIndex) {
T addedItem = nextItem(patchFile.getBuffer());
int patchedOffset = writePatchedItem(addedItem);
++addActionCursor;
++patchedIndex;
} else
if (replaceActionCursor < replacedItemCount && replacedIndices[replaceActionCursor] == patchedIndex) {
T replacedItem = nextItem(patchFile.getBuffer());
int patchedOffset = writePatchedItem(replacedItem);
++replaceActionCursor;
++patchedIndex;
} else
if (Arrays.binarySearch(deletedIndices, oldIndex) >= 0) {
T skippedOldItem = nextItem(oldSection); // skip old item.
++oldIndex;
++deletedItemCounter;
} else
if (Arrays.binarySearch(replacedIndices, oldIndex) >= 0) {
T skippedOldItem = nextItem(oldSection); // skip old item.
++oldIndex;
} else
if (oldIndex < oldItemCount) {
T oldItem = adjustItem(this.oldToPatchedIndexMap, nextItem(oldSection));
int patchedOffset = writePatchedItem(oldItem);
++oldIndex;
++patchedIndex;
}
}
}First of all, the purpose here is to write data to the stringData area of patchedDex. The data written should theoretically be:
- Additional data
- Alternative data
- New and replaced data in oldDex
Of course, they need to write in sequence.
So look at the code, first calculate newItemCount=oldItemCount + addCount - delCount, and then start traversing, traversing conditions are 0~oldItemCount or 0~newItemCount.
We expect that the corresponding Item will be written between patchIndex from 0 to new ItemCount.
Item writes through the code we can see:
- Firstly, it is judged whether the patchIndex is included in addIndices, and if it is included, it is written.
- Furthermore, determine whether it is in repalceIndices, and if it is included, write it.
- Then it judges that if oldIndex is delete d or replace d, it will be skipped directly.
- So the last index is that oldIndex is non-delete and replace, which is the same part as items in newDex.
The above three parts of 1.2.4 can form a complete new Dex region.
This completes the patch algorithm for the stringData region.
The execute code of the remaining 14 algorithms is the same (parent class), and the operations performed are similar, and the patch algorithm of each part will be completed.
When all regions are restored, then all that's left is header and mapList, so go back to where all the algorithms have been executed:
public void executeAndSaveTo(OutputStream out) throws IOException {
//1. Various assignments of offset are omitted.
//2. patch algorithm omitting all parts
// Thirdly, write header, mapList. Calculate and write patched dex's sign and checksum.
Dex.Section headerOut = this.patchedDex.openSection(patchedToc.header.off);
patchedToc.writeHeader(headerOut);
Dex.Section mapListOut = this.patchedDex.openSection(patchedToc.mapList.off);
patchedToc.writeMap(mapListOut);
this.patchedDex.writeHashes();
// Finally, write patched dex to file.
this.patchedDex.writeTo(out);
}Locate the header area, write header related data; locate the map list area, write map list related data. When both are completed, you need to write two special fields in the header: signature and checkSum, because these two fields depend on map list, so you have to write a map list after you write it.
This completes the restoration of the complete dex, and finally writes all the data in memory to the file.
V. Simple case analysis
(1) dex preparation
Just now we have a Hello.dex. Let's write another class:
public class World{
public static void main(String[] args){
System.out.println("nani World");
}
}Then compile and type this class into dx files.
javac -source 1.7 -target 1.7 World.java
dx --dex --output=World.dex World.classSo we have two dex, Hello.dex and World.dex.
(2) diff
Using 010 Editor to open two dex, we focus on string_id_item.
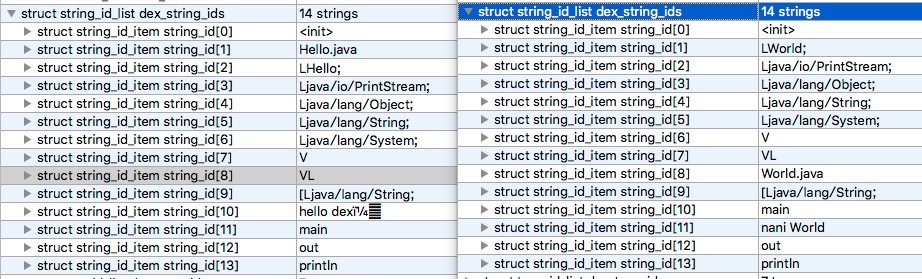
There are 13 strings on each side. According to the diff algorithm we introduced above, we can get the following operations:
The strings on both sides start traversing the comparison separately:
- If < 0, the old Item is considered deleted and recorded as PatchOperation.OP_DEL, and the old Item index is recorded into the PatchOperation object and added to the patchOperationList.
- If > 0, the new Item is considered to be new, recorded as PatchOperation.OP_ADD, and recorded as the new Item index and value to the PatchOperation object and added to the PatchOperation List.
- If = 0, the PatchOperation is not generated.
del 1
add 1 LWorld;
del 2
add 8 World.java
del 10
add 11 naniWorldThen it is sorted according to the index without change.
Next, iterate through all the operations, replacing the operations that are index consistent and adjacent to DEL and ADD with replace
replace 1 LWorld
del 2
add 8 World.java
del 10
add 11 naniWorldEventually, when writing, a traversal is done, the operations are categorized by DEL,ADD,REPLACE, and the item s that appear are placed in the new ItemList.
del ops:
del 2
del 10
add ops:
add 8
add 11
replace ops:
replace 1New ItemList becomes:
LWorld //replace 1
World.java //add 8
naniWorld //add 11 Then write, and the order of writing should be:
2 //del size
2
8 // index - lastIndex
2 // add size
8
3 // index - lastIndex
1 //replace size
1
LWorld
World.java
naniWorldHere we log directly where DexPatch Generator writes ResultToStream:
buffer.writeUleb128(delOpIndexList.size());
System.out.println("del size = " + delOpIndexList.size());
int lastIndex = 0;
for (Integer index : delOpIndexList) {
buffer.writeSleb128(index - lastIndex);
System.out.println("del index = " + (index - lastIndex));
lastIndex = index;
}
buffer.writeUleb128(addOpIndexList.size());
System.out.println("add size = " + addOpIndexList.size());
lastIndex = 0;
for (Integer index : addOpIndexList) {
buffer.writeSleb128(index - lastIndex);
System.out.println("add index = " + (index - lastIndex));
lastIndex = index;
}
buffer.writeUleb128(replaceOpIndexList.size());
System.out.println("replace size = " + addOpIndexList.size());
lastIndex = 0;
for (Integer index : replaceOpIndexList) {
buffer.writeSleb128(index - lastIndex);
System.out.println("replace index = " + (index - lastIndex));
lastIndex = index;
}
for (T newItem : newItemList) {
if (newItem instanceof StringData) {
buffer.writeStringData((StringData) newItem);
System.out.println("stringdata = " + ((StringData) newItem).value);
}
}You can see that the output is:
del size = 2
del index = 2
del index = 8
add size = 2
add index = 8
add index = 3
replace size = 2
replace index = 1
stringdata = LWorld;
stringdata = World.java
stringdata = nani WorldIt is consistent with our analysis above.~~
So other regions can be validated in a similar way, and patch's words are similar, not to mention.
If you support me, you can follow my public number and push new knowledge every day.~
Welcome to my Wechat Public Number: Hongyang Android
(You can leave me a message about the article you want to learn and support the submission.) 