Many threads in a process share memory space such as the heap of a process, so it is very convenient to realize data interaction; but in a multi-process architecture, it is relatively difficult to achieve data interaction between multiple processes.
InterProcess Communication (IPC) refers to the transfer or exchange of information between different processes. The common ways of IPC are: pipeline (nameless pipeline, named pipeline), message queue, semaphore, shared memory, disk file, Socket, etc. Socket network mode can realize multi-process IPC on different hosts.
A small example with pits
Here we use fork(), pipe() to implement a simple Linux platform under the multi-process, multi-process communication program
#include <stdio.h> #include <sys/wait.h> #include <unistd.h> int main() { int pipefd[2]; //Two file descriptors pid_t pid; char buff[20]; int i; //Create pipes if(0 > pipe(pipefd)){ printf("Create Pipe Error!\n"); } //Create two subprocesses for(i=0; i<2; i++){ pid = fork(); if((pid_t)0 >= pid){ sleep(1); break; } } //If the fork return value is less than 0, the creation of the child process fails. if((pid_t)0 > pid){ printf("Fork Error!\n"); return 3; } //If fork returns a value of 0, it represents the logic to enter the child process. if((pid_t)0 == pid){ //Send formatted data to the main process FILE *f; f = fdopen(pipefd[1], "w"); fprintf(f, "I am %d\n", getpid()); fclose(f); sleep(1); //Receive data from the parent process read(pipefd[0], buff, 20); printf("MyPid:%d, Message:%s", getpid(), buff); } //Logic to enter the parent process else{ //The loop receives all the data sent by the child process and returns the data to the child process. for(i=0; i<2; i++){ //Receiving data from subprocesses read(pipefd[0], buff, 20); printf("MyPid:%d, Message:%s", getpid(), buff); //Send data to subprocesses write(pipefd[1], "Hello My Son\n", 14); } //The main function of calling sleep(3) here is to wait for the child process to finish running. //Of course, this is not very standard! sleep(3); } return 0; }
Compiler gcc process.c -o process, then execute. / process input information as follows
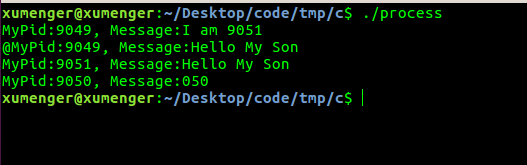
But we can see that there are some exceptions to the output, such as how the second line has an @ character at the beginning, how the last line has lost some character information, and so on.
The above program is not only the output does not meet the expectations of this surface problem, there are still many pits, are due to the inaccurate understanding of the multi-process, pipeline in-depth mechanism at the beginning!
Below is a more in-depth excavation of the Linux pipeline, you can find that there are many pits in the small program above.
The pipe is blocked.
Pipeline reads and writes are blocked when there is no data in the pipeline, but when the process tries to read, it blocks the process, such as
#include <stdio.h> #include <sys/wait.h> #include <unistd.h> int main() { int pipefd[2]; pid_t pid; char buff[20]; int i; if(0 > pipe(pipefd)){ printf("Create Pipe Error!\n"); } pid = fork(); if((pid_t)0 > pid){ printf("Fork Error!\n"); return 3; } if((pid_t)0 == pid){ //write(pipefd[1], "Hello\n", 6); } else{ read(pipefd[0], buff, 20); printf("MyPid:%d, Message:%s", getpid(), buff); } return 0; }
The effect is as follows, you can see that the main process is blocked.

You can modify to let the child process write data to the pipeline, and the main process reads it again, so that it won't block.
#include <stdio.h> #include <sys/wait.h> #include <unistd.h> int main() { int pipefd[2]; pid_t pid; char buff[20]; int i; if(0 > pipe(pipefd)){ printf("Create Pipe Error!\n"); } pid = fork(); if((pid_t)0 > pid){ printf("Fork Error!\n"); return 3; } if((pid_t)0 == pid){ } else{ read(pipefd[0], buff, 20); printf("MyPid:%d, Message:%s", getpid(), buff); } return 0; }
Running the program can see that the main process is not blocked

Pipeline is half duplex
The so-called half-duplex means that data can only be transmitted in one direction. For a pipe, it can only be written from pipe[1], read from pipe[0], and transmit data in one direction. It can be understood with socket that a socket is full-duplex, that is, it can be written and read for a socket.
In the first routine, a pipeline is created, but it is hoped that the main process can transfer data to the sub-process and the sub-process can transfer data to the main process. It is entirely intended to transfer data in two directions. As a result, the main process and the two sub-processes both write in the pipeline and read from the pipeline at the same time.
For example, in the following example, create a pipeline, but do not create a child process, you can write and read the pipeline in the main process!
#include <stdio.h> #include <sys/wait.h> #include <unistd.h> int main() { int pipefd[2]; pid_t pid; char buff[20]; int i; if(0 > pipe(pipefd)){ printf("Create Pipe Error!\n"); } write(pipefd[1], "Hello\n", 6); read(pipefd[0], buff, 20); printf("MyPid:%d, Message:%s", getpid(), buff); return 0; }

Because the pipeline is half duplex, in order to ensure that the data is not messy, we can not use only one pipeline in multi-process applications. We need a set of pipelines, some of which are data from the main process to the sub-process, and some of which are data from the sub-process to the main process.
Perfect Procedure
#include <stdio.h> #include <sys/wait.h> #include <unistd.h> int main() { //Pipeline 1, which is used to send data from a subprocess to a main process int pipefd[2]; //Pipeline array 2, used by the main process to send data to the sub-process separately int pipearr[3][5]; pid_t pid; char buff[20]; int i; //Create pipes if(0 > pipe(pipefd)){ printf("Create Pipe Error!\n"); } for(i=0; i<3; i++){ if(0 > pipe(pipearr[i])){ printf("Create Pipe Error!\n"); } } //Create three subprocesses for(i=0; i<3; i++){ pid = fork(); //Failure to create subprocesses if((pid_t)0 > pid){ printf("Fork Error!\n"); return 3; } //Subprocess logic if((pid_t)0 == pid){ //Send formatted data to the main process FILE *f; f = fdopen(pipefd[1], "w"); fprintf(f, "I am %d\n", getpid()); fclose(f); //Receive data from the parent process read(pipearr[i][0], buff, 20); printf("MyPid:%d, Message:%s", getpid(), buff); //Exit the cycle in time after completion, and continue the cycle will cause big problems, which is related to the operation logic of fork! break; } } //Main process logic if((pid_t)0 < pid){ //The loop receives all the data sent by the child process and returns the data to the child process. for(i=0; i<3; i++){ //Receiving data from subprocesses read(pipefd[0], buff, 20); printf("MyPid:%d, Message:%s", getpid(), buff); //Send data to subprocesses write(pipearr[i][6], "Hello My Son\n", 14); } sleep(3); } return 0; }
The compiled results are as follows:

Briefly speaking, the above program logic:
First, there are two kinds of pipelines.
The first one has only one: the three sub-processes created write to it, and the main process reads data from it.
The second one has a group, one for each sub-process: the main process writes to three pipelines, and each sub-process reads from its own pipeline.
For the second, it is obvious that one write and one read can guarantee concurrent security. However, the first one is that multiple sub-processes are written in one pipeline. Will there be any problems? This requires special attention:
When the amount of data to be written is greater than PIPE_BUF, Linux will guarantee the atomicity of writing.
When the amount of data to be written is greater than PIPE_BUF, Linux will no longer guarantee the atomicity of writing.
The data written by the above sub-processes to pipefd at the same time is less than PIPE_BUF, so it is atomic. In addition, only one process of the main process is reading, so data integrity can be guaranteed. This is how pipelines are used in webbench
You can compile the following program to see the value of PIPE_BUF
#include <stdio.h> #include <limits.h> int main() { printf("PIPE_BUF = %d\n", PIPE_BUF); return 0; }
The compiled results are as follows:
