What is beautifulsoup:
Is a Python library that can extract data from HTML or XML files.It enables you to navigate, find, and modify commonly used documents through your favorite converter.(Official)
beautifulsoup is a parser that parses content specifically, eliminating the hassle of writing regular expressions.
Here we are using bs4:
1. Import module:
from bs4 import beautifulsoup
2. Select a parser to parse the specified content:
Soup=beautifulsoup (parse content, parser)
Common parsers: html.parser,lxml,xml,html5lib
Sometimes you need to install an installation parser, such as pip3 install lxml
BeautifulSoup supports Python's standard HTML parsing libraries by default, but it also supports some third-party parsing libraries:

Differences between parsers (extracted from official documents here)
Beautiful Soup provides the same interface for different parsers, but the parser itself is different.The same document may be parsed by different parsers to produce tree documents with different structures.
The biggest difference is between an HTML parser and an XML parser. See the following fragment parsed into an HTML structure:
BeautifulSoup("<a><b /></a>") # <html><head></head><body><a></a></body></html>
Because the empty tag <b /> does not conform to the HTML standard, the parser parses it into
The same document is parsed using XML as follows (parsing XML requires installing the lxml library).Note that the empty tag <b /> is still retained, and the document is preceded by an XML header instead of being included in the <html>tag:
BeautifulSoup("<a><b /></a>", "xml") # <?xml version="1.0" encoding="utf-8"?> # <a><b/></a>
There are also differences between HTML parsers. If the HTML document being parsed is in a standard format, there is no difference between the parsers except that the parsing speed is different and the result will return the correct document tree.
However, different parsers may return different results if the parsed document is not in a standard format.In the following example, parsing an incorrectly formatted document using lxml results in the </p>tag being directly ignored:
BeautifulSoup("<a></p>", "lxml") # <html><body><a></a></body></html>
Parsing the same document using the html5lib library yields different results:
BeautifulSoup("<a></p>", "html5lib") # <html><head></head><body><a><p></p></a></body></html>
Instead of ignoring the </p>tag, the html5lib library automatically completes the tag and adds the <head>tag to the document tree.
Using pyhton built-in libraries, the results are as follows:
BeautifulSoup("<a></p>", "html.parser") # <a></a>
Similar to the lxml [7] library, the Python built-in library ignores the </p> tag. Unlike the html5lib library, the standard library does not attempt to create a standard-compliant document format or to include document fragments in the <body>tag, unlike the lxml library, it does not even attempt to add the <html>tag.
Because the document fragment'<a></p>'is in the wrong format, all of the above parsing can be counted as'correct'. The html5lib library uses some of the HTML5 standards, so it is closest to'correct'.However, the structure of all parsers can be considered "normal".
Different parsers can affect the results of code execution, and if BeautifulSoup is used in code distributed to others, it is best to indicate which parser is used to reduce unnecessary hassle.
3. Operation
The convention soup is the parsed object returned by beautifulsoup (parser).
3.1 Use label name to find
- Use label names to get nodes:
Sop.Label name
- Use tag names to get node tag names (this focus is name, which is used primarily for tag names that get results when non-tag name filtering):
Sop.Label.name
- Use label names to get node properties:
soup.tag.attrs (get all attributes)
soup.tag.attrs[property name] (get specified property)
soup.label [property name] (get specified property)
soup.label.get (property name)
- Use the label name to get the text content of the node:
Sop.Label.text
Sop.Label.string
soup.label.get_text()
Supplement 1:
The above filtering method can use nesting:
Label a under print(soup.p.a)#p tag
Supplement 2:
The above methods, such as name,text,string,attrs, can be used when the result is a bs4.element.Tag object:
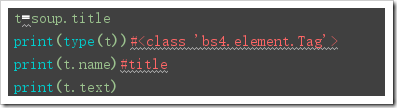
from bs4 import BeautifulSoup html = """ <html > <head> <meta charset="UTF-8"> <title>this is a title</title> </head> <body> <p class="news">123</p> <p class="contents" id="i1">456</p> <a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >advertisements</a> </body> </html> """ soup = BeautifulSoup(html,'lxml') print("Get Nodes".center(50,'-')) print(soup.head)#Get the head er tag print(soup.p)#Return to the first p-Label #Get Node Name print("Get Node Name".center(50,'-')) print(soup.head.name) print(soup.find(id='i1').name) #Get Text Content print("Get Text Content".center(50,'-')) print(soup.title.string)#Return the contents of the title print(soup.title.text)#Return the contents of the title print(soup.title.get_text()) #get attribute print("-----get attribute-----") print(soup.p.attrs)#Returns the contents of a label as a dictionary print(soup.p.attrs['class'])#Returns the value of a label as a list print(soup.p['class'])#Returns the value of a label as a list print(soup.p.get('class')) ############# t=soup.title print(type(t))#<class 'bs4.element.Tag'> print(t.name)#title print(t.text) #Nested Selection: print(soup.head.title.string)
- Get the child node (direct fetching also gets'\n', which would think'\n'is also a label):
soup.label.contents (return value is a list)
soup.tag.children (return value is an iterative object, getting the actual child node requires iteration)

- Get descendant nodes:
soup.tag.descendants (return value is also an iterative object, actual child node needs iteration)
- Get the parent node:
Sop.Label.parent
- Get Ancestor Nodes [Parent Node, Grandfather Node, Great Grandfather Node...]:
Sop.Label.parents
- Get Brother Nodes:
soup.next_sibling (get one of the sibling nodes behind) soup.next_siblings (gets all the sibling nodes that follow) (return value is an iterative object) soup.previous_sibling (get the previous sibling node) soup.previous_siblings (get all the sibling nodes before) (return value is an iterative object)
Supplement 3:
As with Supplement 2, the above functions can be used when the result is a bs4.element.Tag object.
from bs4 import BeautifulSoup html = """ <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <p class="news"><a >123456</a> <a >78910</a> </p><p class="contents" id="i1"></p> <a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >advertisements</a> <span>aspan</span> </body> </html> """ soup = BeautifulSoup(html, 'lxml') #Get Child Nodes print("Get Child Nodes".center(50,'-')) print(soup.p.contents) print("\n") c=soup.p.children#Returns an iterative object for i,child in enumerate(c): print(i,child) print("Get descendant nodes".center(50,'-')) print(soup.p.descendants) c2=soup.p.descendants for i,child in enumerate(c2): print(i,child) print("Get Parent Node".center(50,'-')) c3=soup.title.parent print(c3) print("Get Father, Ancestor Node".center(50,'-')) c4=soup.title.parents print(c4) for i,child in enumerate(c4): print(i,child) print("Get Brothers Node".center(50,'-')) print(soup.p.next_sibling) print(soup.p.previous_sibling) for i,child in enumerate(soup.p.next_siblings): print(i,child,end='\t') for i,child in enumerate(soup.p.previous_siblings): print(i,child,end='\t')
3.2 Use the find\find_all method
- find( name , attrs , recursive , text , **kwargs )
Find the corresponding label based on the parameters, but only return the first qualified result.
- find_all( name , attrs , recursive , text , **kwargs )
Find the corresponding label based on the parameters, but only return all the results that meet the criteria.
- Description of filter condition parameters:
Name: is the label name, filters the labels according to the label name
Attrs: attrs: attributes, tags are filtered according to the key-value pairs of attributes, which can be assigned as: attribute name = value, attrs={attribute name: value} (class_ is required because class is a python keyword)
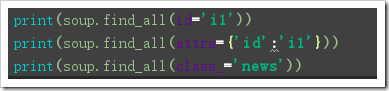
Text: For text content, the tags are filtered according to the specified text content. Using text as the filter condition alone will only return text, so it is generally used in conjunction with other conditions.
Recursive: Specifies whether the filter is recursive. When False, it is not searched in the descendant nodes of the child node, only the child node.
The result of getting a node is a bs4.element.Tag object, so for getting attributes, text content, label names, and so on, you can refer to the previous method of "Filtering results using labels"
from bs4 import BeautifulSoup html = """ <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <p class="news"><a >123456</a> <a id='i2'>78910</a> </p><p class="contents" id="i1"></p> <a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >advertisements</a> <span>aspan</span> </body> </html> """ soup = BeautifulSoup(html, 'lxml') print("---------------------") print(soup.find_all('a'),end='\n\n') print(soup.find_all('a')[0]) print(soup.find_all(attrs={'id':'i1'}),end='\n\n') print(soup.find_all(class_='news'),end='\n\n') print(soup.find_all('a',text='123456'))# print(soup.find_all(id='i2',recursive=False),end='\n\n')# a=soup.find_all('a') print(a[0].name) print(a[0].text) print(a[0].attrs)
3.3 Use select filtering (select uses CSS selection rules)
soup.select('tag name') stands for the specified tag to be filtered out based on the tag.
In CSS #xx stands for the filter id, soup.select('#xxx') stands for the specified tag filtered by id, and the return value is a list.
In CSS. ### stands for the filter class, soup.select('.xxx') stands for the specified label filtered by the class, and the return value is a list.
Nested select: soup.select("#xx.xxxx"), such as ("#id2.news"), is the label of class="news under the id="id2"label, and the return value is a list.
The result of getting a node is a bs4.element.Tag object, so for getting attributes, text content, label names, and so on, you can refer to the method mentioned in the previous "Filter results using labels".
from bs4 import BeautifulSoup html = """ <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <p class="news"><a >123456</a> <a id='i2'>78910</a> </p><p class="contents" id="i1"></p> <a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >advertisements</a> <span class="span1" id='i4'>aspan</span> </body> </html> """ soup = BeautifulSoup(html, 'lxml') sp1=soup.select('span')#The result is a list whose elements are bs4 element label objects print(soup.select("#i2"),end='\n\n') print(soup.select(".news"),end='\n\n') print(soup.select(".news #i2"),end='\n\n') print(type(sp1),type(sp1[0])) print(sp1[0].name)#The elements in the list are bs4 element label objects print(sp1[0].attrs) print(sp1[0]['class'])
Supplement 4:
In case of code incompleteness, soup.prettify() can be used to auto-complete, which is generally recommended to avoid code incompleteness.
from bs4 import BeautifulSoup html = """ <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <p class="news"><a >123456</a> <a id='i2'>78910</a> </p><p class="contents" id="i1"></p> <a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >advertisements</a> <span class="span1" id='i4'>aspan </html> """ soup = BeautifulSoup(html, 'lxml') c=soup.prettify()#The end of the html string above is missing </span>and </body> print(c)
If you want to get a more detailed introduction, you can refer to the official documents. It is good to see that there is a simpler Chinese version:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
Text source network, for learning purposes only. If there is infringement, contact for deletion.
I've put together good technical articles and a summary of my experience in my public number, Python Circle.
Don't panic, I have a set of learning materials, including 40 + e-books, 600 + teaching videos, involving Python basics, crawlers, frames, data analysis, machine learning, etc. Don't be afraid you won't learn!There are also learning and communication groups to learn and progress together ~
