1, Overview
Web crawler, also known as Web spider or Web robot, is mainly used to crawl the content of the target website.
Distinguish web crawlers in terms of function:
- data acquisition
- data processing
- Data storage
For the above three parts, the basic work framework flow is shown as follows:
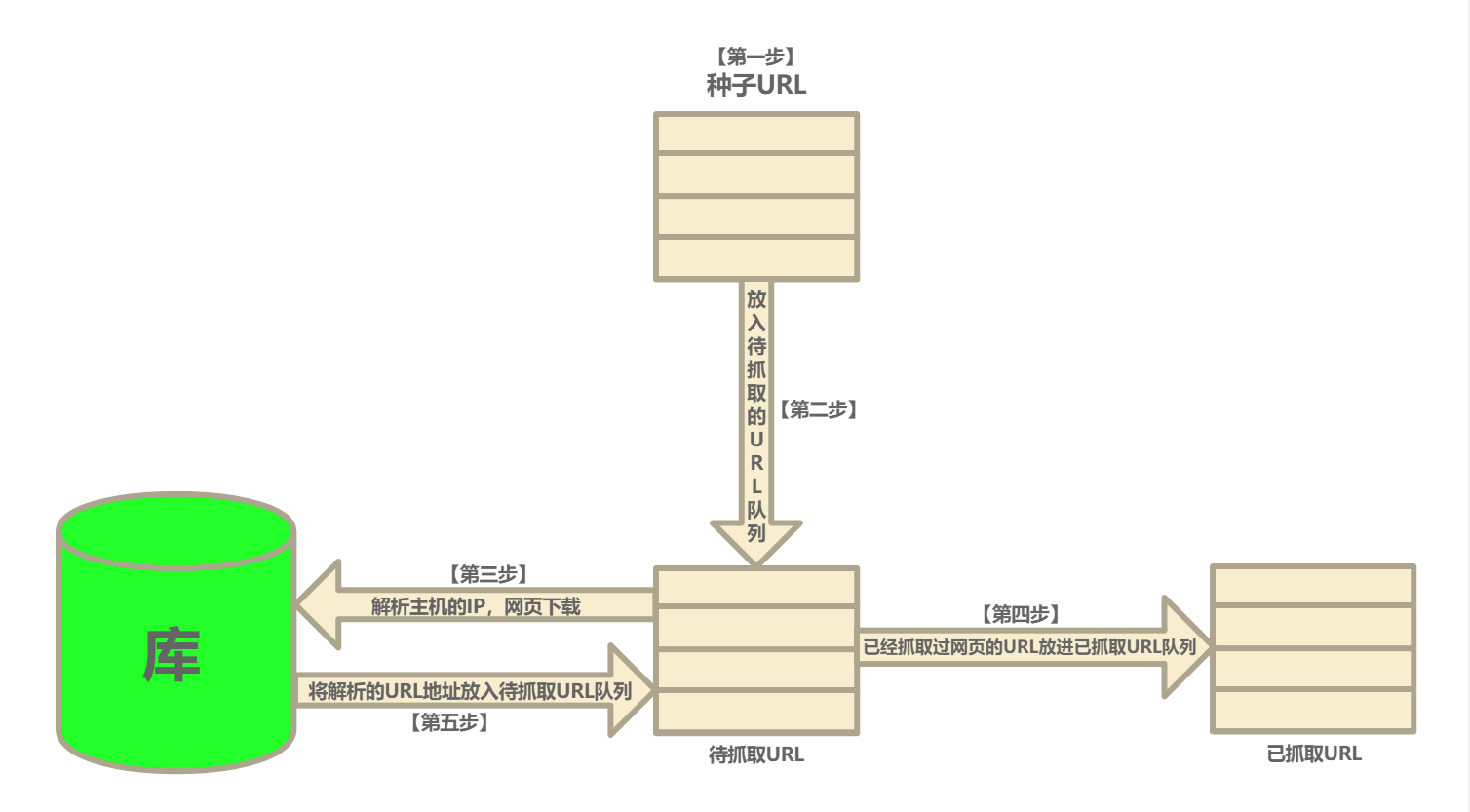
2, Principle
- Function: Download Web page data and provide data source for search engine system.
- Components: controller, parser, resource library.
The Web crawler system first puts the seed URL into the download queue, and then simply takes a URL from the head of the queue to download its corresponding Web page. Get the content of the Web page, store it, and then analyze the link information in the Web page to get some new URLs, which are added to the download queue. Then take out a URL, download the corresponding Web page, and then parse it. This is repeated until the whole network is traversed or certain conditions are met.
3, Reptile classification
1. Traditional reptile
The traditional crawler obtains the URL on the initial web page from the URL of one or several initial web pages. In the process of crawling the web page, it continuously extracts new URLs from the current page and puts them into the queue until certain stop conditions of the system are met.
2. Focus crawler
The workflow of focused crawler is complex. It is necessary to filter the links irrelevant to the topic according to a certain web page analysis algorithm, retain the useful links and put them into the waiting URL queue. Then it will select the next web page URL from the queue according to a certain search strategy, and repeat the above process until a certain condition of the system is reached. In addition, all web pages captured by crawlers will be stored by the system, analyzed, filtered and indexed for future query and retrieval. For focused crawlers, the analysis results obtained in this process may also give feedback and guidance to the future grasping process.
3. Universal web crawler (full web crawler)
General Web crawler, also known as whole Web crawler, crawls from some seed URL s to the whole Web, mainly collecting data for portal sites, search engines and large Web service providers. This kind of Web crawler has a huge crawling range and quantity. It has high requirements for crawling speed and storage space, and relatively low requirements for crawling page order. At the same time, because there are too many pages to be refreshed, it usually works in parallel, but it takes a long time to refresh the page. Although there are some defects, the general Web crawler is suitable for searching a wide range of topics for search engines and has strong application value.
The actual web crawler system is usually realized by the combination of several crawler technologies.
4, Web page crawling strategy
In the crawler system, the URL queue to be fetched is a very important part. The order of URLs in the queue is also a very important issue, because it involves which page to grab first and which page to grab later.
The method to determine the order of these URL s is called a crawl strategy.
1. Width first search:
In the process of crawling, the next level search can be carried out only after the current level search is completed.
- Advantages: the algorithm design and implementation are relatively simple.
- Disadvantages: with the increase of crawling web pages, a large number of irrelevant web pages will be downloaded and filtered, and the efficiency of the algorithm will become low.
2. Depth first search:
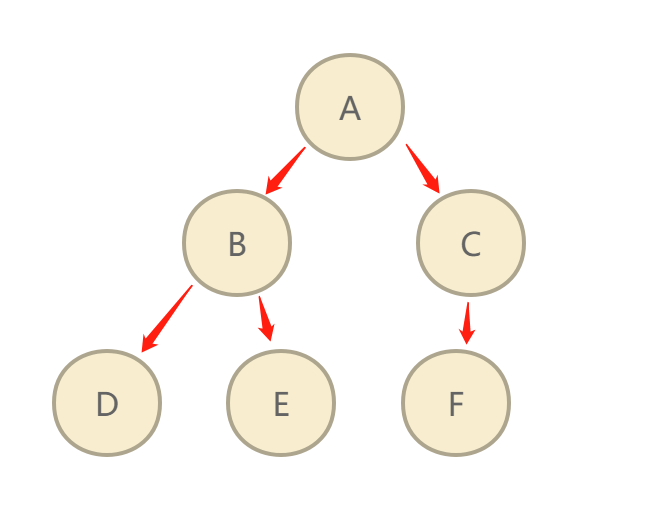
Starting from the starting web page, select a URL to enter, analyze the URL in this web page, grab it link by link, and process the route in the next URL until one route is processed.
For example, in the following figure, the traversal mode of depth first search is A to B to D to e to f (ABDECF), while the traversal mode of width first search is A B C D E F.
3. Best first search:
According to a certain web page analysis method, predict the similarity between the candidate URL and the target web page, or the correlation with the topic, and select one or more URLs with the best evaluation to grab.
4. Number of backlinks policy:
The number of backlinks refers to the number of links to a web page by other web pages. The number of backlinks indicates the degree to which the content of a web page is recommended by others.
5. Partial PageRank policy:
Partial PageRank algorithm draws lessons from the idea of PageRank algorithm. For the downloaded Web pages, together with the URLs in the URL queue to be fetched, it forms a web page collection, calculates the PageRank value of each page, after calculation, arranges the URLs in the URL queue to be fetched according to the size of PageRank value, and grabs the pages in this order.
5, Web page capture method
1. Distributed crawler
It is used for massive URL management in the current Internet. It contains multiple crawlers (programs). The tasks that each crawler (program) needs to complete are similar to those of a single crawler. They download web pages from the Internet, save them on local disks, extract URLs from them, and continue crawling along the directions of these URLs. Because the parallel crawler needs to split the download task, the crawler may send the URL extracted by itself to other crawlers.
These crawlers may be distributed in the same LAN or scattered in different geographical locations.
The popular distributed crawlers:
- Apache Nutch: relying on hadoop to run, hadoop itself will consume a lot of time. Nutch is a crawler designed for search engines. If you don't want to be a search engine, try not to choose nutch.
2. Java crawler
A small program developed in Java to capture network resources. Common tools include Crawler4j, WebMagic, WebCollector, etc.
3. Non Java crawler
- Scrapy: a lightweight, high-level screen capture framework written in Python. The most attractive thing is that scrapy is a framework that any user can modify according to their own needs, and has some high-level functions to simplify the capture process.
6, Project practice
1. Grab the specified web page
Grab the home page of a network
Using the urllib module, this module provides an interface for reading Web page data, which can read the data on www and ftp like reading local files. Urllib is a URL processing package, which collects some modules for processing URLs.
- urllib.request module: used to open and read URLs.
- urllib.error module: contains some errors generated by urllib.request, which can be captured and processed with try.
- urllib.parse module: contains some methods to parse URLs.
- Urllib.robot parser: used to parse robots.txt text file. It provides a separate RobotFileParser class through the can provided by this class_ The fetch () method tests whether the crawler can download a page.
The following code is the code to grab a web page:
import urllib.request
url = "https://www.douban.com/"
# You need to simulate the browser to grab
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
data = response.read()
# Transcoding is required here for normal display
print(str(data, 'utf-8'))
# The following code can print and grab all kinds of information of web pages
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
2. Grab web pages containing keywords
The code is as follows:
import urllib.request
data = {'word': 'One Piece'}
url_values = urllib.parse.urlencode(data)
url = "http://www.baidu.com/s?"
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
print(str(data, 'utf-8'))
3. Download pictures in Post Bar
The code is as follows:
import re
import urllib.request
# Get web page source code
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
# Get all pictures of the web page
def getImg(html):
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
return imglist
html = getHtml('https://tieba.baidu.com/p/3205263090')
html = html.decode('utf-8')
imgList = getImg(html)
imgName = 0
# Cycle save picture
for imgPath in imgList:
f = open(str(imgName) + ".jpg", 'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgName += 1
print('Downloading page %s Picture ' % imgName)
print('The website pictures have been downloaded')
4. Stock data capture
The code is as follows:
import random
import re
import time
import urllib.request
# Grab what you want
user_agent = ["Mozilla/5.0 (Windows NT 10.0; WOW64)", 'Mozilla/5.0 (Windows NT 6.3; WOW64)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11']
stock_total = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
for page in range(1, 8):
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_' + str(page) + '.html'
request = urllib.request.Request(url=url, headers={"User-Agent": random.choice(user_agent)})
response = urllib.request.urlopen(request)
content = str(response.read(), 'gbk')
pattern = re.compile('<tbody[\s\S]*</tbody')
body = re.findall(pattern, str(content))
pattern = re.compile('>(.*?)<')
# Regular matching
stock_page = re.findall(pattern, body[0])
stock_total.extend(stock_page)
time.sleep(random.randrange(1, 4))
# Delete white space characters
stock_last = stock_total[:]
print(' code', '\t', ' abbreviation', '\t', 'Latest price', '\t', 'Fluctuation range', '\t', 'Rise and fall', '\t', '5 Minute increase')
for i in range(0, len(stock_last), 13):
print(stock_last[i], '\t', stock_last[i + 1], '\t', stock_last[i + 2], ' ', '\t', stock_last[i + 3], ' ', '\t',
stock_last[i + 4], '\t', stock_last[i + 5])
6, Conclusion
The Python version used above is 3.9.
The content of this article refers to the book "Python3 data analysis and machine learning practice", which is mainly written for learning.
You can see here. Let's have one button three times (´▽` ʃ ♡ ƪ)
A little lazy after writing ~ (+ ω+)
