Hello, everyone. Let's popularize some knowledge about Hash tables during the national day.
HashMap should be the most commonly used Hash table in our daily life, but HashMap is often called unsafe, and Hash table has a unique capacity expansion mechanism, capacity expansion coefficient, etc.. Many children may not have heard of these things when writing java. Today, the blogger sorted out the knowledge points about Hash tables. Let's have a look!
Security issues of HashMap
We all know that HashMap is thread unsafe, because in some multi-threaded environments, there will be a variety of problems, such as the capacity expansion dead cycle of JDK7 and the dead cycle of link list and tree structure conversion of JDK8. Therefore, we must consider whether concurrency will occur when using it, so as to ensure the normal operation of the program
HashMap is a linked list plus array method before JDK8 and a red black tree introduced after JDK8
In multi-threaded environment, please use HashTable, ConcurrentHashMap, collections.syncronizedmap (HashMap to be wrapped)
JDK7 = = > capacity expansion dead cycle
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}Capacity expansion mode under single thread:
The current node is on the new Hash node to see if there are other nodes:
① No, direct insertion
② Yes, point to that node. Then they become head nodes
Therefore, the linked list will be reversed once the capacity is expanded
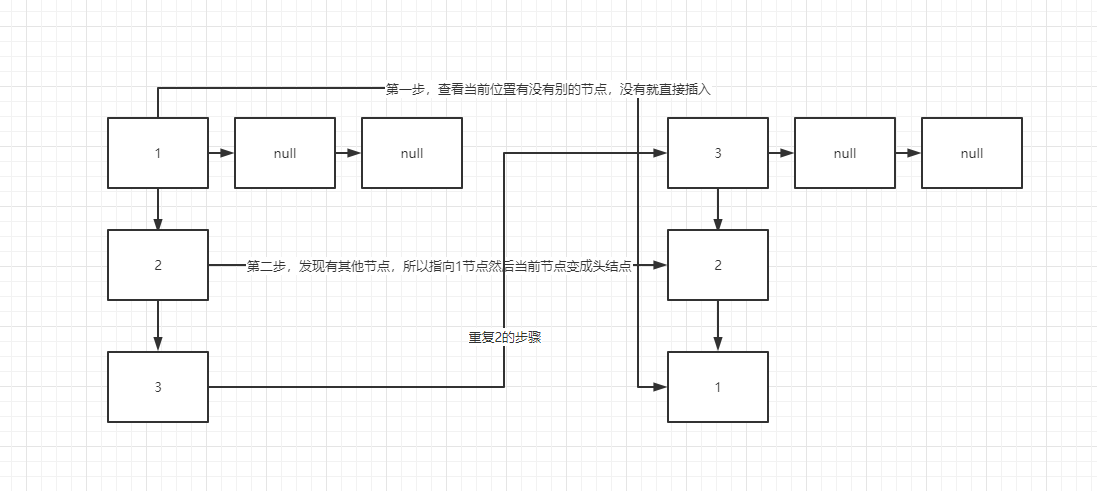
It can be seen that there is no problem under single thread
Problems under multithreading
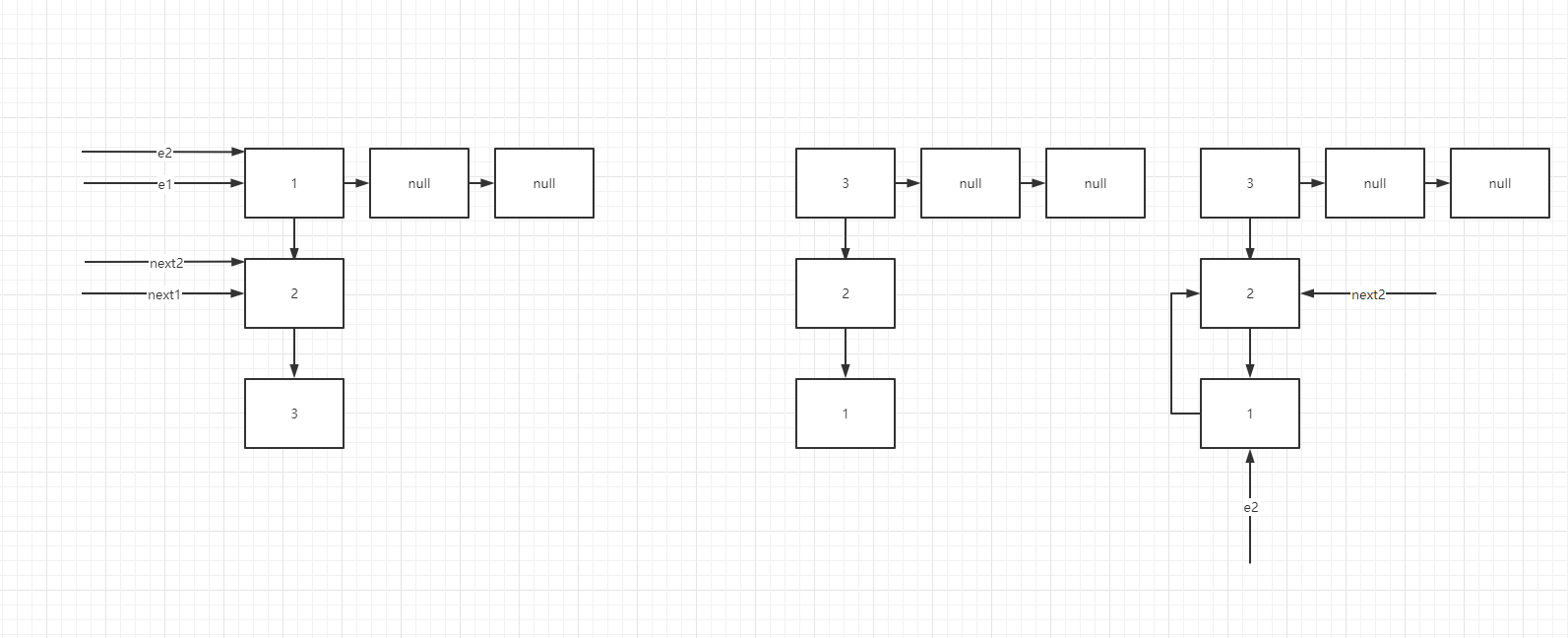
Both threads are just expanding capacity. When thread 1 is ready to start expanding capacity, it is suddenly interrupted. Thread 2 grabs the CPU and expands capacity. At this time, both threads 1-2 are 1 - > 2, right? Then thread 2 expands capacity, and the linked list becomes 3 - > 2 - > 1. At this time, thread 1 gets the CPU and expands capacity,
First time For loop(e = 3) --> At this time 1->2->3; 3.next = null; null = 3; e = 2; Second time 2.next = 3; 2 = e; e = 1; --> 1.next = 2 2.next = 1;
Because this code
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}JDK8 was a dead cycle problem of red and black trees, so I won't repeat it here (in fact, the blogger didn't understand it, 2333)
Therefore, in a multithreaded environment, please use concurrenthashmap (highly recommended)
CocurrentHashMap can be regarded as a thread safe and efficient HashMap. Compared with HashMap, it has the advantages of thread safety and high efficiency compared with HashTable.
Concurrent HashMap is also different in JDK7 and JDK8
JDK7
In JDK1.7, the data structure of ConcurrentHashMap is composed of a segment array and multiple HashEntry arrays. Segment is stored in the form of a linked list array, as shown in the figure.
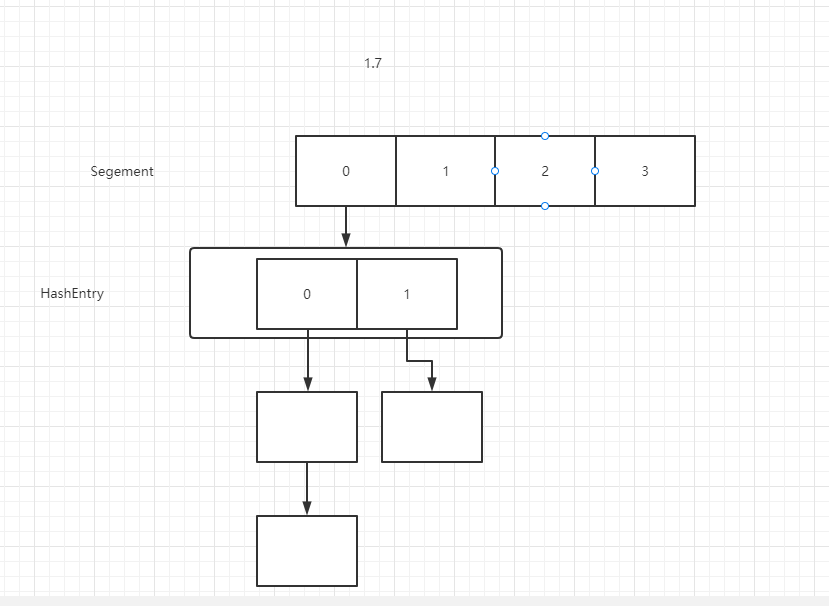
As can be seen from the above figure, the process of locating an element in ConcurrentHashMap requires two hashes. The first Hash is to locate the segment and the second Hash is to locate the head of the linked list. The time taken for two hashes is longer than that for one, but this can lock only the segment where the element is located during the write operation without affecting other segments, which can greatly improve the concurrency.
JDK8
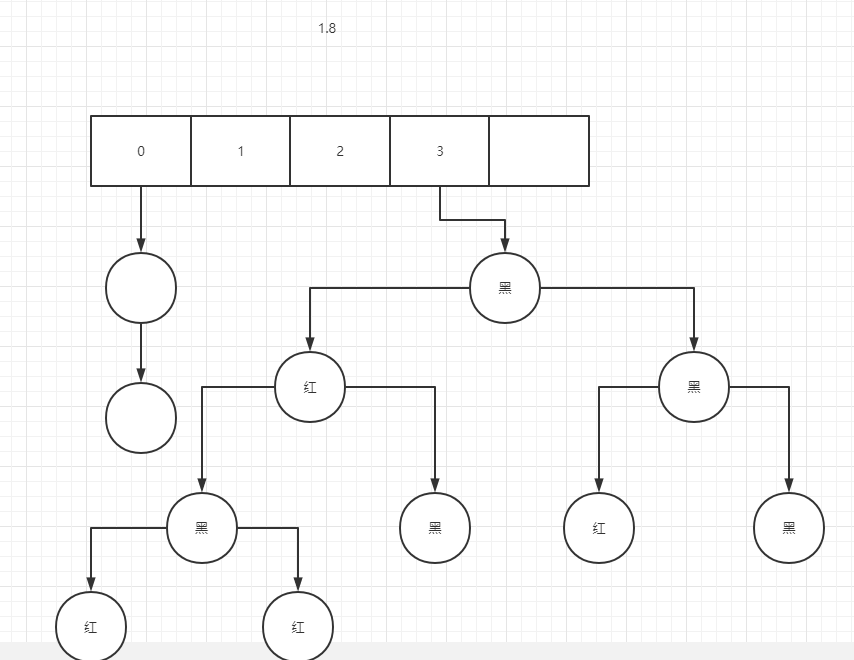
1.8 when the length of the linked list exceeds 8 and the length of the list is greater than 64, it will become a red black tree to ensure the balance of time complexity
Disadvantages of ConcurrentHashMap
Because to ensure efficiency, only part of the data will be locked each time, and the entire table will not be locked. Reading will not ensure that the latest data is read, but only the data that has been successfully inserted. (this thing is much like the repeatable reading of data)
Here, I use CountDownLatch to wait for the end of the thread -- > after submission
Then it is found that the data can still be queried when it is modified -- > but before submission
This may lead to data inconsistency (weak consistency) - > you can solve the synchronized / CAS problem by locking
public class ConcurrentHashMapAndHashMap {
private static CountDownLatch countDownLatch = new CountDownLatch(1);
public static void main(String[] args) {
ConcurrentHashMap<Integer, Integer> concurrentHashMap = new ConcurrentHashMap<>();
try {
//ConcurrentHashMap cannot be passed in empty
concurrentHashMap.put(1, 1);
concurrentHashMap.put(2, 2);
concurrentHashMap.put(3, 3);
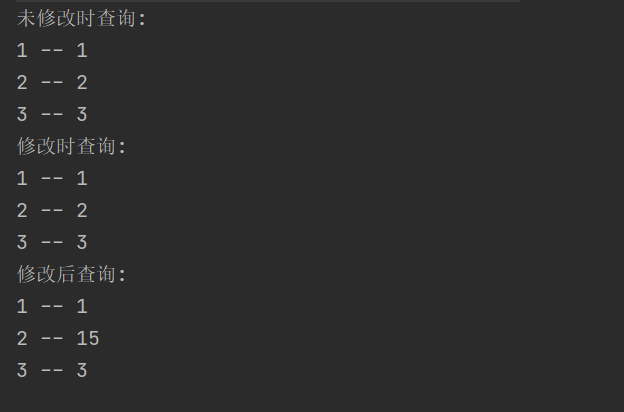
System.out.println("Query when not modified: ");
for (Map.Entry<Integer, Integer> entry: concurrentHashMap.entrySet()) {
System.out.println(entry.getKey() + " -- " + entry.getValue());
}
}catch (NullPointerException e) {
System.out.println("Null pointer");
}
new Thread(()-> {
concurrentHashMap.put(2, 15);
try {
Thread.sleep(2000);
countDownLatch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
System.out.println("Query on modification: ");
for (Map.Entry<Integer, Integer> entry: concurrentHashMap.entrySet()) {
System.out.println(entry.getKey() + " -- " + entry.getValue());
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Query after modification: ");
for (Map.Entry<Integer, Integer> entry: concurrentHashMap.entrySet()) {
System.out.println(entry.getKey() + " -- " + entry.getValue());
}
}
}
Concurrent HashMap does not allow Null values to be inserted to ensure thread safety
Null pointer exception will occur if the key and value in ConCurrentHashMap are null, while the key and value values in HashMap can be null.
The reasons are as follows:
ConCurrentHashMap is used in multi-threaded scenarios. If the value of ConcurrentHashMap.get(key) is null, it is impossible to determine whether the value corresponding to the key is null or there is no corresponding key value.
In the HashMap in the single thread scenario, containsKey(key) can be used to determine whether the key does not exist or whether the value corresponding to the key is null.
Using containsKey(key) to make this judgment in the case of multithreading is problematic, because the value of the key has changed during the two calls of containsKey(key) and ConcurrentHashMap.get(key).
For example, we use the get method to get the value by default. If you don't get the value, it is Null. However, if you insert the Null data and query, because other threads grab the CPU and directly Remove the data, you can check whether it is Null or not. At this time, you don't know whether the data exists or not
Capacity expansion mechanism of HashMap
Each HashMap expansion is twice the expansion,
reason:
1. Because it is an array plus linked list -- >, we must take the module for each data inserted. Because the size of the hash table is always the N-power of 2, we can convert the module to a bit operation. The capacity n is the power of 2, and the binary of n-1 becomes 1. At this time, we can fully hash and reduce hash collision.
Expansion code
newTab[e.hash & (newCap - 1)] = e;
2. Whether to shift is determined by whether the highest position represented after capacity expansion is 1, and there is only one moving direction, that is, to move to the high position. Therefore, whether to shift can be determined according to the detection result of the highest bit, so that the performance can be optimized without shifting every element.
HashMap expansion factor
The expansion factor of hashMap is 0.75. Because it conforms to Poisson distribution, the expansion hash collision is the smallest at this size,
The loading factor is too high, for example, 1, which reduces the space overhead and improves the space utilization, but also increases the query time cost;
The loading factor is too low, such as 0.5. Although it can reduce the query time cost, the space utilization is very low, and the number of rehash operations is increased.
It's just about the Hash collision
The common methods to solve hash collision are
1. Zipper method -- > becomes a linked list
2. Open addressing method -- >
① : linear exploration method: when the current position has a value, move to the right until no collision is found
② : linear compensation detection method: di = q, the next position satisfies Hi=(H(key) + Q) mod Mi = 1,2,... K (k < = m-1), and Q and m are coprime, so that all cells in the hash table can be detected.
Disadvantages: this method will affect the efficiency of finding and deleting when the conflict is serious
3,Rehash