Today I want to introduce to you the crawling and identification of verification code, but only involves the simplest graphic verification code, which is also a common type now.
Many people study python and don't know where to start.
Many people learn python, master the basic syntax, do not know where to find cases to start.
Many people who have already done cases do not know how to learn more advanced knowledge.
Then for these three types of people, I will provide you with a good learning platform, free access to video tutorials, e-books, and the source code of the course!
QQ group: 1097524789
Running platform: Windows
Python version: Python 3.6
IDE: Sublime Text
Other: Chrome browser
Brief process:
Step 1: briefly introduce the verification code
Step 2: crawl a small number of verification code pictures
Step 3: introduce OCR of Baidu character recognition
Step 4: identify the crawling verification code
Step 5: simple image processing
At present, many websites will take a variety of measures to anti crawler, and the verification code is one of them. For example, when it is detected that the access frequency is too high, it will pop up the verification code for you to enter, and confirm that it is not the robot that visits the website. But with the development of reptile technology, there are more and more patterns of verification codes. From the simple graphic verification codes composed of several numbers or letters (which we are going to cover today), to the point touch verification codes that need to click the inverted character letters and the pictures corresponding to the characters, to the polar sliding verification codes that need to slide to the appropriate positions, and to the verification codes of calculation questions Wait a minute. In short, there are all kinds of tricks to make your head bald. Other related knowledge of verification code can be found in this website: captcha.org
Let's briefly talk about the graphic verification code, like this one:


It is composed of letters and numbers, plus some noise, but in order to prevent recognition, simple graphic verification code has become complex now, some with interference lines, some with noise, some with background, font distortion, adhesion, hollowing out, mixing and so on, and even sometimes it is difficult for human eyes to recognize, so they can only click "can't see clearly, another one".
The increase of the difficulty of verification code will bring about the cost of recognition. In the next recognition process, I will directly use the OCR of Baidu character recognition to test the accuracy of recognition, and then confirm whether to choose gray-scale, binary and interference free image operations to optimize the recognition rate.
Next, we will crawl a small number of captcha images and store them in the file.
First, open Chrome browser and visit the website just introduced. There is a captcha image sample link: https://captcha.com/captcha-examples.html?cst=corg There are 60 different types of graphic verification codes in the web page, which is enough for us to identify the experiment.
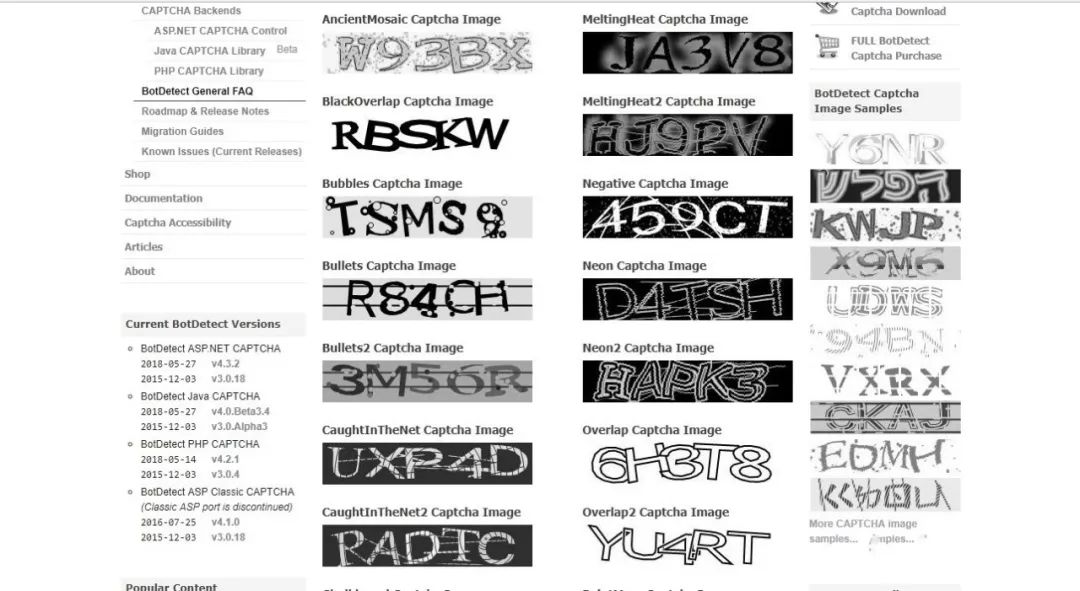
Just look at the code:
import requests
import os
import time
from lxml import etree
def get_Page(url,headers):
response = requests.get(url,headers=headers)
if response.status_code == 200:
# print(response.text)
return response.text
return None
def parse_Page(html,headers):
html_lxml = etree.HTML(html)
datas = html_lxml.xpath('.//div[@class="captcha_images_left"]|.//div[@class="captcha_images_right"]')
item= {}
#Create save captcha folder
file = 'D:/******'
if os.path.exists(file):
os.chdir(file)
else:
os.mkdir(file)
os.chdir(file)
for data in datas:
#Verification code name
name = data.xpath('.//h3')
# print(len(name))
#Verification code link
src = data.xpath('.//div/img/@src')
# print(len(src))
count = 0
for i in range(len(name)):
#Captcha picture filename
filename = name[i].text + '.jpg'
img_url = 'https://captcha.com/' + src[i]
response = requests.get(img_url,headers=headers)
if response.status_code == 200:
image = response.content
with open(filename,'wb') as f:
f.write(image)
count += 1
print('Save the{}Verification code succeeded'.format(count))
time.sleep(1)
def main():
url = 'https://captcha.com/captcha-examples.html?cst=corg'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}
html = get_Page(url,headers)
parse_Page(html,headers)
if __name__ == '__main__':
main()
Still use Xpath to crawl. When you right-click to check the picture, you can see that the web page is divided into two columns, as shown in the red box below. According to the class, it is divided into two columns, and the verification code is located in two columns respectively.
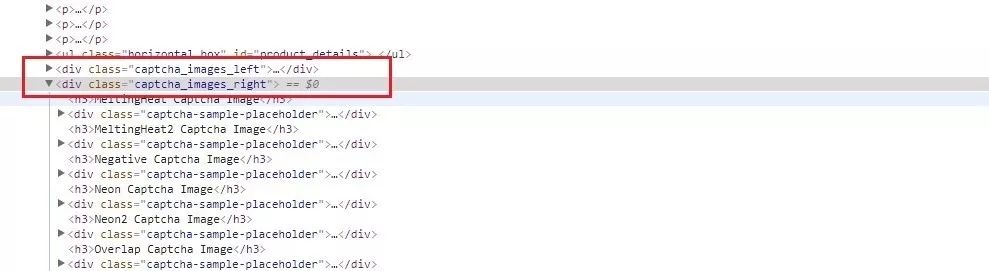
datas = html_lxml.xpath('.//div[@class="captcha_images_left"]|.//div[@class="captcha_images_right"]')
Here, I use path selection in Xpath, and use "|" in path expression to select several paths. For example, I select class as "captcha"_ images_ Left "or" captcha_ images_ Block of "right". Let's look at the running results:
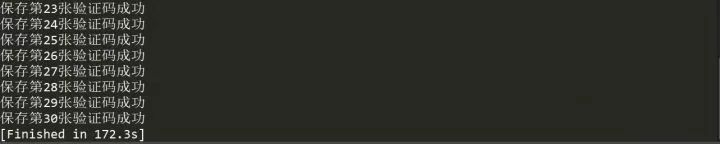
Every time we climb a verification code picture, we have to wait for 1 second. At last, the running time is really desperate. It seems that we need multi threads to speed up the speed. We'll talk about multi processes and multi threads next time. Here we'll take a look at the verification code picture we crawled down.

Now that the pictures are available, the next step is to call the OCR of Baidu character recognition to identify these pictures. Before recognition, I will briefly introduce how to use Baidu OCR. Because many tutorials of identification verification code use the testerocr library, I tried it at the beginning. During the installation process, I encountered a lot of pits, but I didn't continue to use it later. Instead, I chose Baidu OCR To identify. Baidu OCR interface provides the functions of image and text detection, positioning and recognition in natural scenes. The results of text recognition can be used in translation, search, verification code and other scenarios instead of user input. In addition, there are other recognition functions in visual and voice technology. You can read the document directly to understand: Baidu OCR-API document https://ai.baidu.com/docs#/OCR-API/top
When using Baidu OCR, first register the user, then download and install the interface module, and directly input PIP install Baidu AIP into the terminal. Then create a text recognition application to obtain the relevant Appid,API Key and Secret Key. What we need to know is that Baidu AI provides 50000 times of free use of the universal text recognition interface every day, which is enough for us to squander.
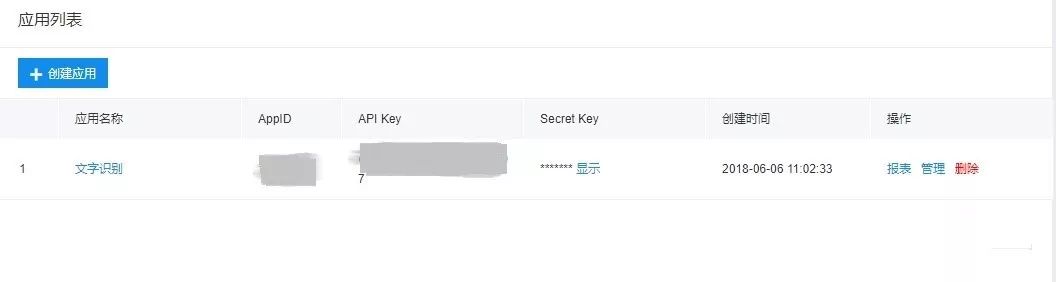
Then you can call the code directly.
from aip import AipOcr
#Your APPID AK SK
APP_ID = 'Your APP_ID '
API_KEY = 'Your API_KEY'
SECRET_KEY = 'Your SECRET_KEY'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
#Read picture
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('test.jpg')
#Call general text recognition, picture parameter is local picture
result = client.basicGeneral(image)
#Defining parameter variables
options = {
#Define image direction
'detect_direction' : 'true',
#Identify language type, default is' CHN_ENG 'mixed Chinese and English
'language_type' : 'CHN_ENG',
}
#Call the universal character recognition interface
result = client.basicGeneral(image,options)
print(result)
for word in result['words_result']:
print(word['words'])
Here we recognize this picture

Let's take a look at the recognition results

The above is the result of direct output after recognition, and the following is the text part extracted separately. As you can see, except for the dash, the text is all output correctly. The picture we use here is jpg format, and the incoming image of text recognition supports jpg/png/bmp format. However, it is mentioned in the technical documents that the uploading of pictures in jpg format will improve the accuracy, which is also the reason why we use jpg format to save when crawling the verification code.
In the output results, each field represents:
-
log_id: the unique log id used to locate the problem
-
Direction: image direction. When the parameter is passed in, it is defined as true to indicate detection, 0 to indicate positive direction, 1 to indicate 90 degrees counter clockwise, 2 to indicate 180 degrees counter clockwise, 3 to indicate 270 degrees counter clockwise, and - 1 to indicate undefined.
-
words_result_num: number of results identified, i.e. word_ Number of elements of result
-
word_result: define and identify element array
-
words: recognized string
There are also some optional fields you can go to the document to familiarize yourself with.
Next, what we need to do is to identify the verification code we crawled before with the OCR just introduced to see if we can get the correct result.
from aip import AipOcr
import os
i = 0
j = 0
APP_ID = 'Your APP_ID '
API_KEY = 'Your API_KEY'
SECRET_KEY = 'Your SECRET_KEY'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
#Read picture
file_path = 'D:\******\Captcha picture'
filenames = os.listdir(file_path)
# print(filenames)
for filename in filenames:
#Combining a path with a filename is the full path to each file
info = os.path.join(file_path,filename)
with open(info, 'rb') as fp:
#Get path to folder
image = fp.read()
#Call general text recognition, picture parameter is local picture
result = client.basicGeneral(image)
#Defining parameter variables
options = {
'detect_direction' : 'true',
'language_type' : 'CHN_ENG',
}
#Call the universal character recognition interface
result = client.basicGeneral(image,options)
# print(result)
if result['words_result_num'] == 0:
print(filename + ':' + '----')
i += 1
else:
for word in result['words_result']:
print(filename + ' : ' +word['words'])
j += 1
print('Common identification verification code{}Zhang'.format(i+j))
print('Text not recognized{}Zhang'.format(i))
print('Text recognized{}Zhang'.format(j))
Just like identifying pictures, here we read all the pictures in the folder verification code pictures, let OCR identify them in turn, and use "word" to_ result_ The "num" field determines whether the text is recognized successfully. If the text is recognized, the result will be printed. If the text is not recognized, the "-- -" will be used instead, and the recognition result will be corresponding to the file name. Finally, count the number of recognition results, and then look at the recognition results.
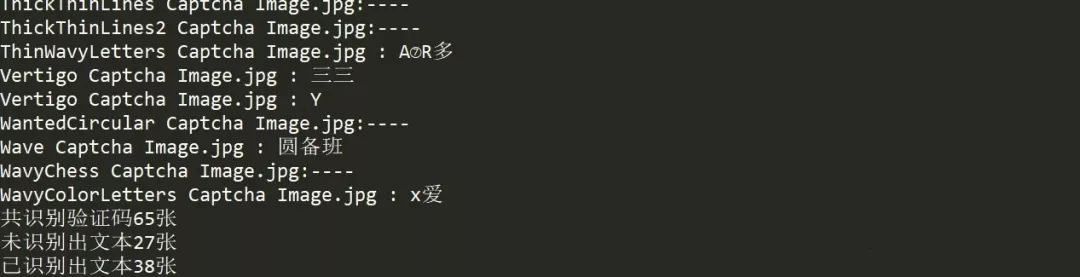
If you see the result, you can only say Amazing! 65 of the 60 images are actually recognized, and 27 of them are unrecognized text. This is not the result I want. First, let's look at the problem and see "vertigo captcha" Image.jpg "This picture name appeared twice. It is suspected that it was interfered in the recognition process, so it was recognized as two lines of text and output, which explains why there are five more verification code pictures. But! Why there are so many unrecognized texts, and the verification code composed of English numbers has been identified into Chinese. It seems that the idea of only relying on OCR to identify the verification code picture will not work. Then we will use the image processing method to re identify the verification code.
Or the picture used to introduce the verification code


This picture can't be recognized. It's bald. Next, we will process this picture to see if it can be correctly recognized by OCR
from PIL import Image
filepath = 'D:\******\Captcha picture\AncientMosaic Captcha Image.jpg'
image = Image.open(filepath)
#Transfer in 'L' to convert picture to grayscale image
image = image.convert('L')
#Enter '1' to binarize the picture
image = image.convert('1')
image.show()
After this transformation, let's see what the picture looks like?

It's really different. Take it to see if you can recognize it or if it fails ~ ~ continue to modify
from PIL import Image
filepath = 'D:\******\Captcha picture\AncientMosaic Captcha Image.bmp'
image = Image.open(filepath)
#Pass in'L'to convert the picture to a grayscale image
image = image.convert('L')
#Enter 'l' to binarize the picture. The default binarization threshold is 127
#Specify threshold for conversion
count= 170
table = []
for i in range(256):
if i < count:
table.append(0)
else:
table.append(1 )
image = image.point(table,'1')
image.show()
Here I save the image as bmp mode, and then specify the threshold value of binarization. If not specified, the default value is 127. We need to convert the original image to gray image first, not directly on the original image. Then add the required pixels of the verification code to a table, and then use the point method to build a new verification code picture.


Now I have recognized the text, although I don't know why it is recognized as "Zhen". After analysis, I found that it's because I set the parameter "language" in z_ Type is CHN_ENG "is a mixed mode of Chinese and English, so I changed it to" ENG "English type, and found that it can be recognized as characters, but it is still not recognized successfully. After trying other methods I know, I said that I was speechless, and I decided to continue to try other methods of PIL library.
#Find edge image = image.filter(ImageFilter.FIND_EDGES) # image.show() #Edge enhancement image = image.filter(ImageFilter.EDGE_ENHANCE) image.show()

Still can't recognize correctly, I decided to change the verification code to try......

I found this one with a shadow
from PIL import Image,ImageFilter
filepath = 'D:\******\Captcha picture\CrossShadow2 Captcha Image.jpg'
image = Image.open(filepath)
#Transfer in 'L' to convert picture to grayscale image
image = image.convert('L')
#Enter 'l' to binarize the picture. The default binarization threshold is 127
#Specify threshold for conversion
count= 230
table = []
for i in range(256):
if i < count:
table.append(1)
else:
table.append(0)
image = image.point(table,'1')
image.show()
After simple processing, we get the following pictures:

The results are as follows:

Recognition is successful, old tears!!! It seems that Baidu OCR can recognize the verification code, but the recognition rate is still a little low. It needs to process the image to increase the recognition accuracy. However, baidu OCR is still very accurate in the recognition of standard text.
So compared with other verification codes, what makes this verification code easier to be read by OCR?
-
The letters are not superimposed on each other and do not cross each other horizontally. That is, you can draw a box outside each letter without overlapping.
-
There are no background colors, lines or other noises that interfere with the OCR program.
-
The contrast between the white background color and the dark letters is high.
This kind of verification code is relatively easy to recognize. In addition, the white background and black characters on the image recognition belong to the standard standard text, so the recognition accuracy is high. As for the more complex graphic verification code, it needs deeper image processing technology or trained OCR to complete. If it is only a simple identification of a verification code, it is better to check the image input manually. If it is more, it can also be handed over to the coding platform for identification