Four stage pipeline 8-bit adder
Code
////////////////////////////////////////////////////////////////////////////////// // Company: NanJing University of Information Science & Technology // Engineer: Yang Cheng Yu // // Create Date: 2020/01/21 20:01:50 // Design Name: add_8bit // Module Name: add_8bit // Project Name: // Target Devices: // Tool Versions: // Description: // // Dependencies: // // Revision: // Revision 0.01 - File Created // Additional Comments: // ////////////////////////////////////////////////////////////////////////////////// //Four stage pipeline 8-bit adder module add_8bit( input clk, input[7:0] a_in, //8-digit input a input[7:0] b_in, //8-digit input b input cin, //Carry input output reg[7:0] sum_out, //Add and output output reg cout //Carry output ); reg c_0to1bit; //0-1 bit carry output register reg[1:0] sum_0to1bit; //0-1 bit plus output register reg c_2to3bit; //2-3 bit carry output register reg[1:0] sum_2to3bit; //2-3 bit plus output register reg c_4to5bit; //4-5 bit carry output register reg[1:0] sum_4to5bit; //4-5 bit plus output register reg c_6to7bit; //6-7 bit carry output register reg[1:0] sum_6to7bit; //6-7 bit plus output register reg[1:0] tempa_2to3bit; //2-3 bit input a register reg[1:0] tempb_2to3bit; //2-3 bit input b register reg[1:0] tempa_4to5bit; //4-5 bit input a register reg[1:0] tempb_4to5bit; //4-5 bit input b register reg[1:0] tempa_6to7bit; //6-7 bit input a register reg[1:0] tempb_6to7bit; //6-7 bit input b register //0-1-bit addition calculation, first level pipeline always@(posedge clk)begin {c_0to1bit,sum_0to1bit} <= a_in[1:0] + b_in[1:0] + cin; tempa_2to3bit <= a_in[3:2]; tempb_2to3bit <= b_in[3:2]; end //2-3-bit addition calculation, second stage pipeline always@(posedge clk)begin {c_2to3bit,sum_2to3bit} <= tempa_2to3bit + tempb_2to3bit + c_0to1bit; tempa_4to5bit <= a_in[5:4]; tempb_4to5bit <= b_in[5:4]; end //4-5-bit addition calculation, third level pipeline always@(posedge clk)begin {c_4to5bit,sum_4to5bit} <= tempa_4to5bit + tempb_4to5bit + c_2to3bit; tempa_6to7bit <= a_in[7:6]; tempb_6to7bit <= b_in[7:6]; end //6-7-bit addition calculation, fourth level pipeline always@(posedge clk)begin {c_6to7bit,sum_6to7bit} <= tempa_6to7bit + tempb_6to7bit + c_4to5bit; end //Final result output always@(posedge clk)begin cout <= c_6to7bit; sum_out <= {sum_6to7bit,sum_4to5bit,sum_2to3bit,sum_0to1bit}; end endmodule
RTL view
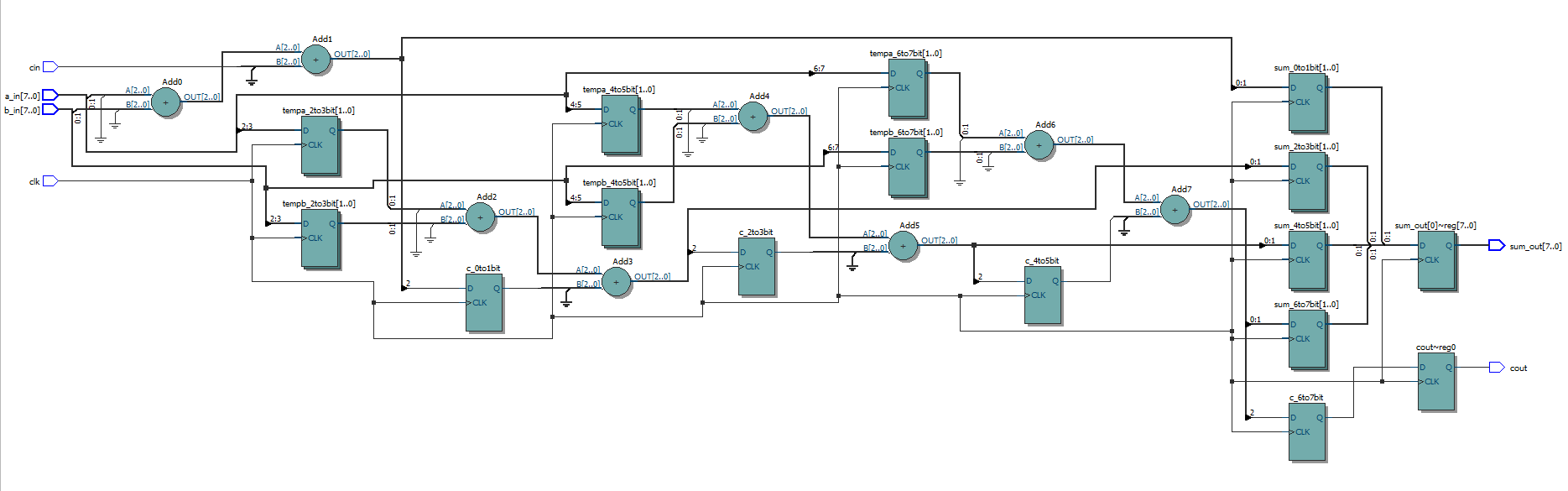
The essential purpose of using pipeline in this design is to store the carry output of each level.
Simulation code
`timescale 1ns/1ps `define clock_period 20 module add_8bit_tb; reg clk ; reg[7:0] a_in ; reg[7:0] b_in ; reg cin ; wire[7:0] sum_out ; wire cout ; add_8bit add_8bit( .clk (clk), .a_in (a_in), .b_in (b_in), .cin (cin), .sum_out (sum_out), .cout (cout) ); initial clk=1; always#(`clock_period/2)clk=~clk; initial begin a_in = 8'b10010010; b_in = 8'b01001101; cin = 1'b1; #(`clock_period*100); a_in = 8'b11110110; b_in = 8'b01101001; cin = 1'b1; #(`clock_period*100); $stop; end endmodule
Gate level simulation waveform
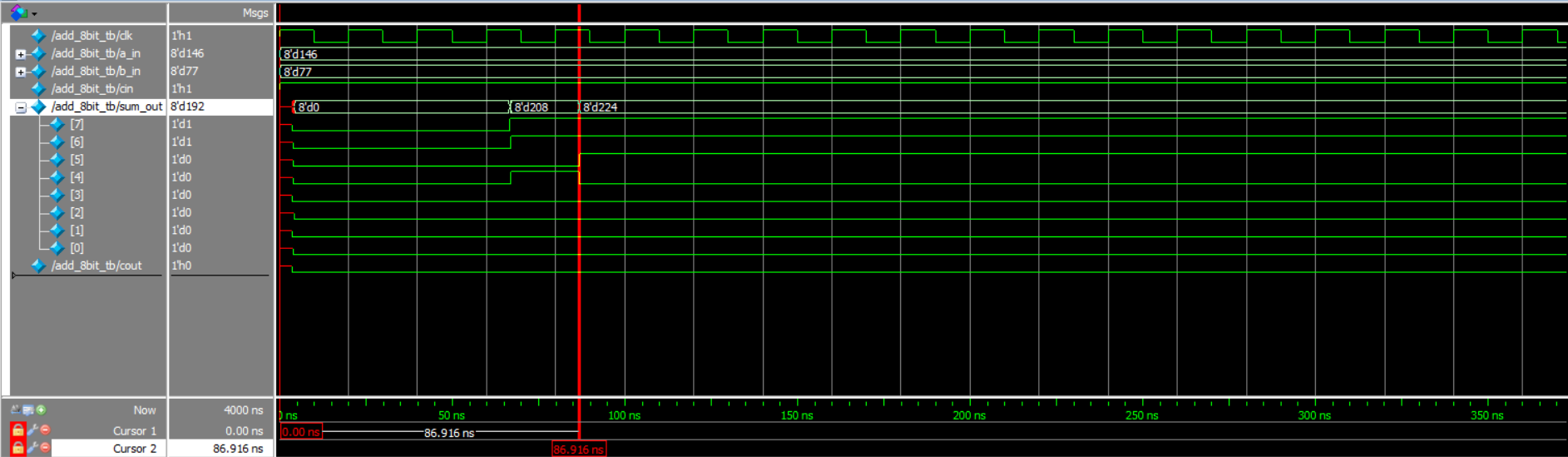
It can be seen from the simulation code that the calculation process costs 86.916ns.
Ordinary 8-bit adder
Code
module add_8bit_common( input clk, input [7:0] a_in, input [7:0] b_in, input cin, output reg cout, output reg[7:0] sum_out ); always@(posedge clk)begin {cout,sum_out} <= cin + a_in + b_in; end endmodule
RTL view
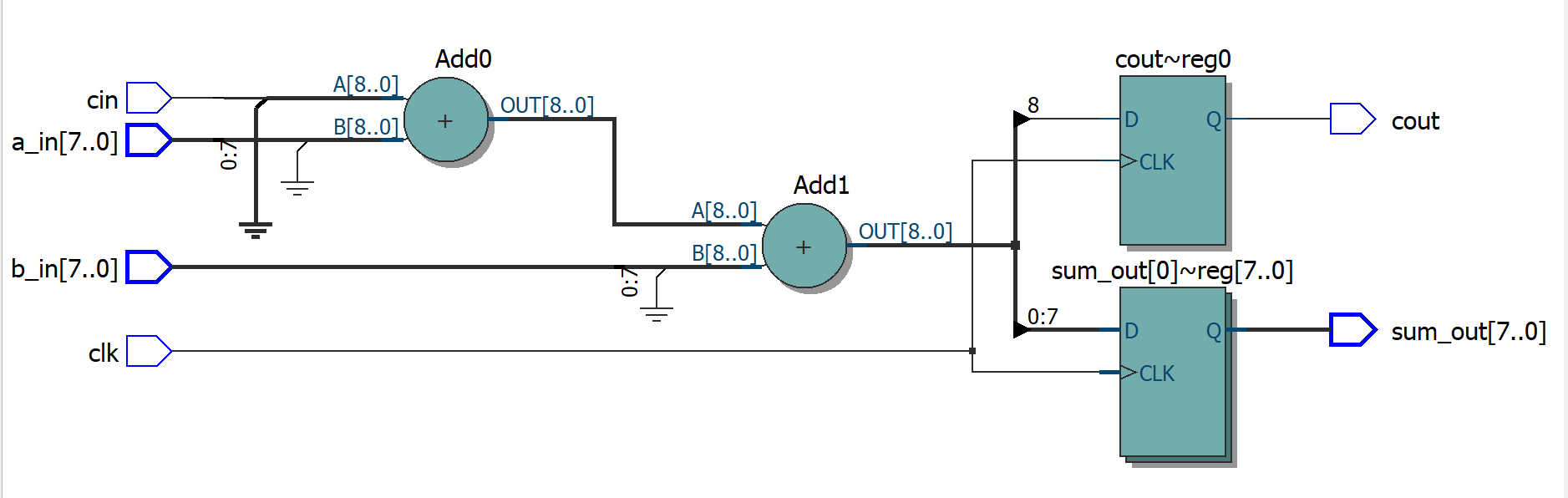
Simulation code
`timescale 1ns/1ps `define clock_period 20 module add_8bit_common_tb; reg clk ; reg[7:0] a_in ; reg[7:0] b_in ; reg cin ; wire cout ; wire[7:0] sum_out ; add_8bit_common add_8bit_common( .clk (clk), .a_in (a_in), .b_in (b_in), .cin (cin), .cout (cout), .sum_out (sum_out) ); initial clk=1; always#(`clock_period/2)clk=~clk; initial begin a_in=8'b10010010; b_in=8'b00011110; cin=1'b1; #(`clock_period*100); a_in=8'b11100010; b_in=8'b01111010; cin=1'b1; #(`clock_period*100); $stop; end endmodule
Gate level simulation waveform
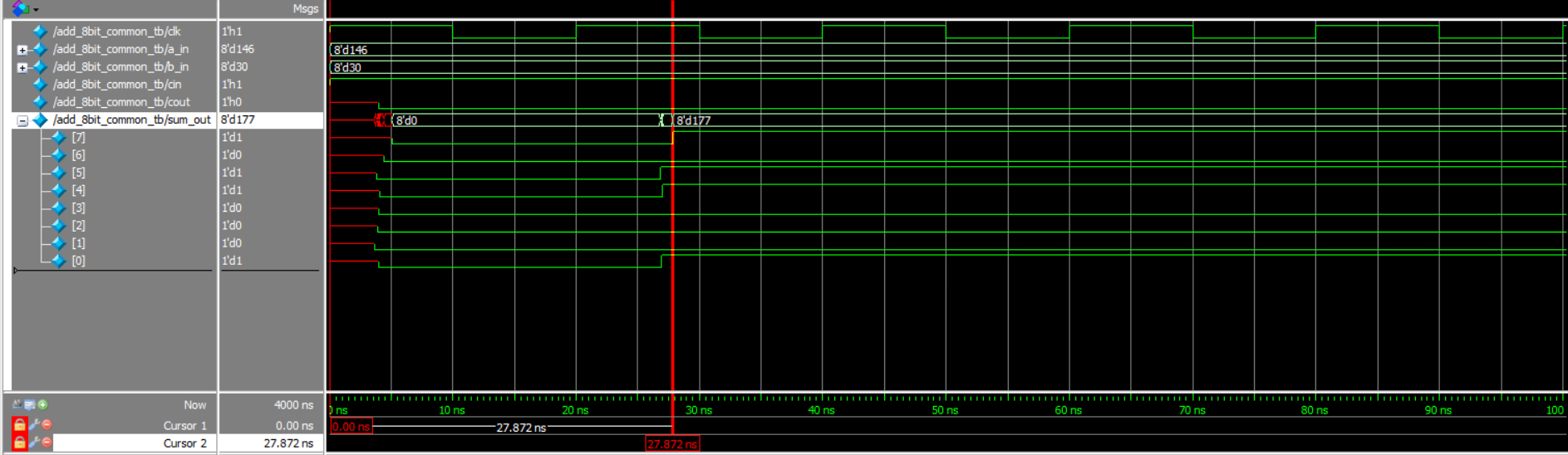
The final result is 27.872ns.
If the two schemes are used to calculate 1000 groups of data continuously, it will cost 27872ns in theory,
The pipeline adder needs 86.916 + 20 * 999 = 20066.916ns. Therefore, it can be seen that the pipeline processing method will be faster than the non pipeline circuit in continuous processing of large quantities of data, but it will be slower in processing a small amount of data, especially when the circuit is simple.

