Article Directory
- 1. Chain List
- Chain lists in the Linux kernel are special
- list_entry, container_of and offsetof macros
- An example illustrates `offsetof` and `container_of`Macro
- Operations on linked lists
- 1. Create a list of chains
- 2. Add Node to Chain List
- 3. Delete Nodes
- 4. Move merge nodes
- 5. Determine whether it is empty
- Traversing Linked Lists
- 2. Queues
- 3. Mapping
- Differences between hash and binary trees
- 1. Initialize an idr
- 2. Assign a new UID
- Find UID
- Delete UID
- Undo idr
- 4. Binary Tree
- Data structure and selection
- 1. Chain List
- 2. Queues
- 3. Mapping
- 4. Black and Red Trees
- The kernel also implements cardinality (trie) and bitmaps
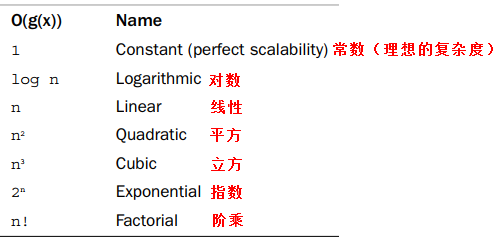
- Algorithmic Complexity (Scalability)
Chain List, Queue, Map, Binary Tree
1. Chain List
Is the simplest and most common data structure on Linux.
Data structure for storing and manipulating variable number elements.
Linu Kernel Standard Chain List uses a highly flexible ring two-way Chain list.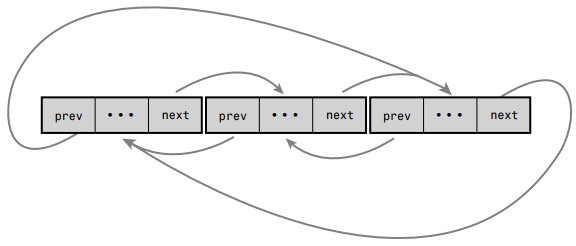
Chain lists in the Linux kernel are special
The chain table implementation in the Linux kernel is different.
It doesn't put data structures in the list.
Instead, the list node is inserted into the data structure (embedded a linked list node in the structure!).
1. Put the data structure in the node:
/* list_element Is a Node */ struct list_element { unsigned long tail_length; /* data1 */ unsigned long weight; /* data2 */ bool is_fantastic; /* data3 */ struct list_element *next; struct list_element *prev; };
2. Place nodes in the data structure:
/* list_head Is a Node */ struct list_head { struct list_head *next struct list_head *prev; } struct fox { unsigned long tail_length; /* data1 */ unsigned long weight; /* data2 */ bool is_fantastic; /* data3 */ struct list_head list; /* Will list_head node into fox data structure */ };
Why do I do this? My understanding is:
- This allows the nodes of this chain table to be embedded in multiple types of structures, that is, the chain table of this type can hold multiple types of data.
- The kernel already provides a variety of routines for creating, managing, and manipulating linked lists, without any concern about the embedded data structure.
- Simple two pointers don't take up much space. There is a lot of data in the kernel. Embedding data into nodes can be a waste, especially in the embedded domain.
list_entry, container_of and offsetof macros
list_entry()
container_of()
offsetof()
The problem is that such a list of chains index only the member list of a node, so how to get the data of a node? In fact, only the starting address of the node is needed.How do I get the starting address of a node by its pointer?, you need to use the macro container_provided by LinuxOf.
offsetof is used to determine the offset position of members in a structure, container_The of macro is used to get the address of the structure based on the address of the member.
Container_The of macro requires three parameters:
ptr denotes the location of a member member.
Typee structure type,
The name of a member of the member structure.
// offsetof, calculates the offset of member members in a structure whose structure type is type #define offsetof(type, member) (size_t)&(((type*)0)->member) // container_of, get the starting address of the node based on the structure member pointer, structure type, member name #define container_of(ptr, type, member) ({ const typeof( ((type*)0)->member ) *__mptr = (ptr); (type *)( (char *)__mptr - offsetof(type, member) ); // (char *)(ptr) causes the pointer's add or subtract operation step to be one byte })
An example of offsetof and container_of macro
#include <stdio.h> #include <stddef.h> // Chain Lists in Linux struct list_head{ struct list_head *next; struct list_head *prev; }; // A custom data structure, and then put nodes into this data structure struct AAA{ char i; long j; struct list_head list; }; // &((type *)0) ->member) Gets the relative position of member directly #define offset_of_member(type, member) (size_t)&( ((type *)0)->member ) // Get the starting address of the node based on the structure member pointer, structure type, and member name (simplified and easy to understand) // (char *)(ptr) causes the pointer's add or subtract operation step to be one byte #define container_of(ptr, type, member) ({ \ (type *)( (char *)ptr - offset_of_member(type, member) ); \ }) // //Actual implementation as follows // #define container_of(ptr, type, member) ({ \ // const typeof( ((type *)0)->member ) *__mptr = (ptr); \ // (type *)( (char *)ptr - offset_of_member(type, member) ); \ // }) int main() { // Define and initialize the AAA type structure variable aaa, which is also a node struct AAA aaa = { .i = 127, .j = 123456789, .list.next = aaa.list.prev = NULL, }; printf("\naaa.i = %d\naaa.j = %d\n", aaa.i, aaa.j); // View offset of member printf("offset i: %d\n", offset_of_member(struct AAA, i)); printf("offset j: %d\n", offset_of_member(struct AAA, j)); printf("offset p: %d\n", offset_of_member(struct AAA, list)); printf("offset p1: %d\n", offset_of_member(struct AAA, list.next)); printf("offset p2: %d\n", offset_of_member(struct AAA, list.prev)); // View the starting address of node aaa directly printf("\nobs_aaa1_addr: %p\n", &aaa); // Via container_of indirectly gets the starting address of node aaa printf("obs_aaa2_addr: %p\n", container_of(&aaa.i, struct AAA, i)); printf("obs_aaa3_addr: %p\n", container_of(&aaa.j, struct AAA, j)); printf("obs_aaa4_addr: %p\n", container_of(&aaa.list, struct AAA, list)); printf("obs_aaa5_addr: %p\n", container_of(&aaa.list.next, struct AAA, list.next)); printf("obs_aaa6_addr: %p\n", container_of(&aaa.list.prev, struct AAA, list.prev)); return 0; }
Operations on linked lists
The complexity of all functions for chain table operations is O(1).The task is completed at a constant time regardless of the size of the list and the parameters passed in.
1. Create a list of chains
Is to create a special pointer index that can be indexed to the entire chain table.The head node of the chain table, the index node, but in fact it is a regular list_head.
static LIST_HEAD(fox_list); // Define and initialize a named fox_list Chain List
2. Add Node to Chain List
// Insert a new node after the head node list_add(struct list_head *new, struct list_head *head); // Insert a new node before the head node, which you can use to implement queues list_add_tail(struct list_head *new, struct list_head *head);
3. Delete Nodes
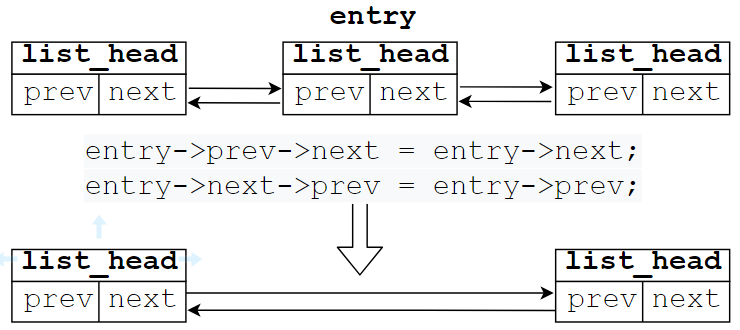
list_del(struct list_head *entry), which does not release the memory occupied by the data structure corresponding to the entry and entry nodes, simply removes the entry element from the list.
// Remove the fox data structure from the list, but the node's data is still there list_del(&fox->list); // Delete entry node from the list of chains and reinitialize entry list_del_init(struct list_head *entry);
4. Move merge nodes
move
// Remove the list node from one list list and add the list node after the head node of another list list_move(struct list_head *list, struct list_head *head); // Remove the list node from one list list and add the list node before the head node of another list list_move_tail(struct list_head *list, struct list_head *head);
merge
// After adding the list to the head node of another list list_splice(struct list_head *list, struct list_head *head); // After adding the list to the head node of another list, reinitialize the empty list list_splice_init(struct list_head *list, struct list_head *head);
5. Determine whether it is empty
list_empty(struct list_head *head);
Traversing Linked Lists
Unlike the list operation function, traversing a list of chains is O(n), n is the number of elements in the list.
1. Basic Methods
Using list_for_each() macro, using two lists_Head type parameter, the first pointing to the current item moving continuously to the next element, and the second is the head of the chain table, which can only traverse list_head pointer, usually combined with list_The entry() macro gets the data structure to which it points.
struct list_head *p; // Chain List Nodes to Find struct fox *f; // Save the results of the search list_for_each(p, &fox_list) { // The p pointer moves in turn to the next item /* f points to the structure in which the list is embedded */ f = list_entry(p, struct fox, list); // Returns a pointer to the data structure containing p, f being the result of traversal } // Macro list_entry parameter: // `ptr` denotes the location of a member member member, and list is of course a member of that member // `type`struct type, // The name of a member of the `member` structure.
2. Available methods, common methods
Traversing through the list results in list_head type pointer, which is usually useless, requires the corresponding data structure of the node.Ready-made macro list_for_each_entry(pos, head, member), also using list_internallyEntry() macro implementation.
pos: The pointer to that data structure, which can be thought of as list_entry() return value
Head: chain head
Member: a member of a data structure such as a list
A small example:
struct fox *f; list_for_each_entry(f, &fox_list, list) { /* on each iteration, 'f' points to the next fox structure ... */ // f is the data structure corresponding to traversing the chain table nodes, but it seems that this traversal method is only suitable for chain tables that store the same type of data, which is not clear? }
3. Reverse traversal of chains
Reasons for existence: performance, reverse traversal may be faster when you know the approximate position of a node; stacks, which use a chain table to implement a stack, need to traverse from the tail forward.
list_for_each_entry_reverse(pos, head, member);
4. Delete while traversing
The standard traversal method is based on the premise that the list items are not changed.If you delete an item in standard traversal, you will not find a pointer to the next (or previous) node.Linux also provides operations that delete nodes during traversal, requiring a next pointer of the same type as pos.
pos: The pointer to that data structure, which can be thought of as list_entry() return value
next: temporarily saves the pointer of the current item to prevent deletion from finding the front and back pointers, the type is identical to pos
Head: chain head
Member: a member of a data structure such as a list
// Delete while traversing list_for_each_entry_safe(pos, next, head, member); // Delete when traversing backwards list_for_each_entry_safe_reverse(pos, n, head, member);
Note: Data needs to be protected and locked when deleting because deletions or operations may occur concurrently elsewhere.
2. Queues
There is no shortage of a programming model for any operating system core: producers and consumers.A simple way to do this is by queuing.
Producers produce data, consumers process data.
kfifo
kfifo is similar to other queues in that it has two main operations, enqueue and dequeue.
Maintain two offsets, in offset entry offset and out offset exit offset.The offset for the next inbound (outbound) queue.The exit offset is always less than or equal to the entry offset out offset <= in offset.
1. Create a queue
Dynamically create more common kfifo_alloc, creates and initializes a kfifo of size size size, which must be a power of 2, returns 0 successfully, and returns a negative error code unsuccessfully.
int kfifo_alloc(struct kfifo *fifo, unsigned int size, gfp_t gfp_mask);
2. Enter and leave the queue to peep
In: Copy the len byte data indicated by the from pointer into the fifo queue. Success returns the length of the successfully copied data. If the queue is idle less than len, the maximum length of the data will be copied. The return value may be less than len. Return 0 means no data has been copied.
Out: Copy len length data from fifo into to buffer, and success returns the length of the copied data.After queuing, the data is no longer in the queue.
Peep: Just look at the data, it's still in the queue.
// Entry unsigned int kfifo_in(struct kfifo *fifo, const void *from, unsigned int len); // Queue unsigned int kfifo_out(struct kfifo *fifo, void *to, unsigned int len); // Just peeking at the data unsigned int kfifo_out_peek(struct kfifo *fifo, void *to, unsigned int len, unsigned offset);
3. Get queue length, empty or full
Total size of kfifo queue space
static inline unsigned int kfifo_size(struct kfifo *fifo);
Size of existing kfifo data
static inline unsigned int kfifo_len(struct kfifo *fifo);
How much space does kfifio have
static inline unsigned int kfifo_avail(struct kfifo *fifo);
Empty or full
Empty or full returns a non-zero value and 0 instead.
static inline int kfifo_is_empty(struct kfifo *fifo); static inline int kfifo_is_full(struct kfifo *fifo);
Reset and Undo Queues
Resetting means discarding all existing queues.
static inline void kfifo_reset(struct kfifo *fifo);
Unuse kfifo_alloc() assigned queue, using kfifo_free().The method of release depends on the method of creation.
3. Mapping
Also known as an associative array, the key-to-value associations are maps.
Both hash and binary search trees can map.
Differences between hash and binary trees
- The hash table has relatively good average time complexity.Binary trees have better worst-case time complexity.
- The hash table can map different types of keys through the hash function.Binary trees have no hash and are more used for similar keys.
- The key s in the hash table are out of order after hash, making it easy to find points (linkedhashmap adds another pointer).Binary trees can be saved sequentially and are easy to find.
- hash shrinking takes time, while binary tree releases and expands in memory with unique advantages.
Mapping in Linux is a simple mapping data structure, not a common mapping.Map a unique number of identities (UIDs) to the pointer.The idr data structure is used to map the UID of the user space.
1. Initialize an idr
You can dynamically assign or statically define a data structure IDR data structure and then call idr_init() initialization.
struct idr id_huh; /* statically define idr structure */ idr_init(&id_huh); /* initialize provided idr structure */
2. Assign a new UID
It takes two steps: 1. Tell idr that you need to allocate a UID, and idr may need to resize (allocate memory without locks); 2. Request a new UID.
// 1. Adjust the backup tree size when needed and use gfp to identify it.Successful return 1, failure return 0, different from other kernel functions int idr_pre_get(struct idr *idp, gfp_t gfp_mask); // 2. Actually get the new UID, associate it with the ptr, and add it to the idr. // Return 0 on success and non-0 error code on error - EAGAIN indicates that idr_needs to be called againPre_Get(); // -ENOSPC indicates idr is full int idr_get_new(struct idr *idp, void *ptr, int *id); // Example: int id; do { if (!idr_pre_get(&idr_huh, GFP_KERNEL)) return -ENOSPC; ret = idr_get_new(&idr_huh, ptr, &id); } while (ret == -EAGAIN);
Find UID
To give the UID to the caller, the idr returns the corresponding pointer.Error returns null pointer.
void *idr_find(struct idr *idp, int id);
Delete UID
Remove the UID from the idr and remove the pointer associated with the id from the map together, but there is no way to prompt for any errors.
void idr_remove(struct idr *idp, int id);
Undo idr
Only memory unused by idr is released.
void idr_destroy(struct idr *idp);
4. Binary Tree
Tree structure is a hierarchical tree-based data structure.
Mathematically, a tree is a returnless, connected directed graph.
Binary Search Tree BST
A binary search tree is a binary tree with ordered nodes, and the order follows the following rules:
- The value of the left branch of the root is less than the value of the root node
- Right branch value is greater than root node value
- All subtrees are binary search trees
Searches for a given value (logarithm) to traverse the tree sequentially (linear).
Self-balanced Binary Search Tree
Balanced Binary Search Tree: A Binary Search Tree with a depth difference of not more than 1 for all leaf nodes.
Self-balanced binary tree: A binary search tree whose operations attempt to maintain (semi) balance.
1. Black and red trees
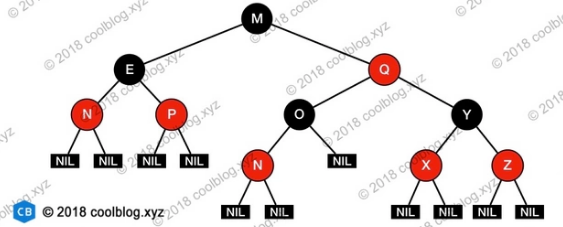
Excellent blogs: https://segmentfault.com/a/1190000012728513
Red-black trees are self-balanced binary search trees that maintain a semi-balanced structure and follow six attributes:
- Nodes are red or black
- Root is black
- All leaves are black (leaves are NIL nodes)
- Each red node must have two black children.(There cannot be two consecutive red nodes on all paths from each leaf to the root.)
- All simple paths from any node to each leaf contain the same number of black nodes (referred to as black heights)
With properties 4 and 5, it is guaranteed that the path from any node to each leaf node will not exceed twice the shortest path.Explain why the longest path from the root node to the leaf node cannot exceed twice the shortest path: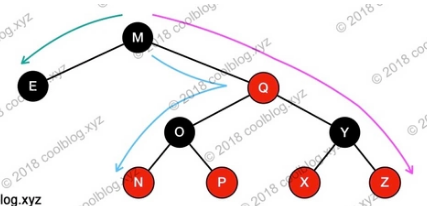
Article 4 A red node must have two children (a red node cannot be a child or parent of another red node).
Article 5. All simple paths from any node to each leaf contain the same number of black nodes.
These two guarantees that the longest path in the tree must be alternating red and black, and the shortest path is all black, so the longest path is not more than twice the shortest path.
The insertion efficiency of red-black trees is logarithmic to the number of nodes in the tree.
rbtree
The red-black tree in Linux is rbtree, and the root node is rb_Root data structure description, create a red-black tree, and initialize RB_with special valuesROOT:
struct rb_root root = RB_ROOT;
Other nodes in the tree are represented by rb_node description.The implementation of rbtree does not provide search and insert routines, which need to be defined by the user, because C is not easy for generic programming, and the most effective search and insert requires the user to implement them.
Data structure and selection
1. Chain List
- The main operation above on the data structure is traversal, and there is no better algorithm to traverse using a chain table than linear complexity.
- Chain lists are also preferred when performance is not a top concern, less data is stored, and code interaction with other chained lists in the kernel is required.
- Stores data collections of unknown size that can be dynamically added.
2. Queues
- Queues can be used when matching producer/consumer
- Fixed-length buffer required
3. Mapping
- Map a UID to an object, and Linux is a UID to pointer mapping.
4. Black and Red Trees
- Storing large amounts of data and requiring fast retrieval, red and black trees guarantee logarithmic search time complexity and linear traversal time complexity.
The kernel also implements cardinality (trie) and bitmaps
Algorithmic Complexity (Scalability)
It is common to study the asymptotic behavior of an algorithm, which refers to the behavior of an algorithm when its input is infinite.