KubeCube (https://kubecube.io ) is a lightweight enterprise container platform recently opened by NetEase Sail, which provides enterprises with the functions of visual management of kubernetes resources and unified multi-cluster and multi-tenant management. The KubeCube community will help developers and users understand and get started with KubeCube more quickly by reading a series of technical articles about its design features and technical implementation. This is the third in-depth explanation of KubeCube's multi-cluster capability.

Why do you need multiple clusters?
- Production-level landings require multiple environmental validations, and individual clusters often do not meet isolation requirements
- When the business size exceeds the capacity of a single cluster
- When an enterprise considers using a cloudy or hybrid Cloud Architecture
- When architecting scenarios such as cloud disaster tolerance, live in different places, etc.
Current status of K8s multi-cluster management
Multi-cluster management is not a primary goal of the K8s community. Although the community proposed the mcs multi-cluster service standard, it still cannot meet the needs of enterprises to manage multi-cluster. If K8s is only used for multi-cluster construction, K8s managers often need to manage a large number of configuration files for different K8s clusters, need to manage authentication and privilege information for different users, and need a lot of manual intervention for the publishing and maintenance of multi-cluster applications. Configuration management confusion and malfunction due to improper operation can easily occur.
KubeCube multi-cluster capability
KubeCube can host any standard Kubernetes cluster, providing unified user management and access control based on the native RBAC extensions of Kubernetes for all Kubernetes clusters it takes over. To improve the efficiency of users managing multiple Kubernetes clusters, KubeCube provides an online maintenance tool that allows users to quickly manage multiple cluster resources through the unified entry of KubeCube: CloudShell can use kubectl for each cluster online, and WebConsole can access Pod s in each cluster online.
In addition, KubeCube controls network jitter and anomalies between clusters and business clusters in mixed cloud scenarios. We provide the capability of business cluster autonomy. When the business cluster is disconnected from the KubeCube control cluster, the access control of the business cluster can take effect normally and will not be affected.
KubeCube's Multi-Cluster Model
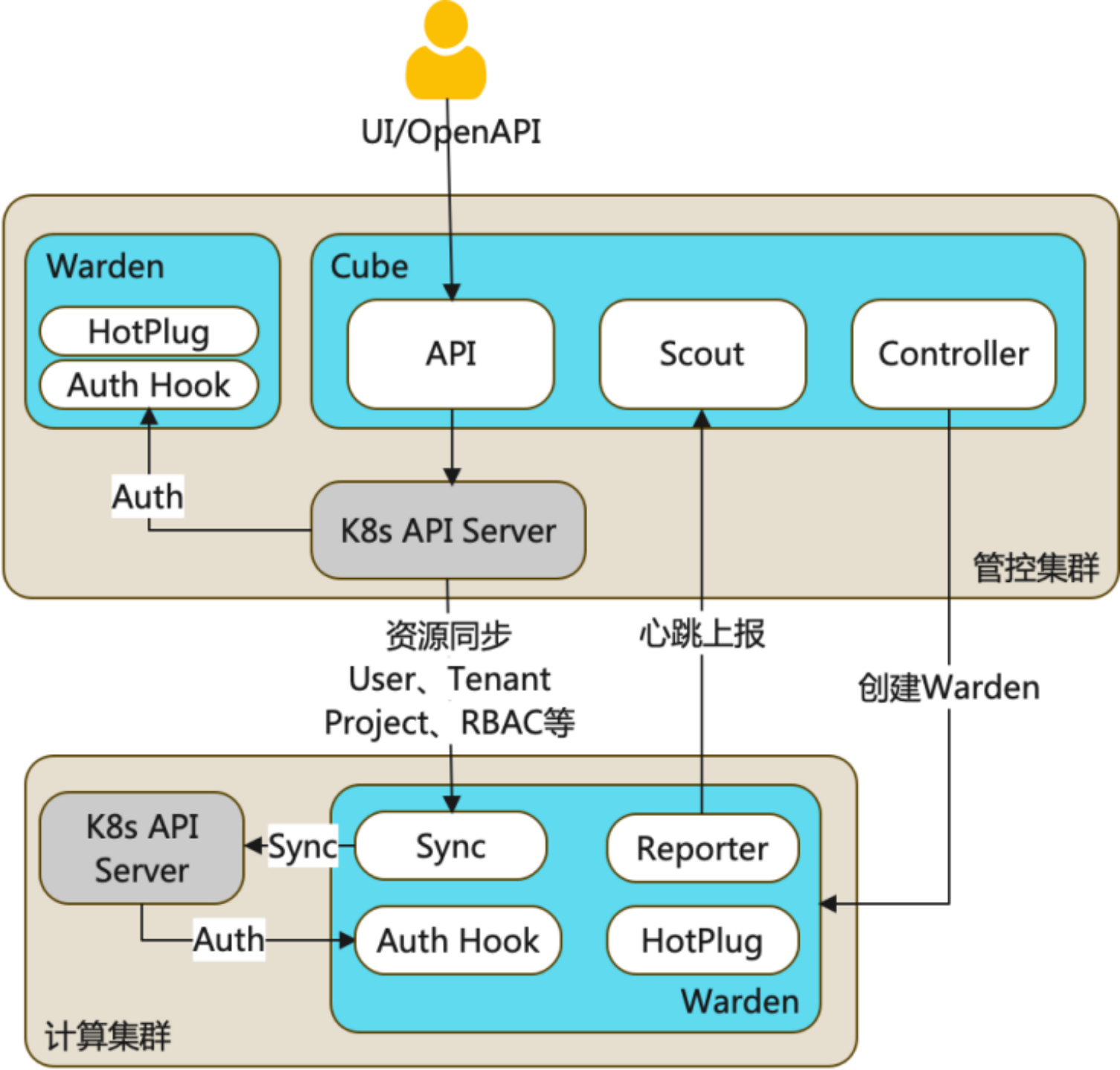 Based on the multi-cluster model, KubeCube achieves multi-cluster management capabilities, multi-cluster unified authentication and authentication capabilities, multi-cluster and multi-tenant management capabilities, and multi-cluster fault tolerance capabilities. Understanding the multi-cluster model can help you understand KubeCube more deeply. The design of each multi-cluster module in KubeCube and Warden is explored below.
Based on the multi-cluster model, KubeCube achieves multi-cluster management capabilities, multi-cluster unified authentication and authentication capabilities, multi-cluster and multi-tenant management capabilities, and multi-cluster fault tolerance capabilities. Understanding the multi-cluster model can help you understand KubeCube more deeply. The design of each multi-cluster module in KubeCube and Warden is explored below.
Multiple Cluster Modules in KubeCube
KubeCube is the core component on a control cluster, which implements life cycle management for multiple clusters and acts as an operational gateway to the UI/openAPI. To understand the multi-cluster module in KubeCube, we need to focus on the following topic s:
- Relationship between cluster cr and InternalCluster
- How multi-cluster-manager manages InternalCluster
- Process of cluster reconcile
- How scout detects and calculates the heartbeat of a cluster
Multi-Cluster-Manager--Multi-Cluster Manager
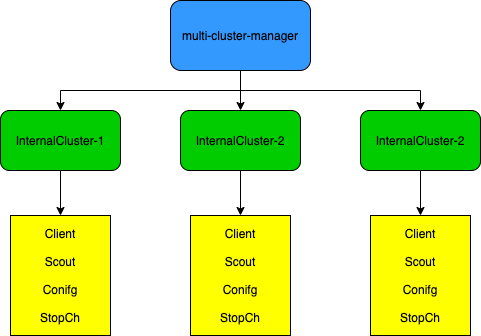
Multi-Cluster Manager is essentially the management of InternalCluster, and the interface contains the methods required to operate InternalCluster.
// MultiClustersManager access to internal cluster
type MultiClustersManager interface {
// Add runtime cache in memory
Add(cluster string, internalCluster *InternalCluster) error
Get(cluster string) (*InternalCluster, error)
Del(cluster string) error
// FuzzyCopy return fuzzy cluster of raw
FuzzyCopy() map[string]*FuzzyCluster
// ScoutFor scout heartbeat for warden
ScoutFor(ctx context.Context, cluster string) error
// GetClient get client for cluster
GetClient(cluster string) (kubernetes.Client, error)
}
InternalCluster is a runtime mapping of a real Clustercr, which represents a cluster managed by KubeCube.
InternalCluster contains four fields:
- Client contains all the k8s client s needed to communicate with a specified cluster, including clientset in sig/client-go, client.Client and cache.Cache in sig/controller-manager, and clientset in k8s.io/metric s. Through Client, we can communicate k8s-apiserver of different k8s clusters in various postures, which is also the basis for achieving multiple clusters.
type Client interface {
Cache() cache.Cache
Direct() client.Client
Metrics() versioned.Interface
ClientSet() kubernetes.Interface
}
- Scout is a scout that detects the health of a given cluster and is detailed below
- Config is the rest.Config required to communicate with the specified cluster, converted from KubeConfig in Clustercr
- StopCh is used to turn off Scout's investigation of a specified cluster and stop all informer behavior associated with that cluster
Scout -- Compute Cluster Investigator
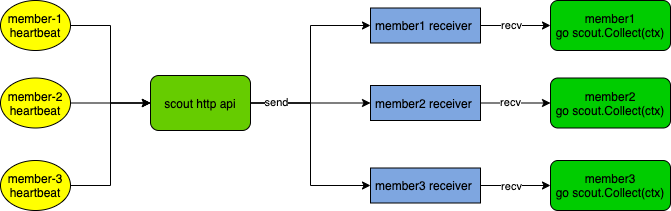
The scout's duty is to investigate the health of the specified cluster. It provides an http interface to receive heartbeats from different clusters, then sends the heartbeat package to the corresponding scout's Receiver channel. Inside, a goroutine loop receives the heartbeat package from the Receiver channel and does different callback processing depending on the health and timeout conditions.
// Collect will scout a specified warden of cluster
func (s *Scout) Collect(ctx context.Context) {
for {
select {
case info := <-s.Receiver:
s.healthWarden(ctx, info)
case <-time.Tick(time.Duration(s.WaitTimeoutSeconds) * time.Second):
s.illWarden(ctx)
case <-ctx.Done():
clog.Warn("scout of %v warden stopped: %v", s.Cluster, ctx.Err())
return
}
}
}
Cluster-Controller--Cluster cr Controller
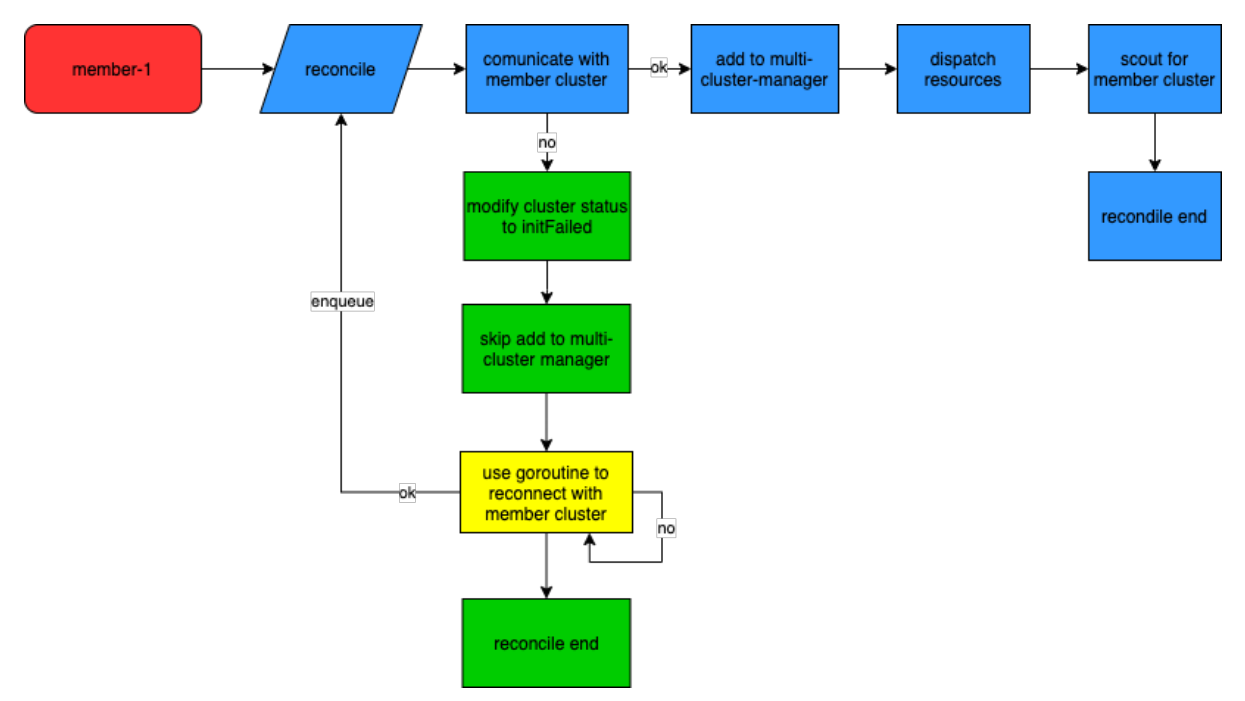
Cluster's controller s are primarily responsible for perceiving cluster changes for KubeCube nanotubes and initializing settings related to computing clusters:
- create event from watch to new cluster cr
- Try to use meta-information in cluster cr to communicate apiserver corresponding to k8s cluster
- If Federation with the corresponding k8s cluster fails, the event will be queued for retry (see Multi-Cluster Fault Tolerance below)
- Once the k8s cluster is successfully federated, the corresponding InternalCluster is created and added to the MultiClusters Manager-managed cache
- deployment of warden under the corresponding cluster and some necessary crd resources
- Create a scout for the cluster and start investigation of the cluster
Multiple Cluster Modules in Warden
Warden exists in each computing cluster as a cluster agent. It provides the capability of resource synchronization, hot plugging, unified authentication, resource configuration management, heartbeat reporting, etc. between computing cluster and control cluster. To understand the multi-cluster module in warden, we need to focus on the following topic s:
- How warden reports heartbeat information to the control cluster
- How warden synchronizes resources from a managed cluster
Reporter -- Cluster Information Reporter
Warden's reporter corresponds to KubeCube's scout inspector one-to-one, far-reaching.
Warden needs to check the health status of each module according to the registered health check method at startup until each module on which it depends has reached a healthy state before it can start reporting a heartbeat to the control cluster. If the health check times out, warden will fail to start.
// waitForReady wait all components of warden ready
func (r *Reporter) waitForReady() error {
counts := len(checkFuncs)
if counts < 1 {
return fmt.Errorf("less 1 components to check ready")
}
// wait all components ready in specified time
ctx, cancel := context.WithTimeout(context.Background(), time.Duration(r.WaitSecond)*time.Second)
defer cancel()
readyzCh := make(chan struct{})
for _, fn := range checkFuncs {
go readyzCheck(ctx, readyzCh, fn)
}
for {
select {
case <-ctx.Done():
return ctx.Err()
case <-readyzCh:
counts--
if counts < 1 {
return nil
}
}
}
}
Warden provides access to health checks for all its modules, and all modules that affect the normal functioning of warden need to register the health check function through the RegisterCheckFunc method to ensure that warden starts properly.
var checkFuncs []checkFunc
// RegisterCheckFunc should be used to register readyz check func
func RegisterCheckFunc(fn checkFunc) {
checkFuncs = append(checkFuncs, fn)
}
func readyzCheck(ctx context.Context, ch chan struct{}, checkFn checkFunc) {
for {
select {
case <-time.Tick(waitPeriod):
if checkFn() {
ch <- struct{}{}
return
}
case <-ctx.Done():
return
}
}
}
After completing the health checks for each module, warden is ready to start, reports a heartbeat containing cluster information to the control cluster, and triggers the corresponding function fallback based on the communication with the control cluster. The corresponding scout in KubeCube will be processed accordingly based on the reported information received.
// report do real report loop
func (r *Reporter) report(stop <-chan struct{}) {
for {
select {
case <-time.Tick(time.Duration(r.PeriodSecond) * time.Second):
if !r.do() {
r.illPivotCluster()
} else {
r.healPivotCluster()
}
case <-stop:
return
}
}
}
Sync-Manager--Cluster Resource Synchronizer
Sync-Manager implements the ability to synchronize resources from a control cluster to a computing cluster, which is also the basis for achieving unified authentication and authentication capabilities for multiple clusters.
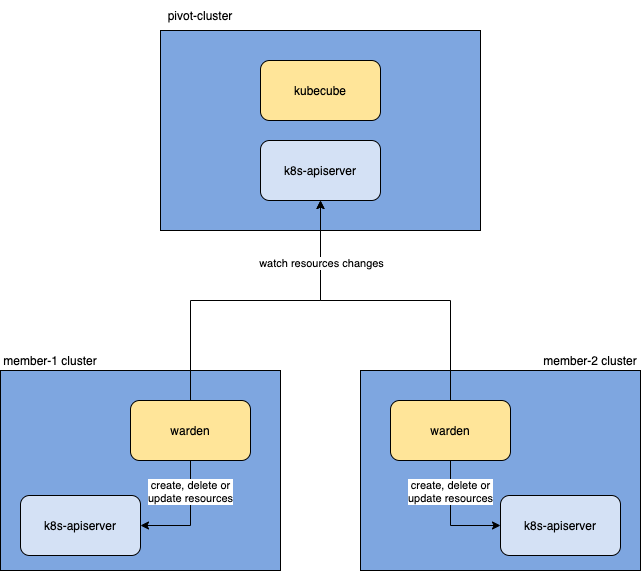
Multiple Cluster Fault Tolerance
It is undeniable that in the real world, multi-K8s clusters may have cross-cluster communication failures, sometimes due to network failures between clusters, sometimes due to K8s failures of a certain cluster, which in general will make cross-cluster access unavailable. For KubeCube, there are currently two main concerns:
-
member cluster is disconnected when KubeCube runs
-
member cluster was disconnected when KubeCube started
For the two cases mentioned above, KubeCube handled in middleware of cluster-controller, scout and kubecube-apiserver respectively.
Cluster-Controller
We mentioned the reconcile logic of the cluster-controller above, knowing that when we initialize a cluster to take care of it, we put the cluster with communication failures in the retry queue and update the state of the cluster cr to initFailed.
// generate internal cluster for current cluster and add
// it to the cache of multi cluster manager
skip, err := multiclustermgr.AddInternalCluster(currentCluster)
if err != nil {
log.Error(err.Error())
}
if err != nil && !skip {
updateFn := func(cluster *clusterv1.Cluster) {
initFailedState := clusterv1.ClusterInitFailed
reason := fmt.Sprintf("cluster %s init failed", cluster.Name)
cluster.Status.State = &initFailedState
cluster.Status.Reason = reason
}
err := utils.UpdateStatus(ctx, r.Client, ¤tCluster, updateFn)
if err != nil {
log.Error("update cluster %v status failed", currentCluster.Name)
return ctrl.Result{}, err
}
r.enqueue(currentCluster)
return ctrl.Result{}, nil
}
Clusters that fail to initialize retry the reconcile periodically in a separate goroutine and reconcile the successfully reconnected cluster through the GenericEvent of K8s, removing the retry task from the retry queue. Retry timeout defaults to 12 hours with a retry interval of 7 seconds.
// try to reconnect with cluster api server, requeue if every is ok
go func() {
log.Info("cluster %v init failed, keep retry background", cluster.Name)
// pop from retry queue when reconnected or context exceed or context canceled
defer r.retryQueue.Delete(cluster.Name)
for {
select {
case <-time.Tick(retryInterval):
_, err := client.New(config, client.Options{Scheme: r.Scheme})
if err == nil {
log.Info("enqueuing cluster %v for reconciliation", cluster.Name)
r.Affected <- event.GenericEvent{Object: &cluster}
return
}
case <-ctx.Done():
log.Info("cluster %v retry task stopped: %v", cluster.Name, ctx.Err())
// retrying timeout need update status
// todo(weilaaa): to allow user reconnect cluster manually
if ctx.Err().Error() == "context deadline exceeded" {
updateFn := func(cluster *clusterv1.Cluster) {
state := clusterv1.ClusterReconnectedFailed
reason := fmt.Sprintf("cluster %s reconnect timeout: %v", cluster.Name, retryTimeout)
cluster.Status.State = &state
cluster.Status.Reason = reason
}
err := utils.UpdateStatus(ctx, r.Client, &cluster, updateFn)
if err != nil {
log.Warn("update cluster %v status failed: %v", cluster.Name, err)
}
}
return
}
}
}()
Of course, when the user actively deletes the cluster cr, the controller calls the cancel method of the context to stop the retry task for the cluster and remove it from the retry queue. The ability of users to trigger retry connections manually will be supported in the future.
// stop retry task if cluster in retry queue
cancel, ok := r.retryQueue.Load(cluster.Name)
if ok {
cancel.(context.CancelFunc)()
clog.Debug("stop retry task of cluster %v success", cluster.Name)
return nil
}
Scout
Scout, as the scout for the computing cluster, updates the status of the corresponding cluster cr to cluster Abnormal when it senses that the member cluster is disconnected and informs multiClusterManger of the unusual state of the cluster.
if !isDisconnected(cluster, s.WaitTimeoutSeconds) {
// going here means cluster heartbeat is normal
if s.ClusterState != v1.ClusterNormal {
clog.Info("cluster %v connected", cluster.Name)
}
s.LastHeartbeat = cluster.Status.LastHeartbeat.Time
s.ClusterState = v1.ClusterNormal
return
}
if s.ClusterState == v1.ClusterNormal {
reason := fmt.Sprintf("cluster %s disconnected", s.Cluster)
updateFn := func(obj *v1.Cluster) {
state := v1.ClusterAbnormal
obj.Status.State = &state
obj.Status.Reason = reason
obj.Status.LastHeartbeat = &metav1.Time{Time: s.LastHeartbeat}
}
clog.Warn("%v, last heartbeat: %v", reason, s.LastHeartbeat)
err := utils.UpdateStatus(ctx, s.Client, cluster, updateFn)
if err != nil {
clog.Error(err.Error())
}
}
s.ClusterState = v1.ClusterAbnormal
When Scout senses that the member cluster has reported a heartbeat again and restored the connection, it updates the status of the corresponding cluster cr to normal and tells the multiClusterManger that the cluster is back to normal.
if s.ClusterState != v1.ClusterNormal {
clog.Info("cluster %v connected", cluster.Name)
}
s.LastHeartbeat = time.Now()
updateFn := func(obj *v1.Cluster) {
state := v1.ClusterNormal
obj.Status.State = &state
obj.Status.Reason = fmt.Sprintf("receive heartbeat from cluster %s", s.Cluster)
obj.Status.LastHeartbeat = &metav1.Time{Time: s.LastHeartbeat}
}
err = utils.UpdateStatus(ctx, s.Client, cluster, updateFn)
if err != nil {
clog.Error(err.Error())
return
}
s.ClusterState = v1.ClusterNormal
KubeCube-Apiserver-Middlewares
As a preprocessor for http server, it provides the ability to pre-check cluster state. When you want to access a cluster's resources through KubeCube, it asks the multiClusterManager about the state of the cluster and fails quickly if the corresponding cluster is unhealthy.
// PreCheck do cluster health check, early return
// if cluster if unhealthy
func PreCheck() gin.HandlerFunc {
return func(c *gin.Context) {
cluster := fetchCluster(c)
clog.Debug("request path: %v, request cluster: %v", c.FullPath(), cluster)
if len(cluster) > 0 {
_, err := multicluster.Interface().Get(cluster)
if err != nil {
clog.Warn("cluster %v unhealthy, err: %v", cluster, err.Error())
response.FailReturn(c, errcode.CustomReturn(http.StatusInternalServerError, "cluster %v unhealthy", cluster))
return
}
}
}
}
Unified authentication and authentication capabilities for multiple clusters
KubeCube's authentication and authentication capabilities are based on K8s'native RBAC, but KubeCube's multi-cluster unified authentication and authentication capabilities are expanded on it.
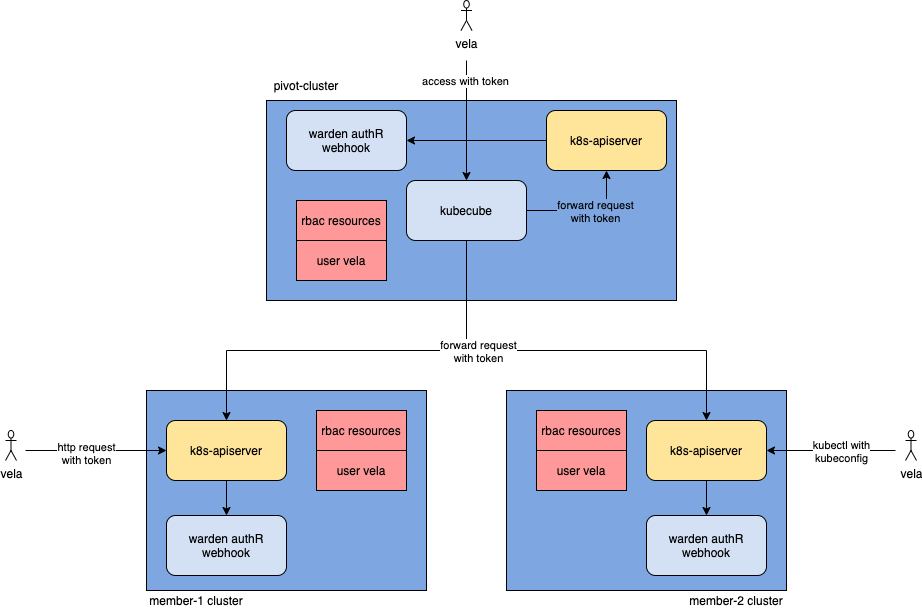
Permission Rule Synchronization
To achieve the same authentication and authentication results for the same user in different clusters, you need to ensure that the permission rules are the same across different clusters
- When a new user is created, KubeCube creates the corresponding user cr for it, which is the subject body in roleBinding
- When a Cluster Administrator assigns a role to a new user, KubeCube creates the corresponding RBAC rule for that user
- Warden's Resource Synchronization Manager synchronizes user cr and RBAC rules from the governing cluster to the computing cluster
User Access
KubeCube supports flexible user access, including access to K8s through the front-end of KubeCube, access to K8s through kubectl, and access to K8s directly using rest-ful l, essentially using the token corresponding to user to access K8s.
-
KubeCube generates a composite jwt standard token for each user, which allows the user to get the resulting KubeConfig by which the front end interacts with KubeCube
-
When carrying token to request k8s-apiserver, k8s-apiserver accesses warden's authR webhook api based on the authentication-token-webhook-config-file we configured in its startup parameters previously: "/etc/cube/warden/webhook.config" parameter and obtains authentication results, such as token:xxx holding vela, after accessing warden's authentication service, Get Vela this user
-
k8s-apiserver then uses vela user and matching rbac rules as authentication
Architecturally, even if KubeCube fails, only warden is functioning properly, users can still access the corresponding K8s resources through unified K8s authentication and authentication in the way of kubectl and rest-ful l.
summary
The implementation of KubeCube's multi-cluster model relies on the complementarity of KubeCube and Warden, providing unified authentication, authentication, and multi-tenant management capabilities for multiple clusters in use, fault tolerance for multiple clusters, and autonomy for a single cluster in failure handling.
Write at the end
In the future, we will continue to provide more functions to help enterprises simplify container landing. You are also welcome to add the following WeChat to the KubeCube Exchange Group.

Author's introduction: Cai Xintao, NetEase Sailing and Light Boat Container Platform Development, KubeCube Committer
Related articles:
KubeCube Open Source: Six features to simplify Kubernetes landing
KubeCube multilevel tenant model
KubeCube home page: https://www.kubecube.io