| Syllabus | Course content | learning effect | Master the goal |
| FlinkSQL | FlinkTable | master | |
| FlinkSQL | master | ||
| FlinkCEP | FlinkCEP | master | |
| Task performance optimization | operator chain | master | |
| slot sharing | master | ||
| Flink asynchronous IO | master | ||
| Checkpoint optimization | master |
1, Table & SQL
(1) Overview
Table API is a general relational API for stream processing and batch processing. Table API can run based on stream input or batch input without any modification. Table API is a superset of SQL language and specially designed for Apache Flink. Table API is an integrated API of scala and java languages. Different from specifying the query as a string in conventional SQL language, table API query is defined in the language embedding style in Java or Scala, and has IDE support, such as automatic completion and syntax detection; Queries that allow you to combine relational operators in a very intuitive way, such as select, filter, and join. Flink SQL support is based on Apache compute, which implements the SQL standard. Whether the input is a DataSet or a DataStream, the query specified in any interface has the same semantics and specifies the same result.
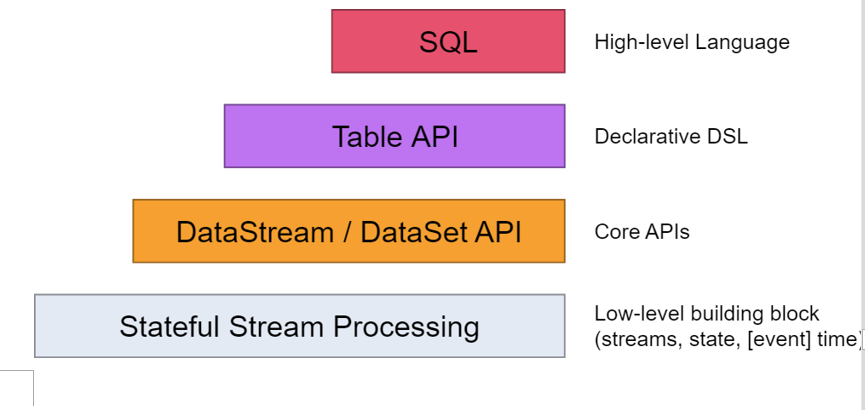
(2) , Table API
1. Rely on
<!-- flink-table&sql -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table</artifactId>
<version>1.9.1</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.9.1</version>
</dependency>
2,Table API
(1),TableEnvironment
TableEnvironment is the core concept of Table API and SQL integration. It is responsible for:
- Registry in internal directory
- Register external directory
- Execute SQL query
- Register user-defined functions
- Convert DataStream or DataSet to Table
- Holds a reference to the ExecutionEnvironment or StreamExecutionEnvironment
A Table is always bound to a specific TableEnvironment. You cannot combine tables of different TableEnvironments (for example, union or join) in the same query. Create TableEnvironment:
// Flow based tableEnv val sEnv = StreamExecutionEnvironment.getExecutionEnvironment // create a TableEnvironment for streaming queries val sTableEnv = StreamTableEnvironment.create(sEnv) // Batch based bTableEnv val bEnv: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment val bTableEnv: BatchTableEnvironment = BatchTableEnvironment.create(bEnv)
(2) . data loading
There are usually two kinds of data loading: one is based on stream / batch, and the other is based on TableSource. However, the latter has been abandoned in Flink1.11, so it is not recommended to use it.
Batch based
case class Student(id:Int,name:String,age:Int,gender:String,course:String,score:Int)
object FlinkBatchTableOps {
def main(args: Array[String]): Unit = {
//Build the executionEnvironment of batch
val env = ExecutionEnvironment.getExecutionEnvironment
val bTEnv = BatchTableEnvironment.create(env)
val dataSets: DataSet[Student] = env.readCsvFile[Student]("E:\\data\\student.csv",
//Whether to ignore the data in the first line of the file (mainly considering the header data)
ignoreFirstLine = true,
//Separator between fields
fieldDelimiter = "|")
//table is equivalent to dataset in sparksql
val table: Table = bTEnv.fromDataSet(dataSets)
//Condition query
val result: Table = table.select("name,age").where("age=25")
//Printout
bTEnv.toDataSet[Row](result).print()
}
}
Data:
Flow based
case class Goods(id: Int,brand:String,category:String)
object FlinkStreamTableOps {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val sTEnv = StreamTableEnvironment.create(env)
val dataStream: DataStream[Goods] = env.fromElements(
"001|mi|mobile",
"002|mi|mobile",
"003|mi|mobile",
"004|mi|mobile",
"005|huawei|mobile",
"006|huawei|mobile",
"007|huawei|mobile",
"008|Oppo|mobile",
"009|Oppo|mobile",
"010|uniqlo|clothing",
"011|uniqlo|clothing",
"012|uniqlo|clothing",
"013|uniqlo|clothing",
"014|uniqlo|clothing",
"015|selected|clothing",
"016|selected|clothing",
"017|selected|clothing",
"018|Armani|clothing",
"019|lining|sports",
"020|nike|sports",
"021|adidas|sports",
"022|nike|sports",
"023|anta|sports",
"024|lining|sports"
).map(line => {
val fields = line.split("\\|")
Goods(fields(0), fields(1), fields(2))
})
//load data from external system
var table = sTEnv.fromDataStream(dataStream)
// stream table api
table.printSchema()
// Operation of high-order api
table = table.select("category").distinct()
/*
When converting a table into a DataStream, there are two options
toAppendStream : Used when there is no aggregation operation
toRetractStream(Scaling (meaning): used after aggregation
*/
sTEnv.toRetractStream[Row](table).print()
env.execute("FlinkStreamTableOps")
}
}
(3),sqlQuery
sql is still the main analysis tool. Of course, using dsl can also complete business analysis, but it is less flexible and simple than sql. FlinkTable uses sqlQuery to complete sql query operations.
case class Goods(id: Int,brand:String,category:String)
object FlinkSQLOps {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val sTEnv = BatchTableEnvironment.create(env)
val dataStream: DataSet[Goods] = env.fromElements(
"001|mi|mobile",
"002|mi|mobile",
"003|mi|mobile",
"004|mi|mobile",
"005|huawei|mobile",
"006|huawei|mobile",
"007|huawei|mobile",
"008|Oppo|mobile",
"009|Oppo|mobile",
"010|uniqlo|clothing",
"011|uniqlo|clothing",
"012|uniqlo|clothing",
"013|uniqlo|clothing",
"014|uniqlo|clothing",
"015|selected|clothing",
"016|selected|clothing",
"017|selected|clothing",
"018|Armani|clothing",
"019|lining|sports",
"020|nike|sports",
"021|adidas|sports",
"022|nike|sports",
"023|anta|sports",
"024|lining|sports"
).map(line => {
val fields = line.split("\\|")
Goods(fields(0), fields(1), fields(2))
})
//load data from external system
sTEnv.registerTable("goods", dataStream)
//sql operation
var sql =
"""
|select
| id,
| brand,
| category
|from goods
|""".stripMargin
sql =
"""
|select
| category,
| count(1) counts
|from goods
|group by category
|order by counts desc
|""".stripMargin
table = sTEnv.sqlQuery(sql)
sTEnv.toDataSet[Row](table).print()
}
}
(4) . Table operation based on scrolling window
Scrolling window operation based on EventTIme
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.Table
import org.apache.flink.types.Row
//Table operation based on scrolling window
object FlinkTrumblingWindowTableOps {
def main(args: Array[String]): Unit = {
//1. Get streaming execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
// 2. Get table execution environment
val tblEnv = StreamTableEnvironment.create(env)
//3. Get data source
//input data:
val ds = env.socketTextStream("node01", 9999)
.map(line => {
val fields = line.split("\t")
UserLogin(fields(0), fields(1), fields(2), fields(3).toInt,
fields(4))
})
.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[UserLogin](Time.seconds(2)) {
override def extractTimestamp(userLogin: UserLogin): Long = {
userLogin.dataUnix * 1000
}
}
)
//4. Convert DataStream to table
//Introduce implicit
//Number of input records every 2 seconds on a day:
import org.apache.flink.table.api.scala._
val table: Table = tblEnv.fromDataStream[UserLogin](ds , 'platform, 'server, 'status, 'ts.rowtime)
// tblEnv.toAppendStream[Row](table).print()
tblEnv.sqlQuery(
s"""
|select
|platform,
|count(1) counts
|from ${table}
|where status = 'LOGIN'
|group by platform, tumble(ts,interval '2' second)
|""".stripMargin)
.toAppendStream[Row]
.print("Log in users on different platforms every 2 seconds->")
env.execute()
}
}
/** User login
*
* @param platform Platform id (e.g. H5/IOS/ADR/IOS_YY)
* @param server Game service id
* @param uid User unique id
* @param dataUnix Event time / s timestamp
* @param status Login action (LOGIN/LOGOUT)
*/
case class UserLogin(platform: String, server: String, uid: String, dataUnix: Int, status: String)
Data:

Window based processTime
object FlinkTrumblingWindowTableOps2 {
def main(args: Array[String]): Unit = {
//1. Get streaming execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 2. Get table execution environment
val tblEnv = StreamTableEnvironment.create(env)
//3. Get data source
//input data:
val ds = env.socketTextStream("node01", 9999)
.map(line => {
val fields = line.split("\t")
UserLogin(fields(0), fields(1), fields(2), fields(3).toInt, fields(4))
})
//4. Convert DataStream to table
//Introduce implicit
//Number of input records every 2 seconds on a day:
import org.apache.flink.table.api.scala._
val table: Table = tblEnv.fromDataStream[UserLogin](ds , 'platform, 'server, 'status, 'ts.proctime)
// tblEnv.toAppendStream[Row](table).print()
tblEnv.sqlQuery(
s"""
|select
| platform,
| count(1) counts
|from ${table}
|where status = 'LOGIN'
|group by platform, tumble(ts,interval '2' second)
|""".stripMargin)
.toAppendStream[Row]
.print("prcotime-Log in users on different platforms every 2 seconds->")
env.execute()
}
}
(3) , Flink Table UDF
1,UDF
(1) . description
User defined scalar function. One line input and one line output.
(2) , data
// A user browses a product and its value at a certain time
{"userID": 2, "eventTime": "2020-10-01 10:02:00", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:02", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:10", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:12", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:15", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:16", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}(3) . demand
UDF time conversion
UDF needs to inherit the 'ScalarFunction' abstract class and mainly implement the eval method.
Customize UDF to convert eventTime into timestamp
(4) , implementation
object FlinkTableUDFOps {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val bTEnv = BatchTableEnvironment.create(env)
val ds = env.fromElements(
).map(line => {
val jsonObj = JSON.parseObject(line)
val userID = jsonObj.getInteger("userID")
val eventTime = jsonObj.getString("eventTime")
val eventType = jsonObj.getString("eventType")
val productID = jsonObj.getString("productID")
val productPrice = jsonObj.getDouble("productPrice")
UserBrowseLog(userID, eventTime, eventType, productID, productPrice)
})
//Custom udf
bTEnv.registerFunction("to_time", new TimeScalarFunction())
bTEnv.registerFunction("myLen", new LenScalarFunction())
val table = bTEnv.fromDataSet(ds)
val sql =
s"""
|select
| userID,
| eventTime,
| myLen(eventTime) my_len_et,
| to_time(eventTime) timestamps
|from ${table}
|""".stripMargin
val ret = bTEnv.sqlQuery(sql)
bTEnv.toDataSet[Row](ret).print
}
}
case class UserBrowseLog(
userID: Int,
eventTime: String,
eventType: String,
productID: String,
productPrice: Double
)
/*
Customize the class to extend ScalarFunction and copy its method: eval
at least one method named 'eval' which is public, not
*/
class TimeScalarFunction extends ScalarFunction {
//2020-10-01 10:02:16
private val df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
def eval(eventTime: String): Long = {
df.parse(eventTime).getTime
}
}
class LenScalarFunction extends ScalarFunction {
//2020-10-01 10:02:16
def eval(str: String): Int = {
str.length
}
}
2, CEP
(1) What is complex event processing CEP
One or more event streams composed of simple events match through certain rules, and then output the data users want to get, which is a complex event that meets the rules.
features:
Objective: to find some high-order features from ordered simple event flow
Input: one or more event flows consisting of simple events
Handling: identify the internal relationship between simple events, and multiple simple events conforming to certain rules constitute complex events
Output: complex events satisfying rules
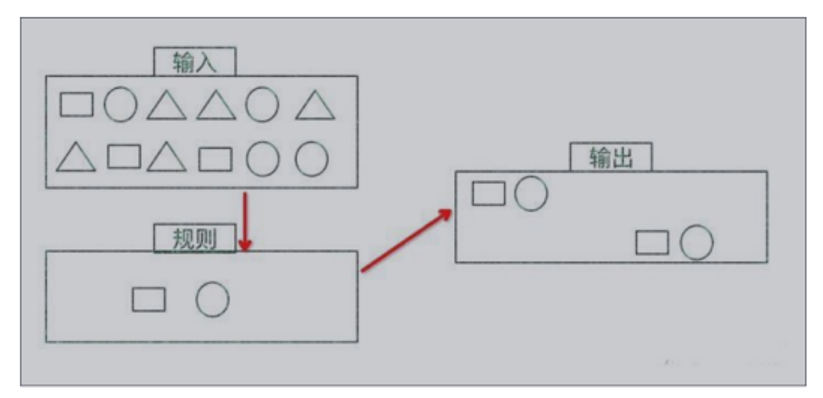
CEP is used to analyze low latency and frequently generated event flows from different sources. CEP can help to find meaningful patterns and complex relationships in complex and irrelevant event flows, so as to obtain notifications and prevent some behaviors in near real-time or quasi real-time.
CEP supports pattern matching on streams, which can be divided into continuous conditions or discontinuous conditions according to different conditions of patterns; The conditions of the pattern allow time constraints. When the conditions are not met within the condition range, the pattern matching timeout will be caused.
It looks simple, but it has many different functions:
Input stream data to produce results as soon as possible
On two event streams, aggregate classes are calculated based on time
Provide real-time / quasi real-time warnings and notifications
Generate associations and analyze patterns in a variety of data sources
High throughput and low latency processing
There are many CEP solutions in the market, such as Spark, Samza, Beam, etc., but they do not provide special library support. However, Flink provides a dedicated CEP library.
(2) , Flink CEP
1. Component description
Flink provides a special Flink CEP library for CEP, which includes the following components:
- Event Stream
- pattern definition
- pattern detection
- Generate Alert
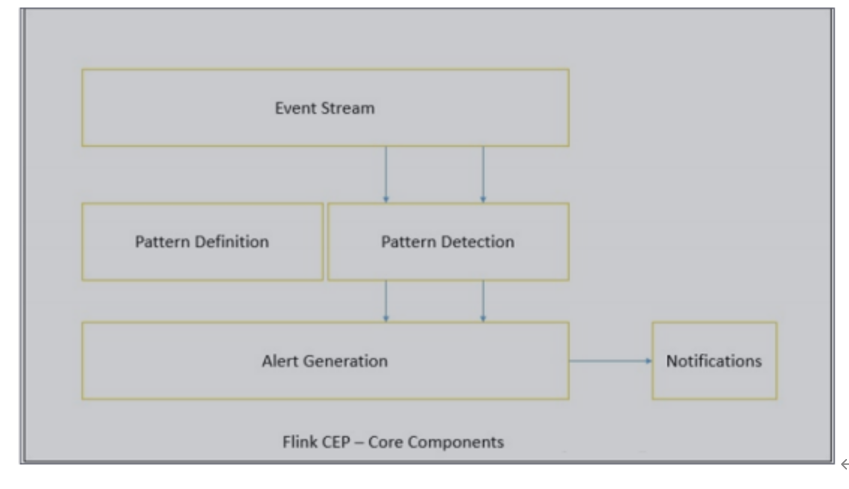
First, the developer should define the mode conditions on the DataStream stream, and then the Flink CEP engine will detect the mode and generate an alarm if necessary.
In order to use Flink CEP, we need to import dependencies:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep-scala_2.11</artifactId>
<version>1.9.1</version>
</dependency>
2. CEP coding process
Event Streams
Take the login event flow as an example:
case class LoginEvent(userId: String, ip: String, eventType: String, eventTime: String)
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val loginEventStream = env.fromCollection(List(
LoginEvent("1", "192.168.0.1", "fail", "1558430842"),
LoginEvent("1", "192.168.0.2", "fail", "1558430843"),
LoginEvent("1", "192.168.0.3", "fail", "1558430844"),
LoginEvent("2", "192.168.10.10", "success", "1558430845")))
.assignAscendingTimestamps(_.eventTime.toLong)
Pattern API
Each Pattern should contain several steps, or state. From one state to another, we usually need to define some conditions, such as the following code:
val loginFailPattern = Pattern.begin[LoginEvent]("begin")
.where(_.eventType.equals("fail"))
.next("next")
.where(_.eventType.equals("fail"))
.within(Time.seconds(10))
Each state should have a flag: for example, "begin" in. begin[LoginEvent]("begin").
Each state needs to have a unique name and a filter to filter the conditions that the event needs to meet, such as:
.where(_.eventType.equals("fail"))
We can also restrict the subtype of event through subtype:
start.subtype(SubEvent.class).where(...);
In fact, you can call the subtype and where methods multiple times; Moreover, if the where condition is irrelevant, you can specify a separate filter function through or:
pattern.where(...).or(...);
Then, based on this condition, we can switch to the next state through the next or followedBy method. Next means the element immediately after the qualified element in the previous step; followedBy does not require that it be the next element. These two are called strict nearest neighbor and non strict nearest neighbor respectively.
val strictNext = start.next("middle")
val nonStrictNext = start.followedBy("middle")
Finally, we can limit the conditions of all patterns to a certain time range:
next.within(Time.seconds(10))
This time can be either Processing Time or Event Time.
- Pattern detection
Through an input DataStream and the Pattern we just defined, we can create a PatternStream:
val input = ...
val pattern = ...
val patternStream = CEP.pattern(input, pattern)
val patternStream = CEP.pattern(loginEventStream.keyBy(_.userId), loginFailPattern)
Once the PatternStream is obtained, we can find the warning information we need from a Map sequence through select or flatSelect.
- Select
The select method needs to implement a PatternSelectFunction and output the required warnings through the select method. It accepts a Map pair containing string/event, where key is the name of state and Event is the real Event.
val loginFailDataStream = patternStream.select(new MySelectFuction())
The return value is only 1 record.
- flatSelect
By implementing the PatternFlatSelectFunction, functions similar to select are realized. The only difference is that the flatSelect method can return multiple records. It passes the data to be output to the downstream through a Collector[OUT] type parameter.
- Handling of timeout events
Through the within method, our partern rule limits the matching events to a certain window range. When there are events that arrive after the window time, we can handle this situation by implementing PatternTimeoutFunction and PatternFlatTimeoutFunction in select or flatSelect
val patternStream: PatternStream[Event] = CEP.pattern(input, pattern)
val outputTag = OutputTag[String]("side-output")
val result: SingleOutputStreamOperator[ComplexEvent] = patternStream.select
(outputTag){
(pattern: Map[String, Iterable[Event]], timestamp: Long) => TimeoutEvent()} {
pattern: Map[String, Iterable[Event]] => ComplexEvent()
}
val timeoutResult: DataStream<TimeoutEvent> = result.getSideOutput(outputTag)
3. CEP practice
import java.util
import org.apache.flink.cep.PatternSelectFunction
import org.apache.flink.cep.scala.CEP
import org.apache.flink.cep.scala.pattern.Pattern
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala._
object FlinkCep2LoginFailEventOps {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
//Event flow
val loginStream = env.fromCollection(List(
LoginEvent("1", "192.168.0.1", "fail", "1558430842"),
LoginEvent("1", "192.168.0.2", "fail", "1558430843"),
LoginEvent("1", "192.168.0.3", "fail", "1558430844"),
LoginEvent("2", "192.168.10.10", "success", "1558430845"))
).assignAscendingTimestamps(_.eventTime.toLong)
//Two consecutive login failures within 10s of defining the rule
val pattern = Pattern.begin[LoginEvent]("begin")
.where(loginEvent => loginEvent.eventType == "fail")
.next("next")
.where(loginEvent => loginEvent.eventType == "fail")
.within(Time.seconds(10))
//Use rules to verify data
val patternStream: PatternStream[LoginEvent] = CEP.pattern(loginStream, pattern)
//Get the data on the matching and generate relevant warnings. At this time, you need to use select to select the stream
patternStream.select(new MySelectPatternFunction).print()
env.execute(s"${FlinkCep2LoginFailEventOps.getClass.getSimpleName}")
}
class MySelectPatternFunction extends PatternSelectFunction[LoginEvent, Warning] {
override def select(pp: util.Map[String, util.List[LoginEvent]]): Warning = {
val firstEvent = pp.getOrDefault("begin", null).get(0)
val secondEvent = pp.getOrDefault("next", null).get(0)
val userId = firstEvent.userId
val firstEventTime = firstEvent.eventTime
val secondEventTime = secondEvent.eventTime
Warning(userId, firstEventTime, secondEventTime, msg = "Failed to log in twice in a row. I suspect you have evil behavior and put you in a small black room~")
}
}
}
case class LoginEvent(userId: String, ip: String, eventType: String, eventTime: String)
//Last generated warning message
case class Warning(userId: String, firstEventTime: String, secondEventTime: String, msg: String)
(3) . Flink task performance optimization
1,Operator Chain
For more efficient distributed execution, Flink will link the subtask s of the operator together to form tasks as much as possible, and each task is executed in one thread. Linking operators to tasks is a very effective optimization: it can reduce the switching between threads, reduce the serialization / deserialization of messages, reduce the exchange of data in the buffer, reduce the delay and improve the overall throughput.
During the generation of JobGraph, Flink will optimize the operators that can be optimized in the code into an operator chain for execution in a task (a thread), so as to reduce the switching and buffering overhead between threads and improve the overall throughput and latency. The following is an example from the official website.
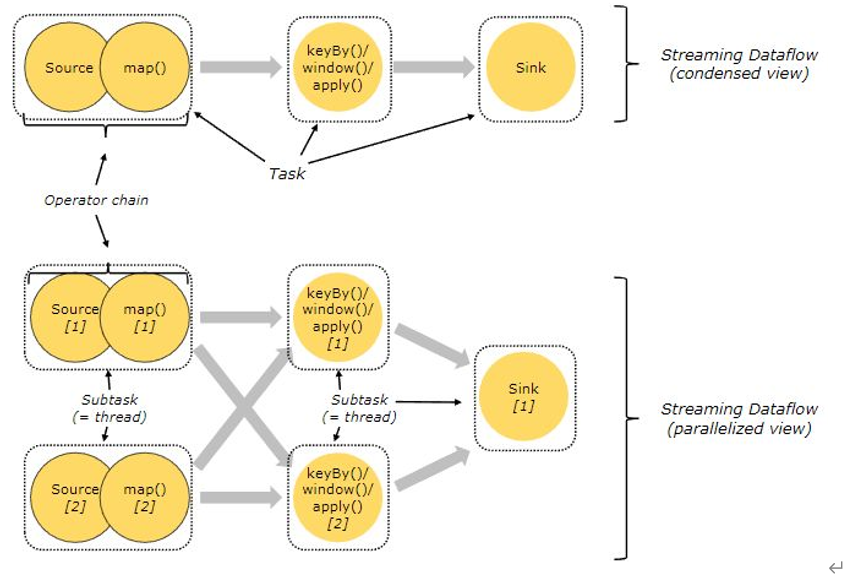
In the figure above, the parallelism of the source, map, [keyBy|window|apply] and sink operators are 2, 2, 2 and 1 respectively. After Flink optimization, the source and map operators form an operator chain and run on a thread as a task. The diagram is shown in the condensed view and the parallel diagram is shown in the parallel view. Whether an operator chain can be formed between operators depends on whether the following conditions are met:
- The parallelism of upstream and downstream operators is consistent;
- Both upstream and downstream nodes are in the same slot group;
- The chain strategy of downstream nodes is ALWAYS;
- The chain policy of the upstream node is ALWAYS or HEAD;
- The data partition mode between two nodes is forward;
- The user did not disable chain.
2,Slot Sharing
Slot Sharing means that subtasks of different tasks from the same Job with the same Slot Sharing group (default) name can share a slot, which gives a slot the opportunity to hold a whole Pipeline of the Job, This is also why the number of slots required for Job startup under the default Slot Sharing condition mentioned above is equal to the maximum parallelism of the Operator in the Job. The Slot Sharing mechanism can further improve the Job performance. When the number of slots remains unchanged, the maximum parallelism that can be set by the Operator is increased, so that resource consuming tasks such as window are distributed on different TM with the maximum parallelism. At the same time, simple operations such as map and filter will not monopolize slot resources, Reduce the possibility of resource waste.
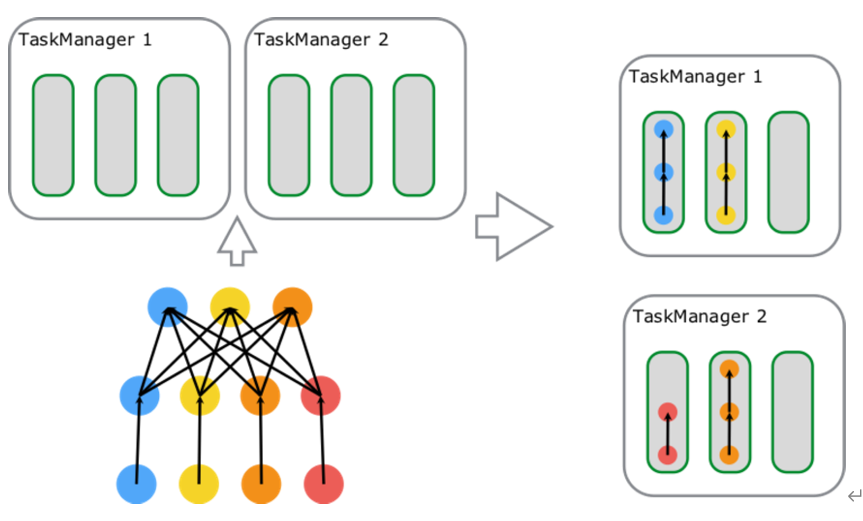
The figure contains three tasks: source map [6 parallelism], keyBy/window/apply[6 parallelism] and sink[1 parallelism], occupying a total of 6 slots; Starting from left to right, the first Slot runs three subtasks [3 threads] and holds a complete pipeline of the Job; There are two subtasks [2 threads] running in the remaining five slots, and the data is finally transmitted to Sink through the network to complete data processing.
3. Flink asynchronous IO
In streaming computing, it is often necessary to interact with external systems, and your time to obtain the connection and wait for communication will account for a high proportion in a connection. The following figure is a comparison example of two methods: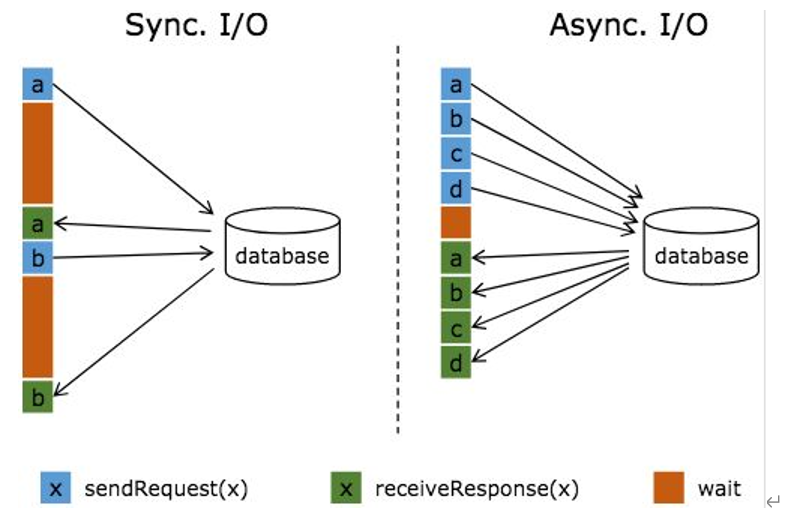
The long brown bar in the figure indicates the waiting time. It can be found that the network waiting time greatly hinders the throughput and delay. In order to solve the problem of synchronous access, asynchronous mode can process multiple requests and replies concurrently. In other words, you can continuously send requests from users a, b, c, etc. to the database. At the same time, the reply of which request is returned first will be processed, so there is no need to block and wait between successive requests, as shown on the right of the above figure. This is exactly the implementation principle of Async I/O.
4. Checkpoint optimization
Flink implements a powerful checkpoint mechanism, which can not only achieve high throughput performance, but also ensure fast recovery at the exact only level.
First, to improve the performance of each node checkpoint, the consideration is the execution efficiency of the storage engine. Among the three checkpoint state storage schemes officially supported by Flink, Memory is only used for debugging level and cannot recover data after failure. Secondly, there are file system and Rocksdb. When the data size of the checkpoint is large, Rocksdb can be considered as the storage of the checkpoint to improve efficiency.
The second idea is resource setting. We all know that the checkpoint mechanism is carried out on each task. When the total state data size remains unchanged, how to allocate and reduce the checkpoint data divided by a single task has become the key to improve the checkpoint execution efficiency.
Finally, incremental snapshots. Under non incremental snapshot, each checkpoint contains all status data of the job. In most scenarios, there are relatively few data changes in the front and back checkpoints, so setting an incremental checkpoint will only store and calculate the state difference between the last checkpoint and the current checkpoint, reducing the time-consuming of the checkpoint.
Suggestions for using checkpoint
In theory, Flink supports very short checkpoint intervals, but in actual production, too short intervals will bring great pressure to the underlying distributed file system. On the other hand, due to the semantics of checkpoints, in fact, there is a mutual exclusion between the record processed by Flink job and the checkpoint executed. Too frequent checkpoints may affect the overall performance. Of course, the starting point of this proposal is the pressure consideration of the underlying distributed file system.
Reasonably set the timeout
The default timeout is 10min. If the state is large, it needs to be configured reasonably. In the worst case, the speed of distributed creation is faster than that of single point deletion (job master side), resulting in high pressure on the available space of the overall storage cluster. It is recommended to increase the timeout when checkpoints frequently fail due to timeout.
//Set the timeout time. The timeout time means that the checkpoint is set, but it is considered to have timed out if it has not been completed in the past 500ms, and then terminate the checkpoint, that is, the checkpoint is no longer used
env.getCheckpointConfig().setCheckpointTimeout(500);
5. Resource allocation
- Parallelism: ensure sufficient parallelism. The greater the parallelism, the better. Too much will increase the pressure of data transmission between multiple solt / task managers, including the pressure caused by serialization and deserialization.
- CPU: CPU resources are shared by the solt on task manager. Pay attention to monitoring CPU usage.
- Memory: memory is used separately by solt. Note that when storing large state s, the memory should be sufficient.
- Network: for big data processing, there will be a lot of data transmission between flink nodes. Try to use 10 Gigabit network card for server network card.
6. Summary
Operator Chain links multiple operators together and places them in one Task. It is only for operators. Slot Sharing is to execute multiple tasks in a slot, which is for tasks after the Operator Chain. Both of these optimizations make full use of computing resources, reduce unnecessary overhead and improve Job performance. Asynchronous IO can solve the problem of requiring efficient access to other systems and improve the performance of Task execution. Checkpoint optimization is the optimization of cluster configuration to improve the processing capacity of the cluster itself.