T1 A Theme of Numberism
subject
[Title Description]
LYK has an undirected graph G={V,E}, which consists of n points and m edges. And this is a weighted graph with only a point weight.
LYK wants to delete this graph, and its method is like this. Choose one point at a time and delete it, but delete it at a cost.
Suppose that the points connected to this point that have not been deleted are u1,u2,... UK. LYK will add a[u1],a[u2],... Fatigue value of a[uk].
It wants to delete all the points and minimize the sum of its fatigue values after deletion. Can you help it?
[Input Format]
The first line has two numbers n,m representing a graph with n points and m edges.
The second line n-number ai represents the point weight.
Next, m rows have three numbers u and V per row, which means that there is an edge connecting u and V. Data ensures that at most one edge is connected between any two points, and there is no self-ring.
[Output Format]
What is the minimum fatigue value you need to output?
[Input sample]
4 3 10 20 30 40 1 4 1 2 2 3
[Output sample]
40
[Data Scale]
For 30% of the data n < 10.
For 60% of the data n,m is less than 1000.
For 100% of the data, 1 < n,m,ai < 100000.
analysis
Long-lost sub-questions
Greedy thinking, the contribution of each point to the points connected with it is sorted from large to small, then deleted in turn.
Code
#include <algorithm> #include <iostream> #include <cstring> #include <string> #include <cstdio> #include <vector> #include <cmath> using namespace std; inline int read() { int num=0; char ch=getchar(); while(ch<'0'||ch>'9') ch=getchar(); while(ch>='0'&&ch<='9') { num=(num<<1)+(num<<3)+ch-'0'; ch=getchar(); } return num; } const int N=100100; struct rec{ int w,num; }a[N]; int n,m,b[N]; long long ans; bool v[N]; vector<int> edge[N]; bool cmp(rec x,rec y) { return x.w>y.w; } int main() { //freopen("god.in","r",stdin); //freopen("god.out","w",stdout); memset(v,false,sizeof(v)); n=read(),m=read(); for(int i=1;i<=n;i++) a[i].w=read(),a[i].num=i,b[i]=a[i].w; for(int i=1;i<=m;i++) { int x=read(),y=read(); edge[x].push_back(y),edge[y].push_back(x); } sort(a+1,a+n+1,cmp); for(int i=1;i<=n;i++) { int x=a[i].num; v[x]=true; for(int j=0;j<edge[x].size();j++) if(!v[edge[x][j]]) ans+=b[edge[x][j]]; } cout<<ans; return 0; }
T2 Array XOR
subject
[Title Description]
xor - xor, like and or, is an important logical operation. Its operation rules are 0 xor 0 = 0, 1 xor 1=0, 1 xor 0=1, 0 xor 1=1.
The difference between two integers or the conversion of two integers into binary, each of them is xor operation, for example: 6(110) xor 13(1101) = 11(1011)
Now let's introduce A new operation, Array XOR. If two arrays of the same size (assuming all of them are n) are XOR or XOR into A new Array C, then the new Array must satisfy the following requirements:
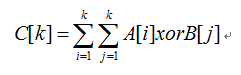
Now give you the array size n, and two arrays A,B.
Find their exclusive or array C
Since the final answer may be too large, you need to model 109 + 7 for each element of C
[Input Format]
There are three rows in all.
The first line has a positive integer N.
The next two lines have N positive integers per row, representing arrays A and B.
[Output Format]
A total of 1 line, N positive integers, representing the array C.
[Input sample]
7 20670 1316 25227 8316 21095 28379 25235 19745 6535 14486 5460 15690 1796 12403
[Output sample]
7583 52096 161325 276944 453024 675974 958287
[Data Scale]
For 50% of the data, N is less than 100.
For all data, N < 105.
analysis
Number theory is not very clear, the following is the problem of the author.

Code
#include <algorithm> #include <iostream> #include <cstring> #include <string> #include <cstdio> #include <cmath> using namespace std; inline int read() { int num=0; char ch=getchar(); while(ch<'0'||ch>'9') ch=getchar(); while(ch>='0'&&ch<='9') { num=(num<<1)+(num<<3)+ch-'0'; ch=getchar(); } return num; } const int N=133333,mod=1000000007; int n,a[N],b[N],aa[33][2],bb[33][2]; int main() { //freopen("xorarray.in","r",stdin); //freopen("xorarray.out","w",stdout); n=read(); for(int i=1;i<=n;i++) a[i]=read(); for(int i=1;i<=n;i++) b[i]=read(); for(int i=1;i<=n;i++) { long long c=0; for(int j=0;j<=30;j++) { aa[j][(a[i]>>j)&1]++,bb[j][(b[i]>>j)&1]++; long long cc=((long long)aa[j][0]*bb[j][1]+(long long)aa[j][1]*bb[j][0])%mod*(1<<j)%mod; c=(c+cc)%mod; } cout<<c<<" "; } return 0; }
T3 Detective Game
subject
[Title Description]
Xiao W is addicted to a detective game recently, in which there will be murders. As the protagonist, Xiao W needs to constantly collect all kinds of key evidence. Only when all the key evidence is found, can you refute everyone's wrong judgment and find the real murderer.
There are N key evidences and M pieces of information. Each piece of information is as follows: if you already have evidence i, you can get evidence J through k-time search and reasoning. Similarly, if you have evidence j, you can get evidence I through k-time search and reasoning.
At the beginning of the game, the player has obtained evidence 1 through preliminary observation. At the same time, each player can get a special skill to speed up the game progress and increase interest in the beginning stage of the game. Xiao W chose a skill he had never used before: good luck. This is a passive skill. The system will select a pair of evidence (a,b) (a_b) at the beginning of the game. When W discovers one of the evidence, he will be lucky to get another evidence immediately (not counting the time).
But this skill is totally random. Little W has no idea which pair of evidence the system will choose after entering the game. He hopes you can help him figure out the expected value of the time he spends in this round of games, so that he can have a bit of B in mind.
Provided information assurance: i is not equal to j, each k value is different, N evidence can be obtained.
[Input Format]
A total of M+1 lines.
The first line contains two positive integers, N and M, representing the amount of evidence and information.
Next, in line M, three digits i,j,k for each line represent a message.
[Output Format]
There are 1 line and 1 integer (the expected value is real, but please keep the 2 decimal output directly here).
[Input sample]
3 3 1 2 3 1 3 2 2 3 5
[Output sample]
2.33
[Data Scale]
For 20% of the data, N < 100
For 60% of the data, N < 1000
For all data, N is less than 20000, M is less than 105, 1 is less than k is less than 106.
analysis
If all edges on MST with edge weights less than w are added and the number of connected points increases K, then the number of points with maximum edge weights of w on the path is K.
So we can use a joint search to add the edge weight from small to large. For edges (u,v,w), the answer accumulates sizeu*sizev*w, and then merges the connected blocks of u and V. (sizei denotes the size of the junction block to which point i belongs).
Code
#include <algorithm> #include <iostream> #include <cstring> #include <string> #include <cstdio> #include <cmath> using namespace std; inline int read() { int num=0,w=1; char ch=getchar(); while(ch<'0'||ch>'9') { if(ch=='-') w=-1; ch=getchar(); } while(ch>='0'&&ch<='9') { num=(num<<1)+(num<<3)+ch-'0'; ch=getchar(); } return num*w; } const int N=33333,M=133333; struct rec{ int u,v,d; }edge[M]; int n,m,fa[N],s[N]; long long cnt,sum; bool cmp(rec x,rec y) { return x.d<y.d; } int find(int x) { if(fa[x]==x) return fa[x]; return fa[x]=find(fa[x]); } int main() { n=read(),m=read(); for(int i=1;i<=m;i++) edge[i].u=read(),edge[i].v=read(),edge[i].d=read(); sort(edge+1,edge+m+1,cmp); for(int i=1;i<=n;i++) fa[i]=i,s[i]=1; for(int i=1;i<=m;i++) { int x=find(edge[i].u),y=find(edge[i].v); if(x==y) continue; sum+=edge[i].d,cnt+=(long long)s[x]*s[y]*edge[i].d,s[x]+=s[y],fa[y]=x; } double ans=sum-2.0*cnt/n/(n-1); printf("%.2lf",ans); return 0; }
T4 Day Fall Pie
subject
[Title Description]
Little G enters a magical world in which some pies fall from the sky. Today, k pies fall randomly from the sky.
Every time a pie falls from the sky, Little G can choose to eat it or not (he must make a choice before the next pie falls, and he can't eat it after he decides not to eat it now).
According to the law of physics, the probability of n kinds of pies falling from the sky is the same and independent. However, each pie i has a precondition pie set Si. Only when all the pies in Si have been eaten can we eat the first kind of pie. For example, in the S of chives pie, there are Chinese cabbage pork pie and shrimp Patty. Then little G can only eat leek stuffed pies after eating Chinese cabbage pork pie and shrimp pie.
At the same time, each pie has a delicious value of Pi. Today, the happiness of little G equals the sum of all the pies that little G eats. Note: Pi may be negative.
Now consider, with the optimal strategy, what is the expected happiness of Little G on this day?
[Input Format]
The first line has two positive integers k and n, representing the number and type of pie.
The following n lines, several numbers per line, describe a pie. The first number represents the delicious value, and the subsequent integer represents the premise pie of the pie, ending at 0.
[Output Format]
Output a real number, reserve 6 decimal, that is, the desired happiness under the optimal strategy.
[Input sample]
1 2 1 0 2 0
[Output sample]
1.500000
[Data Scale]
For 20% of the data, there is no "prerequisite pie" for all pies.
For 50% of the data, 1 < k < 10, 1 < n < 10.
For 100% of the data, 1 < k < 100, 1 < n < 15, and the delicacy is an integer of [-106, 106].
analysis
n is only 15. Obviously, the pressure on DP is equal. Let f[i][j] indicate whether the maximum expected score of state j has been taken in the first to the first rounds.
Then the state transition equation is: (1 < k < n)
- If the j state satisfies the condition of eating the K pie, it will not eat f[i+1][j], but eat f[i+1][j | (1 < k-1)] + Pk, and take the maximum of the two to accumulate f[i][j];
- If the state of J does not satisfy the condition of eating the k pie, it can not be eaten, that is, f[i][j]=f[i+1][j].
As for expectations, although they are very high-end, i n fact, because f[i][j] covers N kinds of pies in the first round, dividing each f[i][j] by N is enough.
The answer is f[1][0].
Code
#include <algorithm> #include <iostream> #include <cstring> #include <string> #include <cstdio> #include <cmath> using namespace std; inline int read() { int num=0,w=1; char ch=getchar(); while(ch<'0'||ch>'9') { if(ch=='-') w=-1; ch=getchar(); } while(ch>='0'&&ch<='9') { num=(num<<1)+(num<<3)+ch-'0'; ch=getchar(); } return num*w; } const int N=16,K=120,T=1<<15; int k,n,v[N],d[N]; double f[K][T]; int main() { k=read(),n=read(); for(int i=1;i<=n;i++) { v[i]=read(); int x=read(); while(x) d[i]+=1<<(x-1),x=read(); } for(int i=k;i>=1;i--) for(int j=0;j<1<<n;j++) { for(int p=1;p<=n;p++) if((j&d[p])==d[p]) f[i][j]+=max(f[i+1][j],f[i+1][j|(1<<(p-1))]+v[p]); else f[i][j]+=f[i+1][j]; f[i][j]/=n; } printf("%.6f",f[1][0]); return 0; }