Related concepts
What is multithreading?
Multithreading refers to the technology of concurrent execution of multiple threads from software or hardware. Computers with multithreading capability can execute multiple threads at the same time due to hardware support, so as to improve performance.
Concurrency and parallelism
- Parallelism: multiple instructions are executed simultaneously on multiple CPU s at the same time.
- Concurrency: at the same time, multiple instructions are executed alternately on a single CPU
Processes and threads
Process: refers to an application running in memory. Each process has an independent memory space. Process is also an execution process of the program and the basic unit of the system running the program.
- Independence: a process is a basic unit that can run independently. It is also an independent unit for system resource allocation and scheduling
- Dynamic: the essence of a process is an execution process of a program. A process is produced and dies dynamically
- Concurrency: any process can execute concurrently with other processes
Thread: it is a single sequential control flow in a process and an execution path
- Single thread: if a process has only one execution path, it is called a single threaded program
- Multithreading: if a process has multiple execution paths, it is called a multithreaded program
Process is the smallest unit of operating system scheduling and resource allocation, and thread is the smallest unit of CPU scheduling. Memory is not shared between different processes. The cost of data exchange and communication between processes is very high. Different threads share the memory of the same process. Of course, different threads also have their own independent memory space. For the method area, the memory of the same object in the heap can be shared between threads, but the local variables of the stack are always independent.
Implementation of multithreading
Method 1: inherit Thread class
Java uses the java.lang.Thread class to represent threads. All Thread objects must be instances of the Thread class or its subclasses. The role of Thread is to complete certain tasks. In fact, it is to execute a program flow, that is, a piece of code executed in sequence. Java uses Thread executors to represent this program flow. The steps to create and start a multithread by inheriting the Thread class in Java are as follows:
- Define a subclass of the Thread class and override the run() method of the class. The method body of the run() method represents the tasks that the Thread needs to complete. Therefore, the run() method is called the Thread execution body.
- Create an instance of Thread subclass, that is, create a Thread object
- Call the start() method of the thread object to start the thread
be careful:

The difference between the run() method and the start() method
- run(): encapsulates the code executed by the thread. It is called directly, which is equivalent to the call of ordinary methods
- start(): start the thread; The run() method of this thread is then called by the JVM
Code example
package ThreadDemo;
// 1: Define a class MyThread to inherit the Thread class
public class MyThread extends Thread {
/**
*2 : Rewrite the run method to complete the logic executed by the thread
*/
@Override
public void run() {
for (int i = 0; i < 30; i++) {
System.out.println("Executing!" + i);
}
}
}Define test class
package ThreadDemo;
public class Test {
public static void main(String[] args) {
//3: Create custom thread object
MyThread mt = new MyThread();
//4: Open new thread
mt.start();
//Execute the for loop in the main method, and the main thread code
for (int i = 0; i < 30; i++) {
System.out.println("main Thread!"+i);
}
}
}
Note: a custom thread object is a thread, that is, an execution path
Method 2: implement Runnable interface
Java has the limitation of single inheritance. When we cannot inherit the Thread class, what should we do? The Runnable interface is provided in the core class library. We can implement the Runnable interface, rewrite the run() method, and then start and execute our Thread body run() method through the object proxy of Thread class
The steps are as follows:
- Define the implementation class of the Runnable interface and override the run() method of the interface. The method body of the run() method is also the thread execution body of the thread.
- Create an instance of the Runnable implementation class and use this instance as the target of the Thread to create the Thread object, which is the real Thread object.
- Call the start() method of the thread object to start the thread.
The code is as follows:
-
package demo; //1: Define a class MyRunnable to implement the Runnable interface public class MyRunnable implements Runnable { @Override public void run() {//2: Override the run() method in the MyRunnable class for(int i=0; i<100; i++) { System.out.println(i); } } } class MyRunnableDemo { public static void main(String[] args) { //3: Create an object of the MyRunnable class MyRunnable my = new MyRunnable(); //4: Create an object of Thread class and take the MyRunnable object as the parameter of the construction method Thread t1 = new Thread(my); //5: Start thread t1.start(); } }
Summary:
- By implementing the Runnable interface, this class has the characteristics of multi-threaded class. The run() method is an execution target of a multithreaded program. All multithreaded code is in the run method. The Thread class is actually a class that implements the Runnable interface.
- When you start the multithreading, you need to construct the object through the Thread class construction method Thread(Runnable target) and then call the start() method of the Thread object to run the multithreaded code.
- In fact, all multithreaded code is run by running the start() method of Thread. Therefore, whether inheriting the Thread class or implementing the Runnable interface to realize multithreading, the Thread is finally controlled through the API of the Thread object. Being familiar with the API of the Thread class is the basis of multithreading programming.
- The Runnable object is only used as the target of the Thread object, and the run() method contained in the Runnable implementation class is only used as the Thread executor. The actual Thread object is still a Thread instance, but the Thread thread is responsible for executing the run() method of its target.
Implementation of multithreading mode 3: implementation of Callable interface
Implementation steps
- Define a class MyCallable to implement the Callable interface
- Override the call() method in the MyCallable class
- Create an object of the MyCallable class
- Create the FutureTask object of the implementation class of Future, and take the MyCallable object as the parameter of the construction method
- Create an object of Thread class and take FutureTask object as the parameter of construction method
- Start thread
- Then call the get method to get the result after the thread ends.
Code example
package demo01;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
for (int i = 0; i < 100; i++) {
System.out.println("physical exercise:" + i);
}
//The return value represents the result after the thread runs
return "Eight abdominal muscles";
}
}
class Test{
public static void main(String[] args) throws ExecutionException, InterruptedException {
//After the thread is started, you need to execute the call method inside
MyCallable myCallable = new MyCallable();
//task can obtain the result after the Thread is executed. It can also be passed to the Thread object as a parameter
FutureTask<String> task = new FutureTask<>(myCallable);
//Create thread object
Thread thread = new Thread(task);
//Open thread
thread.start();
// Gets the object after the thread is executed
String s = task.get();
System.out.println(s);
}
}Comparison of three methods:

Thread class
Construction method:
- public Thread(): allocate a new thread object.
- public Thread(String name): assign a new thread object with a specified name.
- public Thread(Runnable target): allocate a new thread object with the specified target.
- public Thread(Runnable target,String name): allocate a new thread object with the specified target and specify the name.
common method
- public void run(): the task to be executed by this thread defines the code here.
- public String getName(): get the name of the current Thread. A Thread has a default name. The format is Thread number
- public static Thread currentThread(): returns a reference to the currently executing thread object.
- public final boolean isAlive(): test whether the thread is active. Active if the thread has been started and not terminated.
- public final int getPriority(): returns the thread priority
- public final void setPriority(int newPriority): change the priority of threads. Each Thread has a certain priority. Threads with high priority will get more execution opportunities. The default priority of each Thread is the same as the parent Thread that created it. The Thread class provides setPriority(int newPriority) and getPriority() method classes to set and obtain the priority of threads. The setPriority method requires an integer and the range is between [1,10]. By default, the main Thread has normal priority 5.
- public void start(): causes this thread to start executing; The Java virtual machine calls the run method of this thread.
- Public static void sleep (long miles): pauses (temporarily stops) the currently executing thread for the specified number of milliseconds.
- public static void yield(): yield just pauses the current thread and reschedules the system's thread scheduler. It is hoped that other threads with the same or higher priority as the current thread can get execution opportunities. However, this cannot be guaranteed. It is entirely possible that when a thread calls the yield method to pause, The thread scheduler schedules it for re execution.
- void join(): wait for the thread to terminate.
- void join(long millis): the maximum time to wait for the thread to terminate is millis. If the millis time expires, it will no longer wait.
- void join(long millis, int nanos): the maximum time to wait for the thread to terminate is millis + nanos.
- public final void stop(): force the thread to stop execution. This method is inherently unsafe. It has been marked @ Deprecated and is not recommended to be used again. Then we need to stop the thread in other ways. One way is to use the change of variable value to control whether the thread ends.
Daemon thread
There is a thread that runs in the background. Its task is to provide services for other threads. This thread is called "guard thread". The garbage collection thread of the JVM is a typical daemon thread. A feature of daemon threads is that if all non daemon threads die, the daemon thread will die automatically.
- Call the setDaemon(true) method to set the specified thread as a daemon thread. It must be set before the thread starts, otherwise an IllegalThreadStateException will be reported.
- Call isDaemon() to determine whether the thread is a daemon thread.
Thread safety
When we use multiple threads to access the same resource (which can be the same variable, the same file, the same record, etc.), if multiple threads only have read operations, thread safety problems will not occur, but if multiple threads have read and write operations on resources, thread safety problems are easy to occur.
Same resource problem
- Local variables cannot be shared
- Instance variables of different objects are not shared
- Static variables are shared
- Instance variables of the same object are shared
View the following code
package demo06;
public class SellTicket implements Runnable {
private int ticket = 100;
//Rewrite the run() method in SellTicket class to realize ticket selling. The code steps are as follows
@Override
public void run() {
while (true) {
if(ticket <= 0){
//out of stock
break;
}else{
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
ticket--;
System.out.println(Thread.currentThread().getName() + "Selling tickets,Remaining" + ticket + "Ticket");
}
}
}
}Define test class
package demo06;
public class Test {
public static void main(String[] args) {
//Create an object of SellTicket class
SellTicket st = new SellTicket();
//Create three Thread class objects, take the SellTicket object as the parameter of the construction method, and give the corresponding window name
Thread t1 = new Thread(st,"Window 1");
Thread t2 = new Thread(st,"Window 2");
Thread t3 = new Thread(st,"Window 3");
//Start thread
t1.start();
t2.start();
t3.start();
}
}
Results after execution
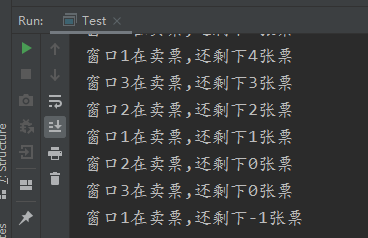
Through the implementation results, we found that
- The same ticket appeared many times
- There were negative votes
Causes of problems
- Due to the randomness of thread execution, the execution right of cpu may be lost during ticket selling, resulting in problems
Conditions for safety problems
- Is a multithreaded environment
- Shared data
- Multiple statements operate on shared data
How to solve the problem of multithreading security? Basic idea: let the program have no security environment. Java provides a synchronized mechanism to solve the problem.
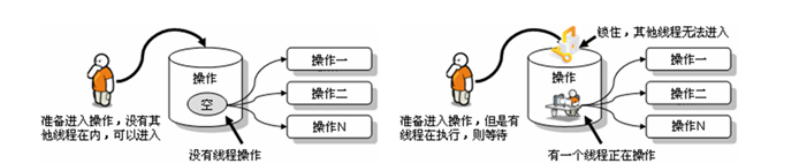
In order to ensure that each thread can normally perform atomic operations, Java introduces thread synchronization mechanism. Note: at most one thread is allowed to have a synchronization lock at any time. Whoever gets the lock will enter the code block, and other threads can only wait outside (BLOCKED).
Advantages and disadvantages of synchronization
- Benefits: it solves the data security problem of multithreading
- Disadvantages: when there are many threads, each thread will judge the lock on synchronization, which is very resource-consuming and will virtually reduce the running efficiency of the program
Synchronous code block
The synchronized keyword can be used in front of a block to indicate that mutually exclusive access is only implemented to the resources of the block.
format
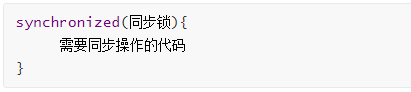
Code example
public class SellTicket implements Runnable {
private int tickets = 100;
private Object obj = new Object();
@Override
public void run() {
while (true) {
synchronized (obj) { // Lock the code that may have security problems. Multiple threads must use the same lock
//When t1 comes in, it will lock this code
if (tickets > 0) {
try {
Thread.sleep(100);
//t1 rest 100ms
} catch (InterruptedException e) {
e.printStackTrace();
}
//Window 1 is selling ticket 100
System.out.println(Thread.currentThread().getName() + "The second is being sold" + tickets + "Ticket");
tickets--; //tickets = 99;
}
}
//When t1 comes out, the lock of this code is released
}
}
}
public class SellTicketDemo {
public static void main(String[] args) {
SellTicket st = new SellTicket();
Thread t1 = new Thread(st, "Window 1");
Thread t2 = new Thread(st, "Window 2");
Thread t3 = new Thread(st, "Window 3");
t1.start();
t2.start();
t3.start();
}
}What is the synchronization lock object?
- The lock object can be of any type.
- Multiple thread objects should use the same lock.
Synchronization method
The synchronized keyword directly modifies a method, indicating that only one thread can enter the method at the same time, and other threads are waiting outside.
Synchronization method: add the synchronized keyword to the method. The format is as follows:

Synchronous static method: add the synchronized keyword to the static method

Code example
package demo02;
public class SaleTicketSafeDemo1 {
public static void main(String[] args) {
// 2. Create resource object
Ticket ticket = new Ticket();
// 3. Start multiple threads to operate on the object of the resource class
Thread t1 = new Thread("Window one") {
public void run() {
while (true) {
try {
Thread.sleep(10);// Add this to make the problem more obvious
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t2 = new Thread("Window II") {
public void run() {
while (true) {
try {
Thread.sleep(10);// Add this to make the problem more obvious
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t3 = new Thread(new Runnable() {
public void run() {
while (true) {
try {
Thread.sleep(10);// Add this to make the problem more obvious
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
}, "Window three");
t1.start();
t2.start();
t3.start();
}
}
// 1. Write resource class
class Ticket {
private int total = 10;
//The lock object implied by non static methods is this
public synchronized void sale() {
if (total > 0) {
System.out.println(Thread.currentThread().getName() + "Sell one ticket and the rest:" + --total);
} else {
return;
}
}
}Lock object problem of synchronization method
- Static method: the Class object of the current Class
- Non static method: this
Lock lock
- Although we can understand the Lock object problem of synchronization code blocks and synchronization methods, we do not directly see where the Lock is added and where the Lock is released. In order to more clearly express how to add and release the Lock, JDK5 provides a new Lock object Lock
- Lock is an interface that cannot be instantiated directly. Its implementation class ReentrantLock is used to instantiate it here
Common methods:
- void lock(): Acquire lock
- void unlock(): release the lock
package demo02;
import java.util.concurrent.locks.ReentrantLock;
public class Ticket implements Runnable {
//Number of tickets
private int ticket = 100;
private ReentrantLock lock = new ReentrantLock();
@Override
public void run() {
while (true) {
try {
lock.lock();
if (ticket <= 0) {
//out of stock
break;
} else {
Thread.sleep(100);
ticket--;
System.out.println(Thread.currentThread().getName() + "Selling tickets,Remaining" + ticket + "Ticket");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
class Demo {
public static void main(String[] args) {
Ticket ticket = new Ticket();
Thread t1 = new Thread(ticket);
Thread t2 = new Thread(ticket);
Thread t3 = new Thread(ticket);
t1.setName("Window one");
t2.setName("Window II");
t3.setName("Window three");
t1.start();
t2.start();
t3.start();
}
}deadlock
Thread deadlock refers to that two or more threads hold the resources required by each other, resulting in these threads being in a waiting state and unable to execute
Under what circumstances will deadlock occur
- Limited resources
- Synchronous nesting
Code demonstration
public class Demo {
public static void main(String[] args) {
Object objA = new Object();
Object objB = new Object();
new Thread(()->{
while(true){
synchronized (objA){
//Thread one
synchronized (objB){
System.out.println("Well off students are walking");
}
}
}
}).start();
new Thread(()->{
while(true){
synchronized (objB){
//Thread two
synchronized (objA){
System.out.println("Xiao Wei is walking");
}
}
}
}).start();
}
}