1. The generation of word cloud needs to confirm that wordcloud and matplotlib have been installed. The download library can be downloaded through cmd or by directly entering instructions on the Jupiter notebook, or from the website https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud Download the installation package manually on the, place the installation package in the scripts file of python, and record the text you need on the text file (txt format), or prepare the desired image style first;
2. You can use the following similar code to realize python positioning. os.getcwd() can know where python is now (the file location needs to be determined according to your own situation)
import os
os.chdir("C:\\Users\\Scholar mn\\Desktop\\123123")3. After understanding the location, you should pay attention to adding this part when you can use the file path to open the file encoding='utf-8 ', setting the encoding format. Encoding means encoding. In python, Unicode type is the basic type of encoding.
text=open('123.txt','r',encoding='utf-8').read()4. Import wordcloud matplotlib starts to generate the first version of the word cloud. If you want to display the font, you need to define the font and reference the path of the font, and set the font size
from wordcloud import WordCloud
import matplotlib.pyplot as plt
font=r'C:\\Windows\\Fonts\\simkai.ttf'
wc=WordCloud(font_path=font,width=800,height=600).generate(text)
plt.imshow(wc)
plt.axis('off')
plt.show()5. After getting the first version of the word cloud, we can use the jieba library to segment the text, traverse the whole text and calculate the number of words, and use the corresponding relationship of key value pairs in the dictionary to correspond the meaning of words with their number.
At the same time, another thesaurus is established to eliminate invalid and unnecessary words from the existing thesaurus. Finally, the words are sorted by using the values in the dictionary to generate new text content.
import jieba
import jieba.posseg as pseg
with open('C:\\Users\\Scholar mn\\Desktop\\123123\\123.txt','r',encoding='utf-8')as f:
renmin=f.read()
jieba.load_userdict('C:\\Users\\Scholar mn\\Desktop\\123123\\123.txt')
seg_list=jieba.cut(renmin,cut_all=False)
tf={}
for seg in seg_list:
if seg in tf:
tf[seg]+=1
else:
tf[seg]=1
ci=list(tf.keys())
import os
os.chdir("C:\\Users\\Scholar mn\\Desktop\\123123")
with open('234.txt','r',encoding='utf-8') as ft:
stopword=ft.read()
for seg in ci:
if tf[seg]<5 or len(seg)<2 or seg in stopword or "one" in seg:
tf.pop(seg)
print(tf)
ci, num, data = list(tf.keys()), list(tf.values()),[]
for i in range(len(tf)):
data.append((num[i],ci[i]))
data.sort()
data.reverse()#Sort in ascending order and reverse order to get the required descending order
tf_sorted={}
print(len(data),data[0],data[0][0],data[0][1])
for i in range(len(data)):
tf_sorted[data[i][1]]=data[i][0]
print(tf_sorted)6. Finally, extract the original image information and extract the color from the original image
import os
os.chdir("C:\\Users\\Scholar mn\\Desktop\\123123")
text=open('123.txt','r',encoding='utf-8').read()
from wordcloud import WordCloud,ImageColorGenerator
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
mask=np.array(Image.open("C:\\Users\\Scholar mn\\Desktop\\123123\\rainbow.png"))
font=r'C:\\Windows\\Fonts\\simkai.ttf'
wc=WordCloud(background_color="white",mask=mask,font_path=font,width=800,height=600).generate_from_frequencies(tf_sorted)
image_colors=ImageColorGenerator(mask)
plt.imshow(wc.recolor(color_func=image_colors))
plt.imshow(wc)
plt.axis('off')
plt.show()Final effect display~

Experience:
1. File location problem: no matter the absolute path or relative path is used, and there is no error in the path, the program still displays "file does not exist" and the file cannot be found.
Solution: by changing the file name and location, the file should not be saved too "deep". At the same time, you can try a simple number 123 for file naming;
2. When you manually input the program code, the most common mistake is to input the wrong letters, regardless of case.
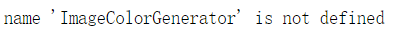
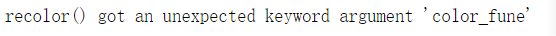
3. If the text content is in Chinese, you should also pay attention to the Chinese style when selecting the font, and there will still be problems when displaying in English