Data type and integrity constraints for MySQL databases
Keywords:
MySQL
Session
MariaDB
less
Supplement:
select * from mysql.user #Show chaos
select * from mysql.user\G #Added\G The next line shows
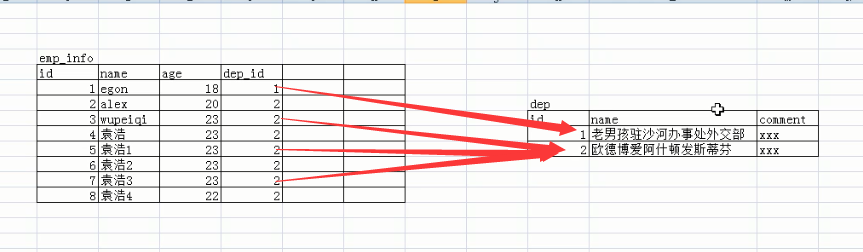
Data Type: Store different types of data in different categories
The storage engine determines the type of table, and there are different types of data stored in the table. U.S. and Chinese data types have their own widths, but the widths are optional.
1. Numbers (signed by default)
The numbers are divided into:
Integer: tinyint (small integer): one byte
Int (integer): four bytes. Note: the width of an int is the display width, independent of storage
Bigint: eight bytes
========================================
tinyint[(m)] [unsigned] [zerofill]
Small integer, the data type used to hold ranges of integer values:
Signed: -128-127
Unsigned: 0-255
PS:MySQL has no Boolean values and is constructed using tinyint(1).
Application of [unsigned] and [zerofill] parameters
3. Change signed to unsigned: alter table t1 modify unsigned; (Note that if there is a value in it,
The values must be emptied before they can be modified.
4.alter table t2 modify id int(10) zerofill; if not shown enough, fill with zerofill
========================================
int[(m)][unsigned][zerofill]
Integer, the data type used to hold ranges of integer values:
Signed: -2147483648~2147483647
Unsigned: 0~4294967295
========================================
bigint[(m)][unsigned][zerofill]
Large integer, data type used to hold ranges of integer values:
Signed: -9223372036854775808~9223372036854775807
Unsigned: 0-18446744073709551615
Decimal:
float: inaccurate when the number is relatively short (**** The larger the value, the less accurate ****)
double: Not accurate when digits are long (**** The larger the number, the less accurate ****)
Decimal: If decimal, decimal is recommended
Because of precision, internal principles are stored as strings


First create a database: create datdabase test;
-----------Validation 1: int,tinyint,bigint----
create table t1(id tinyint);
create table t1(id int);
create table t1(id bigint); #Use if the number is large bigint
1.If no symbol is specified.The default is signed
2.insert into t1(-129) #You will get an error because the range is-128~127
3.Change signed to unsigned: alter table t1 modify unsigned;(Note that if there is value in it, it has to be emptied before it can be modified)
4.alter table t2 modify id int(10) zerofill; If not, use zerofill Fill
5.Width: has nothing to do with survival,Refers to the width of the display
----------Validation 2: float,double------
create table t3(salary float(5,2)) #5 representative salary How wide is the total width, 2 represents the decimal point and reserves 2 bits, then the integer part has 3 bits
insert into t3 values(3.725454);
insert into t3 values(-3.725454);
insert into t3 values(1111.725454); #It would be wrong like this
insert into t3 values(111.725454);
bit Just know the type
bit type:Type representing binary
----------Validation 3: bit--------
create table t3(x bit);
insert into t3 values(0),(1);
insert into t3 values(0),(2)); #Only binary can be stored, which will result in an error
select * from t3;
Verify Number
Finally: Integer type, there is no need to specify the display width, use the default ok
2. Characters
char: Simple and rough, not enough space for fixed length storage, wasting space, but fast storage (sacrifice space, increase speed)
Varchar: accurate, calculates the length of the data with storage, saves space, and accesses slowly (sacrifice speed, increase efficiency)
1.-----------------
create table t6(name char(4));
insert into t6 values('alexsb');
insert into t6 values('Odd Boy');
insert into abc values('Alex a');
2.-------------
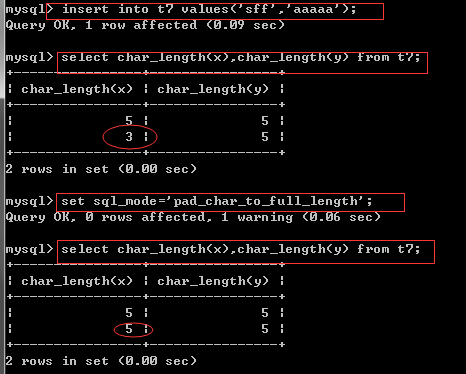
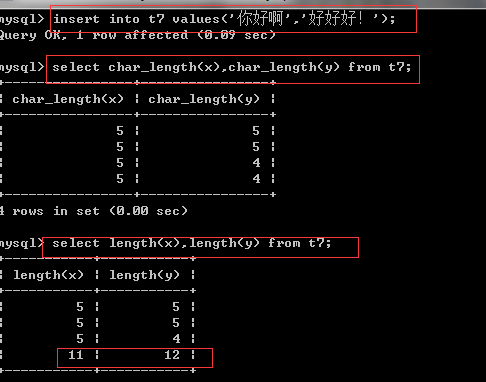
create table t7(x char(5),y varchar(5));
insert into t7 values('sff','aaaaa');
select char_length(x),char_length(y) from t7; View Character Length
set sql_mode='pad_char_to_full_length'; #get a life
insert into t7 values('How do you do','Good!');#utf-8 One of the Chinese characters represents three bytes. That'How do you do'Just nine,
#Add two spaces to 11 bytes
select length(x),length(y) from t7; View byte length
View Character Length
View byte length
3. Date
Role: Store user registration time, article publishing time, employee entry time, birth time, expiration time, etc.
There are several types:
datatime:2017-09-06 10:30:22
data:2017-09-06
time:10:30:22
year:2017
timeatamp: As with datatime, it supports a larger range than DataTime
---------------Validation 4: Date type-------
create table stu(
id int,
name char(5),
born_data date,
born_year year,
reg_time datetime,
class_time time
);
insert into stu values(1,'ao',now(),now(),now(),now());
insert into stu values(1,'xiao','2017-09-06','2017','2017-09-06 10:39:00','08:30:00');
#understand
insert into stu values(1,'alex','2017-09-06',2017,'2017-09-06 10:39:00','08:30:00');
insert into stu values(1,'alex','2017/09/06',2017,'2017-09-06 10:39:00','08:30:00'); No,-Can be exempted from quotation marks
insert into stu values(1,'alex','20170906',2017,'20170906103900','083000'); Or you can take the conjunction of the symbols
============Attention, attention, attention===========
1. When inserting time separately, you need to insert it as a string in the corresponding format
2. When inserting a year, use 4-bit values whenever possible
3. When inserting two years,<=69,Start with 20, such as 50, Result 2050
>=70,Start with 19, for example 71, and end with 1971
MariaDB [db1]> create table t12(y year);
MariaDB [db1]> insert into t12 values
-> (50),
-> (71);
MariaDB [db1]> select * from t12;
+------+
| y |
+------+
| 2050 |
| 1971 |
+------+
In many practical scenarios, both of these date types of MySQL meet our needs and are stored in seconds, but in some cases, they show their own strengths and weaknesses.Here is a summary of the differences between the two date types.
1. The date range of DATETIME is from 001 to 1999, and the time range of TIMESTAMP is from 1970 to 2038.
2.DATETIME storage time is independent of time zone, TIMESTAMP storage time is related to time zone, and displayed values are also dependent on time zone.On the mysql server, the operating system and client connections all have time zones set.
3.DATETIME uses 8 bytes of storage and TIMESTAMP 4 bytes.Therefore, TIMESTAMP has a higher space utilization rate than DATETIME.
4.The default value of DATETIME is null; the field of TIMESTAMP is not null by default, and the default value is the current time (CURRENT_TIMESTAMP), which is updated to the current time by default if no special processing is done and the column's updated value is not specified in the update statement.
Differences between datatime and timestamp
4. Enumerations and collections
The value of a field can only be selected within a given range, such as a radio box or a multi-check box
enum enumeration: specify a range: this range can have more than one, but only one of the ranges can be used when passing values to this field
set collection: specifies a range that can have multiple ranges, but when passing values to the field, one or more of the ranges can be specified
enum If you do not pass a value, default is the first value, or NUll
----------Enumerations and Collections-----------
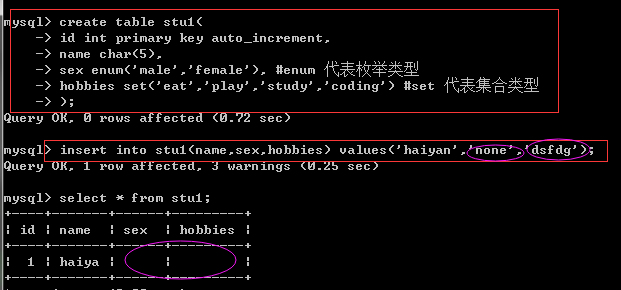
create table stu1(
id int primary key auto_increment,
name char(5),
sex enum('male','female'), #enum Represents an enumeration type
hobbies set('eat','play','study','coding') #set Represents a collection type
);
insert into stu1(name,sex,hobbies) values('haiyan','none','dsfdg');
select * from stu1; #If set sex Is the enumeration type, select one of the storage from the settings
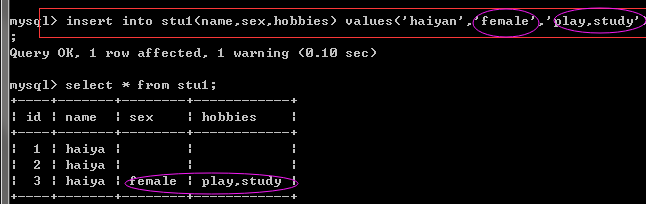
insert into stu1(name,sex,hobbies) values('haiyan','female','play,study');
select * from stu1; #If set hobbies Is a set type, you have to select one or more values from the set to store
No result of passing values as specified by enumeration or collection
Result of value transfer as specified by enumeration or set
2. Integrity Constraints
1. Introduction
Constraints are optional parameters as wide as the data type
Role: Used to ensure data integrity and consistency
It is mainly divided into:
PRIMARY KEY (PK) identifies the field as the primary key for the table and can uniquely identify records
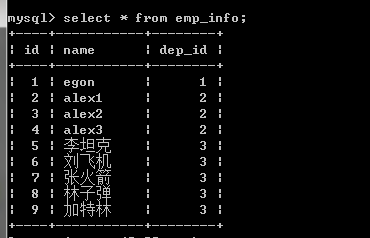
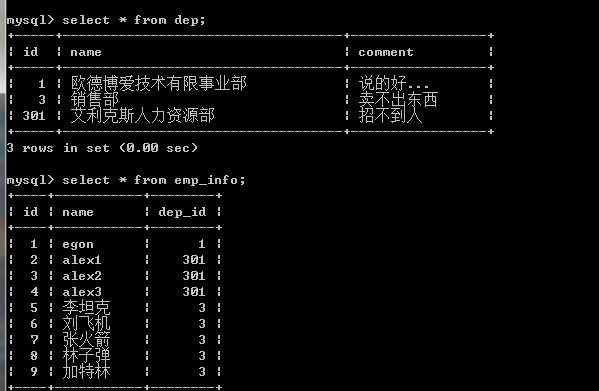
FOREIGN KEY (FK) identifies that the field is a foreign key to the table
NOT NULL identifies that the field cannot be empty
UNIQUE KEY (UK) identifies that the value of the field is unique
AUTO_INCREMENT identifies that the value of the field increases automatically (integer type, and primary key)
DEFAULT sets default values for this field
UNSIGNED unsigned
ZEROFILL is filled with 0
Explain:
1. Allow null, default NULL, NOT NULL can be set, field is not allowed null, must be assigned
2. Does the field have a default value? The default value is NULL. If you insert a record without assigning a value to the field, the field uses the default value
sex enum('male','female') not null default 'male'
age int unsigned NOT NULL default 20 must be positive (unsigned) null not allowed Default is 20
3. Is it a key?
primary key
foreign key
Index (index,unique...)
2.not null and default
Is it nullable, null means null, not a string
not null - not nullable
null - nullable
default value, which you can specify when creating columns default value is automatically added when inserting data if it is not actively set
create table t1(
id int not null defalut 2,
num int not null
)
3.unique Constraints (Uniqueness Constraints)
Single Column Unique
-----1.Single Column Unique---------
create table t2(
id int not null unique,
name char(10)
);
insert into t2 values(1,'egon');
insert into t2 values(1,'alex');
#When creating a table above id A unique constraint is set.Then inserting id=1,You'll make a mistake
Multi-Column Unique
-----2.Multi-Column Unique---------
#255.255.255.255
create table server(
id int primary key auto_increment,
name char(10),
host char(15), #Host ip
port int, #port
constraint host_port unique(host,port) #constraint host_port This is just the name used to set the unique constraint, or you can do it without setting the default
);
insert into server(name,host,port) values('ftp','192.168.20.11',8080);
insert into server(name,host,port) values('https','192.168.20.11',8081); #ip Unique with port
select * from server;
4.primary key (primary key constraint)
The value of the primary key field is not empty and unique
In a table, you can:
Single column as primary key
Multiple columns as primary keys (composite primary keys)
But there can only be one primary key in a table
============Single column as primary key===============
#Method 1: not null+unique
create table department1(
id int not null unique, #Primary key
name varchar(20) not null unique,
comment varchar(100)
);
mysql> desc department1;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | NO | UNI | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.01 sec)
#Method 2: Use after a field primary key
create table department2(
id int primary key, #Primary key
name varchar(20),
comment varchar(100)
);
mysql> desc department2;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.00 sec)
#Method 3: Define separately after all fields primary key
create table department3(
id int,
name varchar(20),
comment varchar(100),
constraint pk_name primary key(id); #Create and name the primary key pk_name
mysql> desc department3;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.01 sec)
Single column primary key