
preface
In learning data structures, we often come into contact with the term sorting, but when we learn, we may be at a loss when facing the code directly. Why do the interface use these parameters and why do we exchange them back and forth... We don't know what the authors think when implementing these interfaces, In this blog, I will gradually explain the thinking mode and implementation process of each sort through the concept of sorting, code analysis and code analysis, so as to really help you understand the implementation of sorting and let us not be at a loss when facing the code
sort
① Sorting concept
Sorting: the so-called sorting is the operation of arranging a string of records incrementally or decrementally according to the size of one or some keywords.
Stability: if there are multiple records with the same keyword in the record sequence to be sorted, the relative order of these records remains unchanged after sorting, that is, in the original sequence, r[i]=r[j], and r[i] is before r[j], while in the sorted sequence, r[i] is still before r[j], then this sorting algorithm is said to be stable; Otherwise, it is called unstable.
Internal sorting: sorting in which all data elements are placed in memory.
External sorting: there are too many data elements to be placed in memory at the same time. According to the requirements of the sorting process, the sorting of data cannot be moved between internal and external memory.
② Sorting application
In life, we often use sorting, price comparison when shopping, praise comparison when ordering takeout, sales volume, etc
1. Sorting and use when purchasing mobile phones
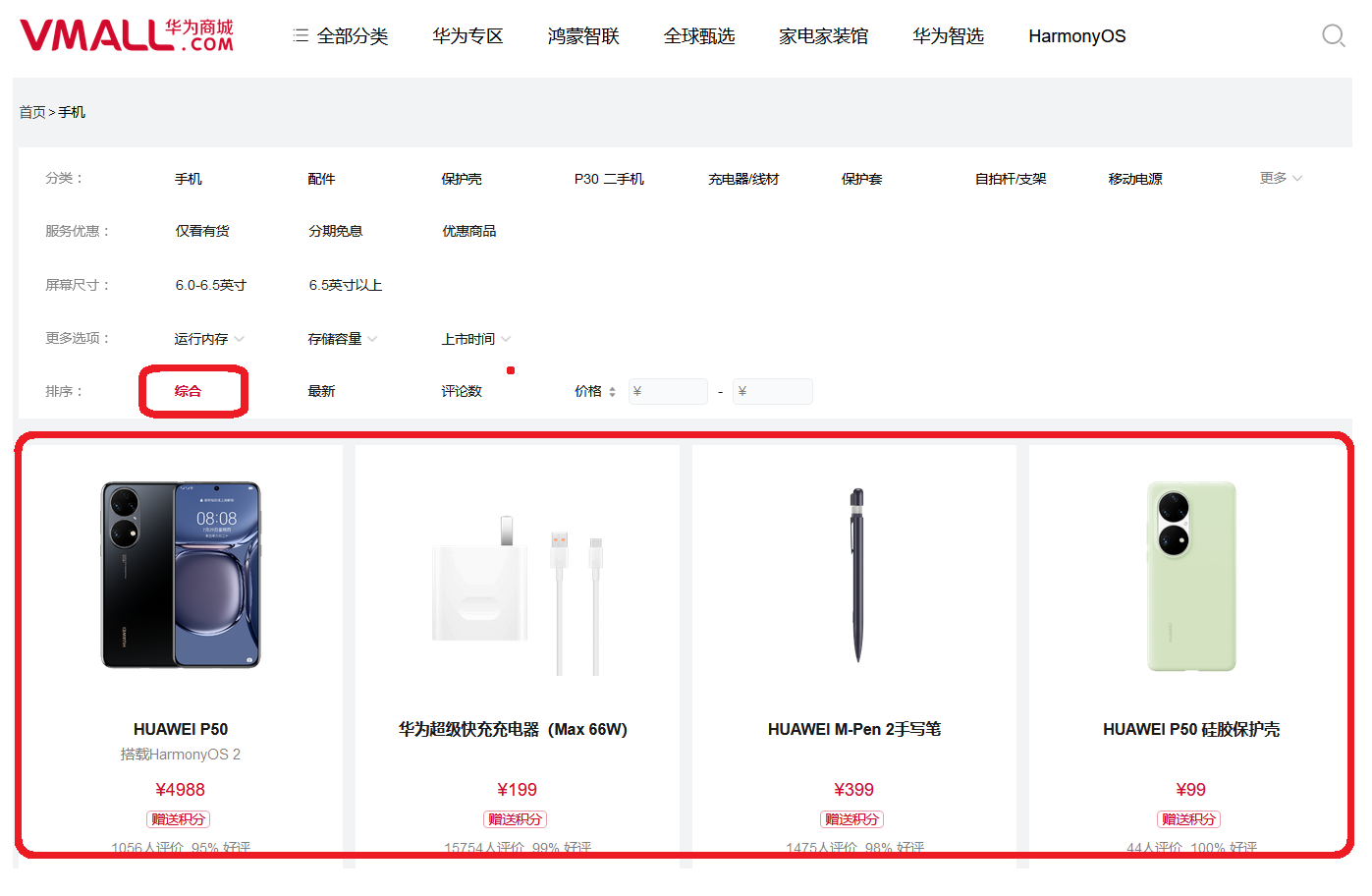
2. Sorting in takeout
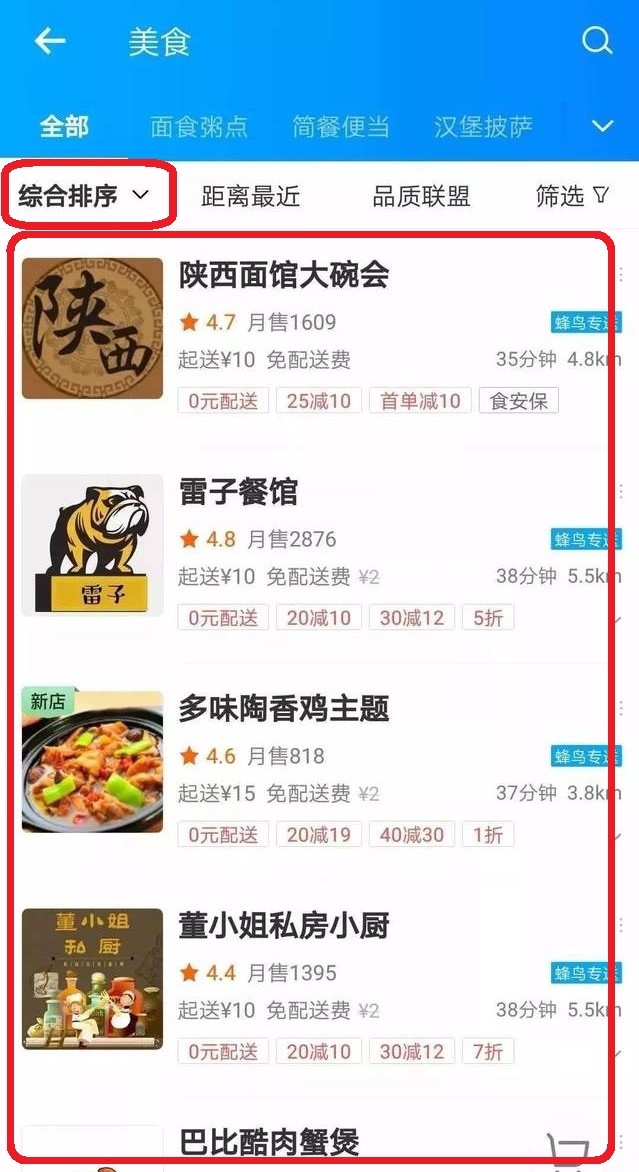
Insert sort
① Concept
Insert the records to be sorted into an ordered sequence one by one according to the size of their key values, until all records are inserted, and a new ordered sequence is obtained.
② Analysis
When we look at the concept, we may still not understand what it means. Here are some examples in life:
When we are playing poker, we will keep grasping cards, and the process of grasping cards is our insertion sorting. First, we will catch our first card, and we default that our current cards are in order; When we catch a new card, we have to insert this new card into the cards that have been ordered before, so that our card group is still orderly, so as to go back and forth until we touch the card. At the same time, the cards in our hands are still sorted from small to large.

③ Code analysis
Through the above analysis, we know the results to be achieved by the code. First, we need to process a data, which is composed of two parts. One part is an ordered array, and the other part is an element to be inserted into our current ordered array. Through our analysis, we can see that the first element in the array is actually regarded as processing data. We order it through our insertion sorting code, and then treat the first two elements as processing data, increasing in turn. The first three elements and the first four elements... Until all elements are processing data.
Then we execute our sorting insertion code on these processing data one by one to realize that the ordered arrangement is still orderly after inserting elements. How should we realize our ordered sorting?
We first analyze the process through the following diagram:

At this time, we know how to implement this process, so how should we write the code? We can start with a trip here, and then we're thinking about the process of circulation
Let's write the code for inserting sorting first:
void InsertSort(int*a, int n)
{
int end = ? ;//Because we don't know the position of our end coordinate at this time, we use? Instead, we modify it in the loop
int tmp = a[end + 1];//Here, we will save the element to be inserted first, because our subsequent code will overwrite the element at this position
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
//a[end+1] = tmp;
break;
}
}
a[end + 1] = tmp;//Here we consider a variety of situations: ① when the number we want to insert is always smaller than the number of our ordered sequence, we put it in the position of end+1; ② Normally, we also put it in the position of end+1
}
Now we just need to consider the size of end to realize our insertion sorting code. Now let's analyze the size value of end
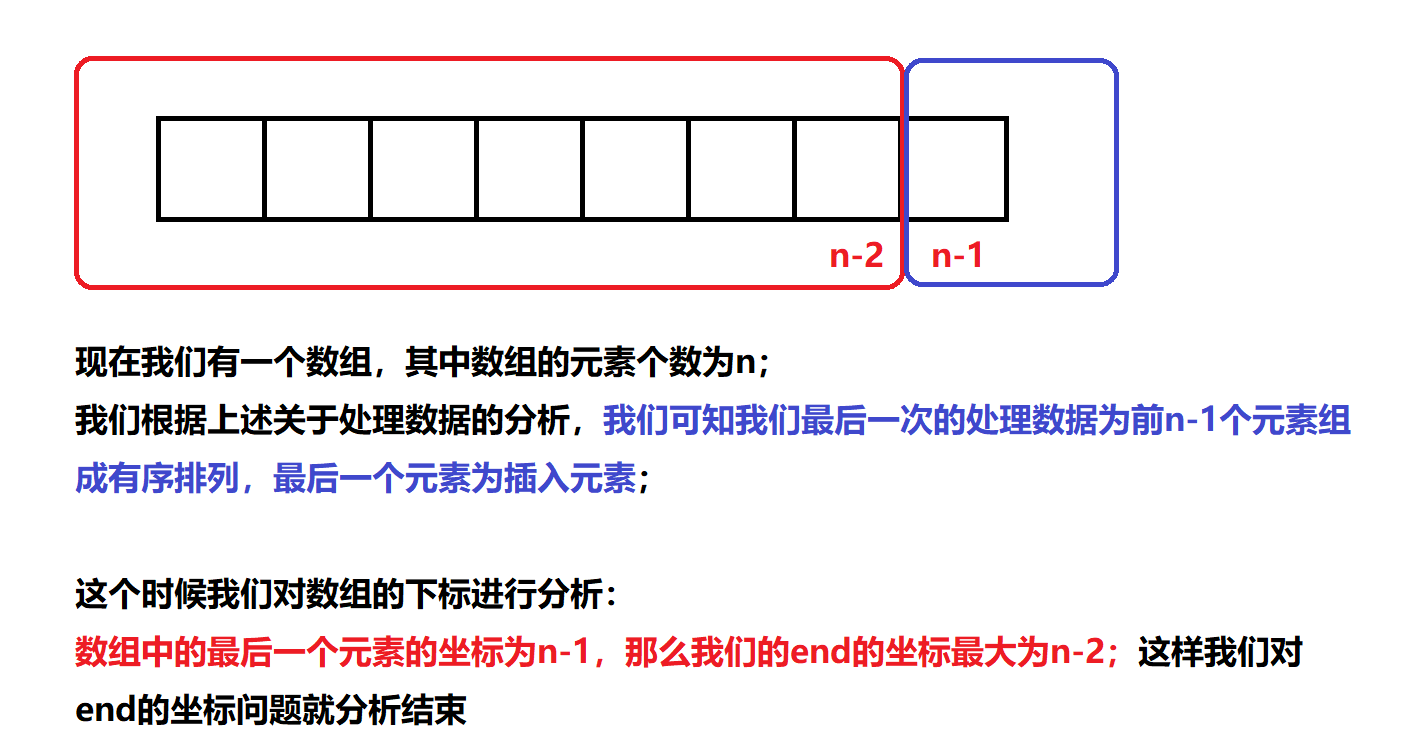
Through the above analysis, we can get the complete code
void InsertSort(int*a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
④ Code check
Sort.h
#include<stdio.h> #include<stdlib.h> void InsertSort(int* a, int n); void PrintArray(int*a, int n); void InsertTest();
Sort.c
#include"Sort.h"
void InsertSort(int*a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
void PrintArray(int*a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ",a[i]);
}
printf("\n");
}
void InsertTest()
{
int a[] = { 54, 38, 96, 23, 15, 72, 60, 45, 83 };
int size = sizeof(a) / sizeof(int);
PrintArray(a, size);
InsertSort(a, size);
PrintArray(a, size);
}
test.c
#include"Sort.h"
int main()
{
InsertTest();
return 0;
}
When we execute the code, the result of compilation execution is
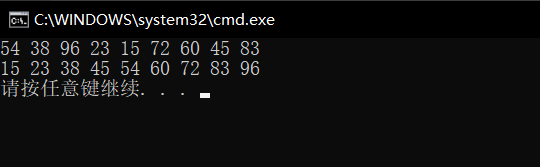
This shows that our analysis idea and code writing are correct
⑤ Advantages and disadvantages of inserting sorting
Now we analyze the time complexity of insertion sorting. We can conclude that the time complexity of insertion sorting depends on our processing data. When our processing data is in reverse order, our time complexity is O(N^2); When our processing data is in order or close to order, our time complexity is O(N)
Note that the advantages and disadvantages of insertion sorting are: the time complexity depends on the sorting degree of the processed data. If the data we process is relatively close to the orderly arrangement at the beginning, our time complexity can be greatly reduced when we perform insertion sorting at this time, So can we sort the data before insertion sort, so that the processed data can be arranged in order?
Shell Sort
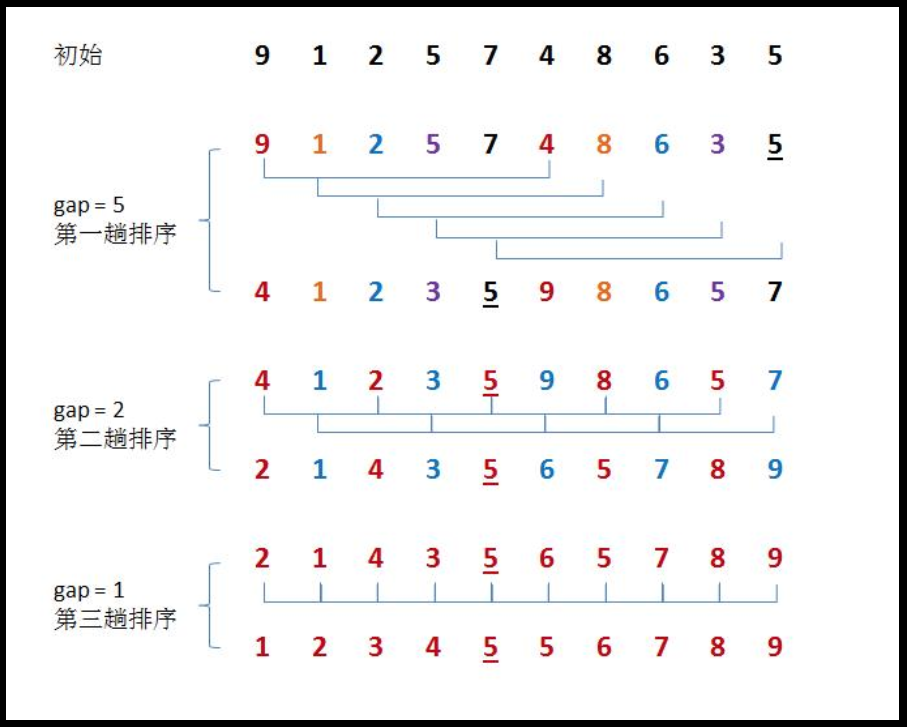
① Concept
Hill ranking method is also known as reduced incremental method. The basic idea of hill sorting method is to select an integer first, divide all records in the file to be sorted into groups, divide all records with distance into the same group, and sort the records in each group. Then, take and repeat the above grouping and sorting. When arrival = 1, all records are arranged in a unified group.
② Analysis
When we read the above concepts for the first time, we may not understand what we are talking about. Let's make a simple analysis through the following diagram to explain the operation steps of hill sorting
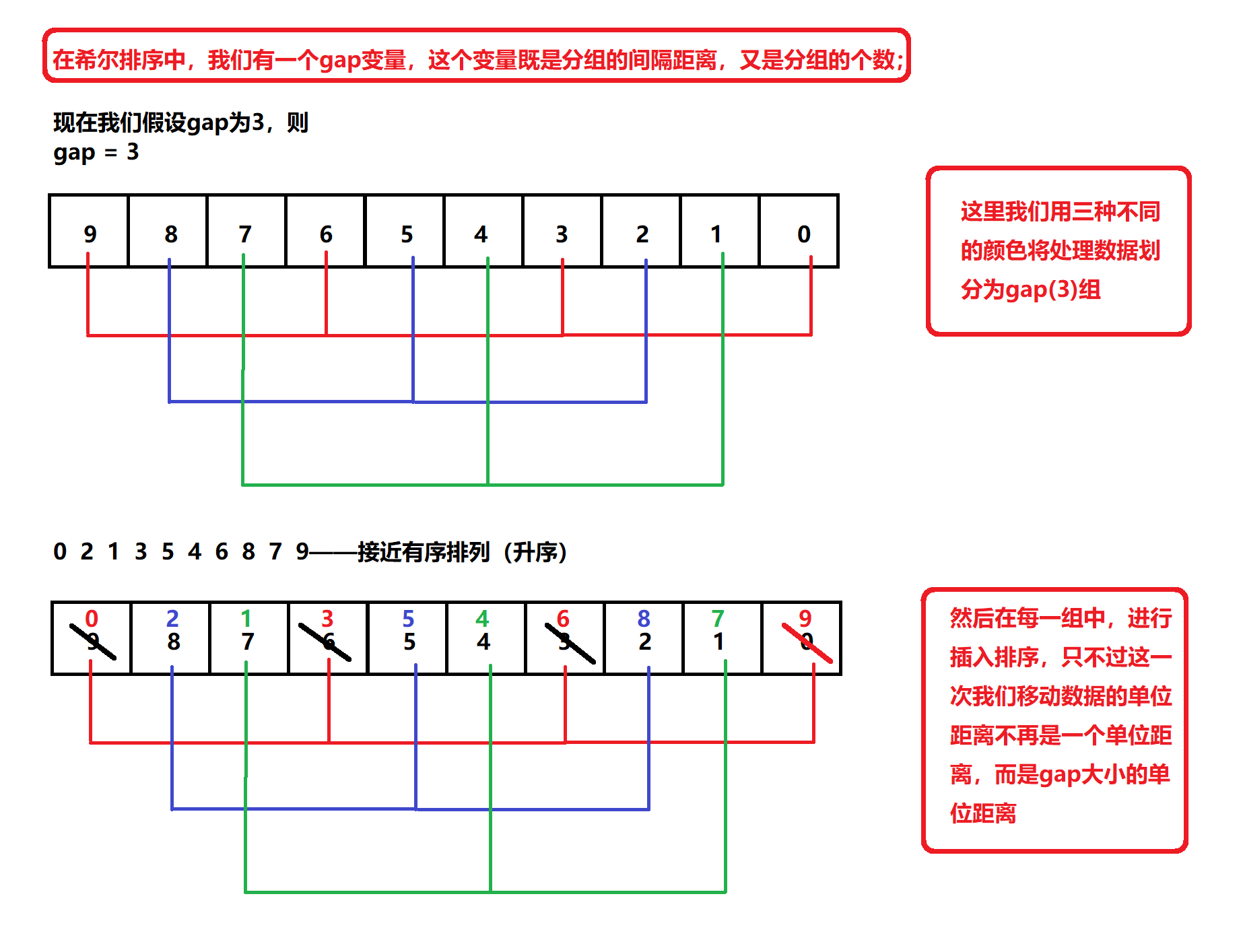 Through the above graphical analysis, we know that when we perform Hill sorting on the processed data, our processed data changes from disorder at the beginning to more order. At this time, we think, if we perform Hill sorting again, will the processed data be more orderly than the last time? But at this time, we found that if the value of our gap does not change, the data will not change after Hill sorting again, so we need to change the value of our gap. At this time, we associate with our insertion sorting. We can think that if our gap value is large, The larger the unit distance of our data movement, the lower the order of our processing data. On the contrary, if we want to sort our insertion, the element movement distance each time is a unit distance. At this time, we get the ordered arrangement
Through the above graphical analysis, we know that when we perform Hill sorting on the processed data, our processed data changes from disorder at the beginning to more order. At this time, we think, if we perform Hill sorting again, will the processed data be more orderly than the last time? But at this time, we found that if the value of our gap does not change, the data will not change after Hill sorting again, so we need to change the value of our gap. At this time, we associate with our insertion sorting. We can think that if our gap value is large, The larger the unit distance of our data movement, the lower the order of our processing data. On the contrary, if we want to sort our insertion, the element movement distance each time is a unit distance. At this time, we get the ordered arrangement

③ Code analysis
Through the above analysis, we know that our Hill sorting method is to perform insertion sorting with gap moving unit distance for many times, and our gap will decrease after each Hill sorting. After many times, our processing data will change from disordered to ordered
At this time, we know how to implement this process, so how should we write the code? We can start with a trip here, and then we can consider the problem of reducing our gap step by step in the process of circulation
void ShellSort(int* a, int n)
{
int gap = 3;//Here we assume that our gap is 3
for (int i = 0; i < n - gap; i++)
{
int end = i ;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
Analysis of code statements
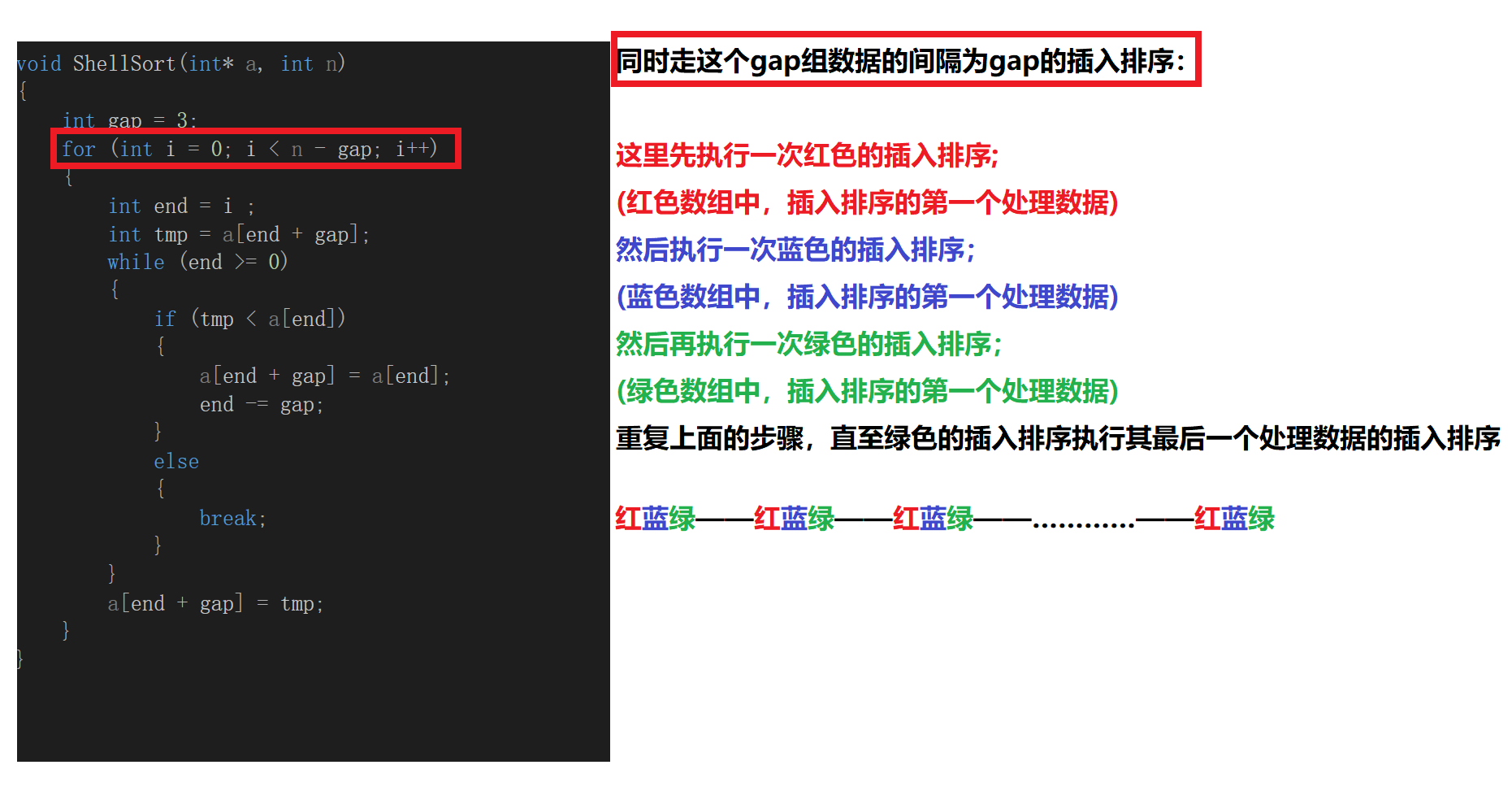
Now we get the code executed in one trip, which is actually our insertion sorting. However, the distance we move each time is no longer the unit distance, but the distance with the size of gap. At this time, we should consider, what should the size of our gap be?
Here, the official suggestion on the size of gap in Hill sort is to add gap data / 3 every time, because it is more efficient to process data. We know that if we do not reduce gap in our Hill sort to 1 when performing Hill sort, that is, if we finally do not perform insert sort, our processing data will never become ordered, Forever is only infinitely close to an orderly arrangement, but not an orderly arrangement
After these analyses, we can get our code
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//Here we can ensure that the value of our last gap is 1, so that we can perform insertion sorting for the last time
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
④ Code check
sort.h
#include<stdio.h> #include<stdlib.h> void PrintArray(int* a, int n); void ShellSort(int* a, int n); void ShellTest();
sort.c
#include"Sort.h"
void PrintArray(int*a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ",a[i]);
}
printf("\n");
}
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
void ShellTest()
{
int a[] = { 54, 38, 96, 23, 15, 72, 60, 45, 83 };
int size = sizeof(a) / sizeof(int);
PrintArray(a, size);
ShellSort(a, size);
PrintArray(a, size);
}
test.c
#include"Sort.h"
int main()
{
ShellTest();
return 0;
}
When we execute the code, the result of compilation execution is
This shows that our analysis idea and code writing are correct
Find sort (select sort)
① Concept
Each time, the smallest (or largest) element is selected from the data elements to be sorted and stored at the beginning of the sequence until all the data elements to be sorted are arranged.
② Analysis
The search sort is much simpler than the first two sorts. Here we will briefly describe the process described above. Here we will first analyze the concepts described above:
The above concept explains that each time we select the maximum or minimum value in the current processing data, and then we exchange and traverse the processing data to finally realize sorting and arrangement. Then we can upgrade this process. We find the maximum and minimum values in the current processing data every time, Then we exchange them with the last element and the first element respectively, narrow our search range, and then repeat the above steps to finally realize our orderly arrangement, so that our efficiency can be higher
③ Code analysis
Now let's analyze the implementation of our code
According to the above contents, we need to create two flags to record the header element and tail element of our processing data respectively. Here, we use begin and end tags; Then, after each pair of arrays is traversed, we will exchange the maximum value and tail element, and the minimum value and head element we find in this trip. Then, we need to reduce our next search range, so our must execute: begin + +; end–; Then we repeat the above steps, and finally realize the orderly arrangement of the processed data
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin <= end)
{
int mini = begin;
int maxi = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;//Record the subscript of our minimum value
}
if (a[i] > a[maxi])
{
maxi = i;//The subscript that records our maximum
}
}
Swap(&a[mini], &a[begin]);
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}
④ Code check
sort.h
#include<stdio.h> #include<stdlib.h> void PrintArray(int* a, int n); void SelectSort(int* a, int n); void SelectTest();
sort.c
#include"Sort.h"
void PrintArray(int*a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ",a[i]);
}
printf("\n");
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin <= end)
{
int mini = begin;
int maxi = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[mini], &a[begin]);
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}
void SelectTest()
{
int a[] = { 54, 38, 96, 23, 15, 72, 60, 45, 83 };
int size = sizeof(a) / sizeof(int);
PrintArray(a, size);
SelectSort(a, size);
PrintArray(a, size);
}
test.c
#include"Sort.h"
int main()
{
SelectTest();
return 0;
}
When we execute the code, the result of compilation execution is
The current execution results show that our analysis ideas and code writing are correct;
Is that really right?
Now let's change a set of processing data for inspection
int a[] = { 154, 38, 96, 23, 15, 72, 60, 45, 83 };
When we execute the code, the result of compilation execution is
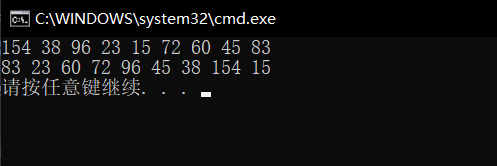
Here, we find that our execution results do not achieve the ordered arrangement we want. At this time, we draw and analyze and find that:
 Then we need to modify the code, so we can judge the subscript:
Then we need to modify the code, so we can judge the subscript:
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin <= end)
{
int mini = begin;
int maxi = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[mini], &a[begin]);
if (begin == maxi)
{
maxi = mini;
}
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}
In this way, we can avoid exchange failure
Heap sort
We explained about heap sorting in the previous blog
Blog address: https://blog.csdn.net/weixin_52664715/article/details/120463777?spm=1001.2014.3001.5501
Here we will give another brief explanation:
① Concept
Heap sort is a sort algorithm designed by using the data structure of heap tree (heap). It is a kind of selective sort. It selects data through the heap.
② Analysis
When we perform heap sorting, our processing data is a random array. Now we need to process this array into a large number (the ordered sorting we explain here is ascending by default)
So how do we handle a random array into a lot? Here, we first find our last subtree, that is, the subtree where the last element in our array is located. We adjust the subtree down to make the subtree into a lot, then regard the parent node of the subtree as our traversal flag, and subtract the parent node one by one until our parent node exceeds the range of our array (parent node < 0);
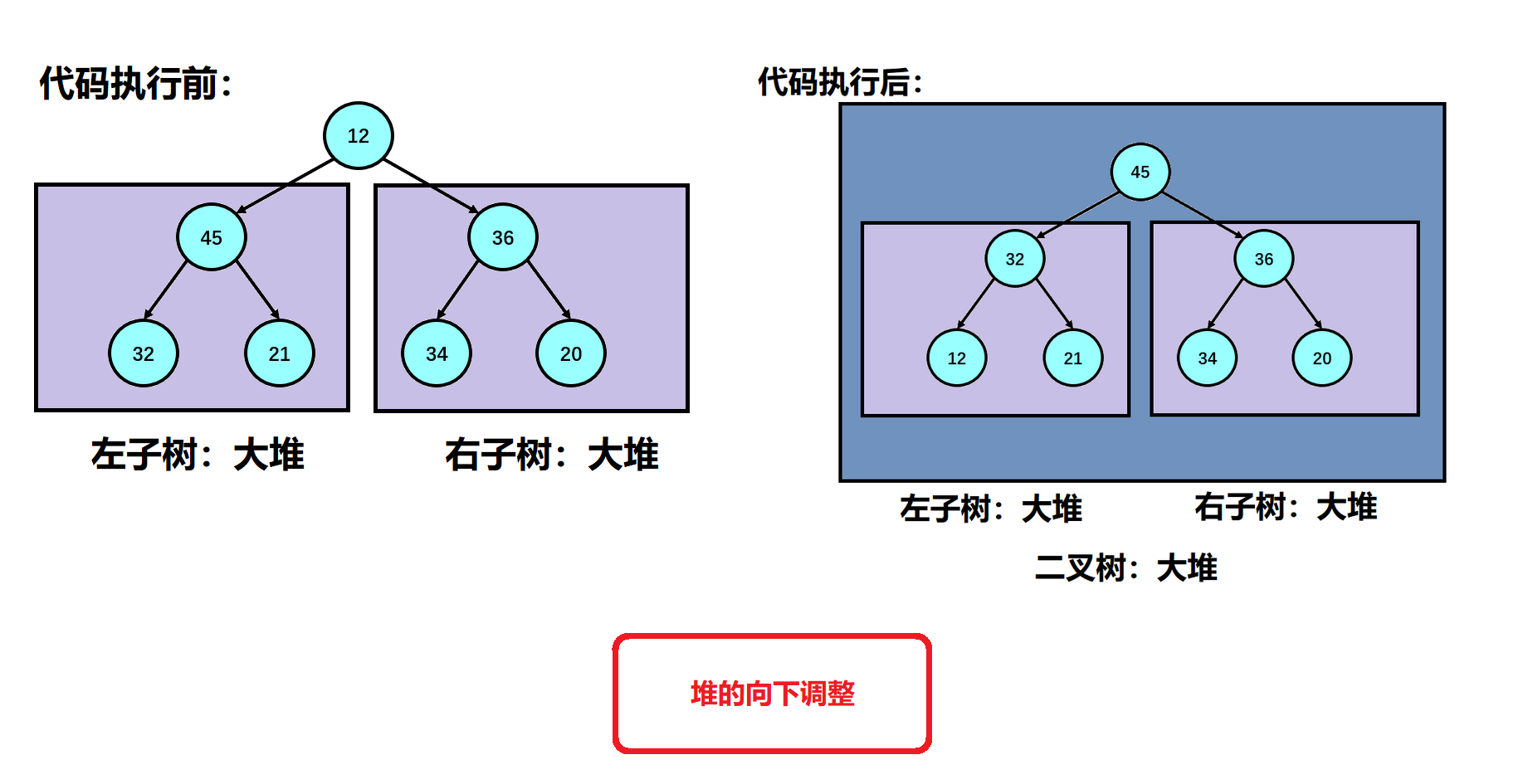
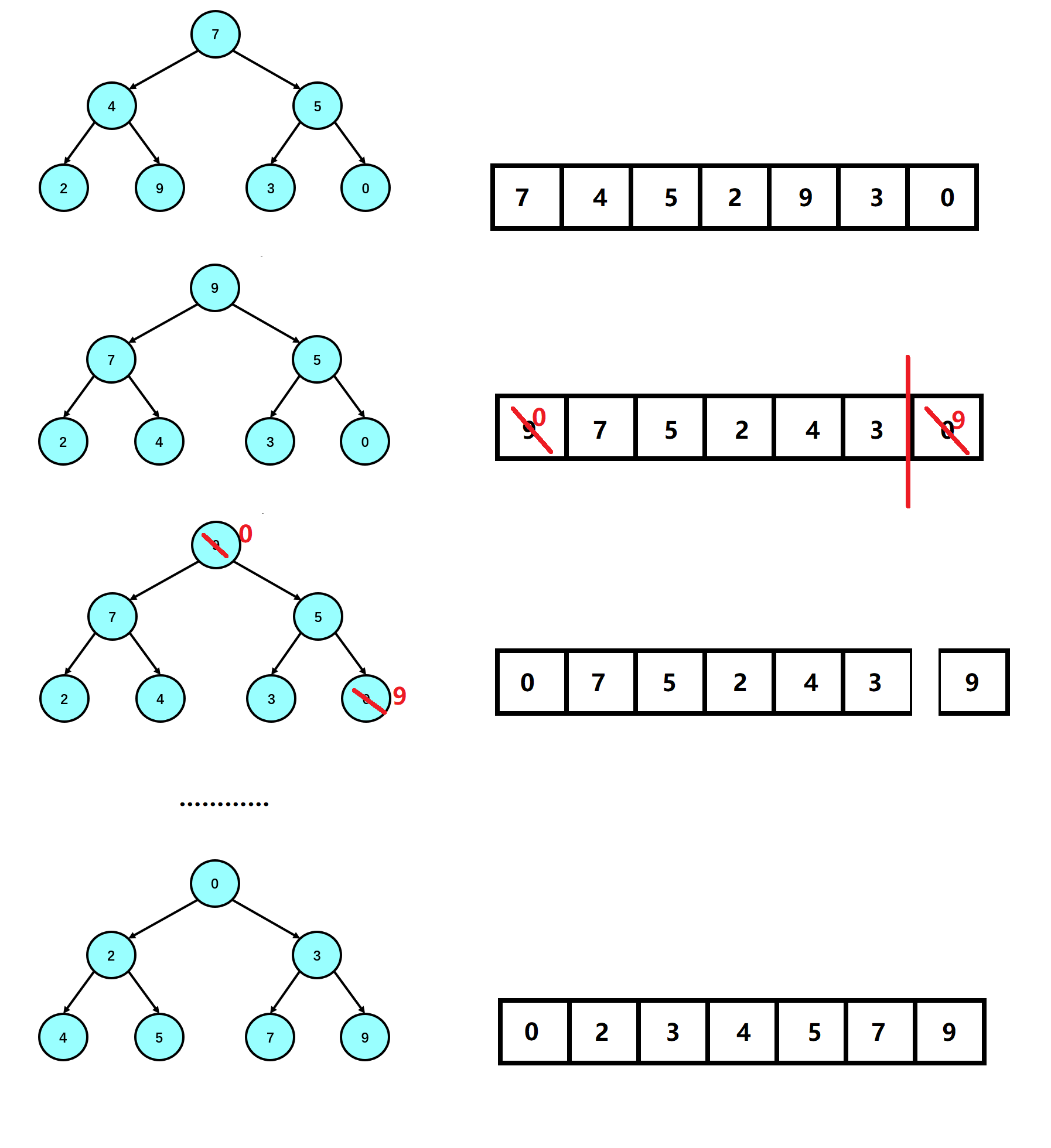
The implementation of heap downward adjustment is briefly described here: we first default that the left node of the root node in the parameter is the larger element in the two subtrees, and then we judge whether the right subtree node exists. If it exists, we also judge whether the right subtree node is large or the left subtree node is large. If the conditions are met at the same time, we mark the child to the right subtree; At this time, we are judging the size of the parent node and the child node. When our child node is larger than our parent node, we exchange the child node with the parent node, and change the subscripts of the child node and the parent node at the same time; Then repeat the above steps until the child node crosses our array range when we adjust downward. At this time, we end the adjustment downward, and the random array is a lot in the logical structure;
After the above operations, our unordered array is a lot in the logical structure. Now we need to change this lot into an orderly arrangement (ascending order). At this time, we exchange the vertex of the heap, that is, our root node, with the last node in our array (the last leaf node in the heap), At this time, except for the exchanged elements, the data we have left is the special case we are explaining in the downward adjustment of the heap. The left and right subtrees of the root node are a lot. At this time, we sort the processing data down the heap to turn our array into a lot. At this time, we reduce the length of the array by one, Repeat the above operation, so that when our loop ends, we can change the processing data array into ascending order;
③ Code analysis
We illustrate the implementation of various interfaces:
1. Downward adjustment of reactor:
2. Establishment of reactor
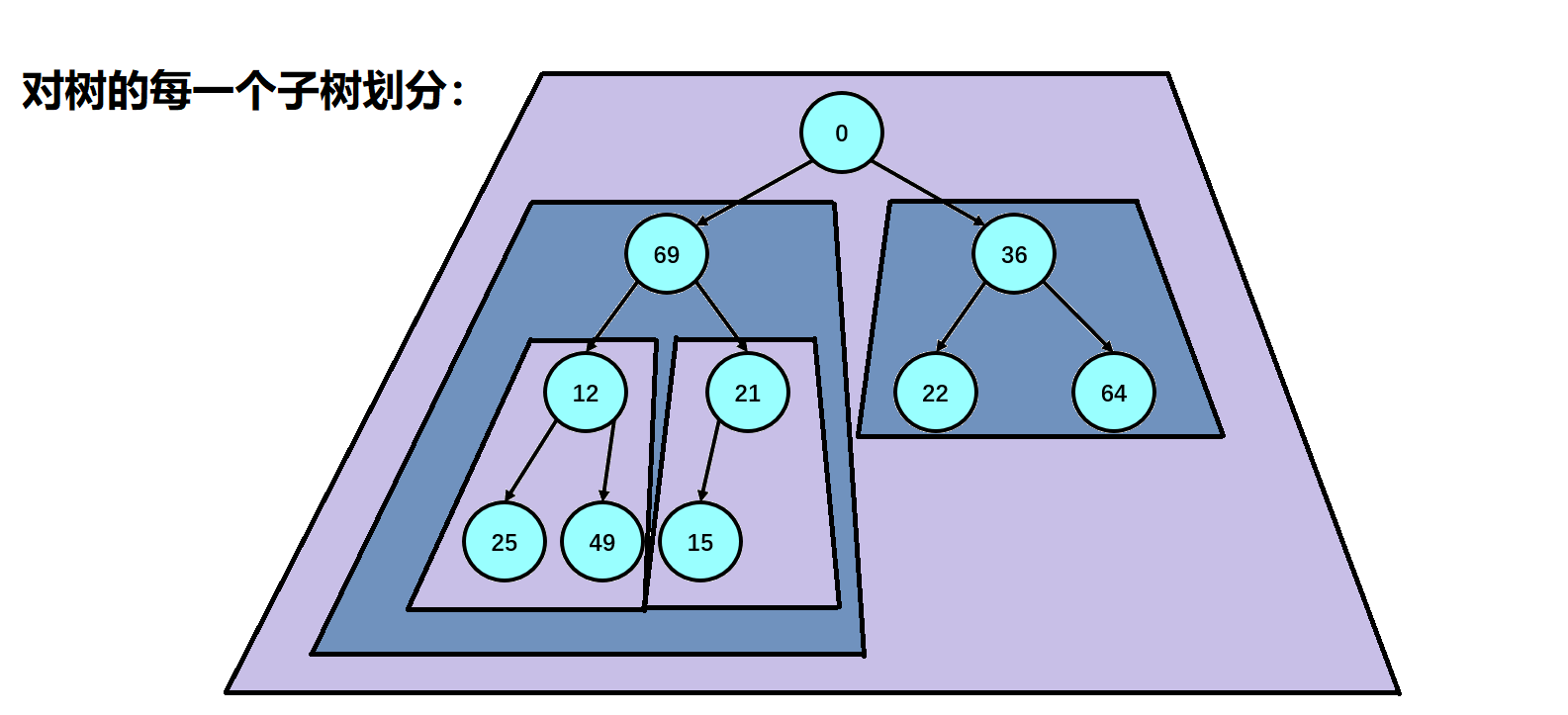

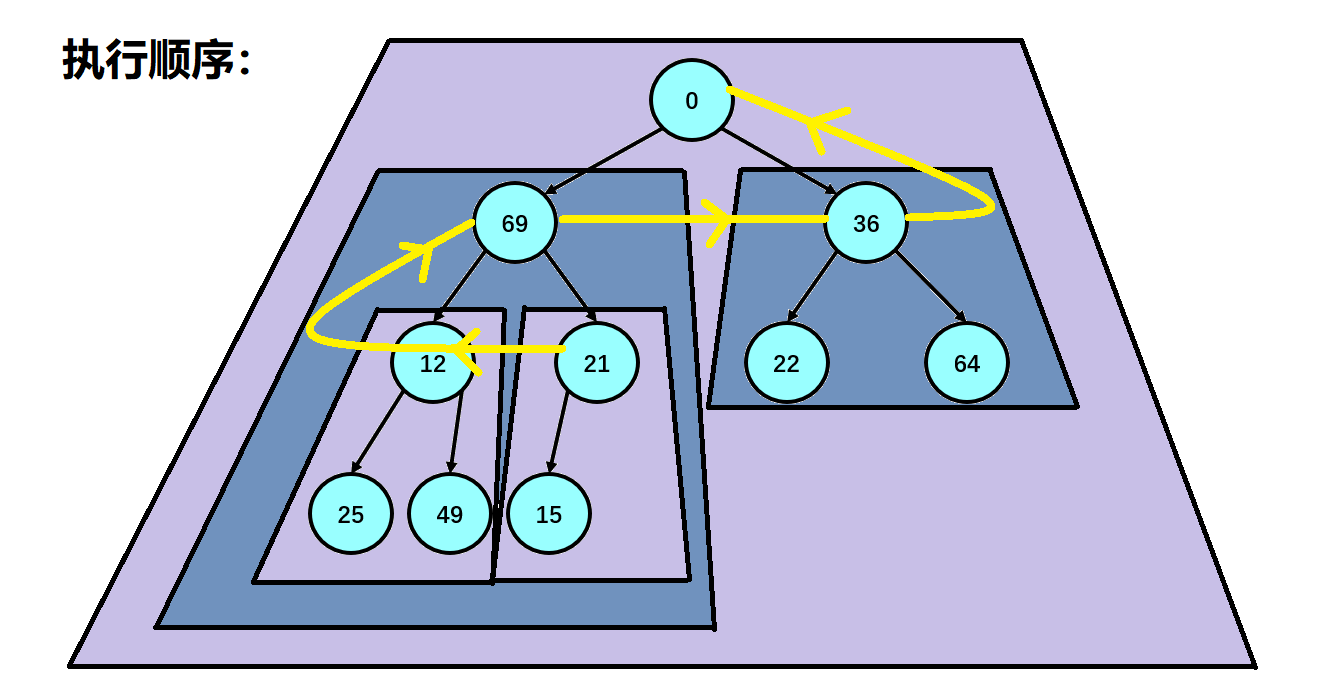
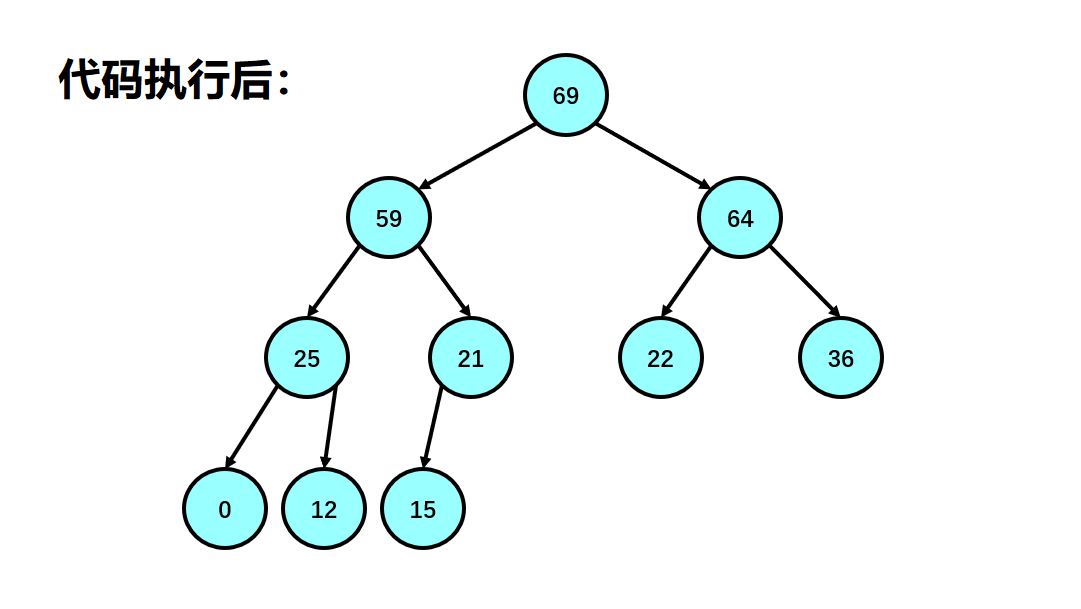
3. Heap sorting:
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void AdjustDown(int* a, int n, int parent)//a is our array; n is the number of elements of our array; parent is the coordinate of our root node
{
int child = parent * 2 + 1;
while (child < n)
{
//If (a [child + 1] < n & & A [child + 1] > a [child]) / / judge whether our tree contains a right subtree; Because we previously default that the left subtree is the larger of the left and right subtrees;
if (child + 1< n && a[child + 1] > a[child])//Judge whether our tree contains right subtree; Because we previously default that the left subtree is the larger of the left and right subtrees;
{
child++;//At this time, we determine the existence of right subtree, and we truly determine the larger trees in the left and right subtrees as right subtrees
}
if (a[child] > a[parent])//At this time, if our child is larger than our parent node, we exchange
{
Swap(&a[child], &a[parent]);//After the exchange, the current tree is normal, which is called a tree in the heap. When its left and right subtrees are destroyed, we need to repeat the above content for its left and right subtrees to rebuild the heap
parent = child;
child = parent * 2 + 1;
}
else
{
break;//When our child is younger than our parent node, we say our heap is OK
}
}
}
//Now we are going to program the code for heap sorting. Let's analyze it:
void HeapSort(int* a, int n)//Here n is the number of our arrays
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
//At this time, we will first build a random array into a pile;
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
④ Code check
sort.h
#include<stdio.h> #include<stdlib.h> void HeapSort(int* a, int n); void AdjustDown(int* a, int n, int parent); void HeapTest();
sort.c
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void AdjustDown(int* a, int n, int parent)//a is our array; n is the number of elements of our array; parent is the coordinate of our root node
{
int child = parent * 2 + 1;
while (child < n)
{
//If (a [child + 1] < n & & A [child + 1] > a [child]) / / judge whether our tree contains a right subtree; Because we previously default that the left subtree is the larger of the left and right subtrees;
if (child + 1< n && a[child + 1] > a[child])//Judge whether our tree contains right subtree; Because we previously default that the left subtree is the larger of the left and right subtrees;
{
child++;//At this time, we determine the existence of right subtree, and we truly determine the larger trees in the left and right subtrees as right subtrees
}
if (a[child] > a[parent])//At this time, if our child is larger than our parent node, we exchange
{
Swap(&a[child], &a[parent]);//After the exchange, the current tree is normal, which is called a tree in the heap. When its left and right subtrees are destroyed, we need to repeat the above content for its left and right subtrees to rebuild the heap
parent = child;
child = parent * 2 + 1;
}
else
{
break;//When our child is younger than our parent node, we say our heap is OK
}
}
}
//Now we are going to program the code for heap sorting. Let's analyze it:
void HeapSort(int* a, int n)//Here n is the number of our arrays
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
//At this time, we will first build a random array into a pile;
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
void HeapTest()
{
int a[] = { 54, 38, 96, 23, 15, 72, 60, 45, 83 };
int size = sizeof(a) / sizeof(int);
PrintArray(a, size);
HeapSort(a, size);//Here n is the number of our values
PrintArray(a, size);
}
test.c
#include"Sort.h"
int main()
{
HeapTest();
return 0;
}
When we execute the code, the result of compilation execution is
This shows that our analysis idea and code writing are correct
Bubble sorting
We learned and explained the content of bubble sorting in the early stage of learning C language, so we won't repeat it here
void BubbleSort(int* a, int n)
{
for (int j = 0; j < n; j--)//In this loop, we control where the maximum value is stored after we exchange
{
for (int i = 1; i < n - j; i++)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
}
}
}
}
We make a simple optimization for bubble sorting
void BubbleSort(int* a, int n)//Optimization of bubble sorting:
{
for (int j = 0; j < n; j++)
{
int exchange = 0;
for (int i = 1; i < n - j; i++)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
{
break;
}
}
}
Quick sort
① Concept
Quick sort is an exchange sort method of binary tree structure proposed by Hoare in 1962. Its basic idea is: any element in the element sequence to be sorted is taken as the reference value, and the set to be sorted is divided into two subsequences according to the sort code. All elements in the left subsequence are less than the reference value, and all elements in the right subsequence are greater than the reference value, Then the leftmost and leftmost subsequences repeat the process until all elements are arranged in the corresponding positions.
② Analysis
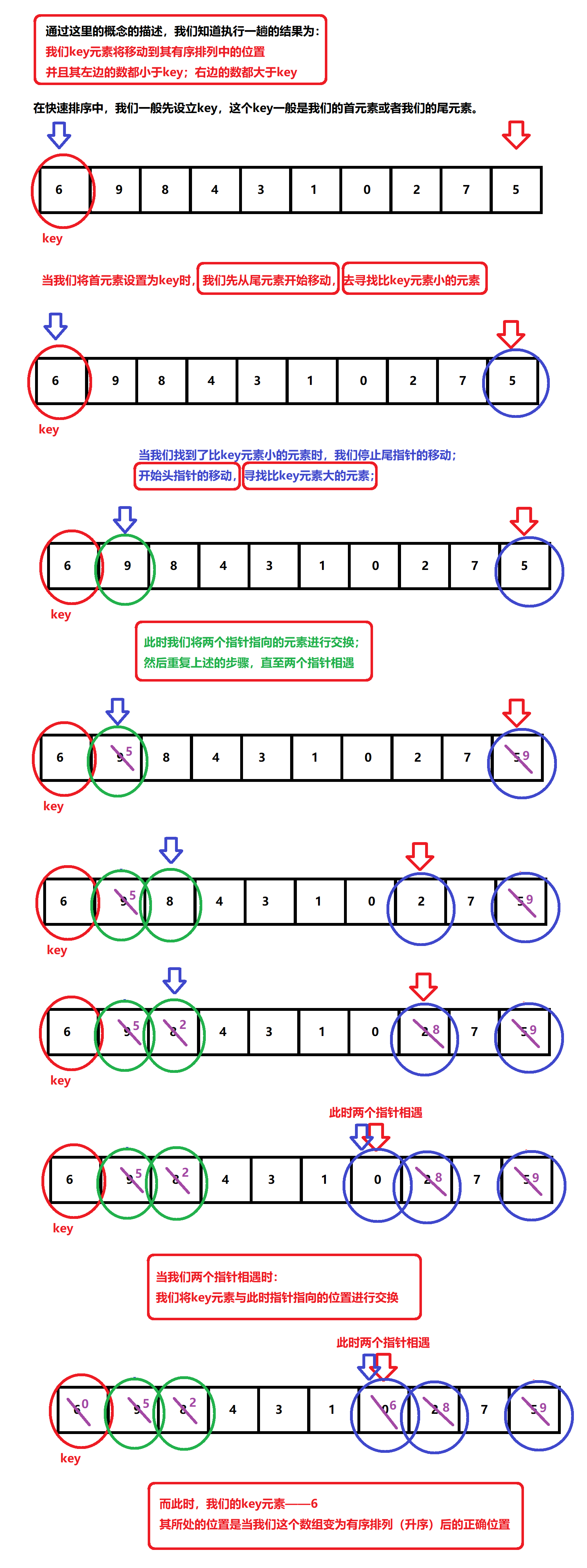
If we look directly at the definition of quick sort, it may not be easy to understand. Here I will briefly describe the above content. When we perform quick sort, we first define a number as the element we want to sort. After we perform a quick sort, The element will move to its correct position after the array changes from random array to ordered array. At the same time, when it reaches the correct position, the elements on the left of the element are smaller than it, and the elements on the right of the element are larger than it.
Now let's analyze the execution process of a quick sort by illustration:
③ Code analysis
Now that we know the execution process of quick sort, let's analyze the code execution:
We now know that we need to determine the key value in each trip, so we need to define it in the program. Secondly, we create two pointers to the first and last elements of our array respectively, and then we begin to shrink the range of our array
When our determined key element is our first element, we start to move from the right pointer, and then start to judge the size relationship between the current element and the key element. When the element pointed to by the pointer is larger than our key element, the pointer moves forward to narrow our array range. When the element pointed to by the pointer is smaller than our key element, the pointer stops moving; We start to move our left pointer. When the element pointed to by the pointer is smaller than our key element, the pointer moves back to narrow the range of our array. When the element pointed to by the pointer is larger than our key element, the pointer stops moving; At this point, we exchange the elements pointed to by our two pointers
After the exchange, we continue to repeat the above contents until the left pointer and the right pointer meet. When our two pointers meet, we exchange the elements marked by our key with the elements met at this time, and the key elements reach the correct sorting position
void PartSort(int* a, int left, int right)//Now we write the execution method of one-time sorting
{
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//At this time, there is no difference between left exchange and right exchange, because now the two pointers point to the same element
}
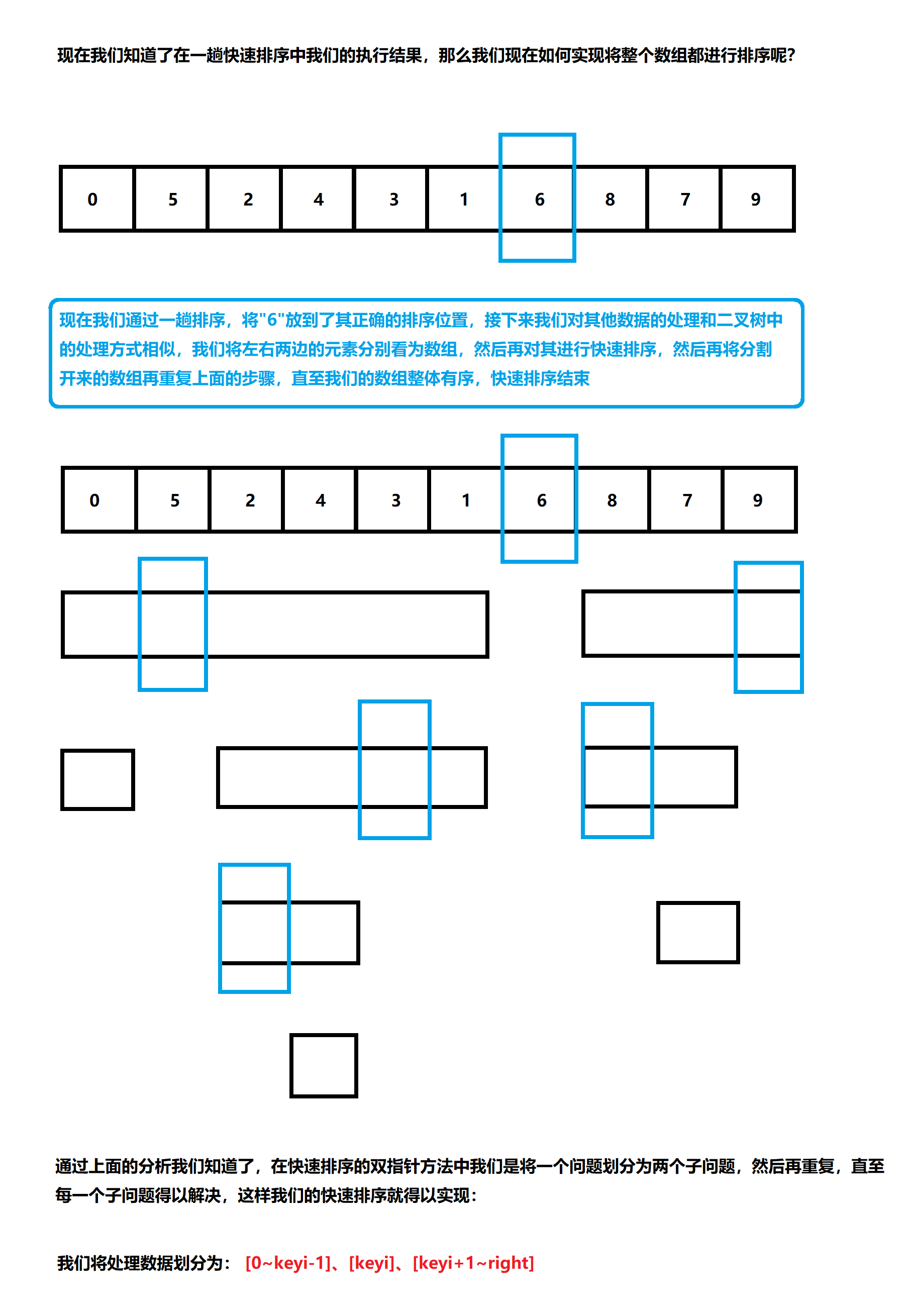
Now that we have realized the correct position after sorting the key element in one trip, how should we move the remaining elements?
At this time, we are looking at the analysis in ②. One content is:
 After performing a quick sort, the number of elements on the left of the key element is less than that of the key element, and the number on the right is greater than that of the key element
After performing a quick sort, the number of elements on the left of the key element is less than that of the key element, and the number on the right is greater than that of the key element
At this time, we may think of our idea when dealing with binary tree - divide and conquer. It is the same here. In the first trip, we moved the key element to the correct position after its sorting, and at this time, the left and right sides of the key element form an array, The positions of these elements after quick sorting are respectively in the array composed of the elements on the left and the array composed of the elements on the right of the key element. There will be no cross-border problem when the elements move after moving. In this way, we only need to divide the array after each quick sort. Through recursion, we can change the whole random array into an ordered array to achieve the purpose of sorting.
int PartSort(int* a, int left, int right)//Now we write the execution method of one-time sorting
{
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//At this time, there is no difference between left exchange and right exchange, because now the two pointers point to the same element
return left;//At this time, the value of our initial keyi subscript is stored in the position with the subscript left or right. Now we return the coordinates of keyi after we exchange, that is, keyi
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
④ Code check
sort.h
#include<stdio.h> #include<stdlib.h> void QuickSortTest(); void QuickSort(int* a, int left, int right); int PartSort(int* a, int left, int right);
sort.c
#include"Sort.h"
int PartSort(int* a, int left, int right)//Now we write the execution method of one-time sorting
{
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//At this time, there is no difference between left exchange and right exchange, because now the two pointers point to the same element
return left;//At this time, the value of our initial keyi subscript is stored in the position with the subscript left or right. Now we return the coordinates of keyi after we exchange, that is, keyi
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
void QuickSortTest()
{
int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
QuickSort(a, 0, sizeof(a) / sizeof(int)-1);
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
QuickSortTest();
return 0;
}
When we execute the code, the result of compilation execution is
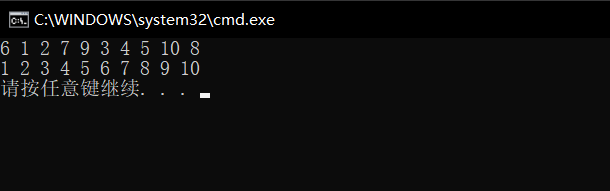
This shows that our analysis idea and code writing are correct
⑤ Code improvements 1
Now we have realized the execution of quick sort, but we think about a special case. If the array we want to deal with is already ordered sort, then every time we execute quick sort becomes insert sort. In this case, the time complexity is too high. Is there any way we can improve our quick sort to avoid this situation?
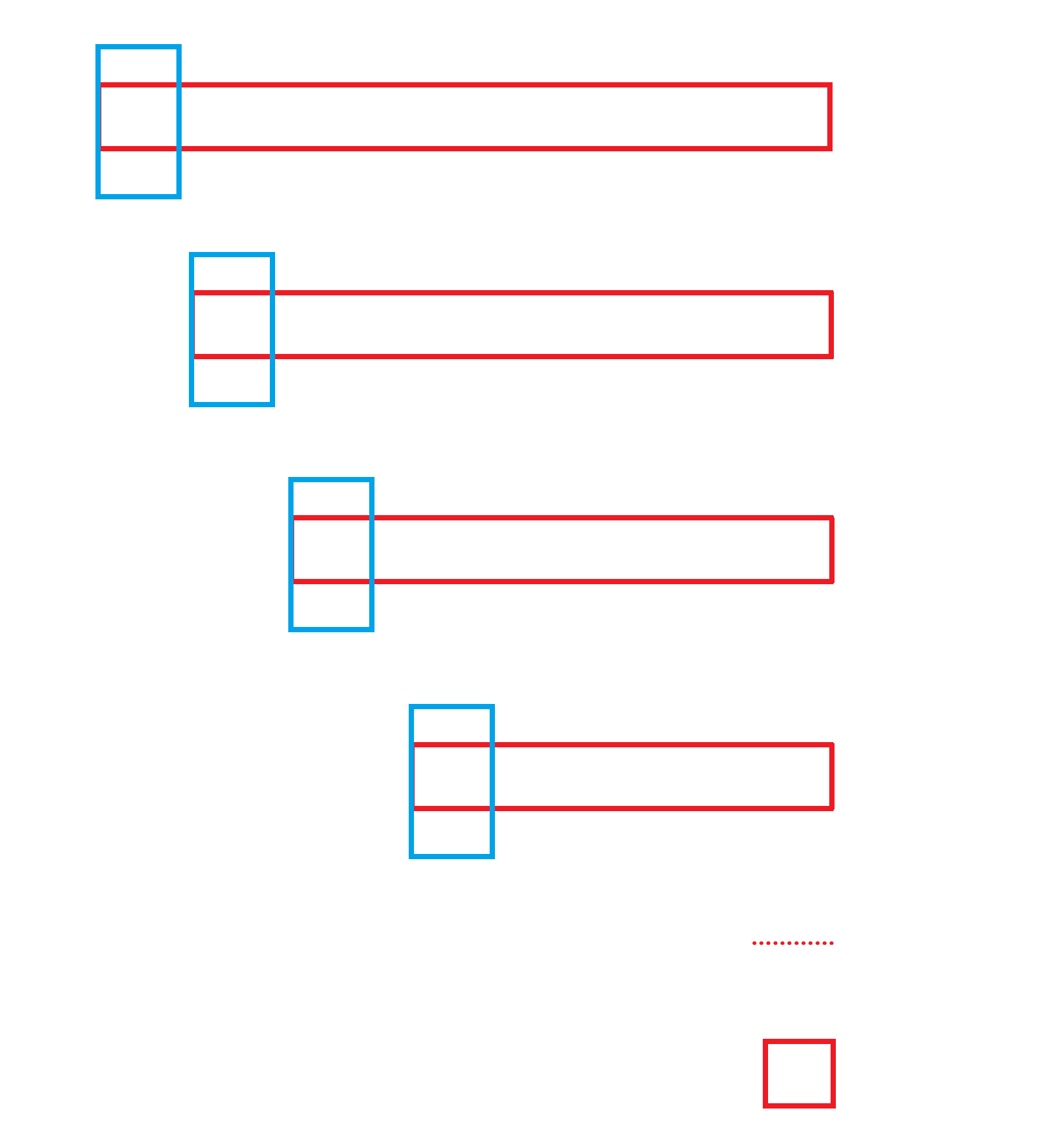
Here we use the "three number middle method"
Our three digit method is to avoid that the data we want to process is an ordered array. The implementation method of this method is that we compare the elements marked by left, right and mid in the current trip, and then we select the middle size element of the three elements to exchange with the element marked by key,, In this way, when our processing data is an ordered array, we can avoid changing our quick sort to insert sort
Now that we know how our methods are executed, let's implement the code
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else if (a[right] > a[left])
{
return right;
}
}
else//(a[left] > a[mid])
{
if (a[right] > a[left])
{
return left;
}
else if (a[right] > a[mid])
{
return right;
}
else if (a[mid] > a[right])
{
return mid;
}
}
}
Through the above code, we can compare the middle size of the three numbers and return its subscript. At this time, we can modify the quick sort code slightly
int PartSort(int* a, int left, int right)//Now we write the execution method of one-time sorting
{
int midi = GetMidIndex(a, left, right);
Swap(&a[left], &a[midi]);//Exchange the data, and the subscript remains unchanged
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//At this time, there is no difference between left exchange and right exchange, because now the two pointers point to the same element
return left;//At this time, the value of our initial keyi subscript is stored in the position with the subscript left or right. Now we return the coordinates of keyi after we exchange, that is, keyi
}
⑥ Code check
sort.h
#include<stdio.h> #include<stdlib.h> void QuickSortTest(); void QuickSort(int* a, int left, int right); int PartSort(int* a, int left, int right); int GetMidIndex(int* a, int left, int right);
sort.c
#include"Sort.h"
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
//In order to avoid the ordered sorting array, we modify the three data fetching algorithm:
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else if (a[right] > a[left])
{
return right;
}
}
else//(a[left] > a[mid])
{
if (a[right] > a[left])
{
return left;
}
else if (a[right] > a[mid])
{
return right;
}
else if (a[mid] > a[right])
{
return mid;
}
}
}
int PartSort(int* a, int left, int right)//Now we write the execution method of one-time sorting
{
int midi = GetMidIndex(a, left, right);
Swap(&a[left], &a[midi]);//Exchange the data, and the subscript remains unchanged
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//At this time, there is no difference between left exchange and right exchange, because now the two pointers point to the same element
return left;//At this time, the value of our initial keyi subscript is stored in the position with the subscript left or right. Now we return the coordinates of keyi after we exchange, that is, keyi
}
void QuickSortTest()
{
int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
QuickSort(a, 0, sizeof(a) / sizeof(int)-1);
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
QuickSortTest();
return 0;
}
When we execute the code, the result of compilation execution is
This shows that our analysis idea and code writing are correct
⑦ Code improvement 2
Now we provide another method for the implementation of quick sorting, the digging method
Now let's explain this method through illustration
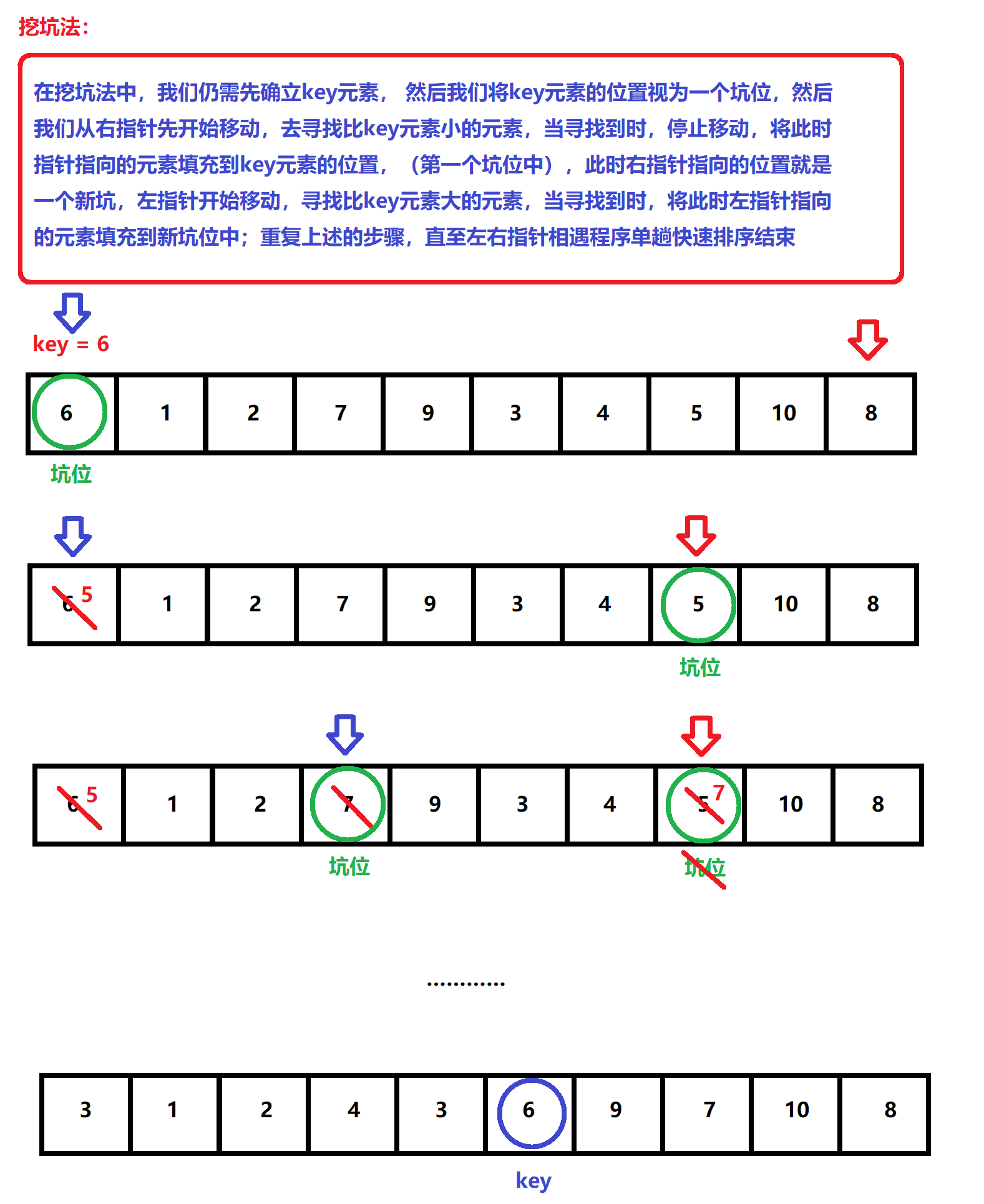
We are the same as above. First, we implement the code of single pass sorting
int PartSort(int* a, int left, int right)
{
int key = a[left];
int hole = left;
while (left < right)
{
while (left < right && a[right] >= key)//Find a small one on the right and fill it in the hole on the left
{
right--;
}
a[hole] = a[right];//After finding, exchange the contents and change the subscript of the pit
hole = right;
while (left < right && a[left] <= key)//Find a big one on the left and fill it in the hole on the right
{
left++;
}
a[hole] = a[left];
hole = left;
}
//At this time, we find the final position of the key value and assign the value
a[hole] = key;
return hole;
}
⑧ Code check
sort.h
#include<stdio.h> #include<stdlib.h> void PrintArray(int* a, int n); void QuickSortTest(); void QuickSort(int* a, int left, int right); int PartSort(int* a, int left, int right);
sort.c
int PartSort(int* a, int left, int right)
{
int key = a[left];
int hole = left;
while (left < right)
{
while (left < right && a[right] >= key)//Find a small one on the right and fill it in the hole on the left
{
right--;
}
a[hole] = a[right];//After finding, exchange the contents and change the subscript of the pit
hole = right;
while (left < right && a[left] <= key)//Find a big one on the left and fill it in the hole on the right
{
left++;
}
a[hole] = a[left];
hole = left;
}
//At this time, we find the final position of the key value and assign the value
a[hole] = key;
return hole;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
void QuickSortTest()
{
int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
QuickSort(a, 0, sizeof(a) / sizeof(int)-1);
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
QuickSortTest();
return 0;
}
When we execute the code, the result of compilation execution is
This shows that our analysis idea and code writing are correct
⑨ Code improvements 3
After learning the above two methods, we will explain another quick sort execution method, the double pointer method
Here, we directly illustrate how this method performs and implements quick sorting through illustration

Now that we know the implementation process of this method, we will implement the single pass sorting code in the same way as the above process
int PartSort(int* a, int left, int right)
{
int keyi = left;
int prv = left;
int cur = prv + 1;
while (cur <= right)
{
if (a[cur] < a[keyi])
{
Swap(&a[++prv], &a[cur]);
}
cur++;
}
Swap(&a[keyi], &a[prv]);
return prv;
}
At this time, if we draw a diagram for analysis, we can see that the above code will exchange with ourselves in the implementation process, which may reduce the efficiency, so we can optimize the above code
int PartSort(int* a, int left, int right)//Here, we judge the two signs one more step. When the two subscripts point to the same position, we do not exchange, so as to avoid the exchange between ourselves and ourselves
{
int keyi = left;
int prv = left;
int cur = prv + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prv != cur)
{
Swap(&a[prv], &a[cur]);
}
cur++;
}
Swap(&a[prv], &a[keyi]);
return prv;
}
Here, I prefer to use the first method to implement the single pass code in our quick sorting, because it is easier to understand, and the third method may be difficult to understand
⑩ Code check
sort.h
#include<stdio.h> #include<stdlib.h> void PrintArray(int* a, int n); void QuickSortTest(); void QuickSort(int* a, int left, int right); int PartSort(int* a, int left, int right);
sort.c
int PartSort(int* a, int left, int right)
{
int keyi = left;
int prv = left;
int cur = prv + 1;
while (cur <= right)
{
if (a[cur] < a[keyi])
{
Swap(&a[++prv], &a[cur]);
}
cur++;
}
Swap(&a[keyi], &a[prv]);
return prv;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
void QuickSortTest()
{
int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
QuickSort(a, 0, sizeof(a) / sizeof(int)-1);
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
QuickSortTest();
return 0;
}
When we execute the code, the result of compilation execution is
This shows that our analysis idea and code writing are correct
Merge sort
① Concept
Merge sort is an effective sort algorithm based on merge operation. It is a very typical application of Divide and Conquer. The ordered subsequences are combined to obtain a completely ordered sequence; That is, each subsequence is ordered first, and then the subsequence segments are ordered. If two ordered tables are merged into one, it is called two-way merging.
② Analysis
After looking at the concept of merge sort, combined with the previous study of binary tree, we are actually familiar with the implementation of merge sort. Here we analyze it through diagrams
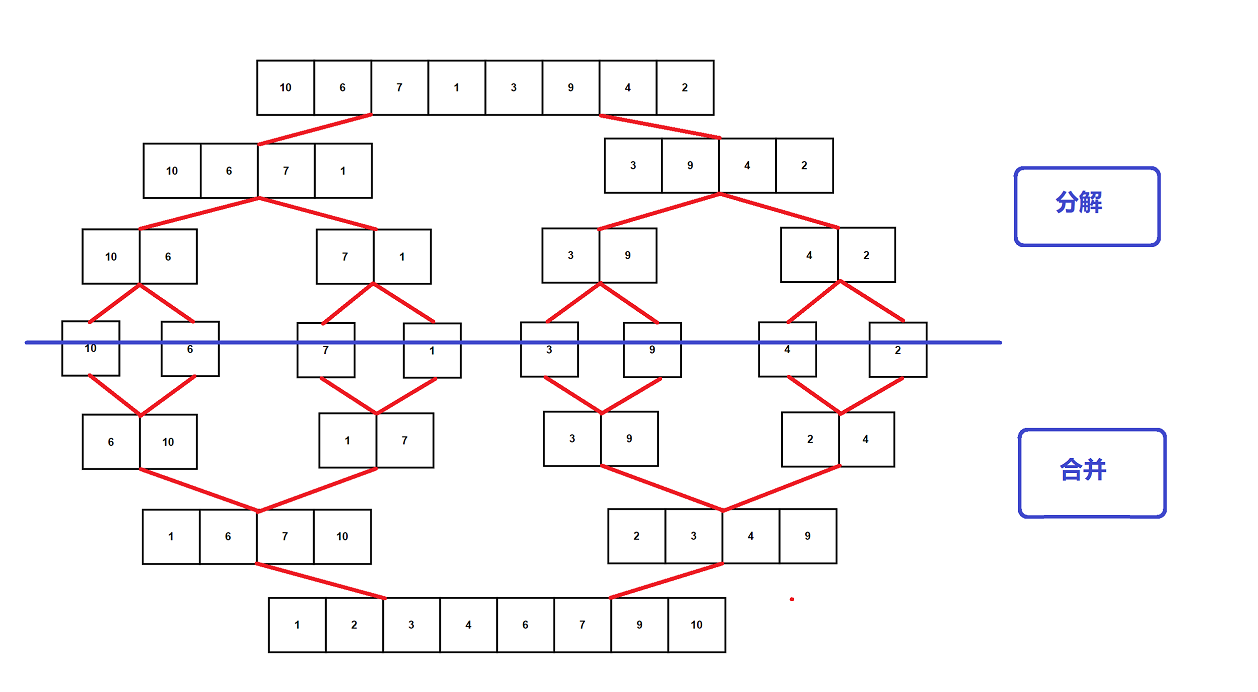
We will process the array to split, and then continue to split according to the idea of divide and rule. When the sub array we split contains only one element, we think the current array is orderly. Then we start to merge and sort in ascending order, so that the merged array is still orderly. In this way, we divide the array through recursive implementation, Then we merge the subarrays through recursion, and keep the merged subarrays in ascending order. In this way, when we end recursion, our array will change from unordered array to ordered array
③ Code analysis
void _MergeSort(int* a, int left, int right, int* tmp)//Interface parameters: original array, left boundary of interval, right boundary of interval, temporary array (used to store the contents of original array)
{
if (left >= right)//At this time, there is only one data in the range, so we default to its order
return;
int mid = (right + left) / 2;
//[left,mid][mid+1,right];
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
//Merge
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int index = left;//Position markers in temporary arrays
while (begin1 <= end1 && begin2 <= end2)//There are still elements in the split array
{
if (a[begin1] < a[begin2])//Compare the elements in the two split arrays, and store the smaller one
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
//When one side ends and all are saved, another split array still contains elements. Move it to the temporary array
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//After merging, we copy the data into the original array
for (int i = left; i <= right; i++)
{
a[i] = tmp[i];
}
}
void MergeSort(int* a, int n)//We originally wanted to merge through recursion, but if we call recursion every time, we need malloc, and the scope of our processing changes every time
//In this way, we will write another interface in the current interface to implement recursion
{
int* tmp = (int*)malloc(sizeof(int)* n);//Create an array whose size is equal to the size of the array we want to sort
_MergeSort(a, 0, n - 1, tmp);//We implement sorting recursively through the internal interface. For example, using this interface, malloc is required every time, and the overhead of stack frames is too large
free(tmp);
}
④ Code check
sort.h
#include<stdio.h> #include<stdlib.h> void PrintArray(int* a, int n); void MergeSort(int* a, int n); void _MergeSort(int* a, int left, int right, int* tmp); void TestMergeSort();
sort.c
void _MergeSort(int* a, int left, int right, int* tmp)//Interface parameters: original array, left boundary of interval, right boundary of interval, temporary array (used to store the contents of original array)
{
if (left >= right)//At this time, there is only one data in the range, so we default to its order
return;
int mid = (right + left) / 2;
//[left,mid][mid+1,right];
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
//Merge
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int index = left;//Position markers in temporary arrays
while (begin1 <= end1 && begin2 <= end2)//There are still elements in the split array
{
if (a[begin1] < a[begin2])//Compare the elements in the two split arrays, and store the smaller one
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
//When one side ends and all are saved, another split array still contains elements. Move it to the temporary array
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//After merging, we copy the data into the original array
for (int i = left; i <= right; i++)
{
a[i] = tmp[i];
}
}
void MergeSort(int* a, int n)//We originally wanted to merge through recursion, but if we call recursion every time, we need malloc, and the scope of our processing changes every time
//In this way, we will write another interface in the current interface to implement recursion
{
int* tmp = (int*)malloc(sizeof(int)* n);//Create an array whose size is equal to the size of the array we want to sort
_MergeSort(a, 0, n - 1, tmp);//We implement sorting recursively through the internal interface. For example, using this interface, malloc is required every time, and the overhead of stack frames is too large
free(tmp);
}
void TestMergeSort()
{
//int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
int a[] = { 10, 6, 7, 1, 3, 9, 4, 2 };
PrintArray(a, sizeof(a) / sizeof(int));
MergeSort(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
TestMergeSort();
return 0;
}
When we execute the code, the result of compilation execution is
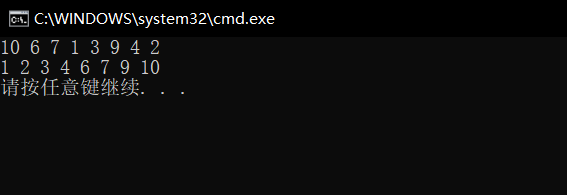
This shows that our analysis idea and code writing are correct
Count sort
① Concept
Idea: counting sorting, also known as pigeon nest principle, is a deformation application of hash direct addressing method.
② Analysis
The content given in the concept is too short for us to start without learning the corresponding knowledge. Here we analyze it through diagrams
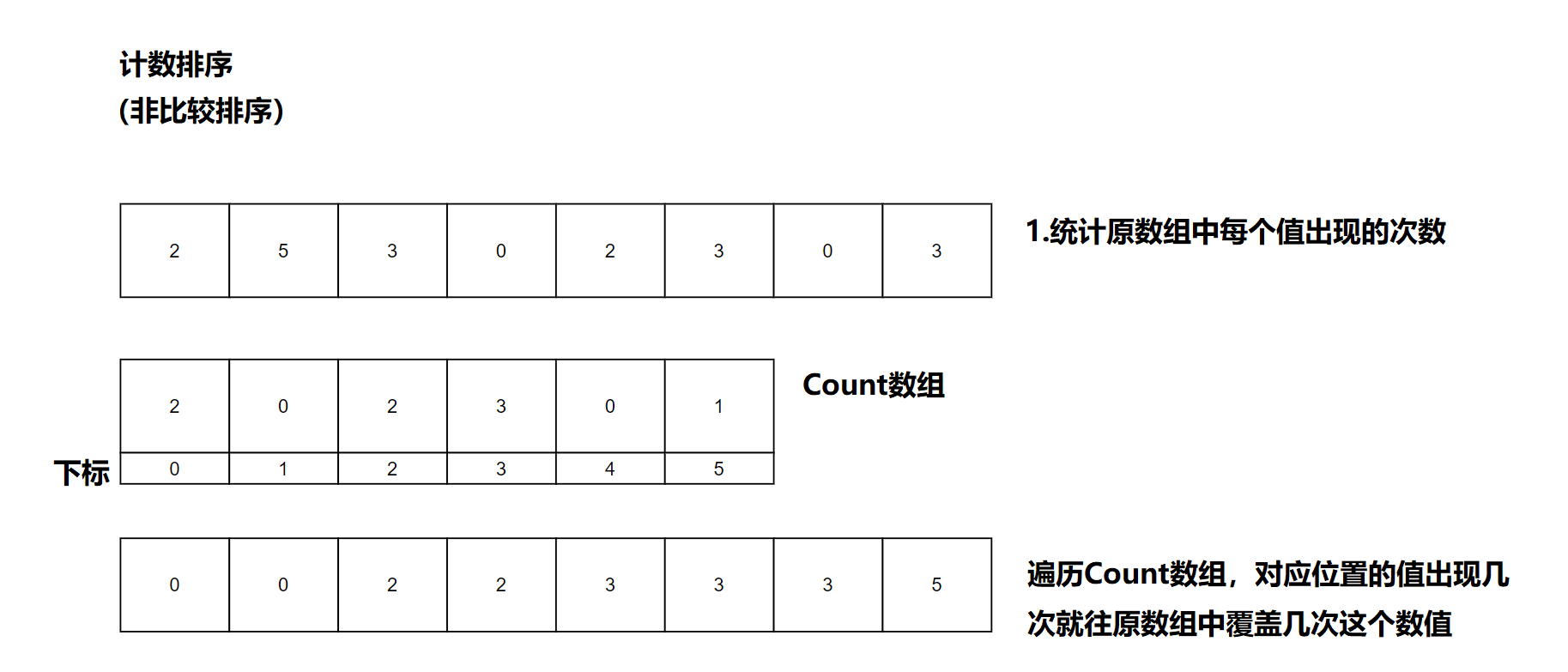
③ Code analysis
Here, we should note that the array in the above diagram gives a smaller range. If our array gives a larger range of elements and a larger jump between elements, what should we do? We can analyze and explain the treatment methods through diagrams
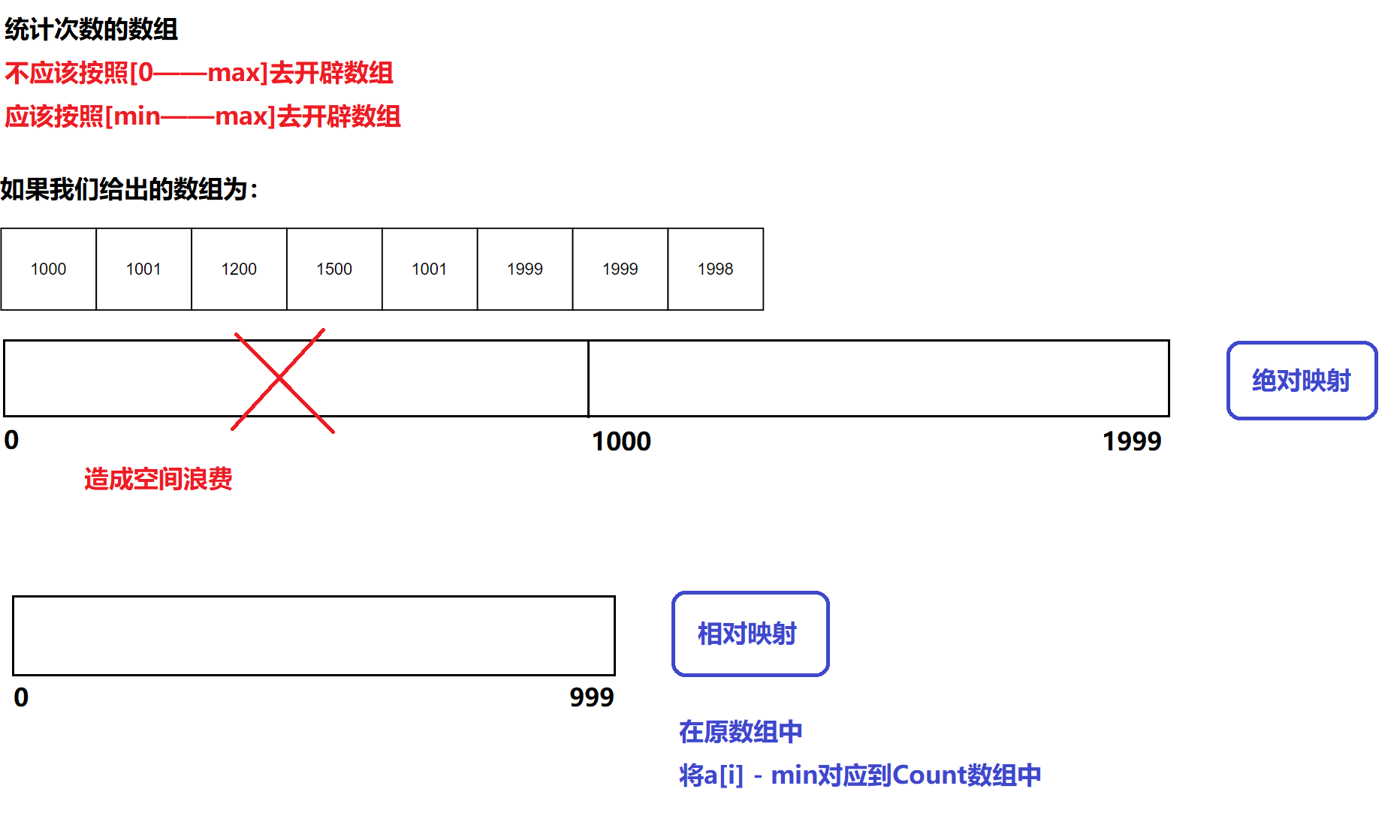
Through the illustration, we know that when we use the most basic method to face our current array, it is not applicable and will cause a waste of space. Therefore, we use the method of relative mapping to reduce the development of our array content and reduce the waste of array space
void CountSort(int* a, int n)
{
int min = a[0], max = a[0];//First select the maximum and minimum values in the current array
for (int i = 1; i < n; ++i)
{
if (a[i] < min)
{
min = a[i];
}
if (a[i] > max)
{
max = a[i];
}
}
int range = max - min + 1;//Count array length
int* count = (int*)calloc(range, sizeof(int));//Create Count array
// Statistical times
for (int i = 0; i < n; ++i)
{
count[a[i] - min]++;//Here we need drawing analysis to make it easier to understand
}
// Sort by count array
int i = 0;
for (int j = 0; j < range; ++j)
{
while (count[j]--)
{
a[i++] = j + min;
}
}
}
Here we need to analyze a code in the generation, and we explain it in a graphical way

④ Code check
sort.h
#include<stdio.h> #include<stdlib.h> void PrintArray(int* a, int n); void TestCountSort(); void CountSort(int* a, int n);
sort.c
void CountSort(int* a, int n)
{
int min = a[0], max = a[0];//First select the maximum and minimum values in the current array
for (int i = 1; i < n; ++i)
{
if (a[i] < min)
{
min = a[i];
}
if (a[i] > max)
{
max = a[i];
}
}
int range = max - min + 1;//Count array length
int* count = (int*)calloc(range, sizeof(int));//Create Count array
// Statistical times
for (int i = 0; i < n; ++i)
{
count[a[i] - min]++;//Here we need drawing analysis to make it easier to understand
}
// Sort by count array
int i = 0;
for (int j = 0; j < range; ++j)
{
while (count[j]--)
{
a[i++] = j + min;
}
}
}
void TestCountSort()
{
int a[] = { 10, 6, 7, 1, 3, 9, 4, 2, 2, 3, 6, 7, 4, 10 };
PrintArray(a, sizeof(a) / sizeof(int));
CountSort(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
test.c
#include <time.h>
#include <stdlib.h>
#include "Sort.h"
int main()
{
TestHeapSort();
return 0;
}
When we execute the code, the result of compilation execution is
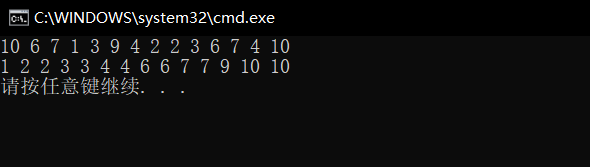
This shows that our analysis idea and code writing are correct
summary
The above is my personal understanding and description of the eight sorting contents. Later, I will explain the stability, time complexity and non recursive implementation of sorting
If there is any mistake in the above content, please give advice to [worship you] [worship you]
