Basic concepts
Classification of data structures
In data structure, according to different angles, data structure is divided into logical structure and physical structure (storage structure).
Logical structure: refers to the relationship between data elements in the data object we are facing.
Physical structure: The logical structure of data stored in a computer.
The logical structure can be subdivided into four more specific structures, as follows:
Aggregate structure
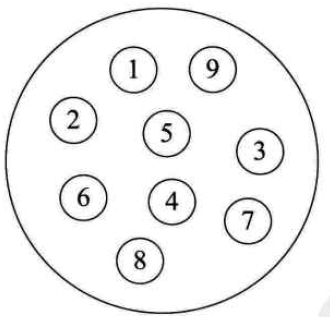
linear structure

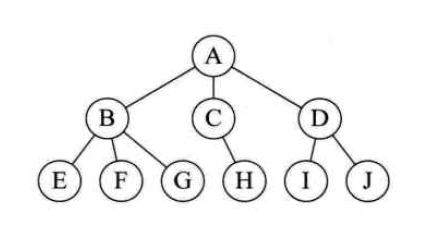
tree structure
Graphic structure
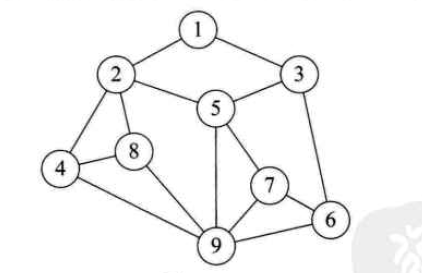
From the four pictures above, we can easily understand the four common logical structures.
The physical structure of data can be divided into two types.
Sequential storage structure: Store data elements in memory cells with continuous addresses. The logical and storage relationships between data are consistent.
Chain Storage Structure: Store data elements in any storage unit. The structure of the storage unit is random.
In summary, data structure classification can be summarized as follows
- Logical structure
- Aggregate structure
- Linear structure (one-to-one)
- Tree structure (one-to-many)
- Graphic structure (many-to-many)
- Physical structure
- Sequential storage (occupying continuous storage space)
- Chain Storage (Occupying Discontinuous Storage Space)
Abstract Data Type ADT
Abstract Data Type ADT.
The description of abstract data type includes the description of the name of abstract data type, the set of data, the relationship between data and the set of operations. Designers of abstract data types give concrete implementations of operations based on these descriptions, and users of abstract data types use abstract data types based on these descriptions.
The general form of abstract data type description is as follows:
ADT abstract data type name{
Data objects:
......
Data relations:
......
Operational set:
Operator name 1:
......
......
Operator name n:
} ADT abstract data type name
ADT includes not only the definition of element binding, but also the set of operations.
How to use the physical structure of data correctly and efficiently to reflect the logical structure of data elements and realize their abstract data types is the work of data structure.
Linear table
Linear table: A finite sequence of zero or more data elements. In addition to the first element, each element has and has only one direct precursor element, and each element has and only one direct successor element except the last one. The relationship between data elements is one-to-one.
Linear table abstract data type (ADT)

Implementation of Sequential Storage Structure for Linear Tables
The sequential storage structure of linear tables can be typically implemented with one-dimensional arrays, and the elements of linear tables can be found, added and deleted.
The following are the search, add and delete algorithms in the set of linear table abstract operations implemented by arrays.
public class LinearStructTest { //Length of Linear Table private static int length; public static void main(String[] args) { int[] data = new int[30]; //Insert elements somewhere in a linear table dataInsert(data, 1, 101); dataInsert(data, 2, 102); dataInsert(data, 3, 103); dataInsert(data, 4, 104); dataInsert(data, 5, 105); dataInsert(data, 6, 106); dataInsert(data, 3, 1003); dataInsert(data, 4, 1004); dataDel(data, 1); dataDel(data, 5); System.out.println("after insert :"); for (int e : data) { System.out.print(e + " "); } System.out.println(""); //Get data elements for a location int a = getData(data, 5); System.out.println("the element at pos=5 is " + a); System.out.println("\nthe length =" + length); } /** * Delete the element of pos, where POS is not an array subscript, but a normal natural position * * @param data * @param pos */ private static boolean dataDel(int[] data, int pos) { //Linear epitope space if (length == 0) { return false; } // if (pos < 1 || pos > length) { return false; } if (pos < length - 1) { for (int m = pos; m < length; m++) { data[m - 1] = data[m]; } } length--; return true; } /** * Insert the new element e before the first position of the array data * * @param data * @param pos * @param e * @return */ private static boolean dataInsert(int[] data, int pos, int e) { //Linear table full if (length == data.length) { return false; } //Location crossing if (pos < 1 || pos > length + 1) { return false; } if (pos <= length) { //The elements from pos-1 move backwards for (int m = length - 1; m >= pos - 1; m--) { data[m + 1] = data[m]; } } data[pos - 1] = e; length++; return true; } /** * Get the element at the first position in the linear table * @param data * @param i * @return */ private static int getData(int[] data, int i) { //Linear table is empty, or position crosses the boundary to return - 1 if (length == 0 || i < 1 || i > length) { return -1; } return data[i - 1]; } }
From the above code, it can be seen that for linear tables with sequential storage structure, because arrays have random access characteristics, it is easy to find a specific location element in them. Its time complexity is O(1). For the operation of adding or deleting elements, it needs to move a large number of elements, and the time complexity is O(N).
For the above linear storage structure is not easy to add or delete the shortcomings, you can consider using the chain storage structure below.
Realization of Chain Storage Structure of Linear List
In the chain storage structure, in order to maintain the characteristics of linear tables; for each element, in addition to storing its own information, it also needs to store the storage location of its direct successor elements; we call the domain storing data information as data domain, and the domain storing direct successor location as pointer domain. Such a storage area is called Node.
Chain structure, as the name implies, is that in computer content, the memory space for storing data is no longer continuous, but random in all locations, and these locations are connected by a specific thing (pointer); such a physical structure is chain structure.
In order to realize the logical structure of data more efficiently with the chain structure, the linked list structure can be divided into the following situations.
Singly Linked List
The n nodes link into a linked list, which is the chain storage structure of linear list, also known as single linked list.
- Head pointer: The storage location of the first node in the list. If there is a header node, the header pointer points to the header node.
- Header node: The node before the first node of a single linked list; its data domain can store any information, and the pointer domain stores pointers to the first node.
- The pointer field of the last node of a single linked list is NULL
- If the single list is empty, the pointer field of the header node is NULL.

Circular linked list
In a single list, the pointer field of the last node is NULL, so at the last node, there is no way to access other nodes in the list. Therefore, we change the pointer field of the last node in the single-linked list from NULL to pointing to the head node, which makes the single-linked list form a ring. This single-linked list is called the single-loop list, referred to as the circular list.
In a circular list, in order to unify and facilitate access to each element in the list, the end node, instead of the head node, is used, a node pointing to the last element in the list, as shown in the figure.

Two way linked list
Whether it is a single linked list or a circular linked list, because each node only stores the location of its direct successor nodes, it is very difficult to access its direct precursor nodes at this time. In order to achieve such an operation in a single linked list, it is necessary to traverse the entire list, which is very bad. Therefore, it is easy to think that, in this case, adding a storage area for each node and saving the location of the direct precursor node is not good. Yes, this is a two-way linked list.
Combined with the advantages of circular linked list, we can define a more universal chain structure, double-loop linked list.
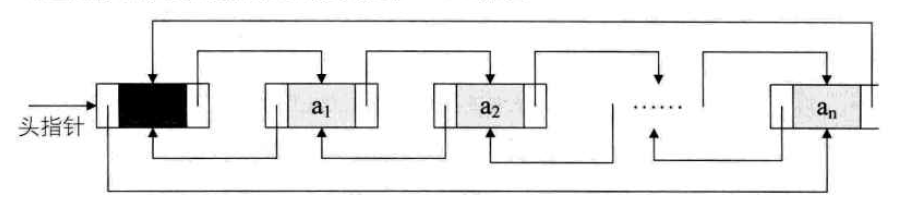
As can be seen from the single linked list of the contrast graph, the structure of the double-loop list is much more complicated than it seems, but in general, it is only one more pointer field, which makes it easier to access the adjacent nodes in the list.
Now let's see how to use double-loop linked list to realize the abstract data type of linear table.
Node DNode with precursor and successor pointers
/** * * Node object */ class DNode<T> { DNode prev,next; T value; DNode(){ this(null, null, null); } private DNode(DNode prev, DNode next, T value) { this.prev = prev; this.next = next; this.value = value; } }
Bidirectional Circulating Link List Abstract Data Operating Set
/** * * list */ class DoubleLoopLink<T> { //head node private DNode<T> mHead; //Node number private int mCount; /** * Initialize Linear Table */ DoubleLoopLink() { //Initialize header node mHead = new DNode<>(); //Create an empty circular list with the front-end and subsequent pointers of the header node pointing to itself mHead.prev = mHead; mHead.next = mHead; //Node number mCount = 0; } /** * Returns the number of elements in a linear table * @return */ int size() { return mCount; } /** * Obtain a node of a linear table * @param index index Scope (0~mCount-1) * @return */ DNode getNode(int index) { //Location crossing if (index < 0 || index >= mCount) { throw new IndexOutOfBoundsException(); } DNode mNode; // Compare the relationship between location and number of nodes to optimize the search interval if (index < mCount / 2) { //Point to the successor node of the head node, clockwise search mNode = mHead.next; for (int i = 0; i < index; i++) { mNode = mNode.next; } } else { //Find the precursor node of the pointing head node counterclockwise mNode = mHead.prev; for (int i = 0; i < mCount - index - 1; i++) { mNode = mNode.prev; } } return mNode; } /** * index insertion node at a location on the linearity table * @param index * @param value */ void insert(int index, T value) { //Create a new node DNode<T> newNode = new DNode<T>(); //New Node Data Domain Assignment newNode.value = value; //Before inserting to the first node if (index == 0) { //New Node Precursor Pointing Head Node Precursor newNode.prev = mHead; //The successor of the new node points to the head node, that is, the first node. newNode.next = mHead.next; //The precursor of the first node points to the new node mHead.next.prev = newNode; //The successor of the head node points to the new node mHead.next = newNode; } else if (index == mCount) { //The new node is appended to the tail node //New node precursor points to tail node newNode.prev = mHead.prev; //New Node Subsequent Pointing Node newNode.next = mHead; //The original tail node, then pointing to the new node mHead.prev.next = newNode; //Head Node Precursor Points to New Node mHead.prev = newNode; } else { //Before inserting into a node in the middle of a non-head-and-tail position //First, get the node at the index location DNode mNode = getNode(index); //The new node precursor points to the precursor of the index node newNode.prev = mNode.prev; //The successor of the new node points to the index location node newNode.next = mNode; //The index position precursor node's successor points to the new node mNode.prev.next = newNode; // idnex location node precursor points to new node mNode.prev = newNode; } mCount++; } /** * Returns the data field of a node at a location * @param index * @return */ T pop(int index) { T value = null; //Get the node of Index location DNode indexNode = getNode(index); //index Location Node--Precursor Node-Successive Point--Successive Node of index Location indexNode.prev.next = indexNode.next; //The precursor point of the index position node--the precursor point of the back-drive node--the precursor node of the index position indexNode.next.prev = indexNode.prev; value = (T) indexNode.value; indexNode = null; mCount--; return value; } /** * Is the Linear Table Empty * @return */ public boolean isEmpty() { return mCount == 0; } }
As for the chain structure, his insertion and deletion attaches great importance to the order of operation, especially in the two-way list, each node changes, taking into account both the direction of its precursor and subsequent pointers. But it is also very regular. Referring to the above code and the following illustration, it should be easy to grasp the key points of insertion and deletion of the two-way linked list.
Bidirectional Link List Insertion
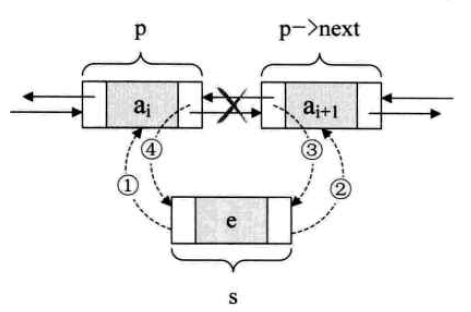
Two-way linked list deletion
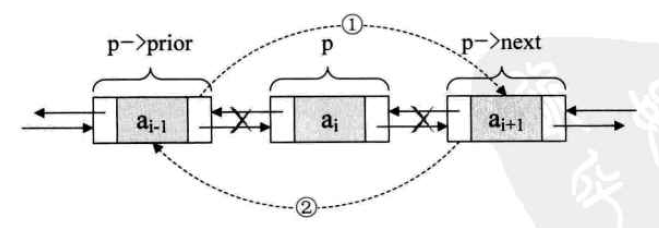
It can be found that the circular implementation of linked list only makes it easier for us to find a node in the list, and the addition and deletion of linked list nodes are not essential changes.
Summary of Linear Tables
As we said before, the work of data structure is to use the physical structure of data to correctly reflect the logical structure of data elements. Therefore, we can think that data structure is how to combine four logical structures and two physical structures to achieve ADT in the best way. Linear table is the simplest and most commonly used linear structure, which is realized by two storage structures.
In summary, the commonly used implementation methods of linear tables can be categorized as follows.
- Sequential storage structure
- One-dimensional array
- Linked Storage Structure
- Singly Linked List
- Circular linked list
- Two way linked list
- static linked list
Static linked list is a kind of structure that can not be implemented in a conventional way without pointers in C, C++, Java, and referring to related concepts. It uses arrays instead of pointers to describe the structure of linked list. The narrative will not be expanded here for the time being.
Generally speaking, the two storage structures have their own advantages and disadvantages for linear tables. Sequential storage structures are usually implemented by using arrays, which makes it possible for them to access randomly and to acquire specific location elements easily. However, because of the characteristics of arrays, storage space is fixed, and the size of storage capacity should be taken into account for the inserted elements; each insertion should take into account the size of storage capacity. And delete operations involve the movement of array elements, which is very inconvenient. The chain storage structure is very suitable for inserting and deleting operations, but also considering the size of the capacity. Therefore, the two implementation methods have their own merits; in actual development, we should choose the appropriate implementation method according to the specific scenario.