1. Numbers that occur only once
Title Description: Given a non-empty integer array, each element occurs twice, except for one element that occurs only once. Find the element that only appears once.
Example 1
Input: [2,2,1]
Output: 1
Example 2:
Input: [4,1,2,1,2]
Output: 4
1. Ideas
1. The easiest way to think about it is to determine if the length of the array is odd or even, return the even number directly to empty, sort the odd number first, and then traverse the array to find the number that only appears once
2. Mathematical thinking: To do this with XOR, first of all, you need to know whether a number is XOR 0, XOR 0 or its number itself, so we set an index=0 to XOR with every number in the array, because the number only appears once, so the final XOR result is that we ask for the number
3. Traverse through the array and place elements one by one into the collection, removing it if it exists in the collection and add ing if it does not. By title, the last element in this collection is this one occurrence only
2. Code
public int singleNumber(int[] nums) {
//Method 1: Violence
// Arrays.sort(nums);
// for (int i = 0; i < nums.length-1; i+=2) {
// if (nums[i] != nums[i+2]){
// return nums[i];
// }
// }
// return nums[nums.length-1];
// }
//Method 2: XOR
int result = 0;
for (int num : nums) {
result ^= num;
}
return result;
//Method 3: Hash table
//
// HashSet<Integer> set = new HashSet<>();
// //so that the final set contains only this non-repeating element
// for(int i = 0; i < nums.length; i++){
// if(set.contains(nums[i])){
// set.remove(nums[i]);
// }else{
// set.add(nums[i]);
// }
// }
// int res = 0;
// for(int i = 0; i < nums.length; i++){
// if(set.contains(nums[i])){
// res = nums[i];
// break;
// }
// }
// return res;
}
2. Copy a chain table with random pointers
Title Description: Give you a chain table with a length of n. Each node contains an additional random pointer that can point to any node in the chain table or to an empty node. Construct a deep copy of this list. The deep copy should consist of exactly n new nodes, where each new node's value is set to the value of its corresponding origin node. The next pointer and random pointer of the new node should also point to the new node in the replication chain table and enable these pointers in the origin chain table and the replication chain table to represent the same chain table state. Neither pointer in the replication list should point to a node in the original list.
For example, if there are two nodes in the original chain table, X.random --> Y. Then the corresponding two nodes X and Y in the replication chain table have the same
x.random --> y .
Returns the head node of the replication chain table.
A list of n nodes is used to represent the list of chains in the input/output. Each node is represented by a [val, random_index]:
Val: An integer representing Node.val. random_index: The index of the node to which the random pointer is pointing (range from 0 to
n-1; If it does not point to any node, it is null. Your code only accepts the head er node of the original list as an incoming parameter.
1. Ideas
1. Let's start with a simple and rough idea: first copy the list of chains in a normal way, and walk through each node to see how much the random pointer of the node is offset from the header node (a few steps from the beginning of the node will lead to the random pointing position). Then use this offset to determine the random direction of each node in the new list, but changing the code is more cumbersome.
2. A simpler and more understandable approach: create a Map <Node, Node> key for the node on the old list, and value for the copy of the corresponding node on the old list (that is, a copy of the new list)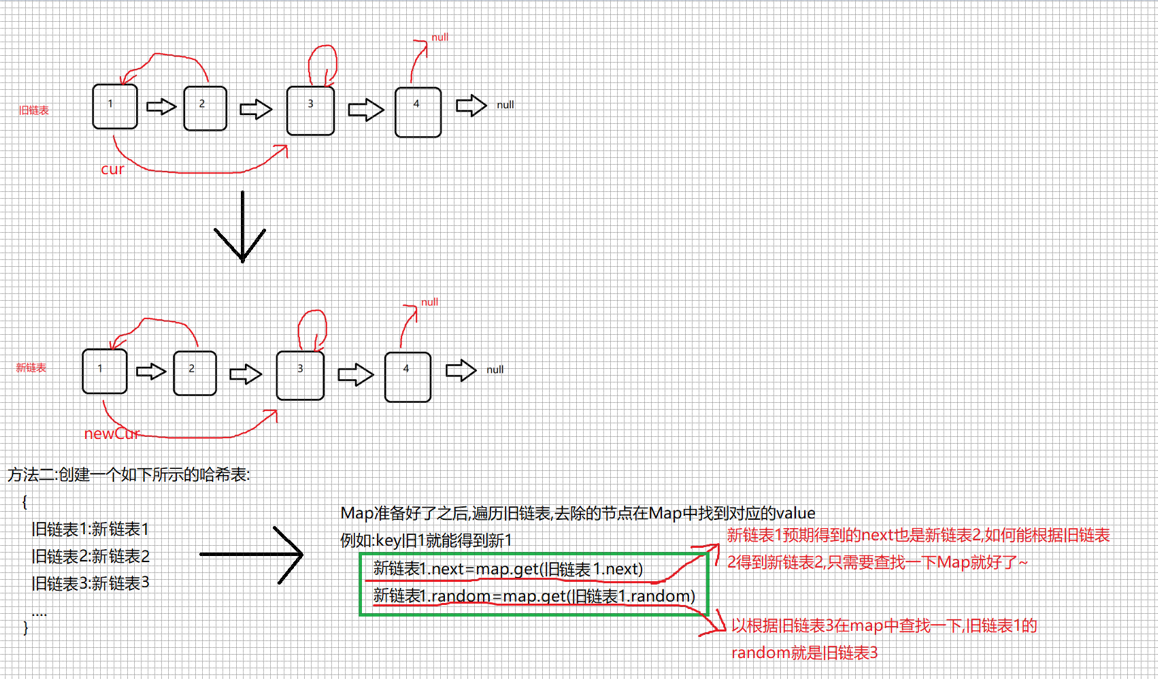
2. Code
public Node copyRandomList(Node head) {
//1. Walk through the old list and insert each node of the old list into the map once. The key is the old list and the value is the copy to get the new list.
Map<Node,Node> map=new HashMap<>();
for (Node cur=head;cur != null;cur=cur.next) {
map.put(cur,new Node(cur.val));
}
//2. Traverse the list again, modifying the next and random in the new list node
for (Node cur=head;cur != null;cur=cur.next) {
Node newCur=map.get(cur);
newCur.next=map.get(cur.next);
newCur.random=map.get(cur.random);
}
//Returns the header node of the new list of chains
return map.get(head);
}
3. Gems and Stones
Give you a string jewels to represent the type of gems in stones, and a string stones to represent the stones you own. Each character in stones represents the type of stone you own, and you want to know how many of the stones you own are gems.
Letters are case sensitive, so "a" and "A" are different types of stones.
Example 1:
Input: jewels = "aA", stones = "aAAbbbb"
Output: 3
Example 2:
Input: jewels = "z", stones = "ZZ"
Output: 0
1. Ideas
First iterate through jewels, saving the characters in HashSet to find them later when traversing stones
Traverse stones and compare each character to the one in the HashSet. If present, the result is ret++, end of traversal, return ret
2. Code
public int numJewelsInStones(String jewels, String stones) {
//1. First traverse j edges to add all gems to a Set
Set<Character> set=new HashSet<>();
for (char c:jewels.toCharArray()) {
set.add(c);
}
//2. Traverse S to get each element and look in the set. If you can find it, it is a gem.
int ret=0;
for (char c:stones.toCharArray()) {
if (set.contains(c)){
ret++;
}
}
return ret;
}
Complexity analysis
Time complexity: O(m+n), where m is the length of the string jewels and N is the length of the string stones. Traversing through the string jewels stores the characters in the hash set, with a time complexity of O(m), then traversing through the string stones to determine whether the current character is a gem or not for each character in the stones within the time of O(1)
The time complexity is O(n), so the total time complexity is O(m+n).
Spatial complexity: O(m), where m is the length of the string jewels.
4. Bad keyboard typing
Enter a description:
The input gives the text that should be entered and the text that is actually entered in two lines. Each text is a string of no more than 80 characters, consisting of the letters A-Z (upper and lower case), the numbers 0-9,
And the underline "" (for spaces). Title guarantees that both strings are not empty.
Output description:
Output broken keys in one line in discovery order. English letters are only capitalized and each bad key is only printed once. Title guarantees at least one bad key.
1. Ideas
1. Loop in two strings, the content of the first expected output and the content of the second actual output
2. Convert both read strings to uppercase
3. The main task in the title is to determine which characters of the expected output do not appear in the actual output string.
4. Start with a set that stores each character of the actual output, and you can iterate through the expected output string to see if the expected character does not appear in the set.
5. [Note] Expect that if there are duplicate keys in the string to be weighted (you can use set to weigh)
2. Code
public static void main(String[] args){
Scanner scanner=new Scanner(System.in);
while (scanner.hasNext()){
//1. Loop in two strings, the first one is the content of its output; The actual output of the second string
String expected=scanner.next();
String actual=scanner.next();
//2. Capitalize both read strings
expected=expected.toUpperCase();
actual=actual.toUpperCase();
//3. Create a Set to save the actual character output
Set<Character> actualSet=new HashSet<>();
for (int i=0;i < actual.length();i++){
//Note that the element in the set cannot be repeated, and add fails if it finds that the element already exists when it adds
//No negative impact
actualSet.add(actual.charAt(i));
}
//4. Traverse through the expected output string to see which character was not actually output
Set<Character> brokenKeySet=new HashSet<>();
for (int i = 0; i < expected.length(); i++) {
char c=expected.charAt(i);
if (actualSet.contains(c)){
//This is a good key, that is, the current character has been output
continue;
}
//The current key that is not actually output is a broken key
//The format of the output is also important, no spaces, no line breaks
//Here's also weight removal
if (brokenKeySet.contains(c)){
//The brokenKeySet here helps with weight removal to prevent the same bad key from being printed multiple times
continue;
}
System.out.print(c);
brokenKeySet.add(c);
}// end for
}//end while
5. First K High Frequency Words
Give a list of non-empty words and return the first k words that appear the most.
Answers returned should be sorted by word frequency from high to low. If different words have the same frequency, sort them alphabetically.
1. Ideas
We can preprocess the frequency of each word, sort it in descending order according to the frequency of each word, and return the first k strings.
Specifically, we use a hash table to record how often each string occurs, and then sort all the strings in the hash table. When sorting, if the two strings occur at the same frequency, we put the smaller dictionary order in the two strings first, otherwise we put the higher frequency first. Finally, we just need to keep the first k strings in the sequence.
2. Code
class Solution {
static class MyComparator implements Comparator<String>{
private Map<String,Integer> map;
public MyComparator(Map<String, Integer> map) {
this.map = map;
}
@Override
public int compare(String o1, String o2) {
int count1= map.get(o1);
int count2= map.get(o2);
if (count1==count2){
//String implements Comparable by itself, with the ability to compare dictionary orders
//comperto is using the String default comparison rule
return o1.compareTo(o2);
//O1 < O2 returns < 0
//O1 > O2 Return > 0
//The count1 - count2 ascending sort defines a smaller number of occurrences
//The count2 - count1 descending sort defines a larger number of occurrences
//sort is also sorted in ascending order
//These two types of straps are redefining "what is smaller"
//
}
return count2-count1;
}
}
public List<String> topKFrequent(String[] words, int k) {
//1. First count the number of occurrences of each word
Map<String,Integer> map=new HashMap<>();
for (String s:words) {
Integer count=map.getOrDefault(s,0);//0 occurrences if not found
map.put(s,count+1);//Same plus one
}
//2. Put the string content you just counted here into the ArrayList
//A keySet is equivalent to a Set in which all keys are stored
ArrayList<String> arrayList=new ArrayList(map.keySet());
//3. Sort the arrayList according to the number of occurrences of the string just now
//Sort defaults to ascending order by element's own size (String's dictionary order)
//Here we need to sort in descending order by the number of occurrences of strings, and we need to customize the comparison rules from the comparator
Collections.sort(arrayList,new MyComparator(map));
return arrayList.subList(0,k);
}
}
22nd birthday, no matter who's blogging here hhhhhhhh (Happy Birthday to myself)
