Source code: GitHub point here || GitEE point here
1, Scenario analysis
1. Scenario case
Friends in the Internet industry must have known or heard of the following scenarios:
Ali: thousands of thousands of faces, meaning different users use Ali related products feel different, for example, the recommended content of Alipay home page, and other related recommended flow information is completely different.
Tencent: social advertising, advertising information in different users' circle of friends or other media scenarios is different, and will be recommended based on user characteristics.
Headline: Information Value: according to the user's browsing information, analyze the user's relevant preferences, recommend the relevant information flow for the analysis results, pay more attention to certain content, and obtain more relevant information.
The logic of the above scenarios is: Based on the continuous analysis of the user's behavior, generate the user's feature portrait, and then based on the user tag, customize the recommendation related content.
2. Basic concepts
Through the above scenario, two concepts are derived:
User portrait
User portrait, as an effective tool to sketch the target user and contact the user's demands and design direction, forms the user portrait by visualizing the data associated with the user. User portrait has been widely used in various fields, initially in the field of e-commerce. Under the background of big data era, user information is full of network, which abstracts every specific information of users into tags, and uses these tags to materialize the user image, so as to provide targeted services for users.
Label data
Labels are very common in life, such as commodity labels, personal labels, industry labels. For example, when you mention 996, you think of programmers, and when you mention programmers, you think of checkers.
Tag is to integrate the scattered multi-party data into a unified technical platform, standardize and subdivide these data, carry out structured storage and update management, so that the business line can push these subdivision results to the existing platform in the interactive marketing environment, and generate value. These data are called tag data, which is often called tag library. In recent years, the concept of data label has become more and more popular in the development of big data.
Tag value
- The foundation of fine operation can effectively improve the accuracy and efficiency of traffic.
- Help the product quickly locate the demand group and carry out precise marketing;
- It can help customers to cut into the market cycle faster;
- In depth forecast and analysis of customers and make timely response;
- Developing intelligent recommendation system based on tag;
- Based on the analysis of a certain type of users, insight into the characteristics of the industry;
The core value of tag, or the most commonly used scenario: real-time intelligent recommendation, precise digital marketing.
2, Data labels
1. Label Division
Property label
For example, after user real name authentication, related tags such as gender, birthday, birth year, age, etc. are obtained based on identity information. The frequency of change is small and the most accurate.
Behavior label
Behavior tag is a series of operations of users on products. Based on the analysis of behavior log, it can be concluded that: for example, purchasing power, consumption hobby, seasonal consumption tag, etc. In the APP of information flow, through relevant browsing behavior, it is based on this logic to continuously recommend the content that users are interested in.
Rule label
According to the business scenario requirements, configure the specified rules, and generate analysis results based on the rules, for example:
- Active users in the past 7 days: in the past 7 days, users who log in every day are generated as rules;
- Lost users: without any operation within six months, they can issue high-value coupons;
- Potential users: use or generate browsing data, but no transaction occurs;
This kind of label can be based on the dynamic rule configuration. After calculation and analysis, it can generate the description result, which is the rule label.
Fit label
The tags of fitting class are the most complex. Through the above-mentioned tags, intelligent combination analysis, given prediction values, such as: unmarried, browsing related wedding content, through analysis and prediction, users will hold a wedding, and get a fitting result: predicted to be married. This prediction logic can also be executed in reverse, and the user purchases baby products: prediction of married and childbearing.
This is a common saying in the data age: after a user operates on an application, the result of algorithm analysis may be more real than the user's description of himself.
2. Label processing flow
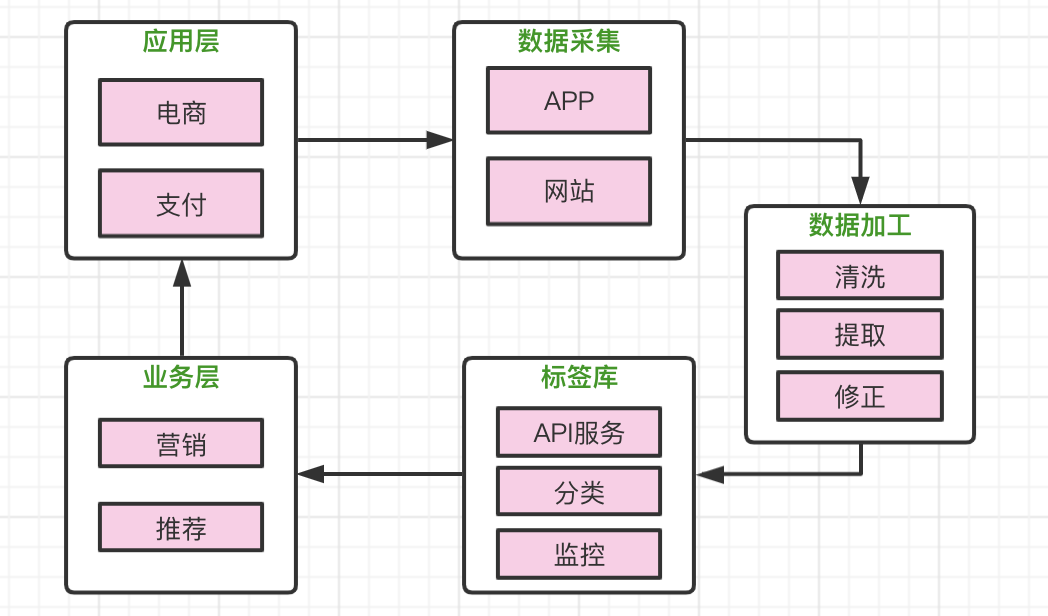
data acquisition
There are many channels for data collection, such as various business lines in the same APP: shopping, payment, financial management, take out, information browsing, etc. Through the data channel to the unified data aggregation platform. With the support of these massive log data, it has the basic conditions of data analysis. Whether it is data intelligence, deep learning, algorithm, etc. are based on massive data, so as to obtain valuable analysis results.
Data processing
Combined with the above businesses, through the processing, analysis and extraction of massive data, to obtain relatively accurate user tags, there is a key step here, which is to continuously verify and repair the existing user tags, especially the related tags of rule class and fitting class.
Label Library
Through the tag library, the management of complex tag results, in addition to complex tags and tag changes based on the time line, tag data has been of considerable value here, and some charging services can be opened around the tag library, such as common, users can browse some products in an e-commerce APP, and see product recommendations in an information flow platform. Big data age is so smart and suffocating.
Label business
After a large circle of data transformation into labels, it is natural to return to the business level. Through the analysis of users of label data, we can carry out precision marketing, intelligent recommendation and other related operations. In e-commerce applications, we can improve the volume of transactions and better attract users in the information flow.
application layer
Develop the above businesses into services, integrate them into the application level, constantly improve the quality of application services, constantly attract users and provide services. Of course, the user's data is constantly generated at the application level, and in the transition to data collection services, a complete closed-loop process is finally formed.
3. Application cases
From the process and business level description are simple, to the development level will become complex and difficult to deal with, which may be the gap between product and development.
Data type of label
The analysis results of different labels need to be described by different data types. In the label system, the data types commonly used to describe labels are as follows: enumeration, numerical value, date, Boolean, text type. Different types require different analysis processes.
Goods and labels
A basic case is provided here to analyze the goods with their labels. For example, through the conditions such as the place of origin, price, and status of the goods, you can query how many qualified goods are in the product library.
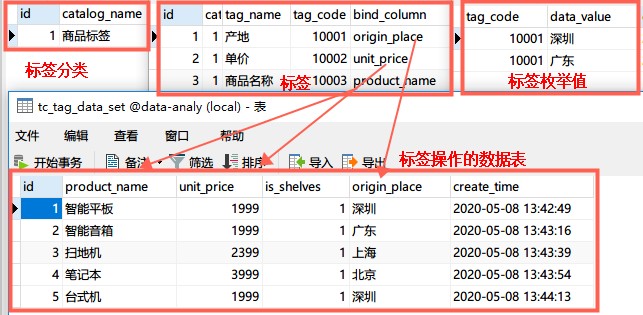
Data sheet design
Mainly divided into four tables: label classification, label library, label value, label data.
CREATE TABLE `tc_tag_catalog` ( `id` INT (11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key ID', `catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT 'name', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', `update_time` datetime DEFAULT NULL COMMENT 'Update time', `state` INT (1) DEFAULT '1' COMMENT 'Status 1 enabled,2 Disable', PRIMARY KEY (`id`) ) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = 'Label level directory'; CREATE TABLE `tc_tag_cloud` ( `id` INT (11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key ID', `catalog_id` INT (11) NOT NULL COMMENT 'catalog ID', `tag_name` VARCHAR (100) DEFAULT '' COMMENT 'Label name', `tag_code` INT (11) DEFAULT NULL COMMENT 'Tag code', `bind_column` VARCHAR (100) DEFAULT '' COMMENT 'Bind data column', `data_type` INT (2) NOT NULL COMMENT '1 enumeration,2 numerical value,3 date,4 Boolean,5 Value type', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', `update_time` datetime DEFAULT NULL COMMENT 'Update time', `remark` VARCHAR (150) DEFAULT NULL COMMENT 'remarks', `state` INT (1) DEFAULT '1' COMMENT 'Status 1 enabled,2 Disable', PRIMARY KEY (`id`) ) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = 'Tag cloud'; CREATE TABLE `tc_tag_data_enum` ( `tag_code` INT (11) NOT NULL COMMENT 'Tag code', `data_value` VARCHAR (150) NOT NULL COMMENT 'enum ', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', KEY `tag_code_index` (`tag_code`) USING BTREE ) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = 'Label enumeration value'; CREATE TABLE `tc_tag_data_set` ( `id` INT (11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key ID', `product_name` VARCHAR (100) DEFAULT '' COMMENT 'Commodity name', `unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT 'Unit Price', `is_shelves` INT (1) DEFAULT '1' COMMENT 'Put on shelves: 1 no,2 yes', `origin_place` VARCHAR (100) DEFAULT '' COMMENT 'Place of Origin', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', PRIMARY KEY (`id`) ) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = 'Label data set';
Analog input interface
The parameters here should be selected dynamically based on requirements and organized together:

For example, the list of label values given here in the picture is called enumeration value.
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List<TagParam> tagParamList = new ArrayList<>() ;
TagParam tagParam1 = new TagParam(1,"Place of Origin","origin_place") ;
List<String> valueList1 = new ArrayList<>() ;
valueList1.add("Shenzhen");
valueList1.add("Guangdong");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"Price","unit_price") ;
List<String> valueList2 = new ArrayList<>() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"date of manufacture","create_time") ;
List<String> valueList3 = new ArrayList<>() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"Is it on the shelf","is_shelves") ;
List<String> valueList4 = new ArrayList<>() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"Product name","product_name") ;
List<String> valueList5 = new ArrayList<>() ;
valueList5.add("intelligence");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result: " + count ;
}
}
Parameter resolution query
Through the analysis of the parameters, the final form of the query SQL statement, to obtain accurate result data.
@Service
public class TagDataSetServiceImpl extends ServiceImpl<TagDataSetMapper, TagDataSet> implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List<TagParam> tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1 enumeration, 2 value, 3 date, 4 Boolean, 5 value type
List<String> valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* Final SQL execution
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('Shenzhen ',' Guangdong ')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%Smart% '
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
Some people may say that this is a query process? If there is such a question, the value of tag data will be more intuitive if the above case is replaced by user query.
3, Intelligent portrait
1. Basic concepts
User portrait
As an effective tool to sketch the target user, contact the user's demand and design direction, user portrait has been widely used in various fields. At first, it was applied in the field of e-commerce. In the background of big data era, user information is full in the network. Each specific information of the user is abstracted into tags, which are used to materialize the user image, so as to provide targeted services for users.
Industry portrait
Through the comprehensive analysis of industry attribute tag and user tag under the industry, the industry analysis report is generated to provide valuable guidance, which is a very popular application in the last two years.
Picture completion
Through continuous analysis of user data, enrich the tag library, and make the user's portrait more abundant and three-dimensional.
2. Portrait Report
Through the analysis of tag data, an analysis report is generated, which contains rich user tag statistics.
For example: post-90s portrait Report
Internet users must have seen this report more or less. It mainly includes some tag statistics, common tag display, or which groups have the greatest impact on the three views of the post-90s, income sources, education and other analysis and interpretation.
4, Source code address
GitHub·address https://github.com/cicadasmile/data-manage-parent GitEE·address https://gitee.com/cicadasmile/data-manage-parent

Recommended reading: architecture design series, turnips and vegetables, each with its own needs