Job 1
-
Requirements: Specify a website to crawl all the pictures in this website, such as China Meteorological Network (China Meteorological Network). http://www.weather.com.cn ). Crawl using single-threaded and multithreaded methods, respectively. (Limit the number of crawled pictures to the last 3 digits of the school number)
-
Output information:
-
Output the downloaded Url information in the console, store the downloaded pictures in the images subfolder, and give a screenshot.
Solving Steps
Single Thread
- STEP1 Make Request (Common Template)
def getHTML(url):
try:
header = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
resp = requests.get(url, headers=header)
resp.raise_for_status() # 200
resp.encoding = resp.apparent_encoding
return resp.text
except Exception as err:
print(err)
- STEP2 gets URLs for different pages because it wants to change pages and puts them in a list for crawling
def getURLs(html):
Html =BeautifulSoup(html,'lxml')
html_urls = Html.select('li > a')
url_list = []
for url in html_urls:
url = url['href']
url_list.append(url)
#print(url_list)
return url_list
- STEP3 uses regular crawling to download pictures
def getImages(url_list):
Image_all = 1
for urls in url_list:
req = getHTML(urls)
req = req.replace("\n","")
imagelist = re.findall(r'<img.*?src="(.*?)"', req, re.S | re.M)
while "" in imagelist:
imagelist.remove("")
for img_url in imagelist:
#print(img_url)
if (img_url[0] == 'h'):
#print(img_url[0])
if (Image_all <= 129):
print("No."+str(Image_all)+"Zhang Crawled Successfully")
file = "D:/wea_img/" + "No."+ str(Image_all) + "Zhang" + ".jpg"
urllib.request.urlretrieve(img_url, filename=file)
Image_all += 1
else:
break
else:
continue
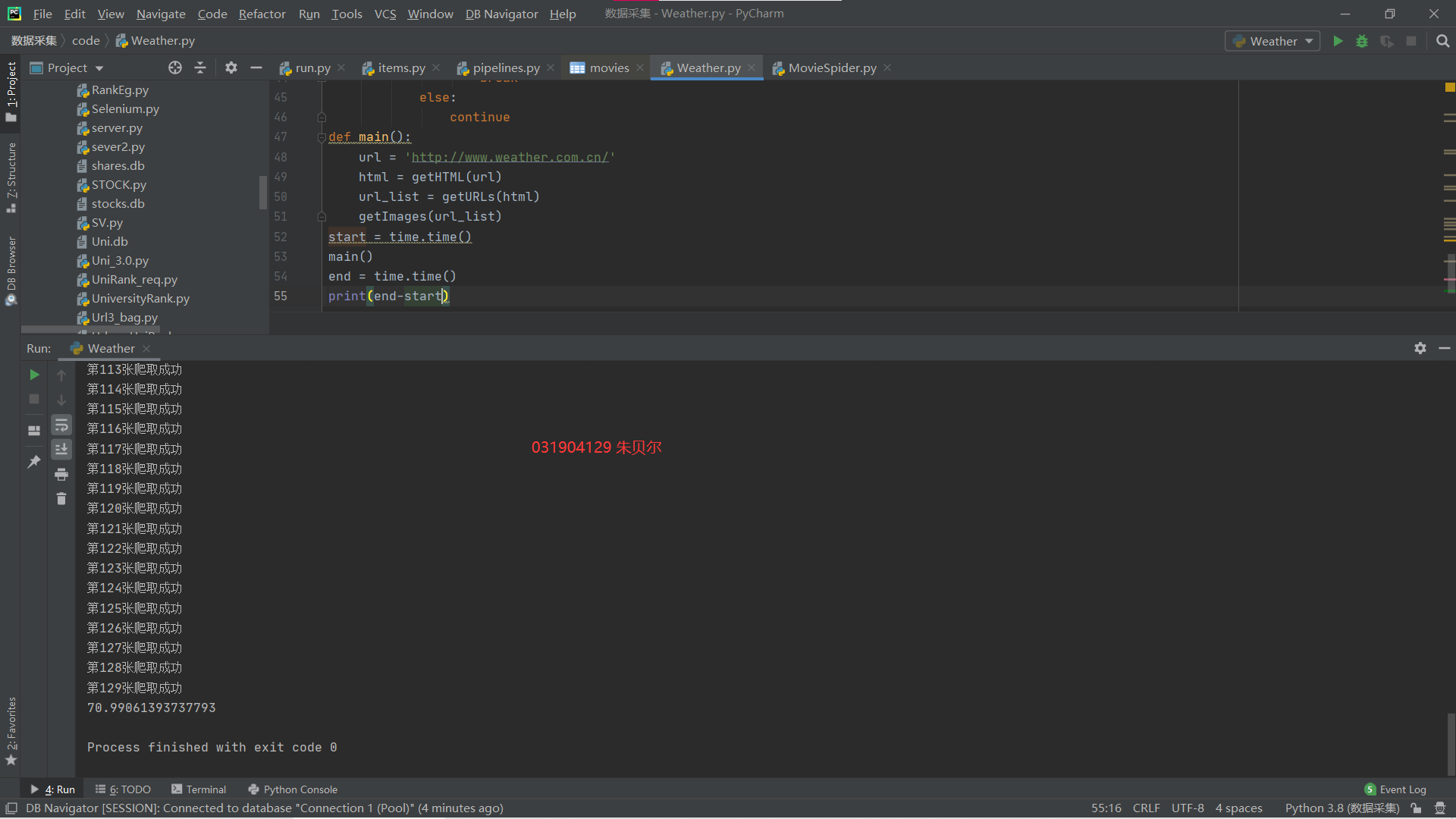
STEP4 plus a time function calculates time and compares it with the following multithreads
start = time.time() main() end = time.time() print(end-start)
Run Results
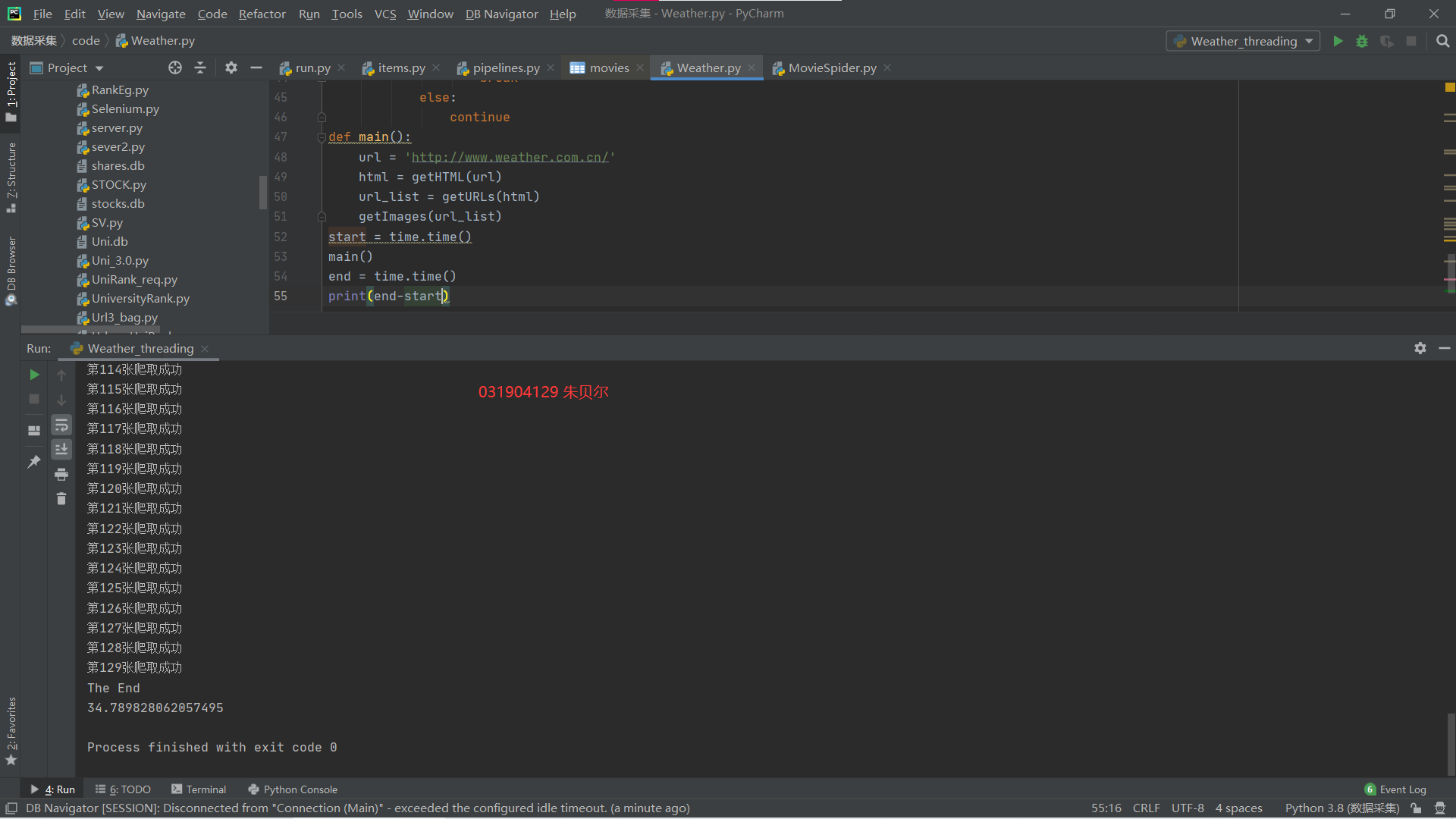
Multithreaded
Introducing threading
print("No."+str(Image_all)+"Zhang Crawled Successfully")
file = "D:/weath/" + "No."+ str(Image_all) + "Zhang" + ".jpg"
urllib.request.urlretrieve(img_url, filename=file)
r = threading.Thread(target=download, args=(img_url, file))
r.setDaemon(False)
r.start()
Image_all += 1
Result Screenshot:
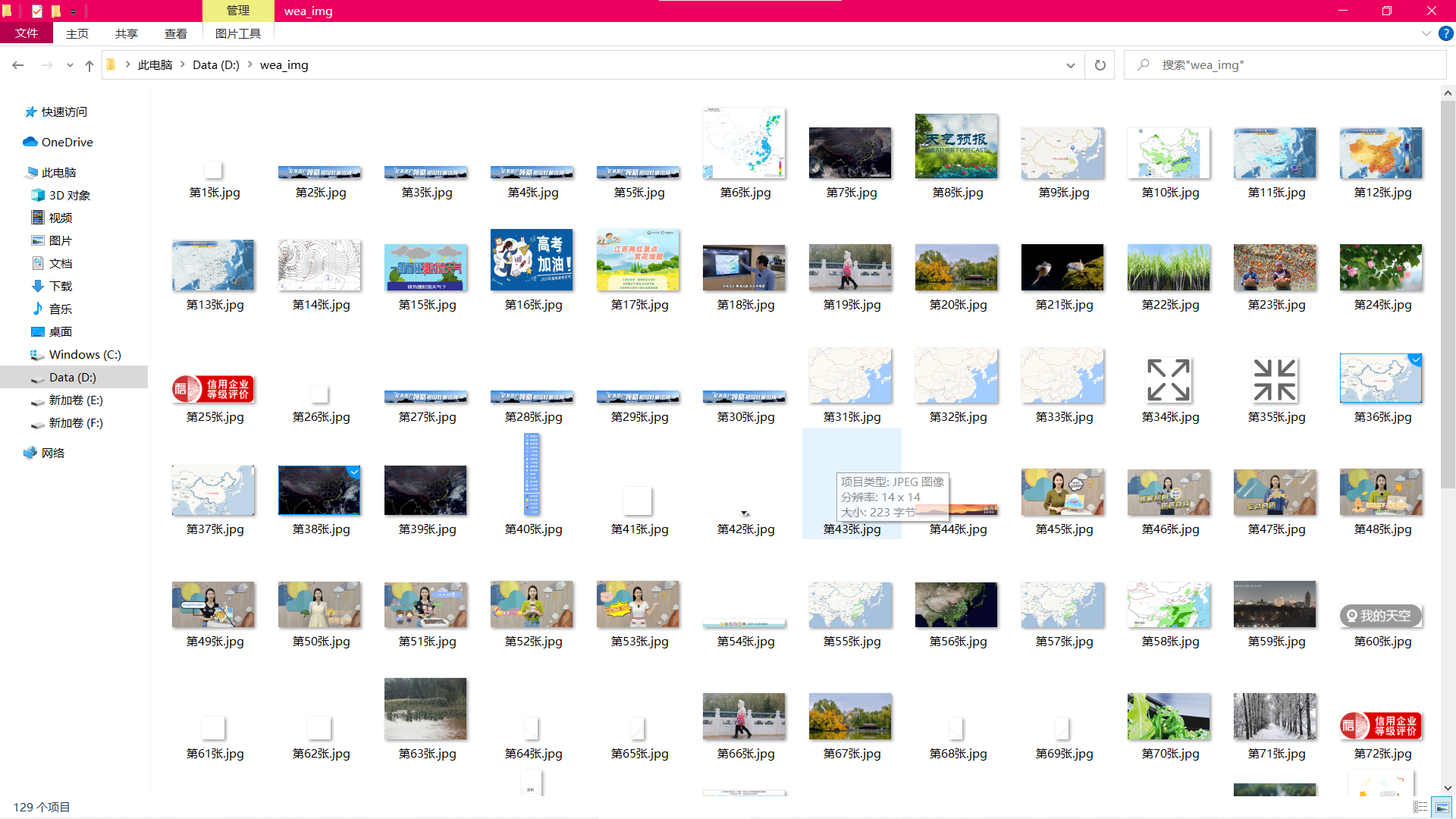
Download pictures in folder screenshots:
Code address: https://gitee.com/zhubeier/zhebeier/blob/master/ Third Big Job/First Question Multithreaded
- Experimentation Experience
1. Comparing single-threaded with multi-threaded, it is found that multi-threaded download pictures significantly faster than single-threaded.
2. Changing the page made me more familiar with finding irregular URLs
Job 2
Requirements: Reproduce jobs using the scrapy framework.
Output information:
Homework 1
Solving Steps
After STEP1 has created the scrapy crawler, write the items file
import scrapy
class WeatherItem(scrapy.Item):
urls_list = scrapy.Field()
STEP2 Modify parameters in setting s file
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
ITEM_PIPELINES = {
'weather.pipelines.WeatherPipeline': 300,
}
STEP3
Write spider parse module for crawler files, crawl pages
def parse(self, response):
try:
links = response.xpath('//a//@href').extract()
yield scrapy.Request(self.start_urls, callback=self.parse_for_page)
for link in links:
if link != 'javascript:void(0)':# Remove such links
yield scrapy.Request(link,callback=self.parse_for_page)
except Exception as err:
print(err)
STEP4 Writes pipeline files to store download crawled files
num = 1
class WeatherPipeline:
def process_item(self, item, spider):
global num
if not os.path.exists('./images_scrapy/'):
os.mkdir('./images_from_scrapy/')
for url in item["urls_list"]:
if num <= 129:
print(url)
image_name = './images_scrapy/'+'No.'+str(num)+'Picture.jpg'
print("Successful use scrapy Download No." + str(num) + "Picture")
urllib.request.urlretrieve(url,image_name)
num += 1
STEP5 Writes a run.py file to start the crawl
from scrapy import cmdline
cmdline.execute("scrapy crawl Weather -s LOG_ENABLED=False".split())
- Run result:
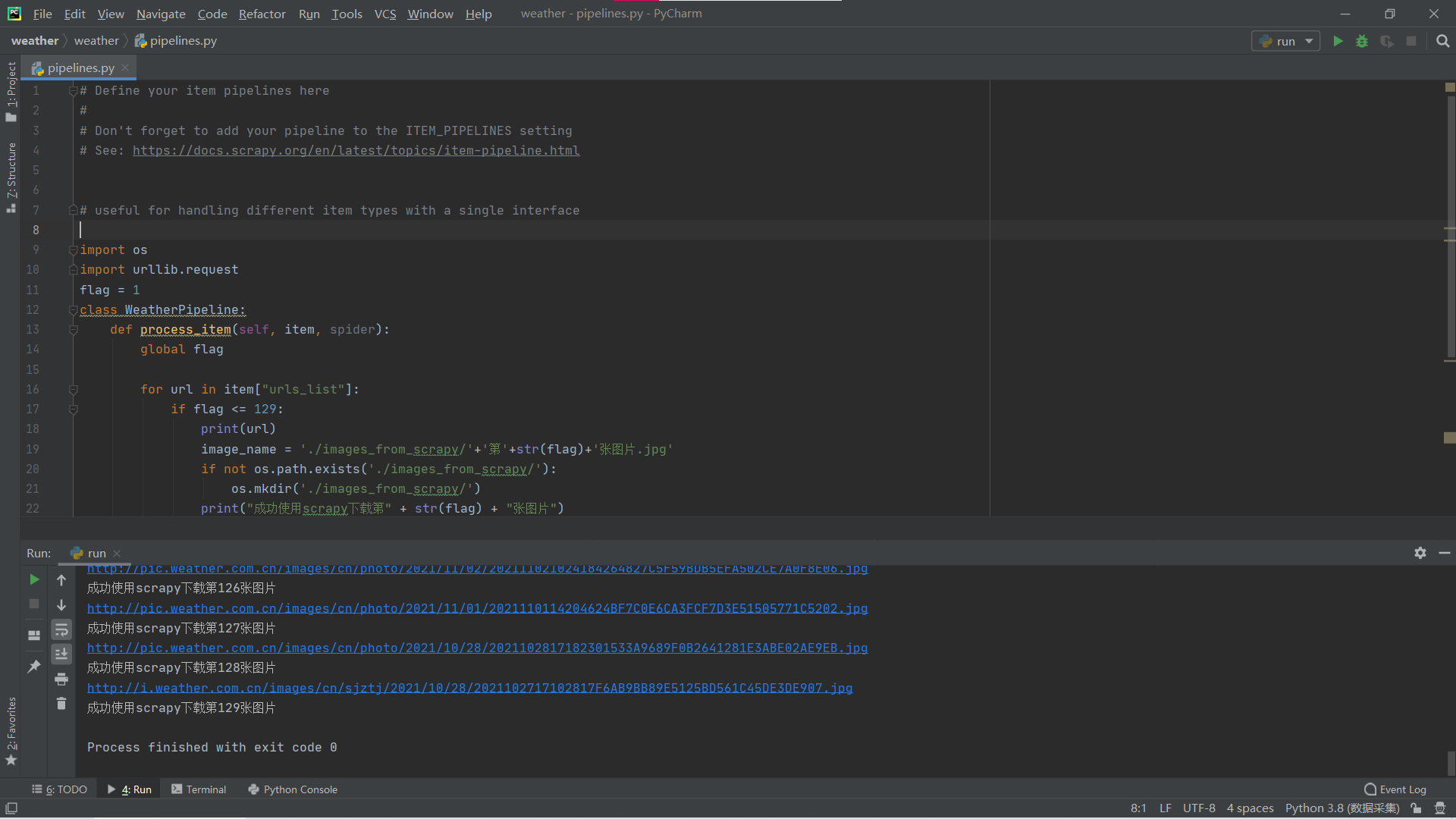
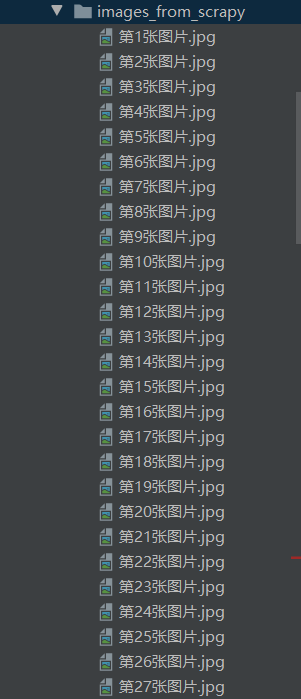
- Experimentation Experience
Familiarized with the basic steps of writing scrapy, items->settings->crawler files->pipeline files
Familiarize yourself with dealing with some special url links
Code address: https://gitee.com/zhubeier/zhebeier/blob/master/ Third major assignment/second topic
Job Three
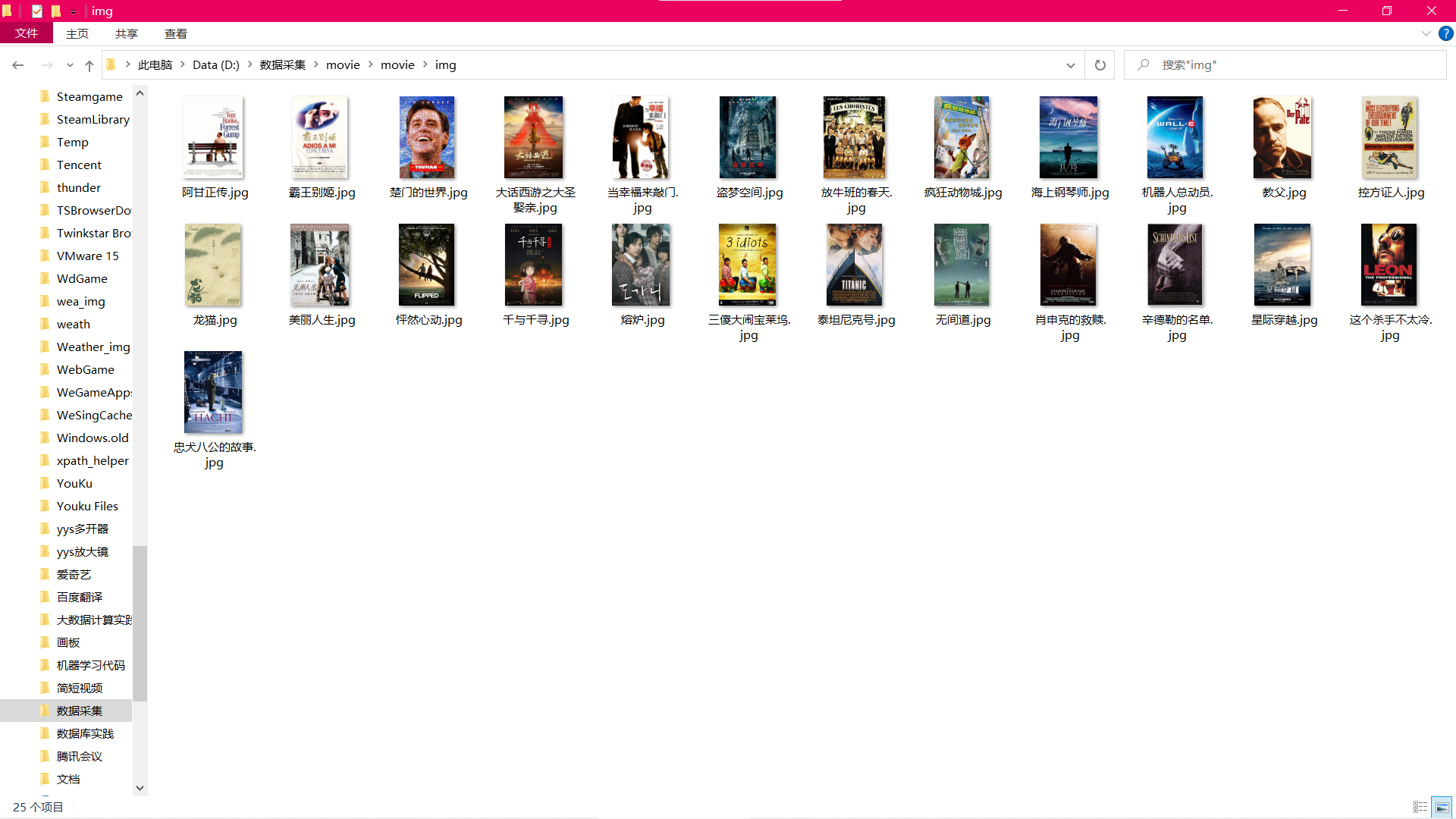
Requirements: Crawl Douban movie data using scrapy and xpath, and store the content in the database, while storing the pictures
Under the imgs path.
Candidate sites: https://movie.douban.com/top250
Output information:
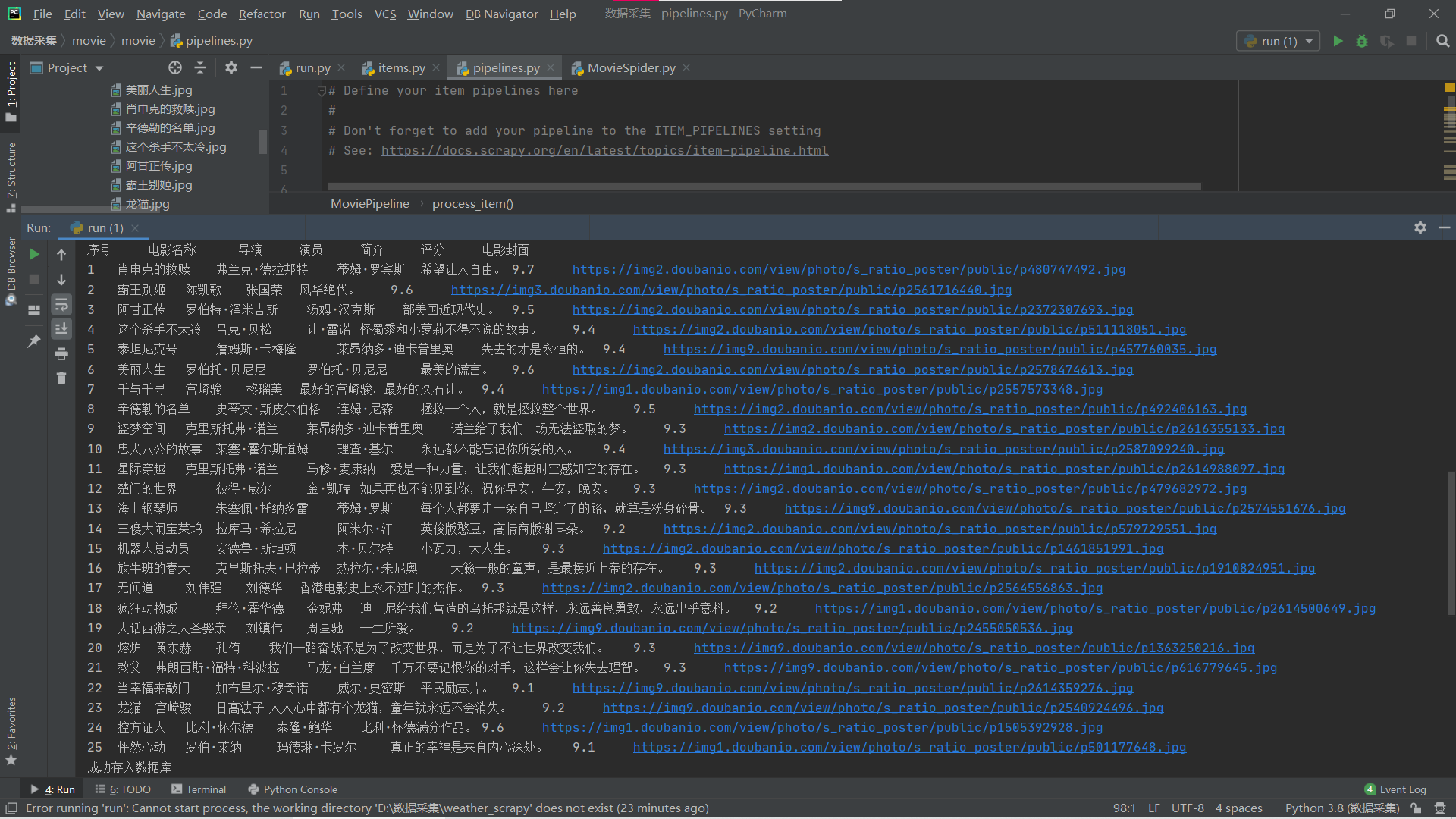
| Sequence Number | Movie Name | director | performer | brief introduction | Movie Scoring | Movie Cover |
|---|---|---|---|---|---|---|
| 1 | The Shawshank Redemption | Frank Drabant | Tim Robins | Want to set people free | 9.7 | ./imgs/xsk.jpg |
| 2.... |
Solving steps:
STEP1 writes items files with six attributes
class MovieItem(scrapy.Item):
name = scrapy.Field() # Movie Title
director = scrapy.Field() # director
actor = scrapy.Field() # To star
statement = scrapy.Field() # brief introduction
rank = scrapy.Field() # score
image_urls = scrapy.Field() # cover
STEP2 Modify settings file, same as Job 2
STEP3 Writes crawler files and uses xpath to extract required information
item["director"] = directors # director
item["actor"] = actors # performer
item["statement"] = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[2]/span/text()').extract()
item["rank"] = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()').extract()
item["image_urls"] = response.xpath('//*[@id="content"]/div/d
STEP4 Writes a PipeLines file to store the crawled data in the database
def openDB(self):
self.con = sqlite3.connect("M.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table movies(rank varchar(10),name varchar(10),director varchar(10),actor varchar(10),state varchar(20),score varchar(10),surface varchar(50))")
except:
self.cursor.execute("delete from movies")
def closeDB(self):
self.con.commit()
self.con.close()
Run result:
Terminal:
Database:
Cover File Download View:
- Working Experience
Familiarize yourself with xpath extraction and scrapy convenience
Code address: https://gitee.com/zhubeier/zhebeier/blob/master/ Third major assignment/third topic