1. Operation ①
1.1 operation content
- Requirements: master the serialization output method of Item and Pipeline data in the scene;
Scrapy+Xpath+MySQL database storage technology route crawling Dangdang website book data
-
Candidate sites: http://www.dangdang.com/
-
Key words: Students' free choice
-
Output information:
MySQL database storage and output formats are as follows:

1.2 problem solving process
1.2.1 web page request
Check dangdang.com in the browser and find the keyword python. You can see the url:

So just construct a get request in the script.
Simultaneous page_ The index parameter indicates the number of pages that can be used for page turning
At start_ In the requests method:
for i in range(1,4): #Turn the page and climb the first three pages here
url = "http://search.dangdang.com/?key=python&act=input&page_index="+str(i)
yield scrapy.Request(url=url, callback=self.parse)
1.2.2 acquisition of web content
View the web source code in the browser:
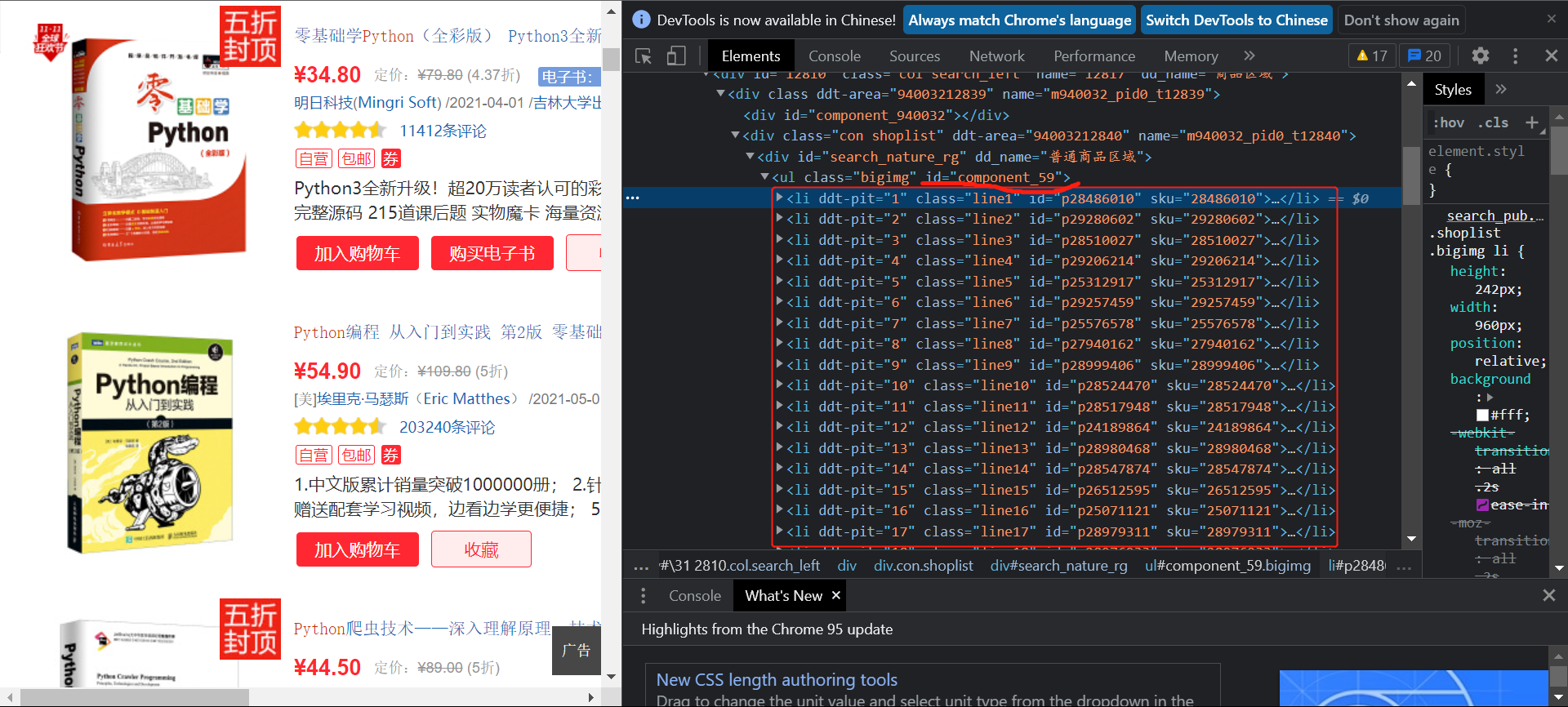
You can see that the content information of the book is stored in the component with id_ The list under the ul tag of 59 can first obtain the whole list and analyze the contents of the list:
BookList = selector.xpath('//*[@ id="component_59"]/li ') # find a list of book information
Then extract the desired information according to the content:
To extract title information:
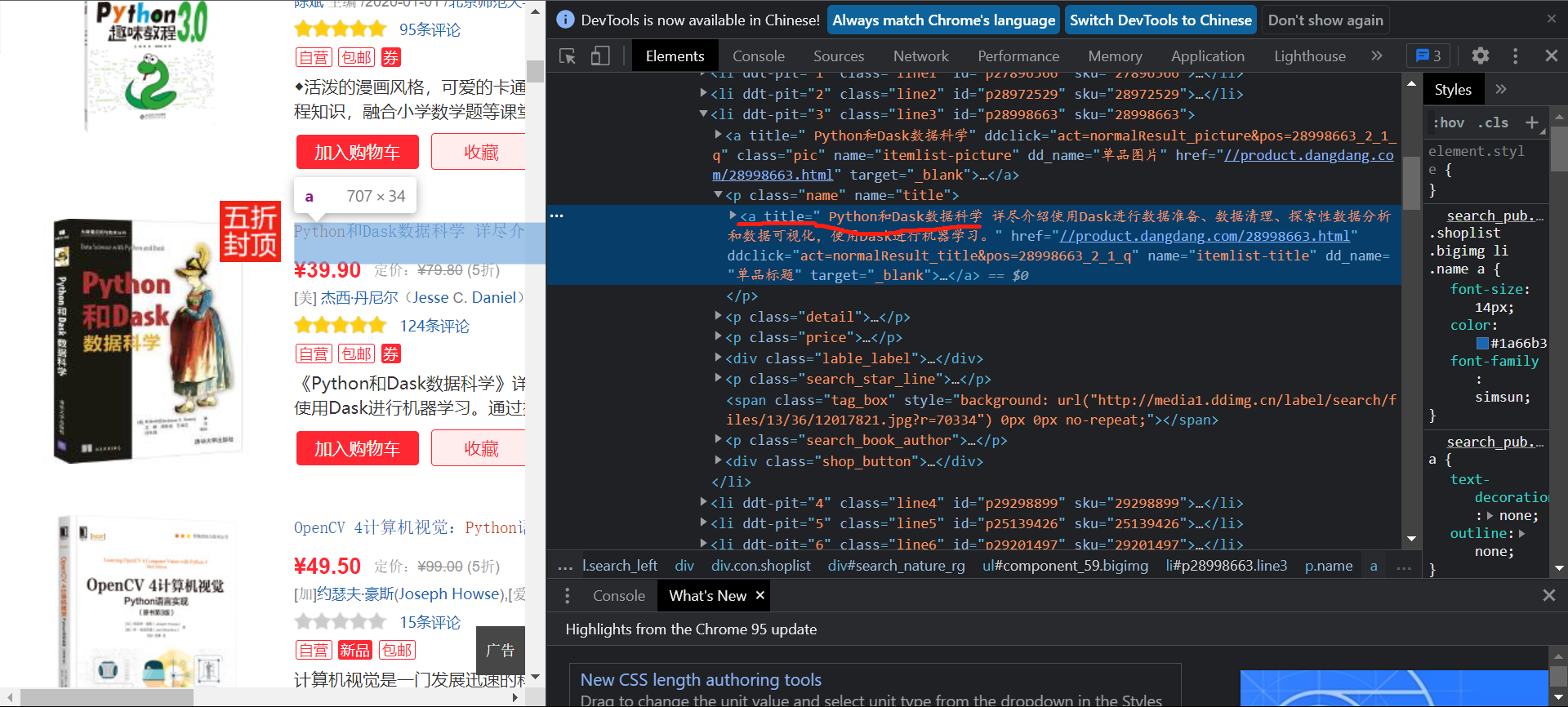
You can see that the content of the title exists in the title attribute value of the a tag under the second element of the list:
title = book.xpath('./a/@title').extract_first() #Book title
You can use this to extract the title content of the book, and other values are similar.
When obtaining the source code of the page:
data = response.body.decode('utf-8')
If utf-8 is set here, an error will be reported:

Error resolution after changing utf-8 to gbk
1.2.3 data storage
First, define the following in item
class Task41Item(scrapy.Item):
title = scrapy.Field()
detail =scrapy.Field()
author =scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
price = scrapy.Field()
id = scrapy.Field()
Used to store the corresponding data content
Operations on mysql are placed in pipelines:
Create table as:
create table if not exists exp4_1(
id int(11) NOT NULL AUTO_INCREMENT,
bTitle text(1000) not null,
bAuthor char(70),
bPublisher char(50),
bDate char(30),
bPrice char(50),
bDetail text(2000),
PRIMARY KEY (id))
Set the self increment of the primary key id.
Then get the corresponding data store from item
sql2 = '''INSERT INTO exp4_1(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) VALUES(%s,%s,%s,%s,%s,%s)''' arg = (item['title'], item['author'], item['publisher'], item['date'], item['price'], item['detail']) cs1.execute(sql2, arg) conn.commit()
Because some of the information in the book is empty:
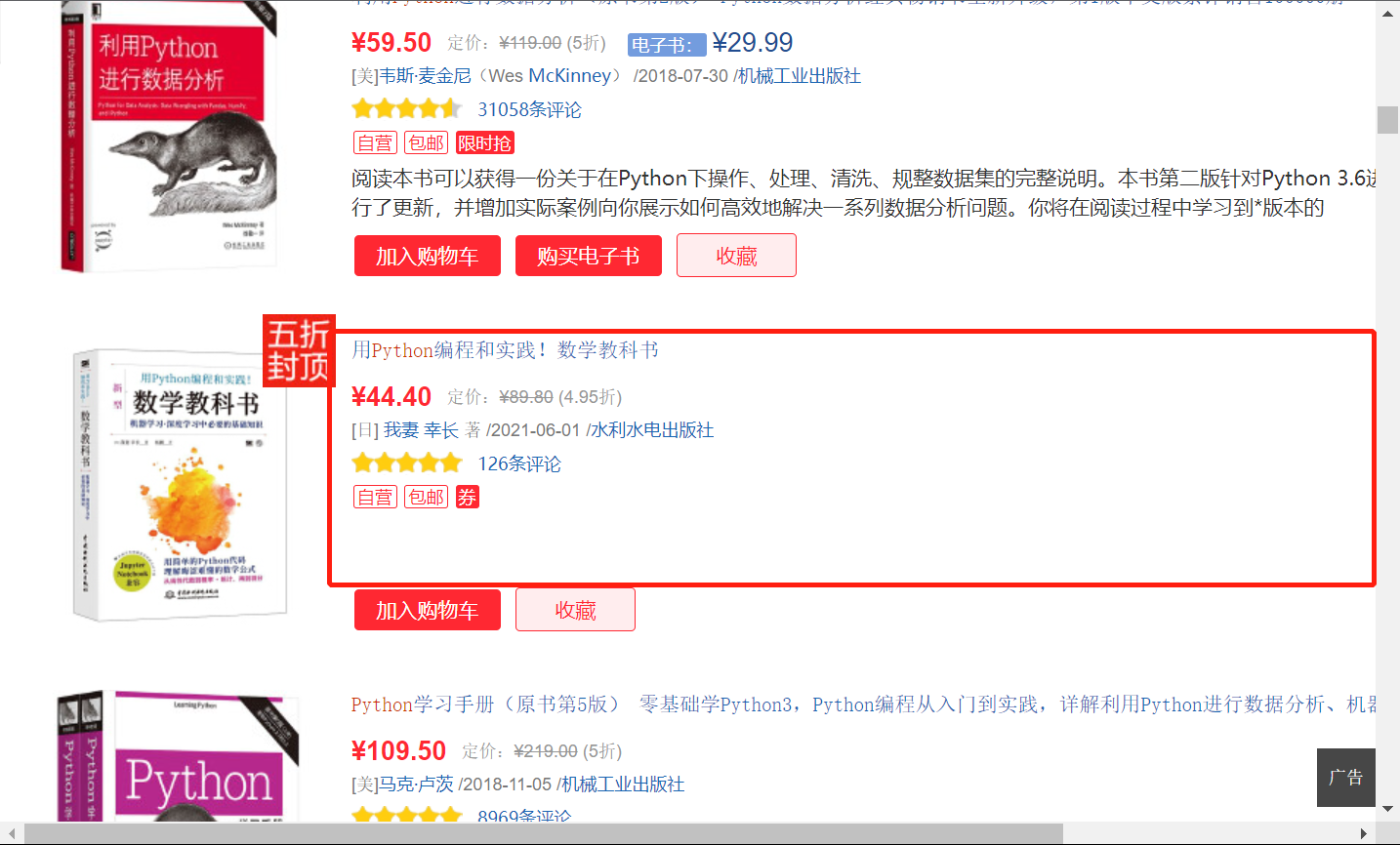
Therefore, if the property value cannot be Null is set when creating the table, an error will occur, so no other property except title is set.
1.3 output
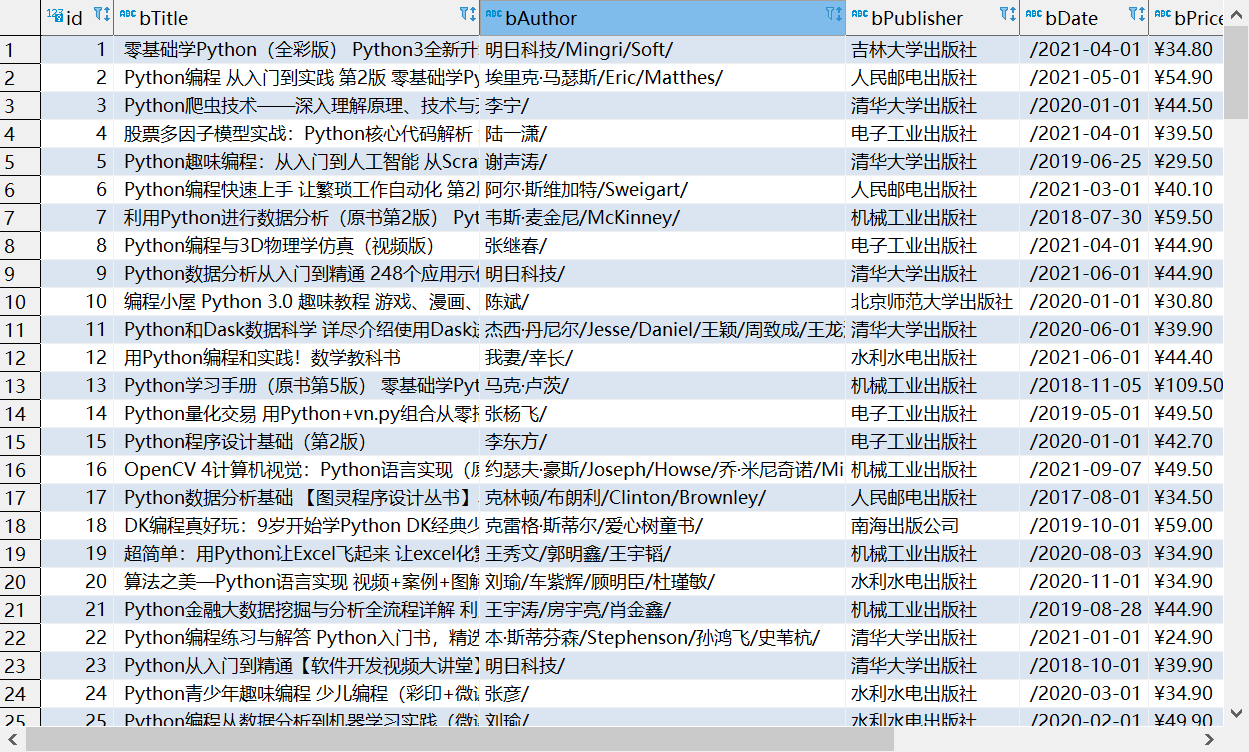

You can see that some information of some lines is empty.
1.4 experience
Through this operation, the use of the scratch crawler framework is consolidated, and it is realized that it is necessary to specify the setting and processing of null values during mysql database operation.
2. Operation ②
1. Requirements: master the serialization output method of Item and Pipeline data in the scene; Crawl the foreign exchange website data using the technology route of "scratch framework + Xpath+MySQL database storage".
-
Candidate website: China Merchants Bank Network: http://fx.cmbchina.com/hq/
-
Output information: MYSQL database storage and output format
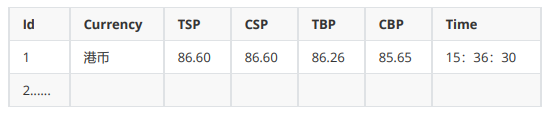
2.2 problem solving process
2.2.1 initiate request
Ibid., at start_ Write the initiation request in requests:
yield scrapy.FormRequest(url=self.url, callback=self.parse)
This question does not need to carry parameters.
2.2.2 acquisition of page content
View content in browser:
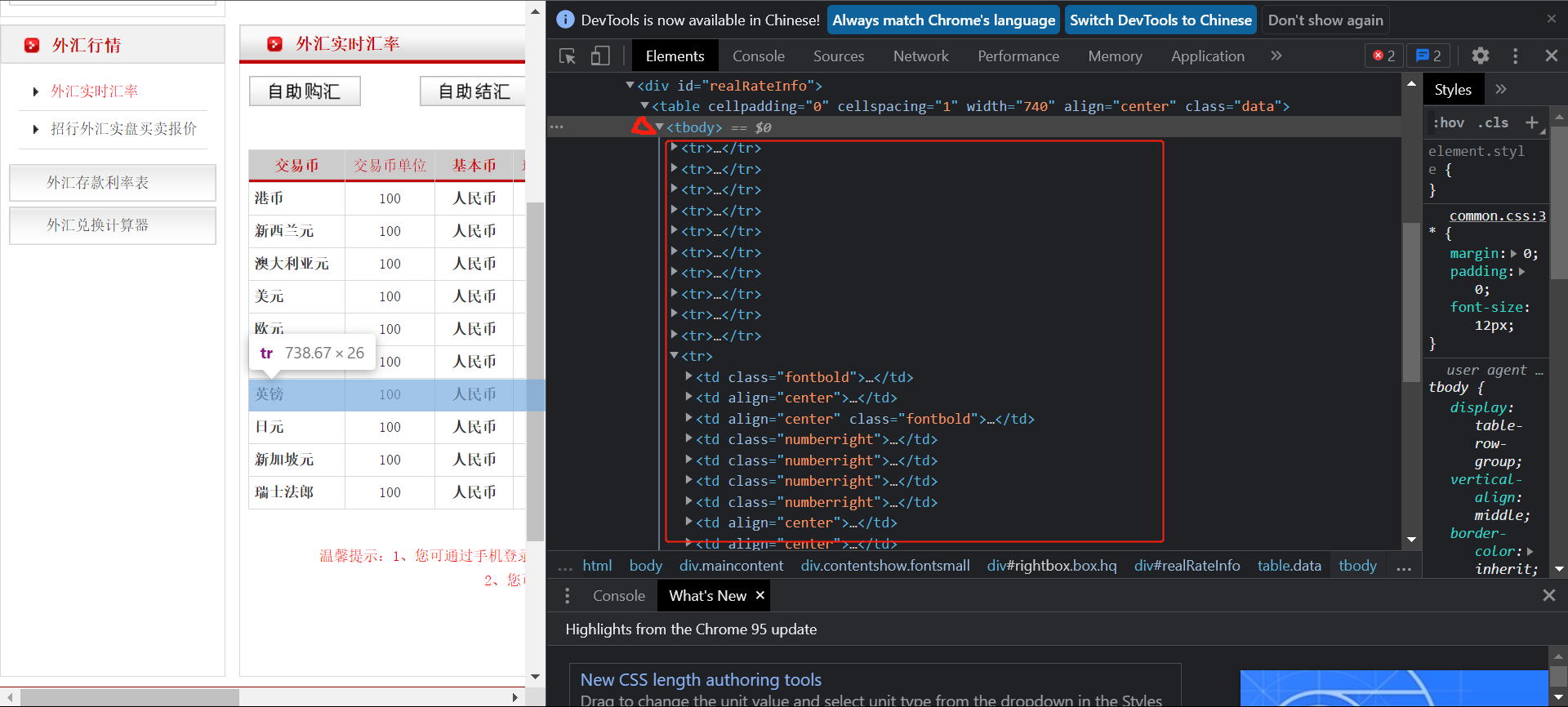
You can see that the data is stored in a table.
If you directly copy the xpath on the web page to find the content:
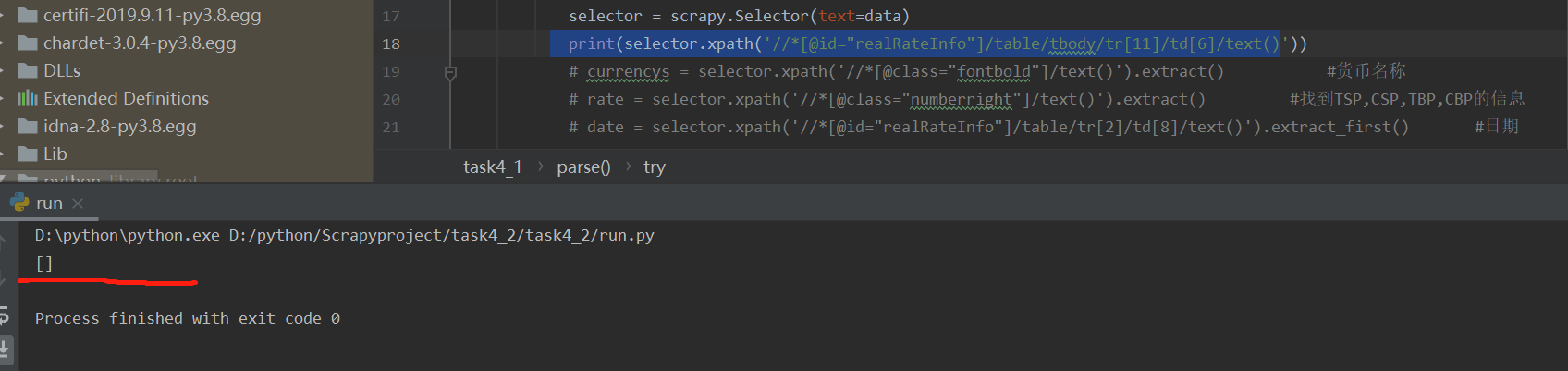
You can see that the data cannot be found.
After deleting tbody in the copied xpath, the data can be found correctly:
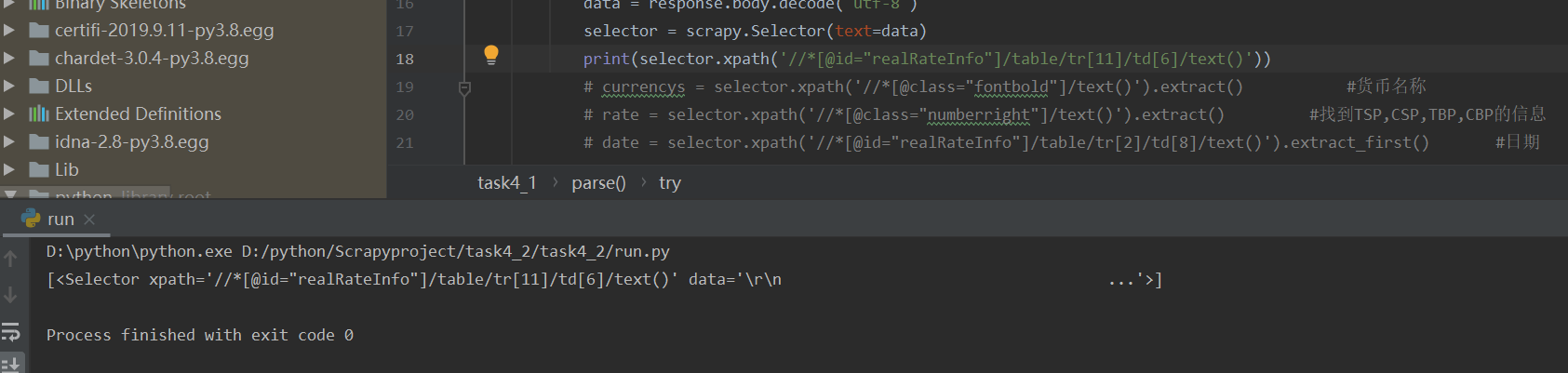
The reason is that the tbody seen in the browser is not available when writing web pages, but added by later software.
In addition, contrary to the first question, if the code is set to gbk, an error will be reported:

However, if it is set to utf-8, it can work normally.
When searching for data, I use the name of class to search directly, and then process the searched data.
rate = selector.xpath('//*[@ class = "numberright"] / text()). Extract() # find the information of TSP, CSP, TBP and CBP
2.2.3 data storage
There is no gap with the above question.
items:
currency = scrapy.Field() TSP= scrapy.Field() CSP= scrapy.Field() TBP= scrapy.Field() CBP= scrapy.Field() date = scrapy.Field()
Create table:
create table if not exists exp4_2(
id int(11) NOT NULL AUTO_INCREMENT,
Currency char(200) not null,
TSP char(70) not null,
CSP char(50) not null,
TBP char(30) not null,
CBP char(50) not null,
Date char(40) not null,
PRIMARY KEY (id))
2.3 output
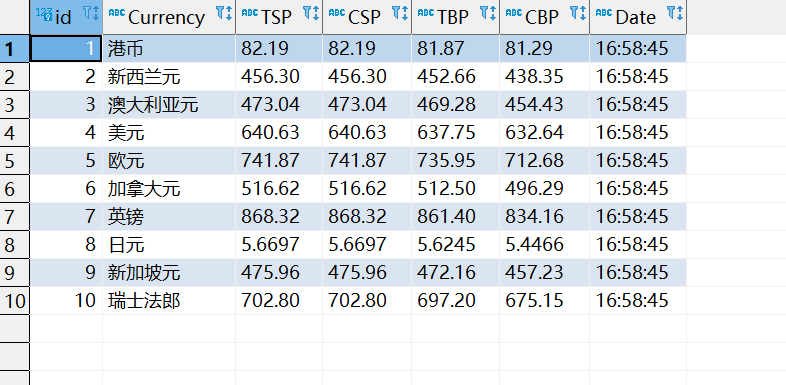
2.4 experience
Through this operation, the use of the scratch crawler framework is consolidated. At the same time, it is found that the content of the web source code viewed in the browser may be slightly different from that crawled down. It needs careful observation and treatment.
3. Operation ③
3.1 operation contents
. requirements: be familiar with Selenium's search for HTML elements, crawling Ajax web page data, waiting for HTML elements, etc;
Use Selenium framework + MySQL database storage technology route to crawl the stock data information of "Shanghai and Shenzhen A shares", "Shanghai A shares" and "Shenzhen A shares".
2. Candidate website: Dongfang fortune.com: http://quote.eastmoney.com/center/gridlist.html#hs_a_board
3. Output information:
MySQL database storage and output formats are as follows:,
The header should be named in English, for example: serial number id, stock code: bStockNo..., which is defined and designed by students themselves:

3.2 problem solving process
3.2.1 initiate request
Using selenium, first create a webdriver, and then use the get method to initiate the request.
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
chrome_options = Options()
#chrome_options.add_argument('--headless') #Set browser not to display
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
3.2.2 acquisition of page content
View the location of the data store in the browser:
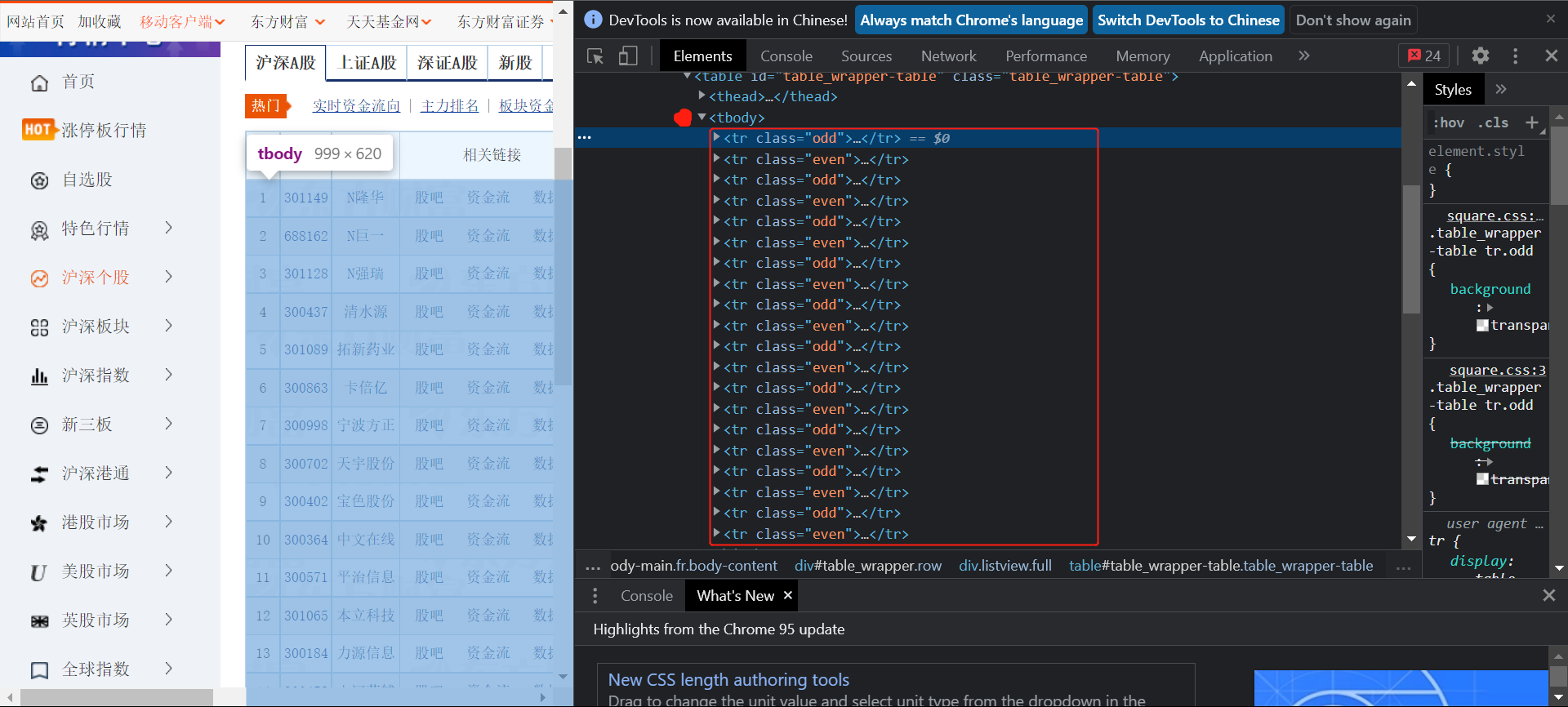
You can see the storage method of the same question 2. Try to find tbody through xpath
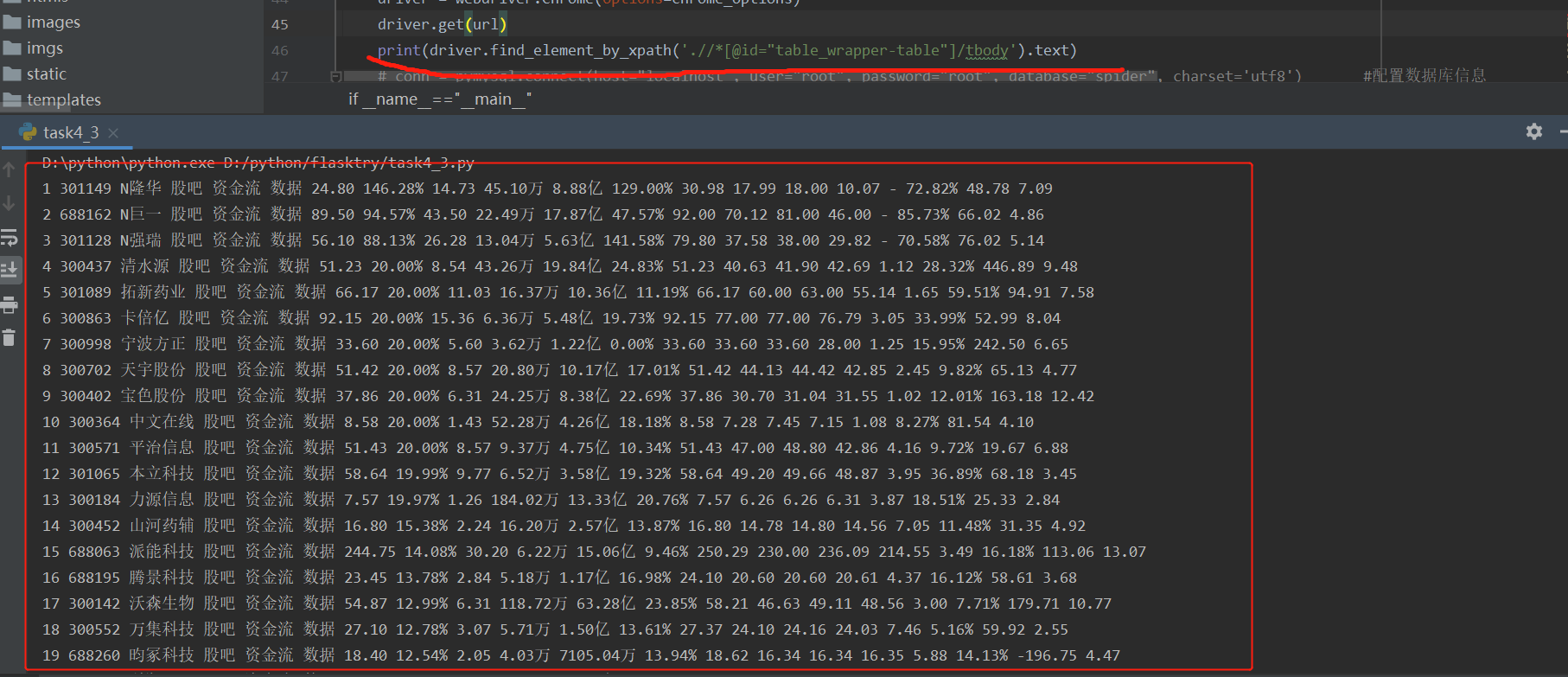
You can see that all the contents of the web page are displayed.
Then replace the plate:
Button to view the replacement section on the web page:
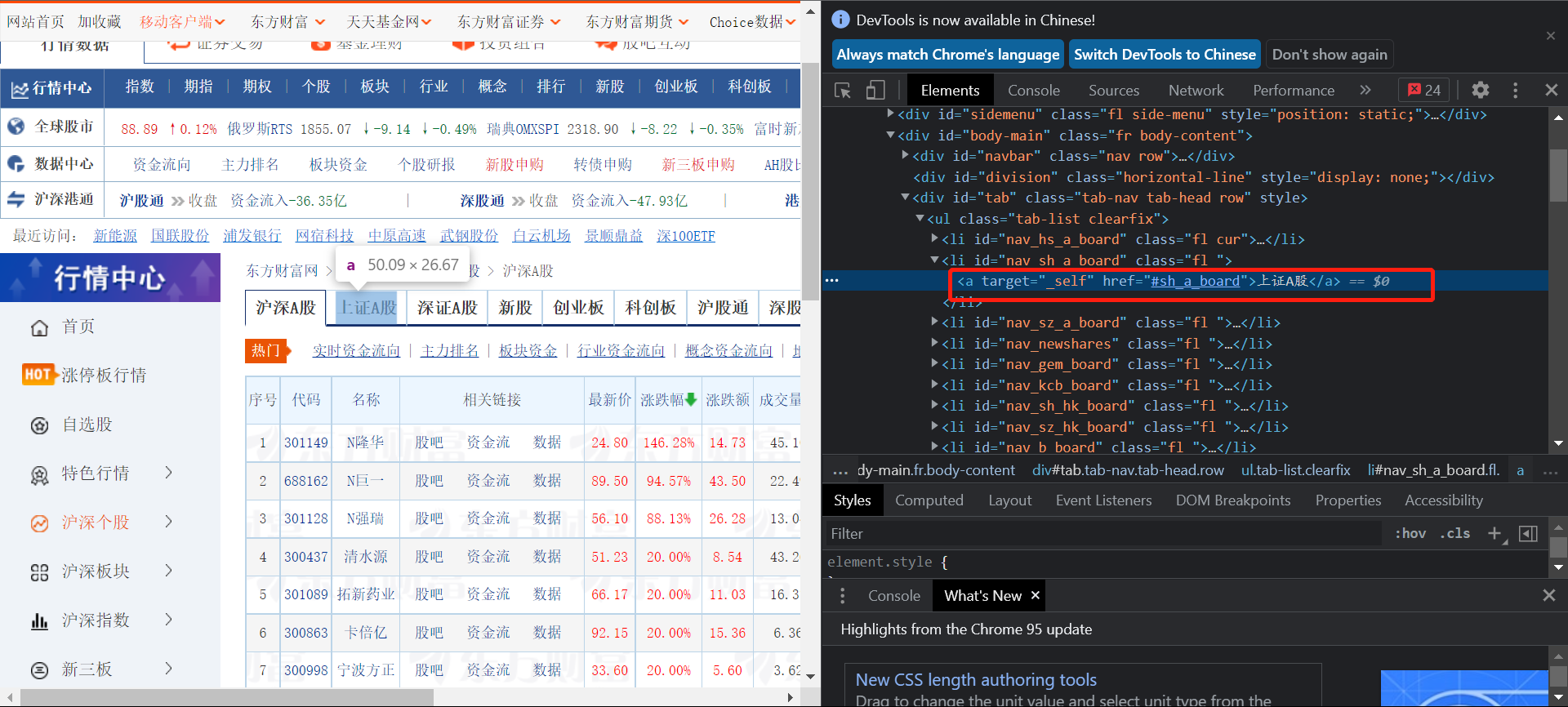
Then search through the corresponding xpath and click. click() to replace the plate:
page2 = driver.find_element_by_xpath('//*[@id="nav_sh_a_board"]/a')
page2.click()
3.2.3 data storage
The same as the previous two questions, use pymysql to link the database
Create table:
create table if not exists exp4_3(
id char(100) not null,
Stockcode char(30) not null,
Stock char(50) not null,
newquotation char(50) not null,
RFrate char(30) not null,
RFnum char(50) not null,
Turnover char(50) not null,
Tnum char(30) not null,
amplitude char(50) not null,
highest char(50) not null,
losest char(30) not null,
today char(50) not null,
yesterday char(50) not null,
PRIMARY KEY (id))
'''
The corresponding data is obtained by split segmentation through the above content,
arg = (name + sqldata[0], sqldata[1], sqldata[2], sqldata[6], sqldata[7], sqldata[8], sqldata[9], sqldata[10],
sqldata[11], sqldata[12], sqldata[13], sqldata[14], sqldata[15])
cs1.execute(sql2, arg)
conn.commit()
At the same time, it should be noted that there are some unnecessary contents after segmentation:
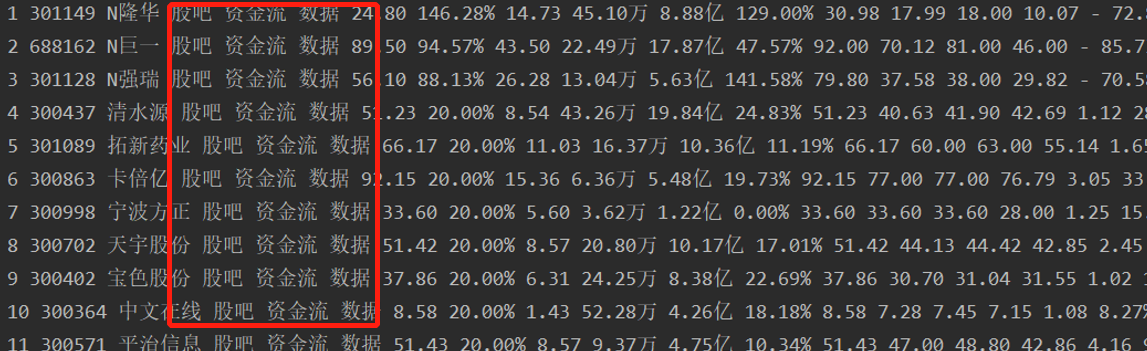
Pay attention to removal.
3.3 output
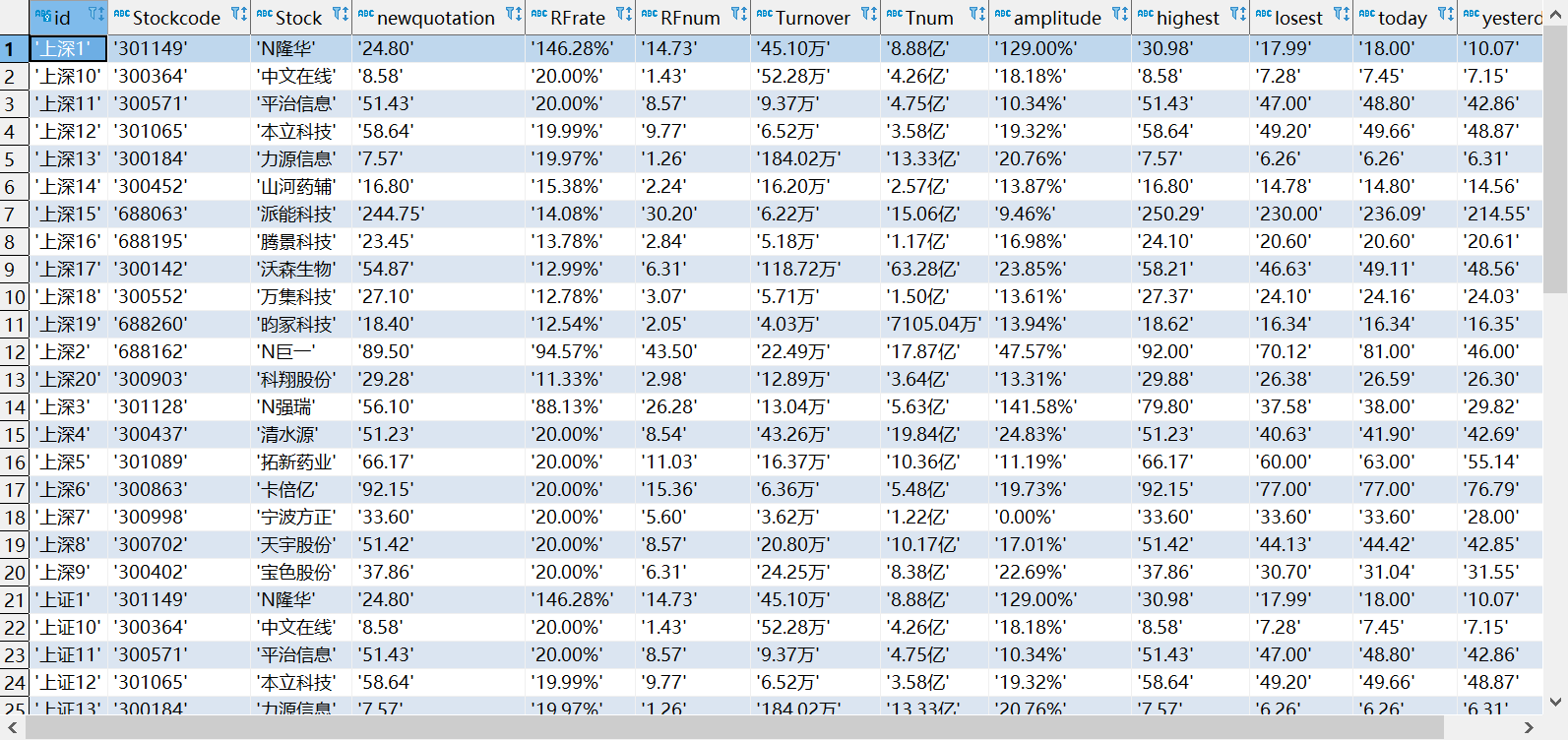
I added the name of each section before the primary key id to avoid duplication.
3.4 experience
This job consolidates the use of selenium and mysql database. At the same time, pay attention to check whether the crawling information is useful information.