The fifth practice of data mining
Assignment 1
Jingdong information crawling experiment
Job content
- Requirements: be familiar with Selenium's search for HTML elements, crawling Ajax web page data, waiting for HTML elements, etc. Use Selenium framework to crawl the information and pictures of certain commodities in Jingdong Mall.
- Candidate sites: http://www.jd.com/
- Key words: Students' free choice
Practice process
Reproduce selenium crawling Jingdong Mall, core crawling code
def processSpider(self): try: time.sleep(1) print(self.driver.current_url) lis =self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']") for li in lis: # We find that the image is either in src or in data-lazy-img attribute self.count += 1 # Quantity plus one try: src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src") except: src1 = "" try: src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img") except: src2 = "" try: price = li.find_element_by_xpath(".//div[@class='p-price']//i").text except: price = "0" try: note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text mark = note.split(" ")[0] mark = mark.replace("Love Dongdong\n", "") mark = mark.replace(",", "") note = note.replace("Love Dongdong\n", "") note = note.replace(",", "") except: note = "" mark = "" self.No = self.No + 1 no = str(self.No) while len(no) < 6: no = "0" + no print(no, mark, price) if src1: src1 = urllib.request.urljoin(self.driver.current_url, src1) p = src1.rfind(".") mFile = no + src1[p:] elif src2: src2 = urllib.request.urljoin(self.driver.current_url, src2) p = src2.rfind(".") mFile = no + src2[p:] if src1 or src2: T = threading.Thread(target=self.download, args=(src1, src2, mFile)) T.setDaemon(False) T.start() self.threads.append(T) else: mFile = "" self.insertDB(no, mark, price, note, mFile) # insert database if self.count >= 100: # If the number exceeds 100, exit print("Crawling to 100 items, end crawling") return # Remove the data from the next page until the last page try: self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']") except: nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']") time.sleep(1) nextPage.click() self.processSpider() except Exception as err: print(err)
Code saved to database
def startUp(self, url, key): # Initializing Chrome browser chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') self.driver = webdriver.Chrome(chrome_options=chrome_options) # Initializing variables self.threads = [] self.No = 0 self.imgNo = 0 self.count = 0 # Record commodity quantity # Initializing database try: self.con = sqlite3.connect("phones.db") self.cursor = self.con.cursor() try: # If there are tables, delete them self.cursor.execute("drop table phones") except: pass try: sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))" self.cursor.execute(sql) except: pass except Exception as err: print(err) # Initializing images folder try: if not os.path.exists(MySpider.imagePath): os.mkdir(MySpider.imagePath) images = os.listdir(MySpider.imagePath) for img in images: s = os.path.join(MySpider.imagePath, img) os.remove(s) except Exception as err: print(err) self.driver.get(url) # Get web page keyInput = self.driver.find_element_by_id("key") # Find input box keyInput.send_keys(key) # Enter keywords keyInput.send_keys(Keys.ENTER) def closeUp(self): try: self.con.commit() self.con.close() self.driver.close() except Exception as err: print(err) def insertDB(self, mNo, mMark, mPrice, mNote, mFile): try: sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)" self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile)) except Exception as err: print(err)
experimental result
As a result, I can only crawl 100 items
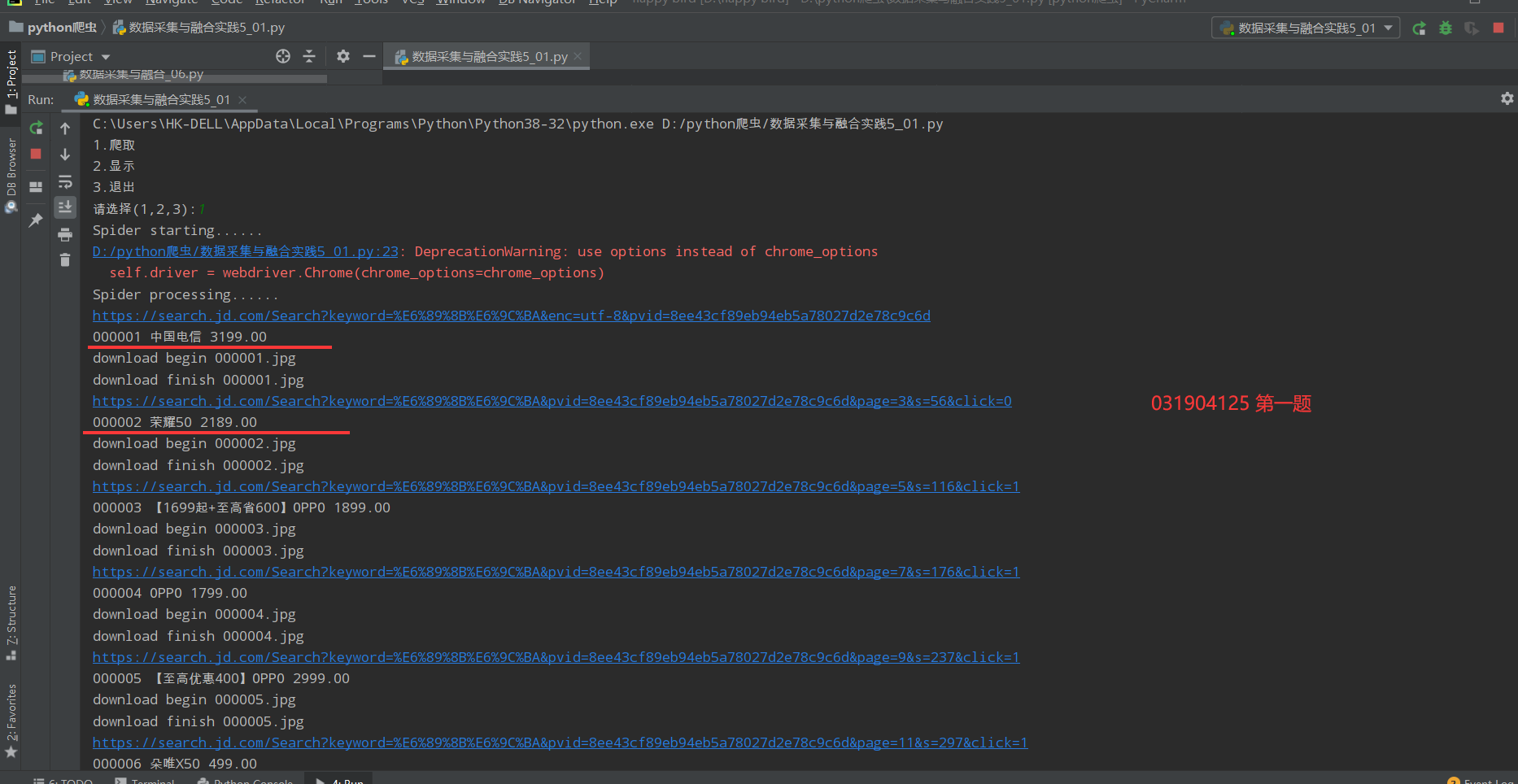
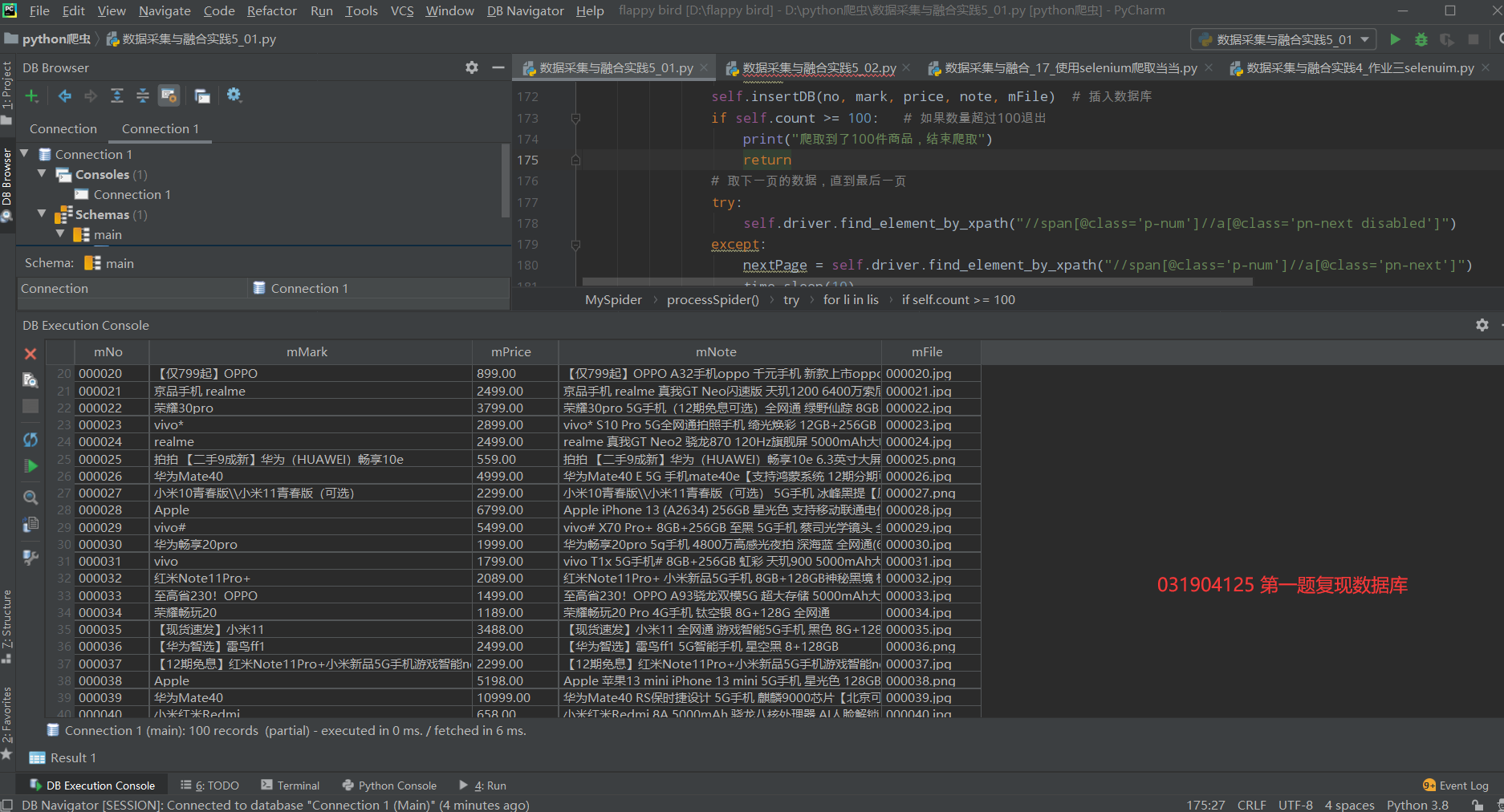
Database save results
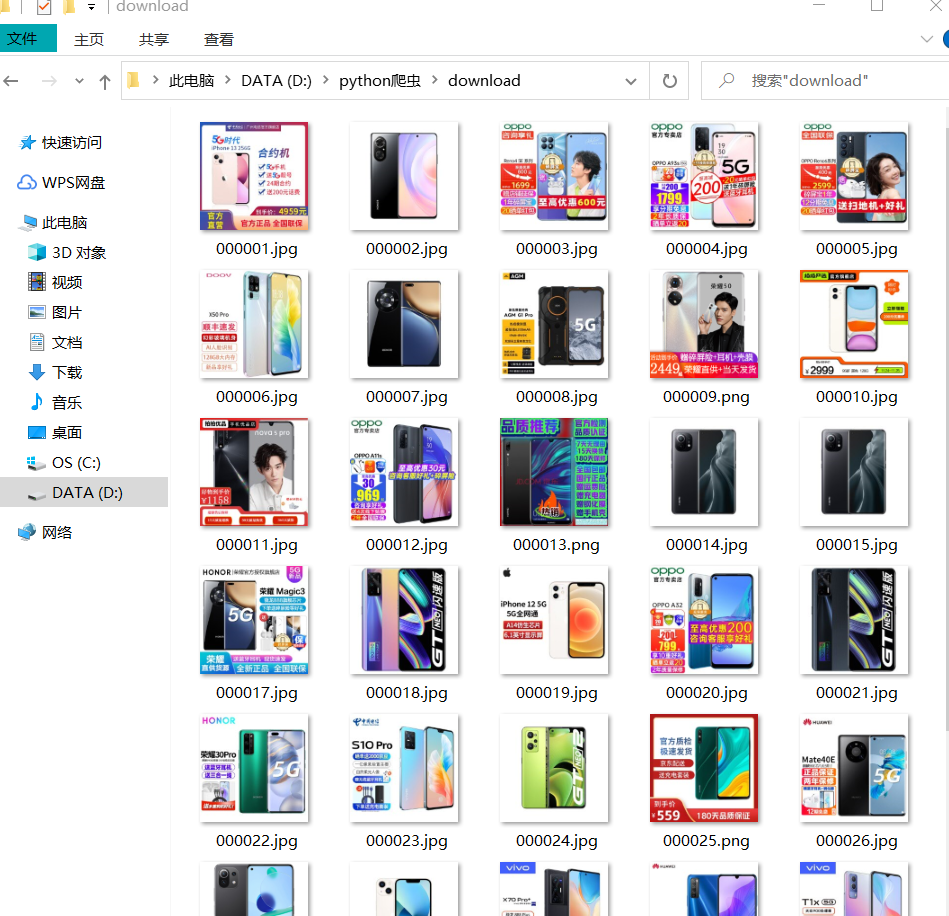
Picture saving results:
Experimental experience
In this experiment, I consolidated my knowledge of selenium crawling website, deeply studied selenium related operations, and learned to store databases in two databases, including MYSQL and SQLite
Assignment 2
MOOC crawling test
Job content
-
Requirements: be familiar with Selenium's search for HTML elements, realizing user simulated Login, crawling Ajax web page data, waiting for HTML elements, etc. Use Selenium framework + MySQL to crawl the course resource information of China mooc network (course number, course name, teaching progress, course status and course picture address), and store the picture in the imgs folder under the root directory of the local project. The name of the picture is stored with the course name.
-
Candidate website: China mooc website: https://www.icourse163.org
Practice process
1. Simulate login, find the login button, click the login button, find the account and password input box, enter the login information with sendkey(), and click the login button. The only place where there is a jam is that the slider verification will appear. Later, check Baidu. There is a blog that also encountered such a problem. He uses a name called browser.switch_to.frame(), there will be no slider verification. I tried it and it's OK
def search(url): try: browser.get(url) time.sleep(1) # Pause for a second browser.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div').click() # Click the login button time.sleep(1) # Pause for a second browser.find_element_by_xpath('/html/body/div[13]/div[2]/div/div/div/div/div[2]/span').click() # Click other login methods time.sleep(1) # Pause for a second browser.find_element_by_xpath('/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[1]/ul/li[2]').click() # Click the mobile number to log in time.sleep(1) # Pause for a second browser.switch_to.frame(browser.find_elements_by_tag_name("iframe")[1]) # Jump to mobile login interface time.sleep(1) # Pause for a second browser.find_element_by_xpath("//input[@id='phoneipt']").send_keys("15160468797") browser.find_element_by_xpath('//input[@placeholder = "please enter password"]').send_keys("@huan301505") # Enter login information time.sleep(1) # Pause for a second browser.find_element_by_xpath('//*[@id="submitBtn"]').click() # Click login time.sleep(3) # Pause for three seconds and log in browser.find_element_by_xpath('//*[@id="privacy-ok"]').click() # Click the "my course" button time.sleep(1) # Pause for a second browser.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[3]/div[4]/div').click() time.sleep(1) print("Course information is as follows:") get_data() # Get the first page of course data content except Exception as err: print(err)
2. Crawl relevant information and save data
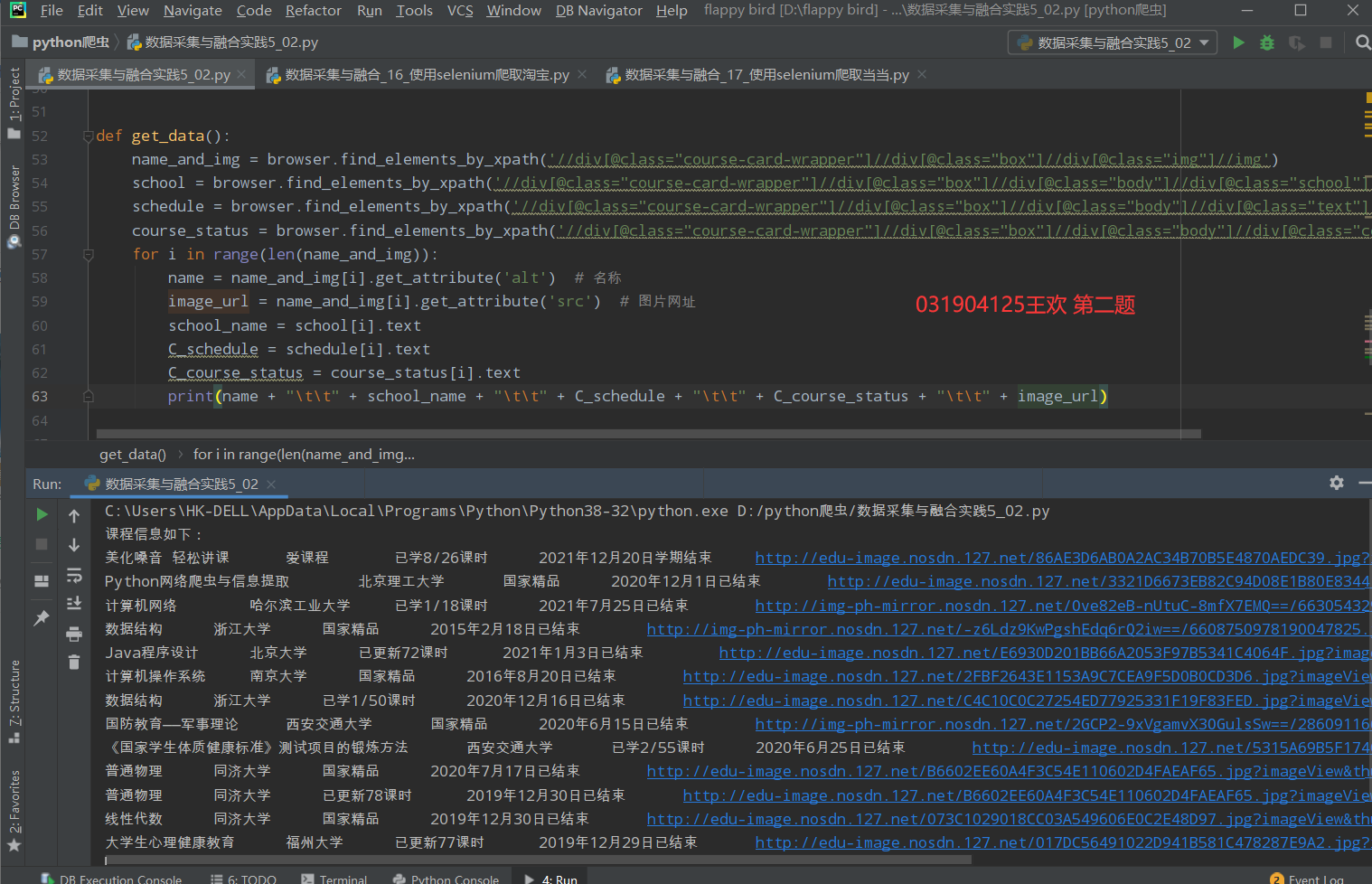
def get_data(): global total_num name_and_img = browser.find_elements_by_xpath('//div[@class="course-card-wrapper"]//div[@class="box"]//div[@class="img"]//img') school = browser.find_elements_by_xpath('//div[@class="course-card-wrapper"]//div[@class="box"]//div[@class="body"]//div[@class="school"]//a') schedule = browser.find_elements_by_xpath('//div[@class="course-card-wrapper"]//div[@class="box"]//div[@class="body"]//div[@class="text"]//a') course_status = browser.find_elements_by_xpath('//div[@class="course-card-wrapper"]//div[@class="box"]//div[@class="body"]//div[@class="course-status"]') for i in range(len(name_and_img)): name = name_and_img[i].get_attribute('alt') # name image_url = name_and_img[i].get_attribute('src') # Picture URL school_name = school[i].text C_schedule = schedule[i].text C_course_status = course_status[i].text print(name + "\t\t" + school_name + "\t\t" + C_schedule + "\t\t" + C_course_status + "\t\t" + image_url) image_name = "./img/The first" + str(page_num) + "Page" + str(i+1) + "Zhang.jpg" # The path and location where the picture is to be saved urllib.request.urlretrieve(image_url, filename=image_name) # Save picture mooc_DB.insertDB(total_num, name, school_name, C_schedule, C_course_status, image_url) # insert data total_num += 1 # Total quantity+1
3. Page turning. I use the. click() method to find the button on the next page and click it directly to turn the page
def next_page(): search(url) global page_num while page_num < 2: browser.find_element_by_xpath('//*[@id="j-coursewrap"]/div/div[2]/ul/li[4]/a').click() # Click next time.sleep(1) page_num += 1 get_data() # Get data for my course mooc_DB.closeDB() # close database
4. Finally, there is the code saved in the database, which is very similar to the previous code, connecting, closing and inserting
class mooc: # Open database def openDB(self): print("open") try: self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="huan301505", db="scraw", charset="utf8") # The first step is to connect to the mysql database self.cursor = self.con.cursor() # Set cursor # You need to create a database outside in advance self.cursor.execute("delete from mooc") # Empty data table self.opened = True except Exception as err: print(err) self.opened = False # close database def closeDB(self): try: if self.opened: self.con.commit() # Submit self.con.close() # Close connection self.opened = False print("closed") print("Climb successfully!") except Exception as err: print(err) # insert database def insertDB(self, id, name, school, schedule, course_status, image_url): try: self.cursor.execute( "insert into mooc(id,name,school,schedule,course_status,image_url) values (%s,%s,%s,%s,%s,%s)", (id, name, school, schedule, course_status, image_url)) except Exception as err: print(err)
experimental result
Console results:
For the database results, I insert mysql, and then view it. I use the work provided by mysql_ Bench visual interface:
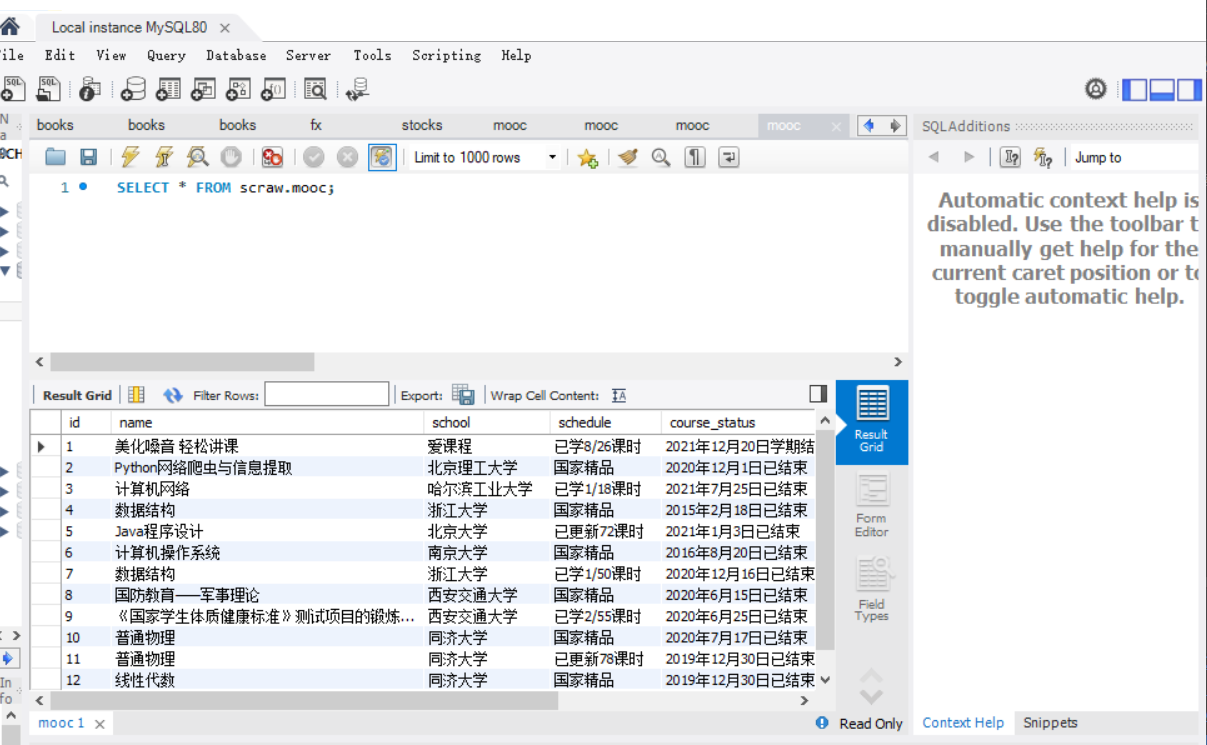
Picture saving results:
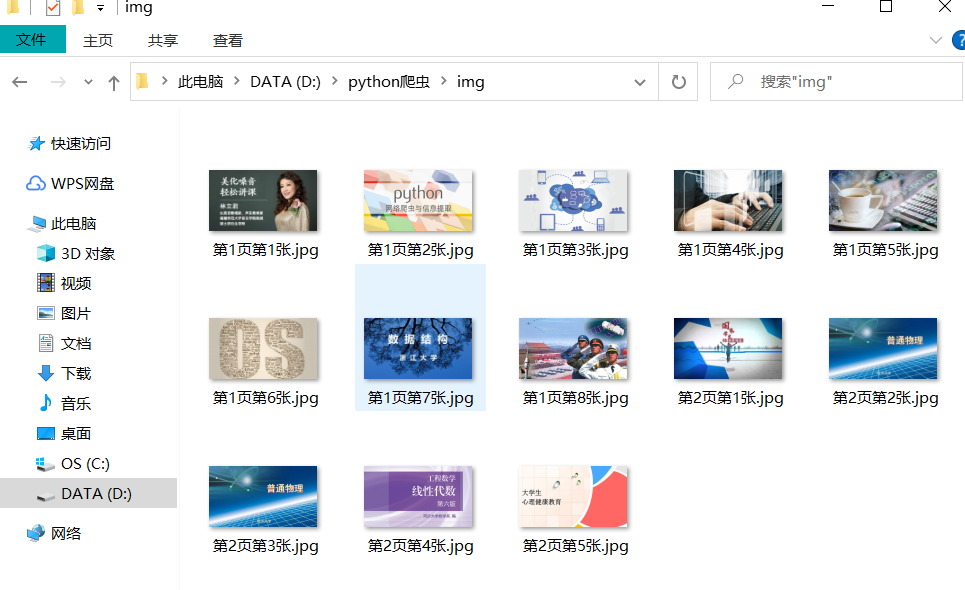
Experimental experience
In this experiment, I consolidated my knowledge of selenium crawling website, deeply studied selenium related operations, and learned to store databases in two databases, including MYSQL and SQLite
Assignment 3
Flume experiment
Job content
-
Requirements: understand Flume architecture and key features, and master the use of Flume to complete log collection tasks. Complete Flume log collection experiment, including the following steps:
Task 1: open MapReduce service
Task 2: generate test data from Python script
Task 3: configure Kafka
Task 4: install Flume client
Task 5: configure Flume to collect data
Practice process
Task 1: open MapReduce service
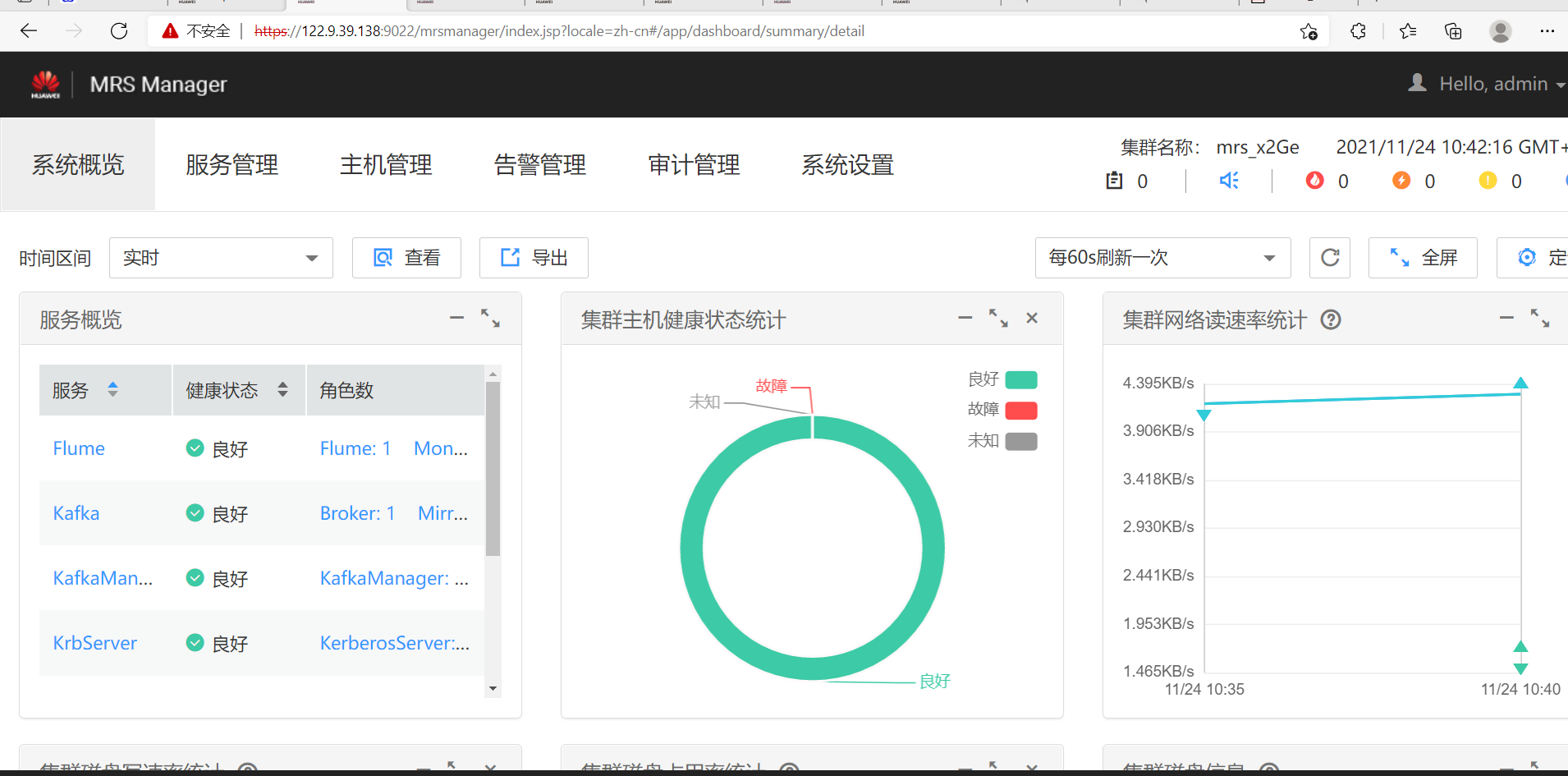
Follow the pdf released by the teacher step by step. Finally, open MRS and enter the manager interface as follows
Task 2: generate test data from Python script
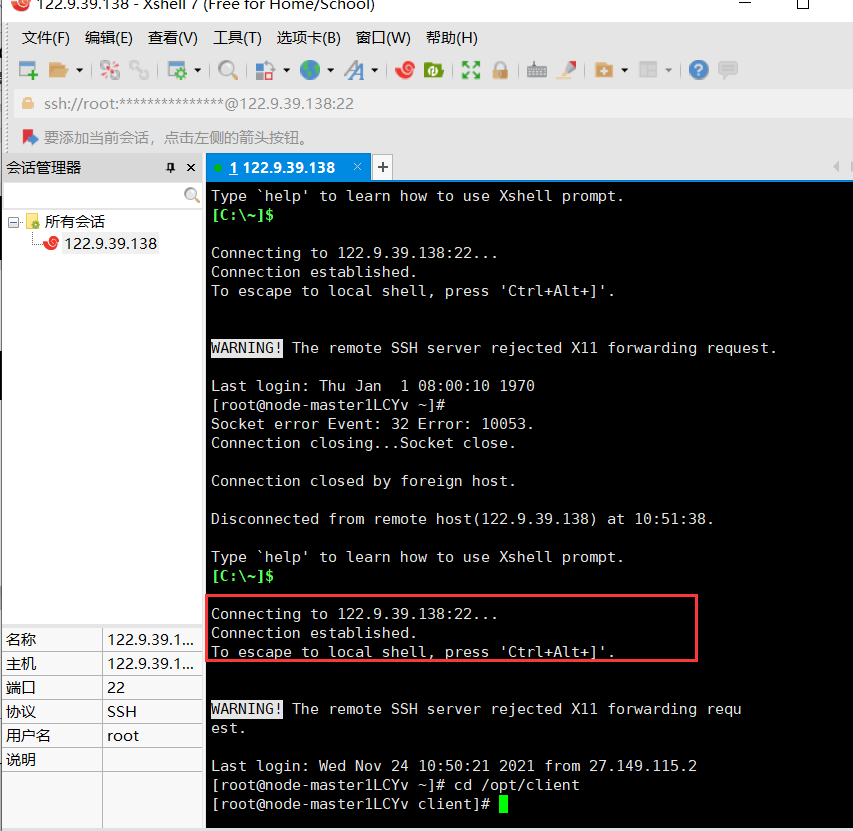
1. Open xshell and establish a connection
2. Transfer the autodatapython.py file to the opt/client / folder
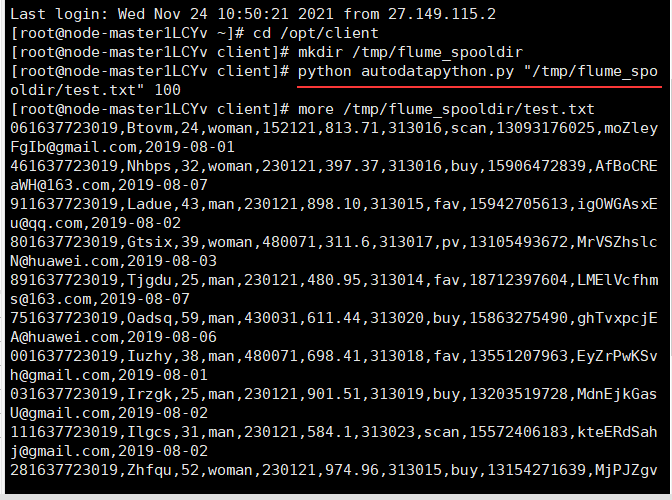
3. Implementation
Task 3: configure Kafka
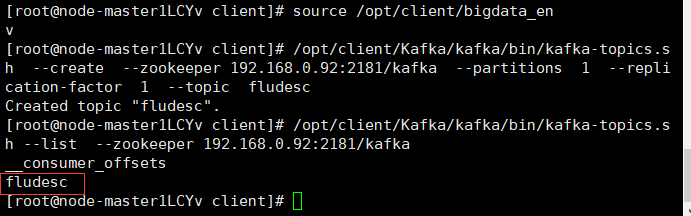
- First, set the environment variable and execute the source command to make the variable effective
- Create topic in kafka
- To view topic information:
Task 4: install Flume client
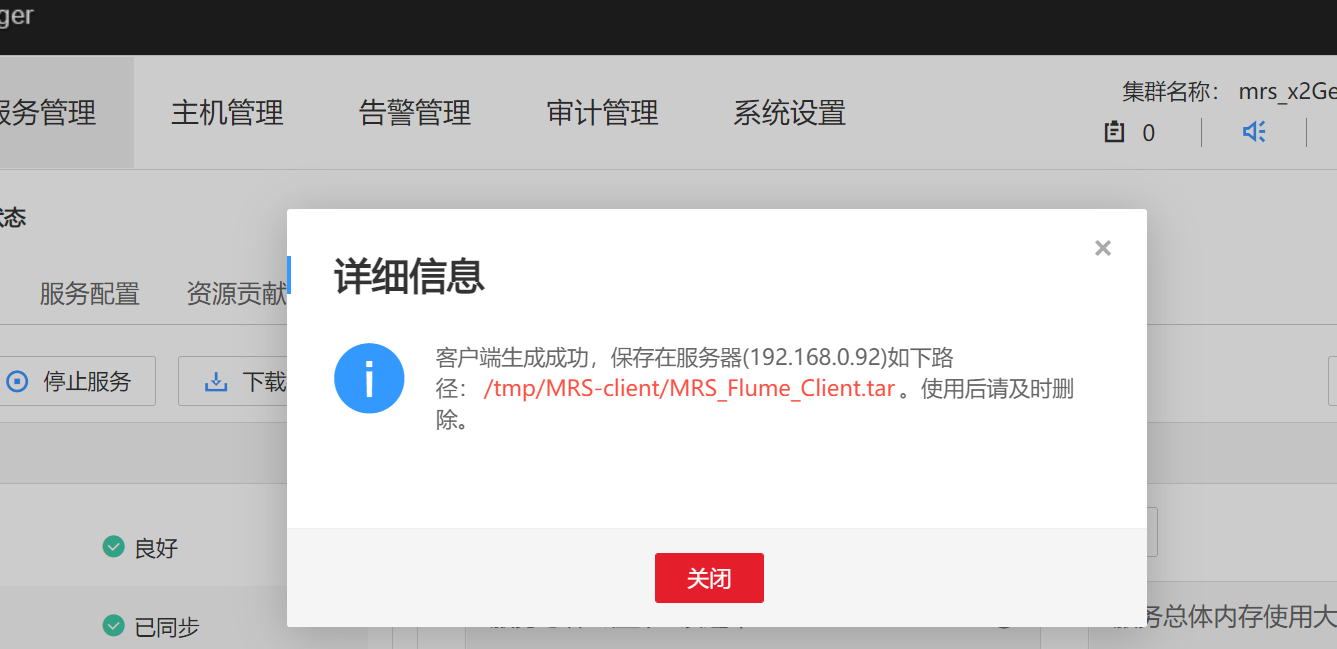
Enter the MRS Manager cluster management interface, open service management, click flume, enter flume service, and click download client
Unzip the flume client file, verify the package, and unzip the "MRS_Flume_ClientConfig.tar" file
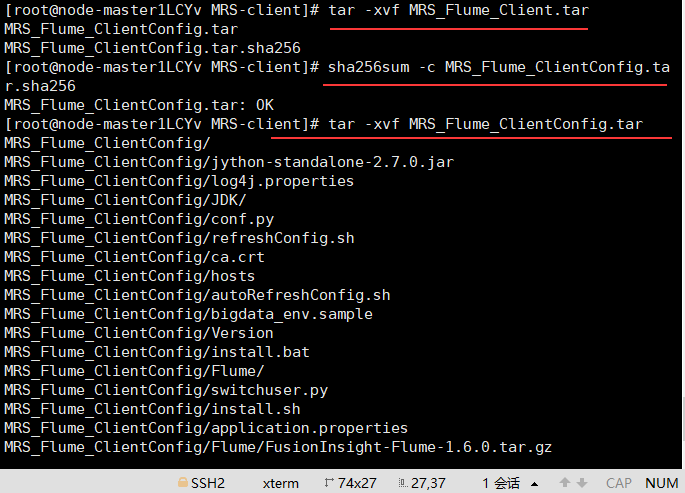
Install flume environment variable
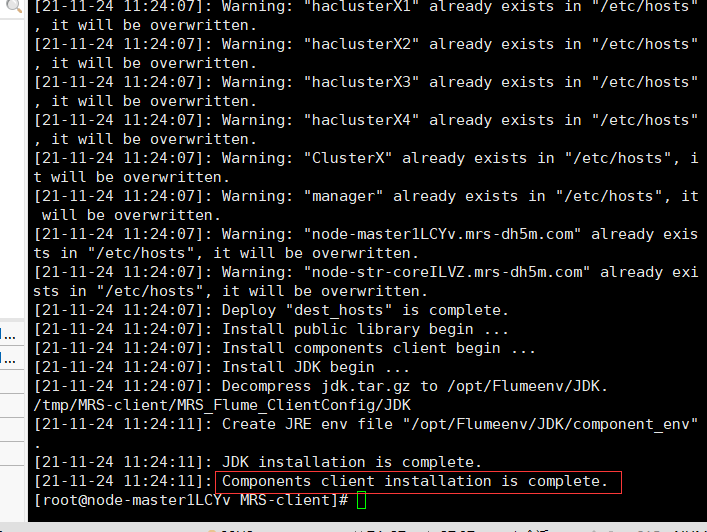
Unzip the flume client
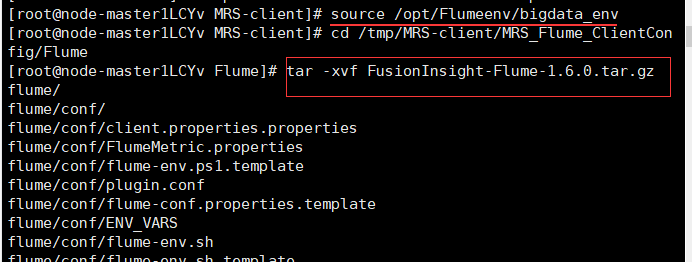
Install flume client

Restart flume service
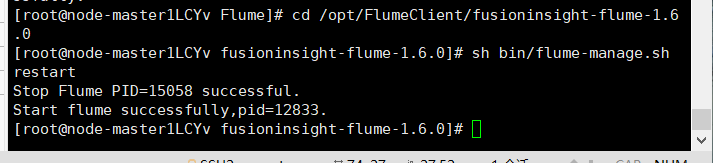
Task 5: configure Flume to collect data
Modify the configuration file and import the file directly from the outside
Log in to the master node, the source configuration file, and execute the following commands
Open another window and execute the python test instructions in 2.2.1. The original window can capture data
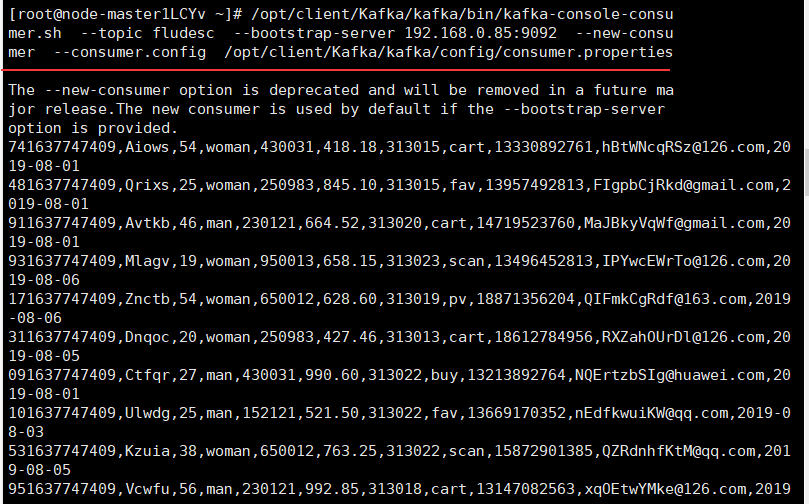
Experimental experience
This experiment mainly introduces the acquisition of real-time stream data through flume, preliminarily understands the relevant knowledge of flume log acquisition, and benefits a lot.
Finally, attach the code of my previous assignment: Data acquisition and fusion: data acquisition and fusion practice assignment - Gitee.com