-
Operation ①:
1) Crawling pictures from China Meteorological Network
– Requirements: Requirements: specify a website and crawl all the pictures in the website, such as China Meteorological Network( http://www.weather.com.cn).
– use single thread and multi thread crawling respectively. (the number of crawling pictures is limited to the last 3 digits of the student number)
– Output information: output the downloaded Url information on the console, store the downloaded image in the images subfolder, and give a screenshot.
Completion process (single thread):
1. Send a request to the page to get the link of the page where the picture is located:
def get_url(start_url):
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
urls = soup.select("a")
i = 0
for a in urls:
href = a["href"]
imageSpider(href, i + 1)
i = i + 1
if count > 110: # Climb 110 sheets
break
2. Climb the download links of all the pictures on this page and download them locally:
def imageSpider(start_url, cous):
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
if count > 110:
break
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url, cous)
except Exception as err:
print(err)
except Exception as err:
print(err)
3. Download the image to the specified path function:
def download(url, cous):
global count
try:
count = count + 1
# Extract file suffix extension
if url[len(url) - 4] == ".":
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
path = r"C:\Users\Huang Dunn\PycharmProjects\pythonProject3\images\\" + "The first" + str(count) + "Zhang" + ".jpg" # Specify download path
with open(path, 'wb') as f:
f.write(data)
f.close()
print("downloaded " + str(cous) + "page" + str(count) + ext)
except Exception as err:
print(err)
4. Display of output results:
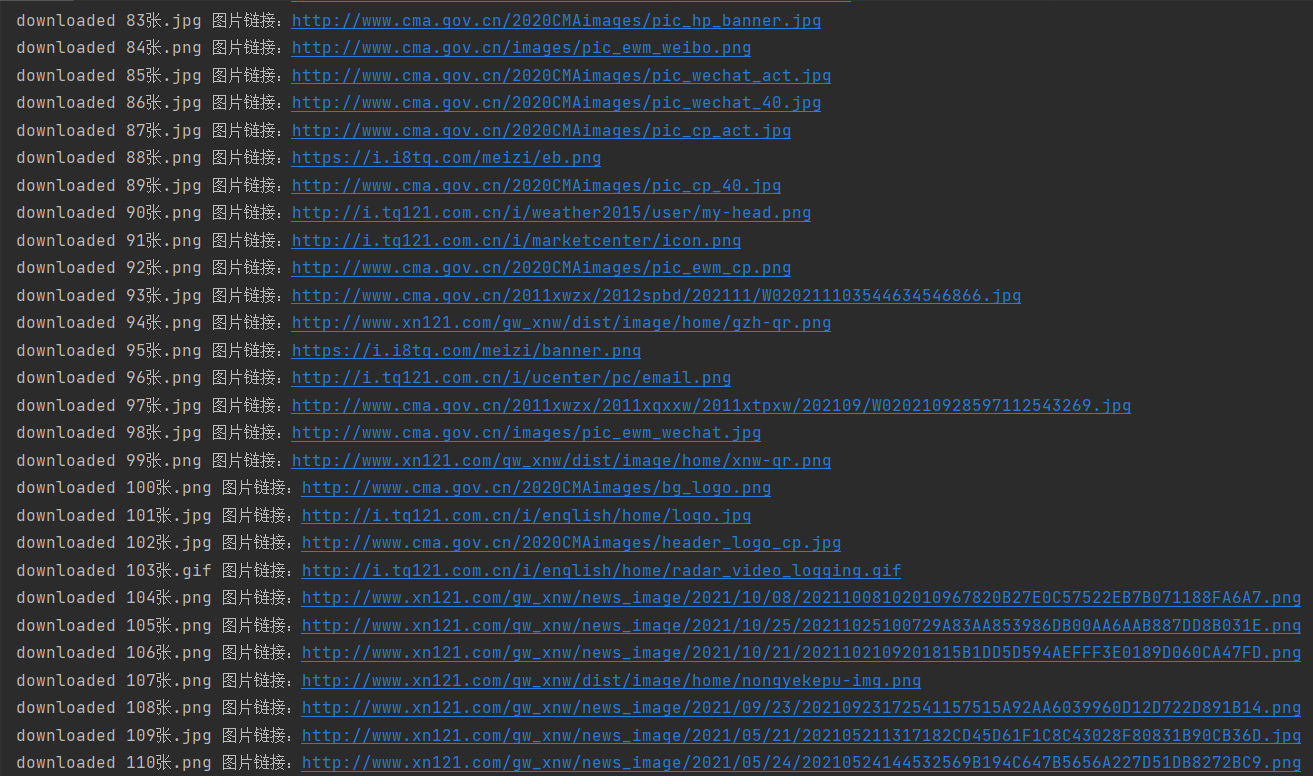
5. Crawling picture results:
6. Code address: https://gitee.com/huang-dunn/crawl_project/blob/master/ Experiment 3 Assignment 1/project_three_test1_1.py
Completion process (multithreading):
1. Modify the single thread code:
def imageSpider(start_url, cous):
global threads
global count
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
if count >= 110:
break
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
count = count+1
T = threading.Thread(target=download, args=(url, cous, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
The main function adds the following sections
get_url(start_url)
threads = []
for t in threads:
t.join()
2. Display of operation results:

3. Code address: https://gitee.com/huang-dunn/crawl_project/blob/master/ Experiment 3 Assignment 1/project_three_test1_2.py
2) Experience: deepen the programming understanding of multi-threaded image crawling method.
-
Operation ②
1) Crawling stock information
– Requirements: use the sketch framework to reproduce the operation ①
– Output information: the same as operation ①
Completion process:
1. Write item class:
class Pro3Test2Item(scrapy.Item):
data = scrapy.Field() # Picture data
count = scrapy.Field() # Total number of pictures
ext = scrapy.Field() # file extension
url = scrapy.Field() # pictures linking
2. Write spiders class:
class Test2Spider(scrapy.Spider):
name = 'pic_test'
global count
count = 1
# allowed_domains = ['XXX.com']
# start_urls = ['http://www.weather.com.cn/']
def start_requests(self):
yield scrapy.Request(url='http://www.weather.com.cn', callback=self.parse)
def parse(self, response):
href_list = response.xpath("//a/@href ") # crawl the page link of the picture under the initial page
for href in href_list:
# print(href.extract())e
H = str(href.extract())
if count > PIC_LIMIT:
return
if len(H) > 0 and H[0] == 'h':
yield scrapy.Request(url=href.extract(), callback=self.parse1)
def parse1(self, response):
a_list = response.xpath("//img/@src ") # crawl the picture download link
for a in a_list:
if count > PIC_LIMIT:
return
# print(a.extract())
url = urllib.request.urljoin(response.url, a.extract())
# print(url)
yield scrapy.Request(url=url, callback=self.parse2)
def parse2(self, response):
global count
count += 1
if count > PIC_LIMIT:
return
item = Pro3Test2Item()
item["ext"] = response.url[-4:]
item["data"] = response.body
item["count"] = count
item["url"] = response.url
return item
3. Write pipeline class:
class Pro3Test2Pipeline:
def process_item(self, item, spider):
path = "D:/py_download/" + "The first" + str(item["count"]) + "Zhang" + item["ext"] # Specify download path
with open(path, 'wb') as f:
f.write(item["data"])
f.close()
print("downloaded " + str(item["count"]) + "Zhang" + item["ext"] + " Picture link:" + item["url"])
return item
4. Display of output results:

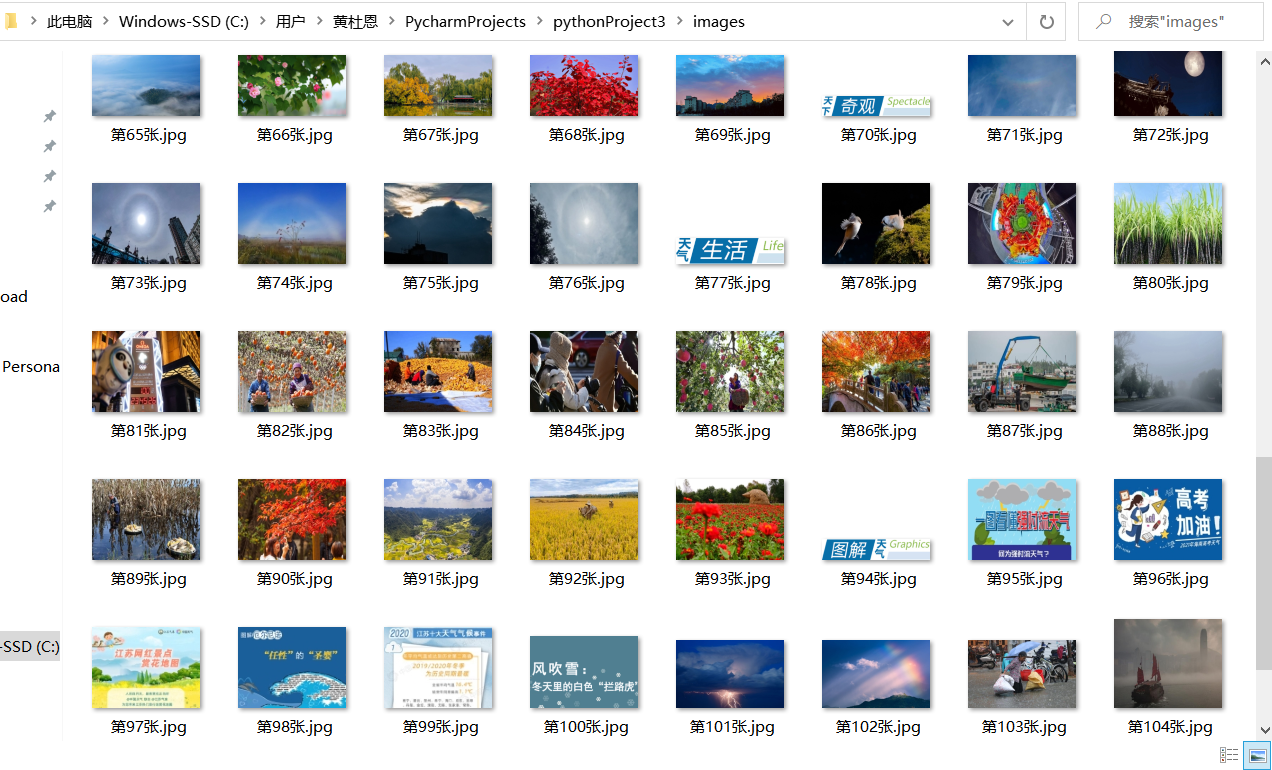
5. Picture crawling results:
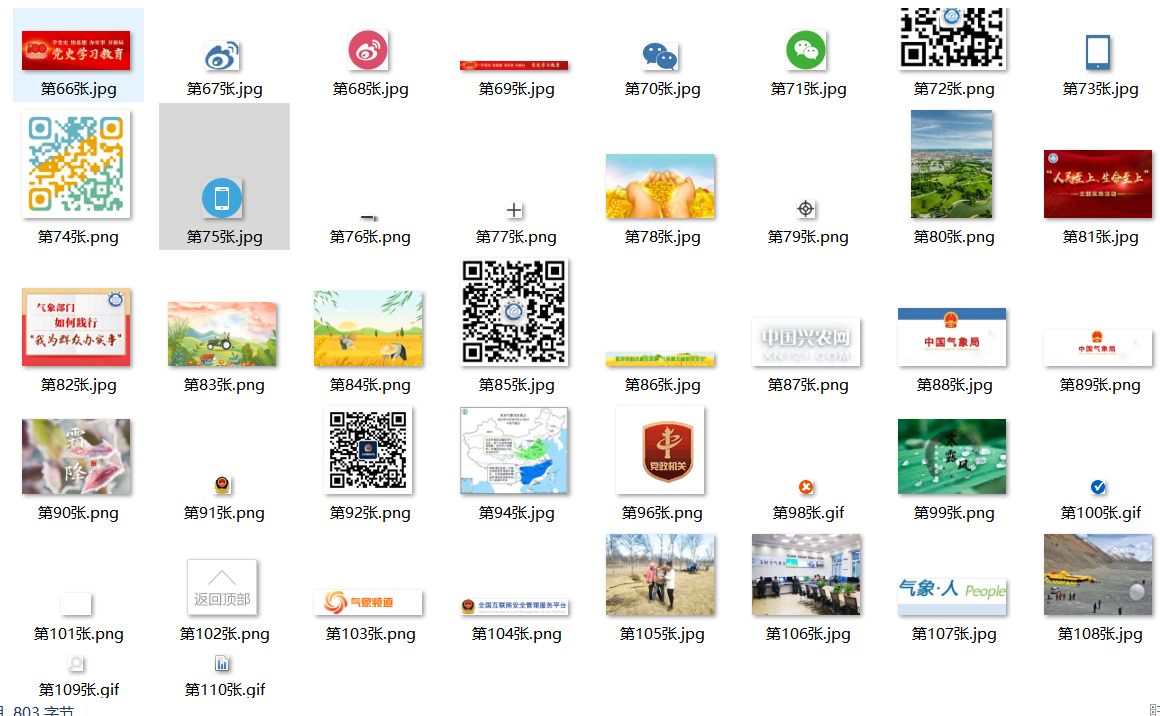
6. Code link: https://gitee.com/huang-dunn/crawl_project/tree/master / Experiment 3 assignment 2
2) Experience: I am more proficient in using the script framework and have a deeper understanding of xpath matching text.
-
Operation ③
1)
– Requirements: crawl the Douban movie data, use scene and xpath, store the content in the database, and store the pictures in the database
– imgs path.
– candidate websites: https://movie.douban.com/top250
– Output information:
| Serial number | Movie title | director | performer | brief introduction | Film rating | Film cover |
|---|---|---|---|---|---|---|
| 1 | The Shawshank Redemption | Frank delabond | Tim Robbins | Want to set people free | 9.7 | ./imgs/xsk.jpg |
| 2... |
Completion process:
1. Write item class:
class Pro3Test3Item(scrapy.Item):
no = scrapy.Field() # Serial number
name = scrapy.Field() # Movie title
director = scrapy.Field() # director
actor = scrapy.Field() # performer
grade = scrapy.Field() # Film rating
url = scrapy.Field() # pictures linking
inf = scrapy.Field() # brief introduction
pass
2. Write spiders class:
class MovieSpider(scrapy.Spider):
name = 'movie'
# allowed_domains = ['XXX.com']
# start_urls = ['http://XXX.com/']
def start_requests(self):
cookie = {}
for i in range(0, 11):
yield scrapy.Request(url='https://movie.douban.com/top250?start=' + str(i * 25) + '&filter=',
callback=self.parse)
def parse(self, response):
li_list = response.xpath('//*[@ id="content"]/div/div[1]/ol/li ') # use Xpath for information identification
item = Pro3Test3Item()
for li in li_list:
item["no"] = li.xpath('./div/div[1]/em/text()').extract_first().strip()
item["name"] = li.xpath('./div/div[2]/div[1]/a/span[1]/text()').extract_first()
temp_ = li.xpath('./div/div[2]/div[2]/p[1]/text()[1]').extract_first().split(" ")[9]
temp = temp_.split(":")
item["director"] = temp[1].split(" ")[0]
if len(temp) > 2:
item["actor"] = temp[2]
else:
item["actor"] = 'None'
item["grade"] = li.xpath('./div/div[2]/div[2]/div/span[2]//text()').extract_first()
item["inf"] = li.xpath('./div/div[2]/div[2]/p[2]/span/text()').extract_first()
if item["inf"] == '':
item["inf"] = 'None'
item["url"] = li.xpath('./div/div[1]/a/img/@src').extract_first()
print(item["no"], item["name"], item["director"], item["grade"], item["inf"])
yield item
3. Write database class:
class MovieDB:
def __init__(self):
self.con = sqlite3.connect("movies.db")
self.cursor = self.con.cursor()
def openDB(self):
try:
self.cursor.execute(
"create table movies (Serial number int(128),Movie title varchar(128),director varchar(128),"
"performer varchar(128),brief introduction varchar(128),Film rating varchar(128),Film cover varchar(128),"
"constraint pk_movies primary key (Serial number))")
except:
self.cursor.execute("delete from movies")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, no, name, director, actor, grade, inf, image):
try:
self.cursor.execute("insert into movies (Serial number,Movie title,director,performer,brief introduction,Film rating,Film cover) "
"values (?,?,?,?,?,?,?)",
(int(no), name, director, actor, inf, grade, image))
except Exception as err:
print(err)
4. Write pipeline class:
class Pro3Test3Pipeline:
def __init__(self):
self.db = MovieDB()
def open_spider(self, spider):
self.db.openDB()
def process_item(self, item, spider):
data = requests.get(item['url']).content
path = r"D:/example/pro3_test3/pro3_test3/images/" + "The first" + str(item["no"]) + "Zhang" + ".jpg" # Specify download path
with open(path, 'wb') as f:
f.write(data)
f.close()
print("downloaded " + str(item["no"]) + "Zhang" + "jpg" + " Picture link:" + item["url"])
self.db.insert(int(item["no"]), item["name"], item["director"], item["actor"], item["grade"], item["inf"],
item["url"])
return item
def close_spider(self, spider):
self.db.closeDB()
5. Display of output results:
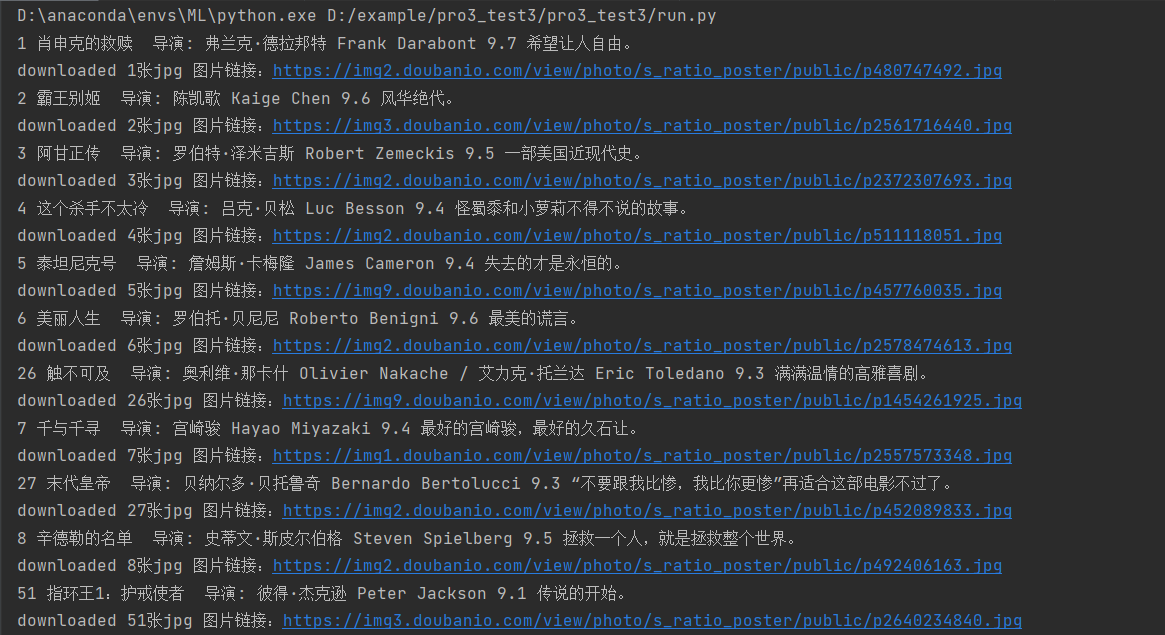
6. Crawling picture display:
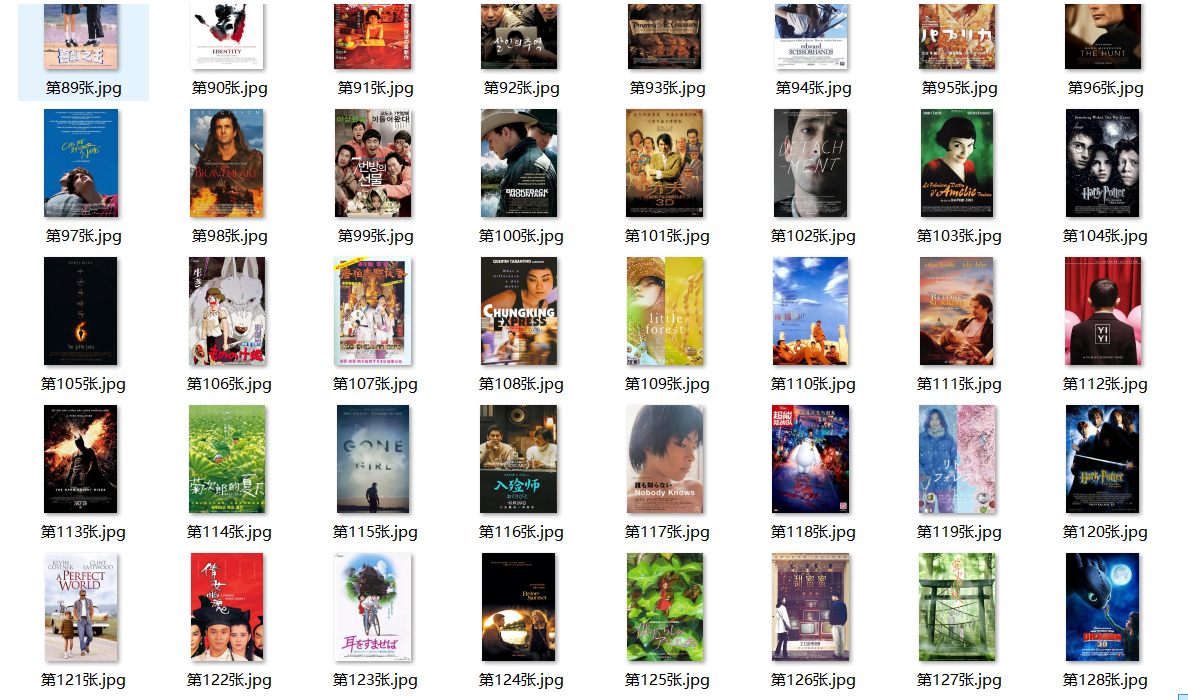
7. Display of database storage results:
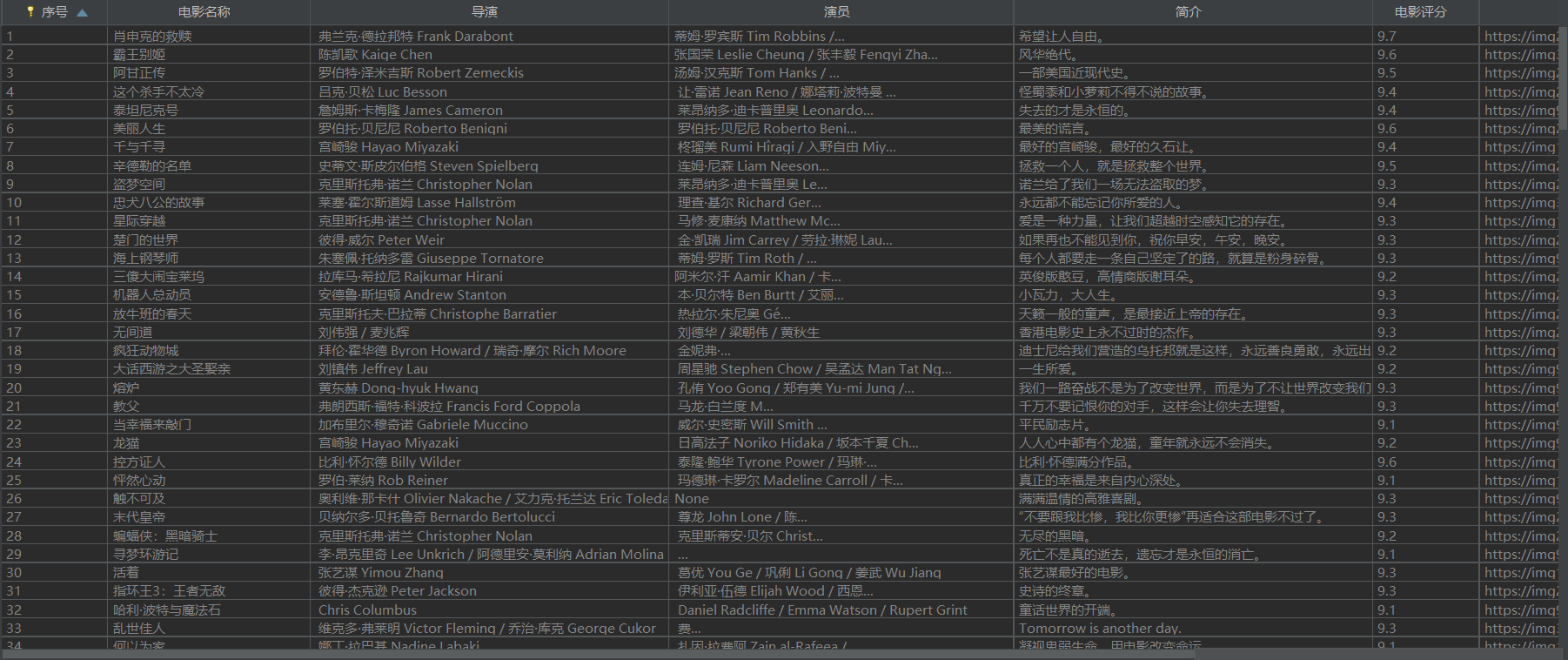
8. Relevant code link: https://gitee.com/huang-dunn/crawl_project/tree/master / Experiment 3