Operation ①:
requirement:
- Master Selenium to find HTML elements, crawl Ajax web page data, wait for HTML elements, etc.
- Use Selenium framework to crawl the information and pictures of certain commodities in Jingdong Mall.
Candidate sites: http://www.jd.com/
Key words: Students' free choice
Output information: the output information of MYSQL is as follows
| mNo | mMark | mPrice | mNote | mFile |
|---|---|---|---|---|
| 000001 | Samsung Galaxy | 9199.00 | Samsung Galaxy Note20 Ultra 5G | 000001.jpg |
| 000002...... |
Idea:
Infrastructure:
Since selenium is a single page parsing, the parsing of selenium can be carried out on a page by page basis. The following is my process of crawling Jingdong Mall.
The whole information is obtained through get_ The board () function is implemented, and the page turning and page limit functions are added.
def get_board(limit=1): """ Get current plate information :param limit: Limit the number of crawls :return: """ for i in range(limit): print(f"Crawling to No{i + 1}page") parse() if i != limit - 1: # Right click switch driver.find_element(By.XPATH, "/html/body").send_keys(Keys.ARROW_RIGHT) if __name__ == '__main__': board = "mobile phone" url = 'https://search.jd.com/Search?keyword=' + board driver.get(url) limit_page = 2 # mobile phone get_board(limit_page) driver.close()
What's more interesting here is that when handling the page turning operation, we found such a line under JD's label: "you can also turn to the next page by using the direction key and right clicking!".
Then we're welcome. Even the steps to obtain Xpath are left. Directly use the direction key and right-click to change the page.

Page parsing
In terms of data analysis, because you need to wait for the commodity picture to load, you need to use some means to load it first.
Here, we use the circular direction down key (the visual effect is better, and the pull-down is silky) to wait for the picture to be loaded.
for i in range(300): driver.find_element(By.XPATH, "/html/body").send_keys(Keys.ARROW_DOWN) if not i % 20: time.sleep(1)
The parsing statement uses Xpath. Due to its high repeatability, it borrows the code in PPT:
phones = driver.find_elements(By.XPATH, "//*[@id='J_goodsList']/ul/li") print(len(phones)) for phone in phones: try: mPrice = phone.find_element_by_xpath(".//div[@class='p-price']//i").text except: mPrice = "0" try: mNote = phone.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text mMark = mNote.split(" ")[0] mNote = mNote.replace(",", "") except: mNote = "" mMark = "" try: src1 = phone.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src") except: src1 = "" try: src2 = phone.find_element_by_xpath(".//div[@class='p- img']//a//img").get_attribute("data-lazy-img") except: src2 = "" global mNo mNo = mNo + 1 no = str(mNo) while len(no) < 6: no = "0" + no if src1: src1 = urllib.request.urljoin(driver.current_url, src1) p = src1.rfind(".") mFile = no + src1[p:] elif src2: src2 = urllib.request.urljoin(driver.current_url, src2) p = src2.rfind(".") mFile = no + src2[p:] if src1 or src2: T = threading.Thread(target=download, args=(src1, src2, mFile)) T.setDaemon(False) T.start() threads.append(T) else: mFile = ""
database
The database is basically code reuse, so there is nothing to say:
Connect database + create table:
db = DB(db_config['host'], db_config['port'], db_config['user'], db_config['passwd']) db.driver.execute('use spider') db.driver.execute('drop table if exists phones') sql_create_table = """ CREATE TABLE `phones` ( `mNo` varchar(11) NOT NULL, `mMark` varchar(64)DEFAULT NULL, `mPrice` float DEFAULT NULL, `mNote` varchar(64) DEFAULT NULL, `mFile` varchar(64) DEFAULT NULL, PRIMARY KEY (`mNo`) )ENGINE=InnoDB DEFAULT CHARSET=utf8; """ db.driver.execute(sql_create_table)
Insert:
sql_insert = f'''insert into phones(mNo, mMark, mPrice, mNote, mFile) values ("{no}", "{mMark}", "{mPrice}", "{mNote}", "{mFile}" ) ''' db.driver.execute(sql_insert) db.connection.commit()
Result screenshot


Operation ②:
requirement:
- Proficient in Selenium's search for HTML elements, user simulated Login, crawling Ajax web page data, waiting for HTML elements, etc.
- Use Selenium framework + Mysql to simulate login to muke.com, obtain the information of the courses learned in the students' own account, save it in MySQL (course number, course name, teaching unit, teaching progress, course status and course picture address), and store the pictures in the imgs folder under the root directory of the local project. The names of the pictures are stored with the course name.
- Candidate website: China mooc website:
Output information: MYSQL database storage and output format
The header should be named in English, for example: course number ID, course name: cCourse... The header should be defined and designed by students themselves:
| Id | cCourse | cCollege | cSchedule | cCourseStatus | cImgUrl |
|---|---|---|---|---|---|
| 1 | Python web crawler and information extraction | Beijing University of Technology | 3 / 18 class hours learned | Completed on May 18, 2021 | http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg |
| 2...... |
Idea:
Realize login
The difficulty of this problem is to realize login. In the previous Taobao crawlers, the method of waiting for code scanning login is used. Because of its high security level, there are still a lot of strange operations using account secret login.
In this question, if there are not too many logins, there is no limit to using account secret login. Therefore, in this question, the method of account secret login is adopted.
First of all, it is necessary to collect the account and password. Here, the input method is adopted (it can be written directly during the test and runs quickly), which is manually input by the operator:
# username = "mirrorlied@***.com" # password = "*************" username = input("enter one user name") password = input("Please input a password")
Next, you need to click the login button. The click effects of the two buttons shown in the figure below are the same.
I chose the larger green button here:
driver.find_element(By.CLASS_NAME, "_3uWA6").click()
After clicking, the code scanning login box will pop up, but we are account secret login. We need to click other login methods:
driver.find_element(By.CLASS_NAME, "ux-login-set-scan-code_ft_back").click()

Click in and wait for a while before the input box is loaded:

Use wait until the input box appears:
input_text = (By.XPATH, "//*[@data-loginname='loginEmail']") iframe = driver.find_element(By.XPATH, "/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[1]/iframe") driver.switch_to.frame(iframe) WebDriverWait(driver, 200, 0.5).until(EC.presence_of_element_located(input_text))
Enter the account secret and enter to log in:
driver.find_element(By.XPATH, "//*[@data-loginname='loginEmail']").send_keys(username) driver.find_element(By.XPATH, "//*[@name='password']").send_keys(password) driver.find_element(By.XPATH, "//*[@name='password']").send_keys(Keys.ENTER)
If you log in multiple times, a sliding verification will appear here, which needs to be processed manually by sleep.
After logging in, you need to click my course, but a fixed size privacy agreement confirmation box will pop up in the lower right corner.
Coincidentally, when the browser resolution is small, this box will block "my course".

Contrast at high resolution ↓

To ensure the correct operation of the crawler, click OK to close this box, and then click "my course":
driver.find_element(By.XPATH, "/html/body/div[4]/div[3]/div[3]/button[1]").click() driver.find_element(By.XPATH, "/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[3]/div[4]/div").click()
After entering, the target information will be read out, and can be analyzed all the way:
courses = driver.find_elements(By.CLASS_NAME, "course-card-wrapper") print(len(courses)) for course in courses: a = course.find_element(By.XPATH, ".//div/a") href = a.get_attribute("href") img = a.find_element(By.XPATH, ".//img").get_attribute("src") name = a.find_element(By.XPATH, ".//div[@class='title']//span[@class='text']").text status = a.find_element(By.XPATH, ".//div[@class='course-status']").text school = a.find_element(By.XPATH, ".//div[@class='school']").text t = a.find_element(By.XPATH, ".//*[@class='course-progress-text-span']").text download(img)

(the mooc platform is really unstable. It broke down when I was writing a blog)
database
sql_insert = f'''insert into course(cCourse, cCollege, cSchedule, cCourseStatus, cImgUrl) values ("{name}", "{school}", "{status}", "{t}", "{img}" ) ''' db.driver.execute(sql_insert) db.connection.commit()
Result display

Operation ③: Flume log collection experiment
- Requirements: Master big data related services and be familiar with the use of Xshell
- Complete the document Hua Weiyun_ Big data real-time analysis and processing experiment manual Flume log collection experiment (part) v2.docx The tasks in are the following five tasks. See the document for specific operations.
- Environment construction
- Task 1: open MapReduce service
- Real time analysis and development practice:
- Task 1: generate test data from Python script
- Task 2: configure Kafka
- Task 3: install Flume client
- Task 4: configure Flume to collect data
1, Build the environment according to the tutorial

2, Python script generates test data
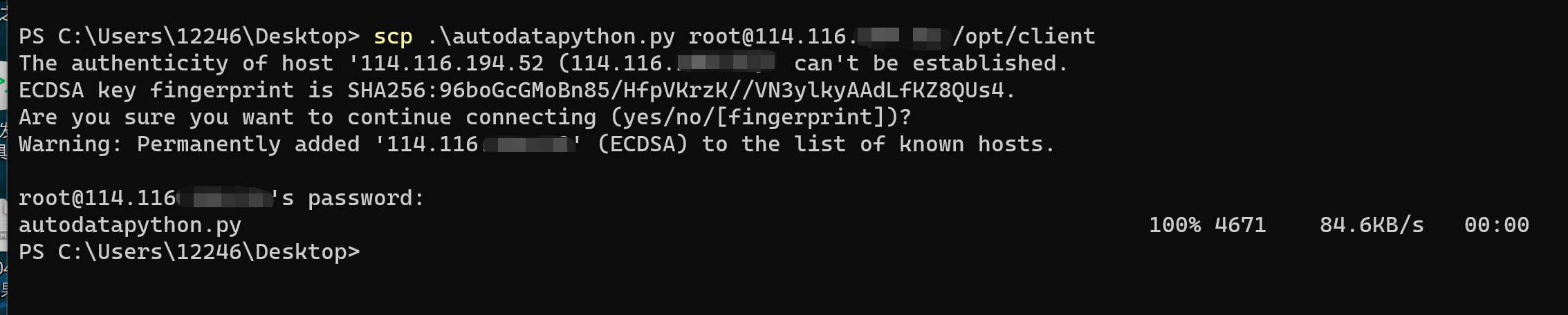
Script file transfer using scp (better than ftp for a single file):
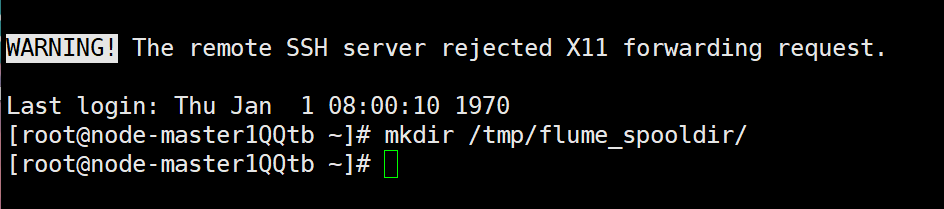
Create output directory:
Operation and result output:

3, Configure Kafka
According to the tutorial case, replace the ip address and execute the script file:

4, Install Flume client
1. Install the client running environment
First, you need to replace the IP of Zookeeper and decompress Mrs_ Flume_ Compress the clientconfig.tar package and execute the installation script:

See the terminal output Components client installation is complete
This indicates that the client running environment was successfully installed.
2. Install Flume client
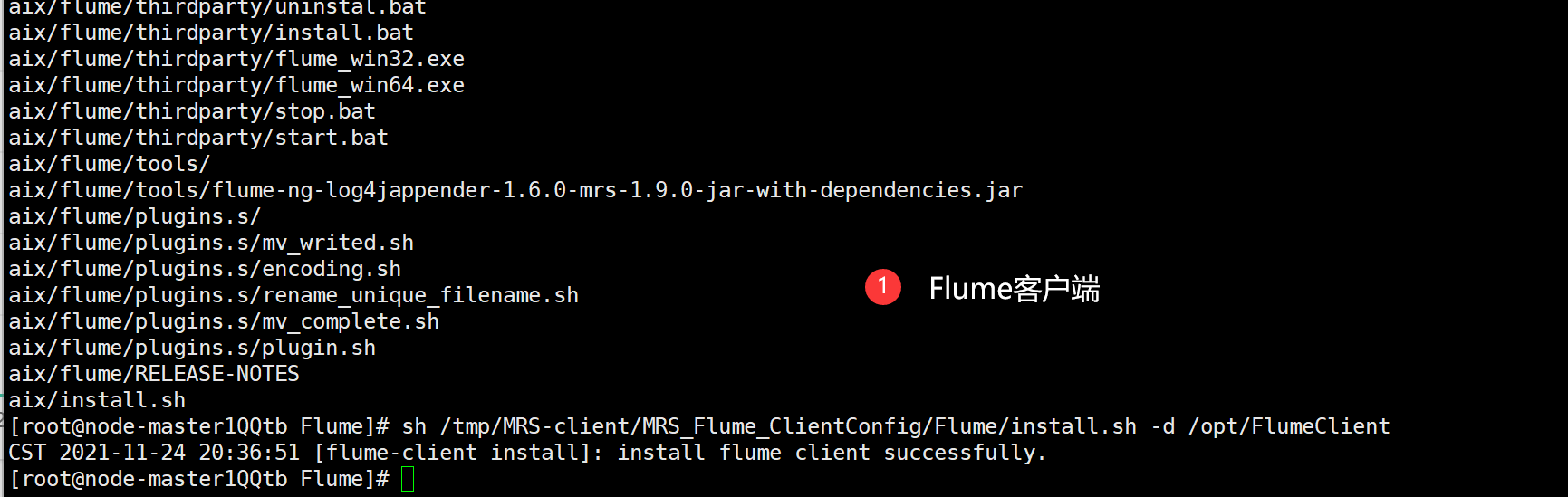
Directly use the installation script install.sh to implement the installation, and then see the terminal output install flume client successfully
Description Flume client installation is complete.
3. Restart the service
After installation, restart the service to realize the configuration of the application:
sh bin/flume-manage.sh restart

5, Configure Flume to collect data
To configure Flume, we modify it locally and then throw it on the server:

Change Kafka's socket to the intranet Ip address assigned to us by Huawei ECs.
Then continue to transmit through scp (it is also included by default in windows system, and the use method is the same).

After using the source application configuration, create a new ssh connection and run the python script again. You can see the information received in the Kafaka consumer window:
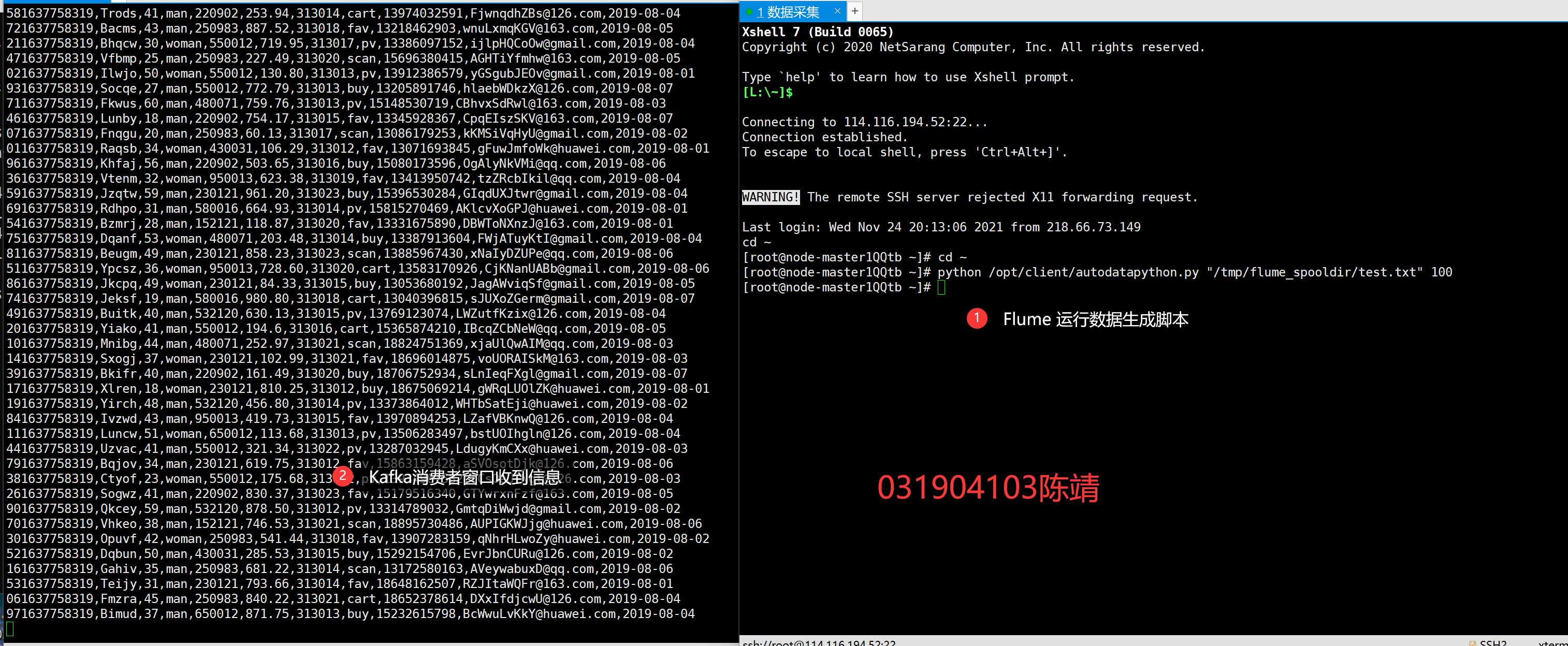
Code address
https://gitee.com/mirrolied/spider_test
Experience
one Complete the one-time login process and be more proficient in selenium positioning;
2. Have a preliminary understanding of Flume real-time stream front-end data acquisition.