previously on
Hello everyone, VIsion Transformer has reached its sixth day. With the passage of time, the difficulty is getting greater and greater. I believe you have learned from ResNet, ViT Transformer and Diet. Today, you have learned the best ICCV paper Swin Transformer in 2021. Swin Transformer directly killed the list on major pound lists this year. Swin was used to brush the list in the top 8 of COCO verification set, Swin's original paper is the eighth, and the first seven are all swin's re innovations, https://paperswithcode.com/sota/object-detection-on-coco-minival?p=end-to-end-semi-supervised-object-detection
. If today's notes can help you, it's definitely my great honor.
The difference between Swin and VIT
The difference between Swin and Vit can be illustrated by a figure
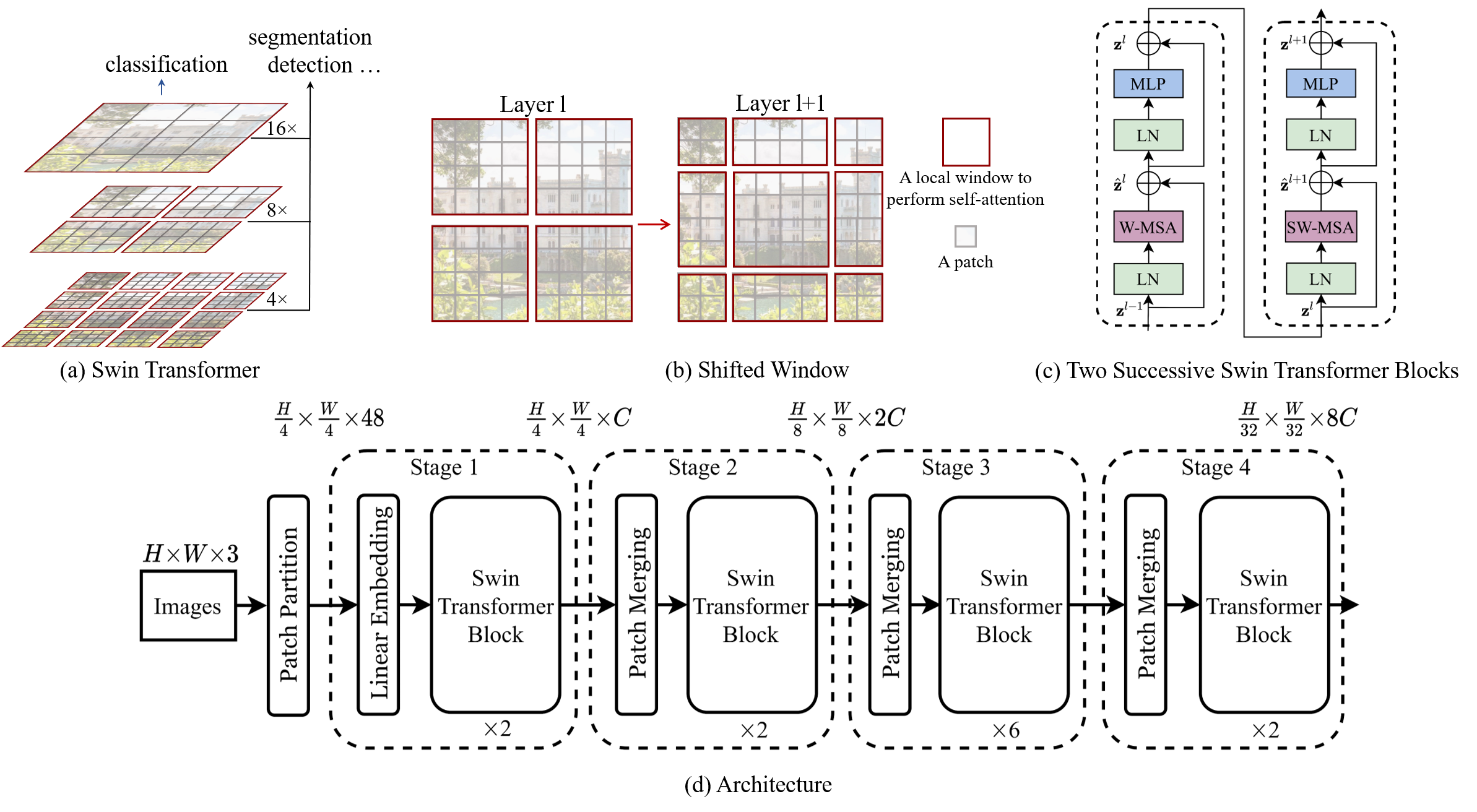
Compared with Vit's direct down sampling of 16 times, swing uses the concept of window and uses different down sampling times, and the calculation of different windows does not interfere with each other. In this way, compared with Vit, the amount of calculation is greatly reduced and the performance is effectively improved
Patch layer explanation
If you have studied vit, you should know that vit has a PatchEmbedding layer, which is responsible for mapping a batch of RGB images from four dimensions to three dimensions
[B,C,H,W]->[B,H*W/N/N,C*N*N]
The responsibility of PatchEmbedding in swing is assumed by the Patch Partition. Since Mr. Zhu's ppt has not been released yet, the PPT of station B up thunderbolt bar Wz quoted here.
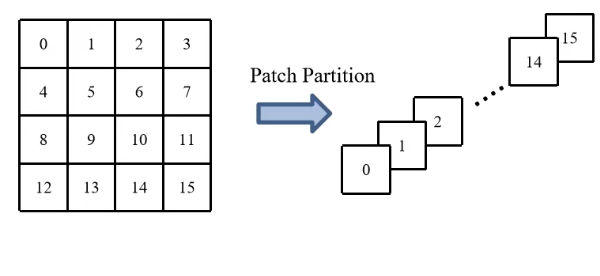
Unlike VIt, the swing transformer uses multiple down sampling, and the first down sampling uses a 4x4 convolution kernel
After that, the number of channels will be converted from 48 to C through a full link layer, also known as Linear Embedding layer, and its overall view is.
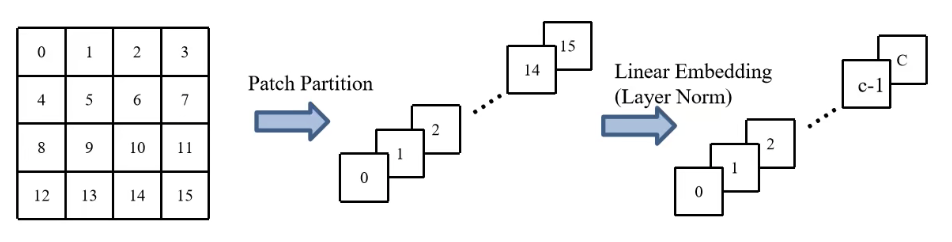
However, in the code implementation of Swin Transformer, Patch Partition and Linear Embedding are directly combined into one, and a convolution core with 4x4 size and stripe of 4 is directly used to convert the number of channels from 3 to C.
import paddle import paddle.nn as nn
class PatchEmbed(nn.Layer):
"""
2D Image to Patch Embedding
"""
def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=nn.LayerNorm):
super().__init__()
patch_size = (patch_size, patch_size)
self.patch_size = patch_size
self.in_chans = in_c
self.embed_dim = embed_dim
self.proj = nn.Conv2D(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
_, _, H, W = x.shape
# # padding
# # If the H and W of the input picture are not patch_ An integer multiple of size. padding is required
# pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)
# if pad_input:
# # to pad the last 3 dimensions,
# # (W_left, W_right, H_top,H_bottom, C_front, C_back)
# x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],
# 0, self.patch_size[0] - H % self.patch_size[0],
# 0, 0))
# Down sampling patch_size times
x = self.proj(x)
_, _, H, W = x.shape
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = paddle.transpose(x.flatten(2),(0,2,1))
x = self.norm(x)
print(x.shape)
return x, H, W
model = PatchEmbed() paddle.summary(model,(8,3,224,224))
[8, 3136, 96]
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[8, 3, 224, 224]] [8, 96, 56, 56] 4,704
LayerNorm-1 [[8, 3136, 96]] [8, 3136, 96] 192
===========================================================================
Total params: 4,896
Trainable params: 4,896
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 4.59
Forward/backward pass size (MB): 36.75
Params size (MB): 0.02
Estimated Total Size (MB): 41.36
---------------------------------------------------------------------------
{'total_params': 4896, 'trainable_params': 4896}
PatchMerging explanation
Because Swin requires the manager to downsample four times, the first downsample is by patchemedding
Layer, and then there are three times by PatchMerging. PatchMerging will double the width and height of the feature map again, and make the number of channels Cx2. The illustration quoted here is also the PPT of station B up thunderbolt Wz.
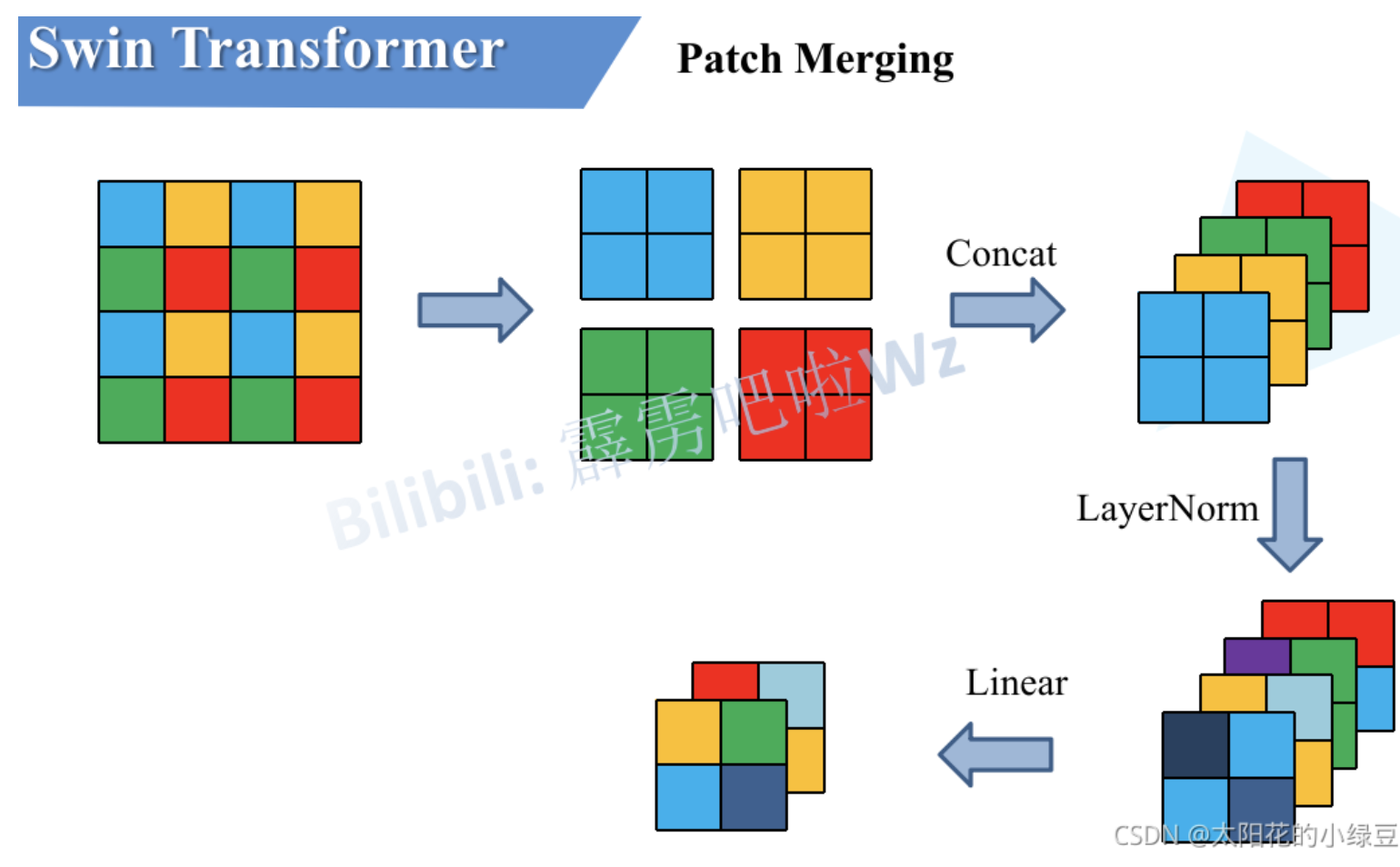
First, we use a 2x2 convolution kernel as the window, and each window has four pixels. Then I will take out the pixels at the same position of each window and get four characteristic matrices like the second one. Then, we will splice the four characteristic matrices at latitude C to get 4xC, and then carry out a LinearNorm layer, Finally, a Linear mapping is performed through a Linear layer to become 2xC. such
The shape of X becomes
[H/4,W/4,C]->[H/8,W/8,2*C]
class PatchMerging(nn.Layer):
r""" Patch Merging Layer.
Args:
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H=224//4, W=224//4):
"""
x: B, H*W, C
"""
B, L, C = x.shape
print(x.shape)
assert L == H * W, "input feature has wrong size"
x = paddle.reshape(x,(B, H, W, C))
# # padding
# # If the input H and W of the feature map are not integral multiples of 2, padding is required
# pad_input = (H % 2 == 1) or (W % 2 == 1)
# if pad_input:
# # to pad the last 3 dimensions, starting from the last dimension and moving forward.
# # (C_front, C_back, W_left, W_right, H_top, H_bottom)
# # Note that the Tensor channel here is [B, H, W, C], so it is somewhat different from the official document
# x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]
x = paddle.concat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
x = paddle.reshape(x,(B, -1, 4 * C)) # [B, H/2*W/2, 4*C]
x = self.norm(x)
x = self.reduction(x) # [B, H/2*W/2, 2*C]
print(x.shape)
return x
model = PatchMerging(96) paddle.summary(model,(8,3136,96))
[8, 3136, 96]
[8, 784, 192]
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
LayerNorm-2 [[8, 784, 384]] [8, 784, 384] 768
Linear-1 [[8, 784, 384]] [8, 784, 192] 73,728
===========================================================================
Total params: 74,496
Trainable params: 74,496
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 9.19
Forward/backward pass size (MB): 27.56
Params size (MB): 0.28
Estimated Total Size (MB): 37.03
---------------------------------------------------------------------------
{'total_params': 74496, 'trainable_params': 74496}
Swin TansFormer Block explanation
Similar to the Block layer of VIT TransFormer, swing transformer uses S-MSA and SW-MSA instead of MSA, and nothing else has changed
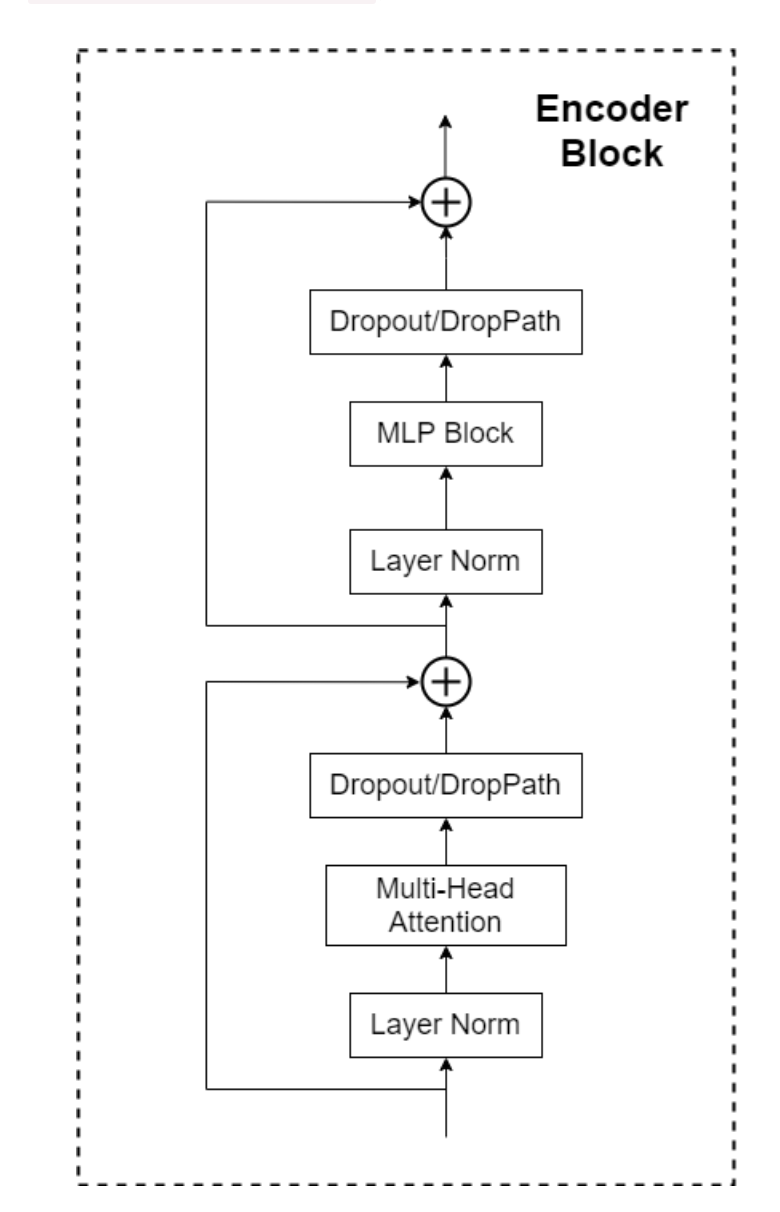
S-SMA and SW-MSA are a little difficult for the time being. Let's explain them tomorrow. Today, let's implement the whole Block module first
It can be seen that the Block layer first passes through a LayerNorm, then S-MSA or SW-MSA, then enters a Dropout or DropPath layer, then performs a short circuit, then performs a LayerNrom, then an Mlp, then a Dropout or DropPath layer, and then a short circuit. Such a Block layer is realized.
Next, I'll implement the Mlp layer before.
Mlp explanation
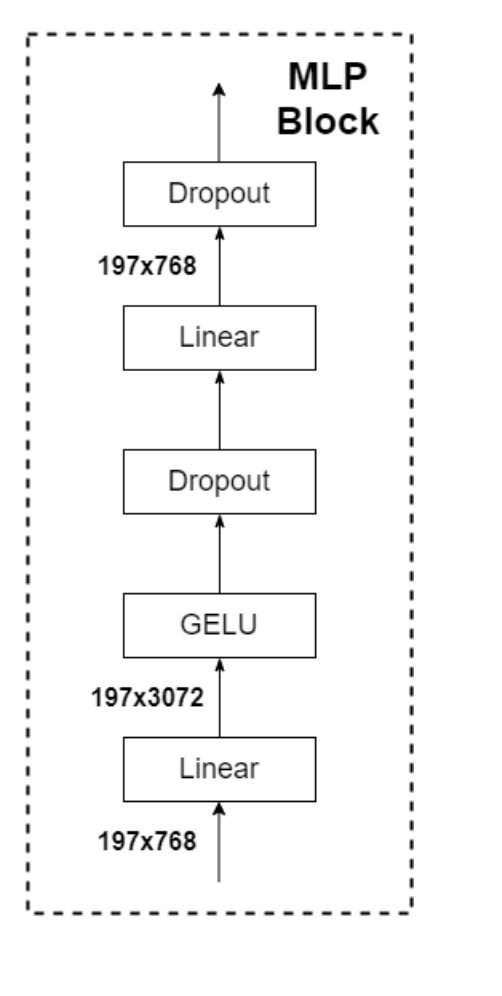
Mr. Zhu has made it clear before Mlp that a Linear layer will count the number of channels × 4. Then go through GELU activation function, then go through a Dropout layer, and then go through a Linear layer to change the number of channels back to the original number, and then go through a Dropout layer
class Mlp(nn.Layer):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
print(x.shape)
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
print(x.shape)
return x
model = Mlp(768) paddle.summary(model,(8,197,768))
[8, 197, 768]
[8, 197, 768]
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Linear-2 [[8, 197, 768]] [8, 197, 768] 590,592
GELU-1 [[8, 197, 768]] [8, 197, 768] 0
Dropout-1 [[8, 197, 768]] [8, 197, 768] 0
Linear-3 [[8, 197, 768]] [8, 197, 768] 590,592
Dropout-2 [[8, 197, 768]] [8, 197, 768] 0
===========================================================================
Total params: 1,181,184
Trainable params: 1,181,184
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 4.62
Forward/backward pass size (MB): 46.17
Params size (MB): 4.51
Estimated Total Size (MB): 55.29
---------------------------------------------------------------------------
{'total_params': 1181184, 'trainable_params': 1181184}
SwinTransformerBlock layer implementation
The following is the implementation of the Block layer. Here is a WindowAttention, which is the implementation of S-MSA and SW-MSA. Let's briefly define it here without any content.
class WindowAttention(nn.Layer):
def __init__(self,dim, window_size, num_heads, qkv_bias,attn_drop, proj_drop):
super().__init__()
pass
def forward(self,x):
return x,x
class SwinTransformerBlock(nn.Layer):
""" Swin Transformer Block.
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.drop_path = nn.Dropout(0) #if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
H, W = 56, 56
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = paddle.reshape(x,(B, H, W, C))
# # pad feature maps to multiples of window size
# # Give the feature map to the pad to an integer multiple of the window size
# pad_l = pad_t = 0
# pad_r = (self.window_size - W % self.window_size) % self.window_size
# pad_b = (self.window_size - H % self.window_size) % self.window_size
# x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
#--------------------------------------------------------------------------------------------------#
# S-MSA will not handle it for the time being. We'll talk about it next time
#--------------------------------------------------------------------------------------------------#
# # cyclic shift
# if self.shift_size > 0:
# shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
# else:
# shifted_x = x
# attn_mask = None
# # partition windows
# x_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C]
# x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [nW*B, Mh*Mw, C]
# # W-MSA/SW-MSA
# attn_windows = self.attn(x_windows, mask=attn_mask) # [nW*B, Mh*Mw, C]
# # merge windows
# attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [nW*B, Mh, Mw, C]
# shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H', W', C]
# # reverse cyclic shift
# if self.shift_size > 0:
# x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
# else:
# x = shifted_x
# if pad_r > 0 or pad_b > 0:
# # Remove the data of the previous pad
# x = x[:, :H, :W, :].contiguous()
#--------------------------------------------------------------------------------------------------#
x = paddle.reshape(x,(B,H*W,C))
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
model = SwinTransformerBlock(96,3) paddle.summary(model,(8,3136,96))
[8, 3136, 96]
[8, 3136, 96]
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
LayerNorm-3 [[8, 3136, 96]] [8, 3136, 96] 192
Dropout-3 [[8, 3136, 96]] [8, 3136, 96] 0
LayerNorm-4 [[8, 3136, 96]] [8, 3136, 96] 192
Linear-4 [[8, 3136, 96]] [8, 3136, 384] 37,248
GELU-2 [[8, 3136, 384]] [8, 3136, 384] 0
Dropout-4 [[8, 3136, 384]] [8, 3136, 384] 0
Linear-5 [[8, 3136, 384]] [8, 3136, 96] 36,960
Dropout-5 [[8, 3136, 96]] [8, 3136, 96] 0
Mlp-2 [[8, 3136, 96]] [8, 3136, 96] 0
===========================================================================
Total params: 74,592
Trainable params: 74,592
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 9.19
Forward/backward pass size (MB): 330.75
Params size (MB): 0.28
Estimated Total Size (MB): 340.22
---------------------------------------------------------------------------
{'total_params': 74592, 'trainable_params': 74592}
summary
Today, we have completed all the knowledge except S-MSA and SW-MSA. Tomorrow, we will realize S-MSA and SW-MSA. The above is personal understanding. If there is any error, please correct it.
The above pictures are all from station B up main thunderbolt bar Wz, thank you very much.
I'm Lao Mengxin
I got the gold level in AI Studio and lit 5 badges to pass each other~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/553083