Based on MySQL Router to achieve high availability, read-write separation, load balancing and so on, MySQL Router can be said to be a very lightweight middleware.
Looking at the principle of MySQL Router, it is not complicated, and the principle is not difficult to understand. In fact, it is a proxy function similar to VIP. One MySQL Router has two port numbers, which are forwarding to read and write respectively.
As for which port number to choose, you need to customize it when you apply for connection. In other words, when you generate connection strings, you need to specify whether to read or write, and then forward it to a specific server by MySQL Router.
To quote here is:
Generally speaking, it is not a good way to achieve read/write separation through different ports. The biggest reason is that these connection ports need to be specified in the application code.
However, MySQL Router can only achieve read-write separation in this way, so MySQL Router can be used as a toy to play with. Its principle refers to the following figure, the relevant installation configuration is very simple.
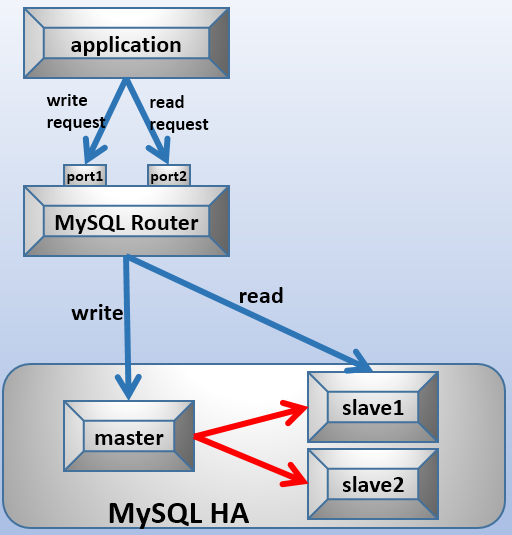
In fact, no matter "MySQL Router is used as a toy to play with", similar to the need to specify their own port (or specify read-write) to achieve read-write separation, they can fully achieve, why use a middleware?
Long ago, I wondered if I could try to achieve the separation of reading and writing by myself without the help of middleware.
For the simplest master-salve replication cluster, read-write separation,
Based on assigning a priority on the original database connection, the priority of the master server can be assigned to the highest level, and the other two can be assigned to a lower priority.
For requests initiated by applications, it is necessary to specify whether to read or write, if to write, it is specified to the master to execute, if to read, it randomly points to the slave operation, which can completely implement functions similar to MySQL Router in the connection layer.
In fact, it is very simple, it can take less than half an hour to achieve a similar function, in the connection layer to achieve read-write separation, high availability, load balancing, demo a code implementation.
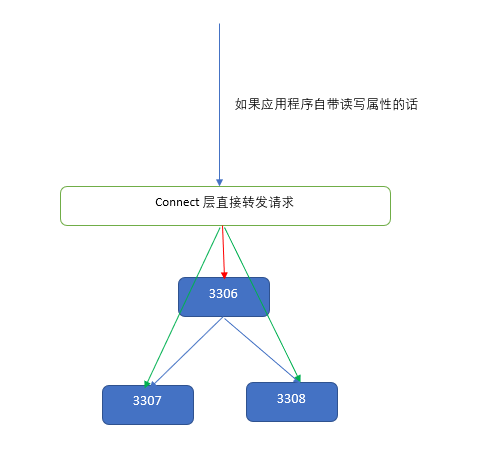
The following is a simple implementation of read-write separation and load balancing from the database connection layer.
1. Write requests point to the highest priority master in the connection string. If the specified highest priority instance is unavailable, if failover is achieved here, look for the next priority instance in turn.
2. Slve replicates master's data and reads requests randomly to different slaves. Once a slave is unavailable, continue looking for other slaves.
3. Maintain a connection pool, and all connections are obtained from the connection pool.
Fault transfer can be implemented independently, and does not need to be done in the connection layer, nor does the connection layer do fault transfer. In this way, once a failure occurs, as long as the failover is achieved, the application side does not need to make any modifications.
# -*- coding: utf-8 -*- import pymysql import random from DBUtils.PooledDB import PooledDB import socket class MySQLRouter: operation = None conn_list = [] def __init__(self, *args, **kwargs): for k, v in kwargs.items(): setattr(self, k, v) # Probe instance port number @staticmethod def get_mysqlservice_status(host,port): mysql_stat = 0 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) result = s.connect_ex((host, int(port))) # port os open if (result == 0): mysql_stat = 1 return mysql_stat def get_connection(self): if not conn_list: raise("no config error") conn = None current_conn = None # Sort by node priority self.conn_list.sort(key=lambda k: (k.get('priority', 0))) #Write or undefined requests, all directed at high priority servers, readable and writable if(self.operation.lower() == "write") or not self.operation: for conn in conn_list: # If the primary node with the highest priority is not reachable, it is assumed that failover has been successfully implemented and the instance of the secondary priority is continued to be found. if self.get_mysqlservice_status(conn["host"], conn["port"]): current_conn = conn break else: continue #Read requests randomly point to different slave elif(self.operation.lower() == "read"): #Random access to nodes other than the most priority node conn_read_list = conn_list[1:len(conn_list)] random.shuffle(conn_read_list) for conn in conn_read_list: #Random acquisition of nodes other than the primary node, if not reachable, continue to find other random acquisition of nodes other than the primary node if self.get_mysqlservice_status(conn["host"], conn["port"]): current_conn = conn break else: continue try: #Get the current connection from the connection pool if (current_conn): pool = PooledDB(pymysql,20, host=current_conn["host"], port=current_conn["port"], user=current_conn["user"], password=current_conn["password"],db=current_conn["database"]) conn = pool.connection() except: raise if not conn: raise("create connection error") return conn; if __name__ == '__main__': #Define three instances conn_1 = {'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'password': 'root',"database":"db01","priority":100} conn_2 = {'host': '127.0.0.1', 'port': 3307, 'user': 'root', 'password': 'root',"database":"db01","priority":200} conn_3 = {'host': '127.0.0.1', 'port': 3308, 'user': 'root', 'password': 'root',"database":"db01","priority":300} conn_list = [] conn_list.append(conn_1) conn_list.append(conn_2) conn_list.append(conn_3) print("####execute update on master####") myrouter = MySQLRouter(conn_list=conn_list, operation="write") conn = myrouter.get_connection() cursor = conn.cursor() cursor.execute("update t01 set update_date = now() where id = 1") conn.commit() cursor.close() conn.close() print("####loop execute read on slave,query result####") #Loop read to determine which node the read points to. for loop in range(10): myrouter = MySQLRouter(conn_list = conn_list,operation = "read") conn = myrouter.get_connection() cursor = conn.cursor() cursor.execute("SELECT id,cast(update_date as char), CONCAT('instance port is: ', CAST( @@PORT AS CHAR)) AS port FROM t01;") result = cursor.fetchone() print(result) cursor.close() conn.close()
Here we used a priority of the server to point the write request to the master server of the highest priority and the read request to the slave of the highest priority at random.
The query returns a port number to determine whether the read requests are evenly distributed to the inaccessible slave end.
For update requests, they are executed on master, slave copies master's data, reads different data each time, and executes requests each time, basically randomly pointing to two slave servers.

Compared with MySQL Router as a toy, the implementation here is as low as that of MySQL Router, because requests for data need to specify explicitly whether to read or write.
For automatic read-write separation, it is no more than a problem of judging whether an SQL statement is read or written. It is not difficult to resolve whether the SQL statement is read or written.
Some database middleware can achieve automatic read-write separation, but it should be understood that those middleware supporting automatic read-write separation are often subject to certain constraints, such as what can not be stored procedures, why?
Or the problem of SQL parsing mentioned above, because once stored procedures are used, it is impossible to parse whether the SQL is read or written, at least not too directly.
For the judgment of SQL reading and writing, that is to say, to maintain an enumerated regular expression of reading or writing, non-reading or writing, we should pay special attention to the efficiency of the judgment of reading and writing.