Cross validation
https://sklearn.apachecn.org/docs/0.21.3/30.html
cross_val_score
>>> from sklearn.model_selection import cross_val_score >>> clf = svm.SVC(kernel='linear', C=1) >>> scores = cross_val_score(clf, iris.data, iris.target, cv=5) >>> scores array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
>>> from sklearn import metrics >>> scores = cross_val_score( ... clf, iris.data, iris.target, cv=5, scoring='f1_macro') >>> scores array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
>> from sklearn.pipeline import make_pipeline >> clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(C=1)) >> cross_val_score(clf, iris.data, iris.target, cv=5) ... array([ 0.97..., 0.93..., 0.95...])
K fold
KFold All samples are divided into k groups, called folds (if k=n, which is equivalent to Leave One Out strategy), and all have the same size (if possible). Predictive function learning uses k-1 folded data, and the last remaining fold is used for testing.
Examples of using 2-fold cross-validation on four sample datasets:
>>> import numpy as np >>> from sklearn.model_selection import KFold >>> X = ["a", "b", "c", "d"] >>> kf = KFold(n_splits=2) >>> for train, test in kf.split(X): ... print("%s %s" % (train, test)) [2 3] [0 1] [0 1] [2 3]
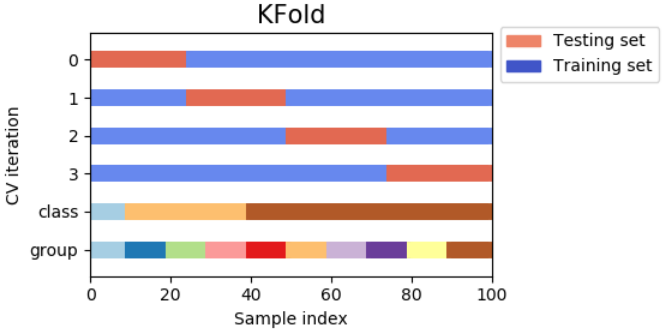
Hierarchical k folding
Stratified KFold is a variant of k-fold that returns stratified folding: in each small set, the proportion of samples for each category is roughly the same as in the complete data set.
In 10 examples, there are two examples of hierarchical 3-fold cross-validation on data sets of slightly unbalanced categories:
>>> from sklearn.model_selection import StratifiedKFold >>> X = np.ones(10) >>> y = [0, 0, 0, 0, 1, 1, 1, 1, 1, 1] >>> skf = StratifiedKFold(n_splits=3) >>> for train, test in skf.split(X, y): ... print("%s %s" % (train, test)) [2 3 6 7 8 9] [0 1 4 5] [0 1 3 4 5 8 9] [2 6 7] [0 1 2 4 5 6 7] [3 8 9]
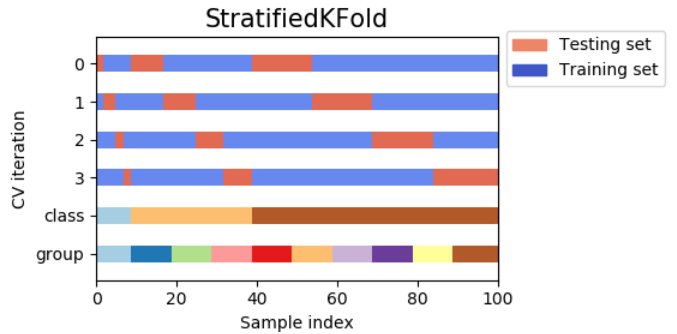
Adjustment of superparameters
https://sklearn.apachecn.org/docs/0.21.3/31.html
param_grid = [ {'C': [1, 10, 100, 1000], 'kernel': ['linear']}, {'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']}, ]
from sklearn.metrics import fbeta_score, make_scorer from sklearn.model_selection import GridSearchCV from sklearn.svm import LinearSVC ftwo_scorer = make_scorer(fbeta_score, beta=2) grid = GridSearchCV(LinearSVC(), param_grid={'C': [1, 10]}, scoring=ftwo_scorer) corer(fbeta_score, beta=2) grid = GridSearchCV(LinearSVC(), param_grid={'C': [1, 10]}, scoring=ftwo_scorer)