Image text cross modal similarity comparison and retrieval SDK [Chinese]
Note:
Due to network reasons, the multilingual version of the CLIP model cannot be downloaded after multiple attempts.
https://github.com/FreddeFrallan/Multilingual-CLIP
Therefore, the second step is to use the SDK previously made to translate Chinese into English, first translate Chinese into English, and then submit it to the CLIP model for subsequent processing.
https://zhuanlan.zhihu.com/p/398787028
The difference is that the lac is replaced by another Chinese word splitter (jieba), which has better Chinese word segmentation effect.
https://zhuanlan.zhihu.com/p/400536545
Background introduction
OpenAI has released two new neural networks: CLIP and DALL · E. They combine NLP (natural language recognition) with image recognition,
Have a better understanding of images and language in daily life.
In the past, we used to search words and pictures with words. Now, through the CLIP model, we can search pictures with words and search words with pictures.
The realization idea is to map the picture and text to the same vector space. In this way, the cross modal similarity comparison and retrieval of image and text can be realized.
- Feature vector space (composed of picture & text)

CLIP, "alternative" image recognition
At present, most models learn to recognize images from labeled examples of labeled data sets, while CLIP learns images and their descriptions obtained from the Internet,
That is, recognize the image through a description rather than word labels such as "cat" and "dog".
To do this, CLIP learning associates a large number of objects with their names and descriptions, so that objects other than the training set can be identified.
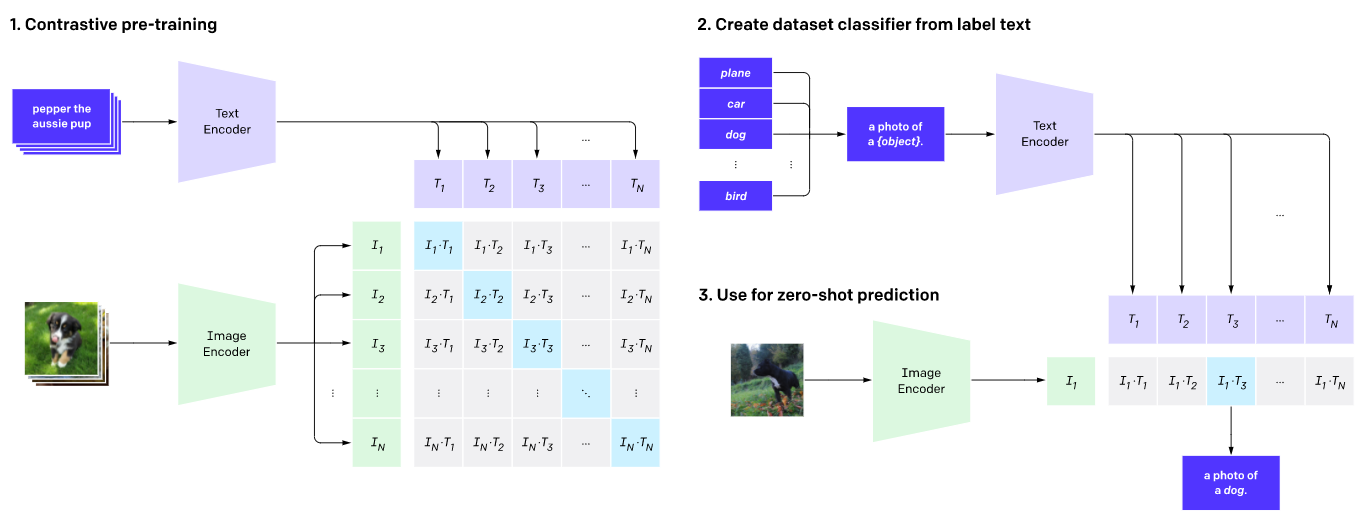
As shown in the above figure, the CLIP network workflow: pre train the graph encoder and text encoder to predict which images in the dataset are paired with which text.
Then, the CLIP is converted to a zero shot classifier. In addition, all classifications of the data set are converted into labels such as "a picture of a dog" and the best paired images are predicted.
CLIP model address:
https://github.com/openai/CLIP/blob/main/README.md
SDK functions:
- Image text feature vector extraction
- Similarity calculation
- softmax calculation confidence
Run example - ImageTextSearchExample
After running successfully, the command line should see the following information:
... # Test text: [INFO ] - texts: [There are two dogs in the snow, A cat is on the table, London at night] # Test picture: [INFO ] - image: src/test/resources/two_dogs_in_snow.jpg

# Vector dimension: [INFO ] - Vector dimension: 512 # Generate picture vector: [INFO ] - image embeddings: [0.22221693, 0.16178696, ..., -0.06122274, 0.13340257] # Chinese Word Segmentation & Translation (top 5): [INFO ] - Tokens : [stay, Snow, in, have, Two, dog] [INFO ] - There are two dogs in the snow: [ There are two dogs in the snow, In the snow there are two dogs, There were two dogs in the snow, There are two dogs in the snow., There are two dogs in the snow@@ .@@ ()] [INFO ] - Tokens : [One, cat, stay, Table, upper] [INFO ] - A cat is on the table: [ A cat is on the table, A cat is on the desk, A cat is on the desk., A cat is on the table@@ .@@ 3, A cat is on the table@@ .@@ 7@@ 16] [INFO ] - Tokens : [night, of, London] [INFO ] - London at night: [ Night in London, London at night, Even@@ ing London, Late at night in London, Late in London] # Generate text vector (take the first generated vector of translation) & calculate similarity: [INFO ] - text [There are two dogs in the snow] embeddings: [0.111746386, 0.08818339, ..., -0.15732905, -0.54234475] [INFO ] - Similarity: 28.510675% [INFO ] - text [A cat is on the table] embeddings: [0.08841644, 0.043696217, ..., -0.16612083, -0.11383227] [INFO ] - Similarity: 12.206457% [INFO ] - text [London at night] embeddings: [-0.038869947, 0.003223464, ..., -0.177596, 0.114676386] [INFO ] - Similarity: 14.038936% #softmax confidence calculation: [INFO ] - texts: [There are two dogs in the snow, A cat is on the table, London at night] [INFO ] - probs: [0.9956493, 0.0019198752, 0.0024309014]
catalog:
http://www.aias.top/
Git address:
https://github.com/mymagicpower/AIAS
https://gitee.com/mymagicpower/AIAS