When you need information on some web pages in the past, it is very convenient to use Python to write crawlers to crawl.
1. Use urllib.request to get the web page
Urllib is a built-in HTTP Library in Python. Using urllib, you can efficiently collect data in very simple steps; With Beautiful and other HTML parsing libraries, large crawlers for collecting network data can be written;
Note: the sample code is written in Python 3; Urllib is a combination of urllib and urllib 2 in Python 2. Urllib 2 in Python 2 corresponds to urllib.request in Python 3
Simple example:
import urllib.request # Introduce urllib.request
response = urllib.request.urlopen('http://www.zhihu.com ') # open URL
html = response.read() # Read content
html = html.decode('utf-8') # decode
print(html)
2. Forge request header information
Sometimes the request initiated by the crawler will be rejected by the server. At this time, it is necessary to disguise the crawler as a browser of human users, which is usually realized by forging the request header information, such as:
import urllib.request
#Define save function
def saveFile(data):
path = "E:\\projects\\Spider\\02_douban.out"
f = open(path,'wb')
f.write(data)
f.close()
#website
url = "https://www.douban.com/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
#You can also save the crawled content to a file
saveFile(data)
data = data.decode('utf-8')
#Print captured content
print(data)
#Print all kinds of information about crawling web pages
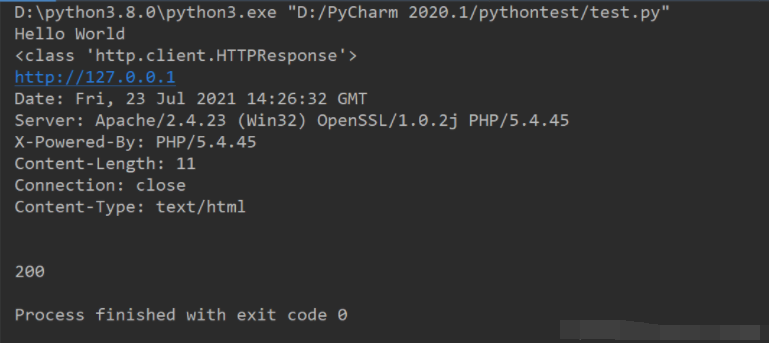
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
result:
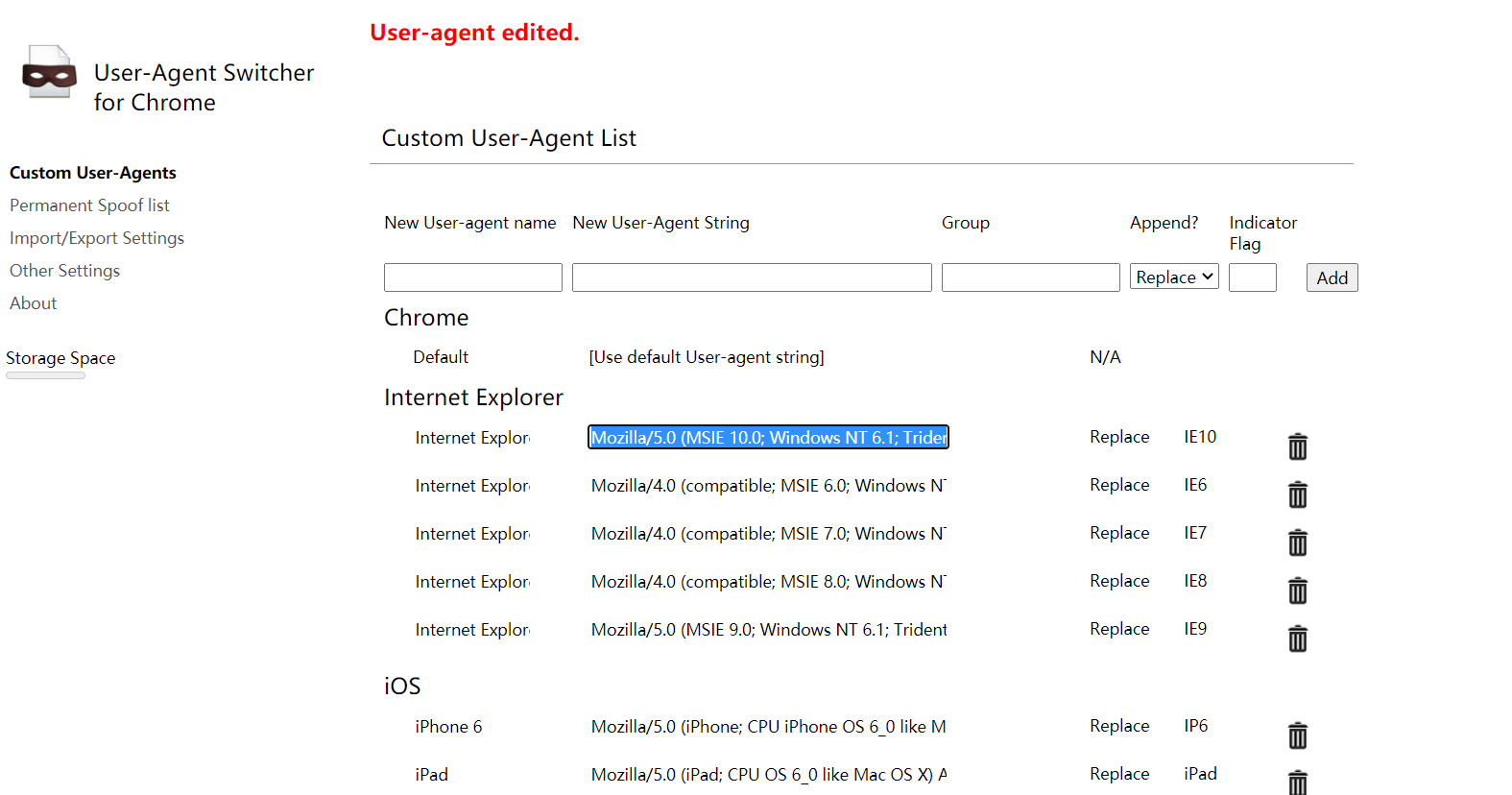
 The forged request header can use Google's plug-in Chrome UA Spoofer
The forged request header can use Google's plug-in Chrome UA Spoofer

Right click the option, and many human users' browsers can be forged and copied directly
3. Subject of forgery request
When crawling some websites, you need to POST data to the server. At this time, you need to forge the request subject;
In order to realize the online translation script of Youdao dictionary, open the development tool in Chrome and find the request with the method of POST under the Network. By observing the data, it can be found that the 'i' in the request body is the content that needs to be translated after URL coding. Therefore, the request body can be forged, such as:
import urllib.request
import urllib.parse
import json
while True:
content = input('Please enter the content to be translated:')
if content == 'exit!':
break
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# Request subject
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'
req = urllib.request.Request(url,data,head) # Forge request header and request body
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print('Translation results: ',(target['translateResult'][0][0]['tgt']))
You can also use add_ The header () method forges the request header, such as:
import urllib.request
import urllib.parse
import json
while True:
content = input('Please enter the content to be translated(exit!):')
if content == 'exit!':
break
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# Request subject
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')
response = urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target = json.loads(html)
print('Translation results: ',(target['translateResult'][0][0]['tgt']))
4. Use proxy IP
In order to avoid IP blocking caused by too frequent crawler collection, proxy IP can be used, such as:
# The parameter is a dictionary {'type': 'proxy ip: port number'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})
# Customize an opener
opener = urllib.request.build_opener(proxy_support)
# Install opener
urllib.request.install_opener(opener)
#Call opener
opener.open(url)
Note: using crawlers to visit the target site too frequently will occupy a lot of server resources. Large scale distributed crawlers to crawl a site in a centralized manner is even equivalent to launching DDOS attacks on the site; Therefore, the crawling frequency and time should be reasonably arranged when using crawlers to crawl data; For example, crawling is performed when the server is relatively idle (e.g. early morning), and a period of time is suspended after completing a crawling task;
5. Detect the encoding mode of the web page
Although most web pages are encoded with UTF-8, sometimes we will encounter web pages using other encoding methods, so we must know the encoding method of web pages in order to correctly decode the crawled pages;
chardet is a third-party module of python, which can automatically detect the coding mode of web pages;
Install chardet: PIP install Charest
use:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()
>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. Get jump link
Sometimes a page needs to jump once or even several times on the basis of the original URL to finally reach the destination page, so it needs to deal with the jump correctly;
Obtain the URL of the jump link through the head() function of the requests module, such as
url='https://unsplash.com/photos/B1amIgaNkwA/download/' res = requests.head(url) re=res.headers['Location']