1. Crawler
With Scrapy, we can easily write a site crawler. However, if the number of sites captured is very large, such as crawling news information of major media, multiple spiders may contain a lot of repetitive code.
If we keep the common parts of spiders in each site and extract different parts as separate configurations, such as crawling rules, page parsing methods and so on, to make a configuration file, then when we add a crawler, we only need to implement crawling rules and extraction rules of these sites.
In this chapter, we will learn about the implementation method of scratch general-purpose crawler.
1.1 CrawlSpider
Before implementing a general-purpose crawler, we need to know about crawlespider, the official document: https://scrapy.readthedocs.io/en/latest/topics/spiders.html#crawlspider.
Crawlespider is a general spider provided by Scrapy. In spider, we can specify some crawling rules to extract pages, which are represented by a special data structure rule. Rule contains the configuration of extraction and follow-up page. Spider will determine which links in the current page need to continue crawling, which page crawling results need to be resolved by which method, etc. according to rule.
Crawlespider inherits from the Spider class. In addition to all the methods and properties of the Spider class, it also provides a very important property and method.
Rules, which is a crawler Rule property, is a list containing one or more Rule objects. Each Rule defines the action of crawling the website. CrawlSpider will read and parse each Rule of the rules.
parse_start_url(), which is an overridable method. When the corresponding Request in start hurls gets the Response, the method is called to analyze the Response and must return the Item object or Request object.
The most important content here is the definition of Rule:
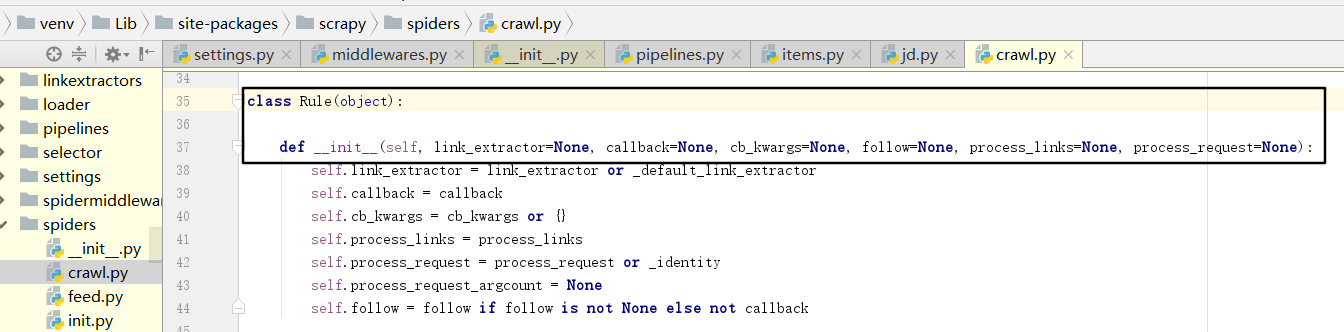
Rule parameter:
- Link? Extractor: is the Link Extractor object. With it, Spider can know which links to extract from the crawled page. The extracted link automatically generates a Request. It is also a data structure, usually using the LxmlLinkExtractor object as a parameter.
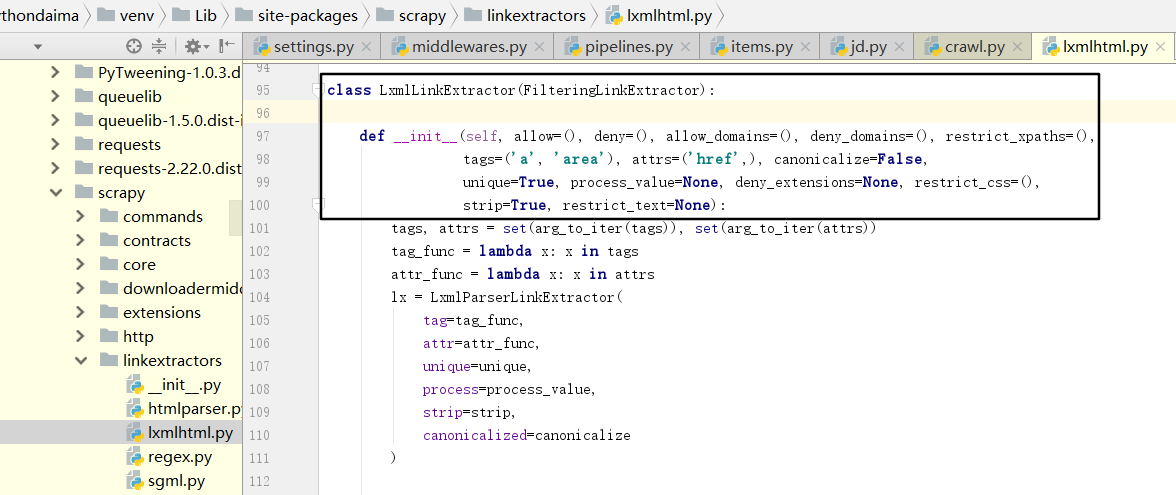
allow is a regular expression or regular expression list. It defines which links extracted from the current page are qualified. Only qualified links will be followed up. deny is the opposite. allow_domains defines a domain name that meets the requirements. Only the link of this domain name will be followed up to generate a new Request, which is equivalent to the domain name to list. deny fields, on the other hand, is the domain name blacklist. restrict_xpaths defines the extraction of links from areas of the current page where the XPath matches, with the value XPath expression or list of XPath expressions. Restrict > css defines to extract links from the matching area of css selectors in the current page. Its value is that css selectors or css selectors list and some other parameters represent the label, de duplication, link processing and other contents of the extracted links. The frequency of use is not high.
Reference documents: https://scrapy.readthedocs.io/en/latest/topics/link-extractors.html#module-scrapy.linkextractors.lxmlhtml.
- Callback: that is, callback function, which has the same meaning as the callback defined previously for Request. This function is called every time a link is retrieved from the link? Extractor. The callback function takes a response as its first parameter and returns a list containing the Item or Request object. Note that avoid using pars() as a callback function. Because CrawlSpider uses the parse() method to implement its logic, if the parse() method is overridden, CrawlSpider will fail to run.
- cb_kwargs: dictionary that contains the parameters passed to the callback function.
- Follow: Boolean value, True or False, which specifies whether the link extracted from response according to the rule needs to be followed up. If the callback parameter is None, follow is set to True by default, otherwise it is False by default.
- Process'links: Specifies the processing function that will be called when the list of links is obtained from the link'extractor, which is mainly used for filtering.
- process_request: it is also a specified processing function. When each Request is extracted according to the Rule, the function department will call to process the Request. The function must return Request or None.
The above is the basic usage of the core Rule in craefisipider. But that may not be enough to complete a crawler spider. Next, we use crawlespider to implement crawling instance of news website to better understand the usage of Rule.
1.2 Item Loader
We learned how to use the rules of crawler to define the crawling logic of the page, which is a part of configurability. However, Rule does not define how items are extracted. For Item extraction, we need to use another module, Item Loader.
Item Loader provides a convenient mechanism to help us extract items easily. It provides a series of API s to analyze the original data and assign values to items. Item provides a container to hold the captured data, while Item Loader provides a mechanism to fill the container. With it, data extraction will become more regular.
Item LoaderAPI parameter:
Item: it is an item object, which can be filled by calling methods such as add_xpath(), add_css(), or add_value().
Selector: it is a selector object, which is used to extract the filled data.
Response: it is a response object that uses the response of the construction selector.
Example:
from scrapy.loader import ItemLoader from scrapyDemo.items import Productdef parse(self, response):
loader = ItemLoader(item=Product(),response=response)
loader.add_xpath('name','//div[@class="product_name"]')
loader.add_xpath('name','//div[@class="product_title"]')
loader.add_xpath('price','//p[@id="price"]')
loader.add_css('stock','p#stock]')
loader.add_value('last_updated','today')
return loader.load_item()
Here we first declare a Product Item, instantiate Item Loader with the Item and Response objects, call add_xpath() method to extract data from two different locations, assign them to name attributes, and then assign values to different attributes in turn by add_xpath(), add_css(), add_value(), and finally invoke the method of add_css() to implement the analysis of the name. This way is more regular. We can extract some parameters and rules separately and make them into configuration files or save them in the database to realize configurability.
In addition, each field of Item Loader contains an Input Processor and an Output Processor. When the Input Processor receives the data, it immediately extracts the data. The results of the Input Processor are collected and saved in ltemLoader, but are not assigned to the Item. After all the data is collected, the load Item () method is called to populate and regenerate the Item object. When it is called, the Output Processor will be called first to process the previously collected data, and then stored in the Item, so the Item is generated.
Built in Processor:
(1) Identity
Identity is the simplest Processor, which directly returns the original data without any processing.
(2) TakeFirst
TakeFirst returns the first non null value of the list, which is similar to the extract_first() function. It is often used as Output Processor.
from scrapy.loader.processors import TakeFirst processor = TakeFirst() print(processor(['',1,2,3]))
The run result is 1.
(3) Join
The Join method is equivalent to the join() method of string, which can combine the list into a string. The string is separated by space by default.
from scrapy.loader.processors import Join processor = Join() print(processor(['one','two','three']))
The result is one two three.
It can also change the default separator by parameters, such as comma:
from scrapy.loader.processors import Join processor = Join(',') print(processor(['one','two','three']))
The result is one,two,three.
(4) Compose
Compose is a Processor constructed by the combination of given multiple functions. Each input value is passed to the first function, its output is passed to the second function, and so on until the last function returns the output of the whole Processor.
from scrapy.loader.processors import Compose processor = Compose(str.upper,lambda s:s.strip()) print(processor('hello world'))
The running result is HELLO WORLD.
Here we construct a Compose Processor, passing in a string with a space at the beginning. There are two parameters of Compose Processor: the first is str.upper, which can change all letters to uppercase; the second is an anonymous function, which calls the strip() method to remove the first and last blank characters. Compose will call two parameters in sequence, and finally all the strings returned will be converted to uppercase and the spaces at the beginning will be removed.
(5) MapCompose
Similar to Compose, MapCompose can iterate through a list input value.
from scrapy.loader.processors import MapCompose processor = MapCompose(str.upper,lambda s:s.strip()) print(processor(['Hello','World','Python']))
The result of the run is ['HELLO','WORLD','PYTHON'].
The content to be processed is an iterative object, which MapCompose will traverse and process in turn.
(6) SelectJmes
SelectJmes can query JSON, pass in Key, and return the Value obtained by query. However, you need to install the jmespath library before you can use it.
pip install jmespath
After jmespath is installed, you can use the Processor.
from scrapy.loader.processors import SelectJmes processor = SelectJmes('foo') print(processor({'foo':'bar'}))
The operation result is: bar.
The above are some common processors. In the example in this section, we will use processors to process data. Next, let's use an example to understand the usage of Item Loader.
1.3 general reptile cases
This time we simply crawled some novel information from the starting point novel website. I will not do distributed crawlers. I will directly use the video information cases of crawling b station and crawling novel cases as the end.
As a mainstream novel website, the starting point has made preparations to prevent the reverse of data collection. It uses a custom code mapping value for the main numbers, and it is impossible to achieve data acquisition directly through the page.
It can be achieved to get numbers alone. Send a request through requests, match character elements with regularity, and match the url of their mapping relationship again. The data obtained is parsed into dictionary format by font package tool, and then code matching is done. The code returned from the starting point matches English numbers, and English numbers match Arabic numbers. Finally, the actual number string is obtained by splicing, However, the crawling efficiency will be greatly reduced by sending the request many times. In this centralized crawling, the crawling numbers are abandoned and the easily obtained scoring numbers are selected. The default score value is 0, which is updated from the js data pushed in the background.
But it's too complicated. I don't have time to do it. Now I just make time to write blog.
1.3.1 new project
First, create a new scratch project named qd.
scrapy startproject qd
To create a crawler spider, you need to develop a template first. We can first see what templates are available.
scrapy genspider -l
Operation result:

When we created Spider, we used the first template basic by default. To create the crawlespider this time, you need to use the second template, crawler.
scrapy genspider -t crawl read qidian.com
After running, a crawlespider will be generated.
The Spider content generated this time has an additional definition of the rules attribute. The first parameter of Rule is LinkExtractor, which is the LxmllinkExtractor mentioned above, but with different names. At the same time, the default callback function is no longer parse, but parse item.
1.3.2 define Rule
To achieve the crawling of novel information, we need to define the Rule, and then implement the analytic function. Let's go step by step to realize this process.
First, change start_urls to start link.
start_urls = ['https://www.qidian.com/all?orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page=1']
After that, the Spider crawls every link in start ENU URLs. So the first page to crawl here is the link we just defined. After getting the Response, Spider will extract the hyperlinks in this page according to each Rule to generate further requests. Next, we need to define rules to specify which links to extract.

This is the list page of the start novel network. The next step is naturally to extract the links of each novel detail in the list. Here you can directly specify the area where these links are located.
rules:
rules = ( #Match all master pages url Rule depth crawl subpage Rule(LinkExtractor(allow=(r'https://www.qidian.com/all\?orderId=\&style=1\&pageSize=20\&siteid=1\&pubflag=0\&hiddenField=0\&page=(\d+)')),follow=True), #No depth crawling for matching details page Rule(LinkExtractor(allow=r'https://book.qidian.com/info/(\d+)'), callback='parse_item', follow=False), )
1.3.3 Analysis page
What we need to do next is to analyze the content of the page, and extract the title, author, status, type, introduction, score, story and the latest chapter. First define an Item.
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html from scrapy import Field,Item class QdItem(Item): # define the fields for your item here like: book_name = Field() #Title author=Field() #author state=Field() #state type=Field() #type about=Field() #brief introduction score=Field() #score story=Field() #Story news=Field() #Latest chapters
Then I created many methods to get the information separately.
def get_book_name(self,response): book_name=response.xpath('//h1/em/text()').extract()[0] if len(book_name)>0: book_name=book_name.strip() else: book_name='NULL' return book_name def get_author(self,response): author=response.xpath('//h1/span/a/text()').extract()[0] if len(author)>0: author=author.strip() else: author='NULL' return author def get_state(self,response): state=response.xpath('//p[@class="tag"]/span/text()').extract()[0] if len(state)>0: state=state.strip() else: st='NULL' return state def get_type(self,response): type=response.xpath('//p[@class="tag"]/a/text()').extract() if len(type)>0: t="" for i in type: t+=' '+i type=t else: type='NULL' return type def get_about(self,response): about=response.xpath('//p[@class="intro"]/text()').extract()[0] if len(about)>0: about=about.strip() else: about='NULL' return about def get_score(self,response): def get_sc(id): urll = 'https://book.qidian.com/ajax/comment/index?_csrfToken=ziKrBzt4NggZbkfyUMDwZvGH0X0wtrO5RdEGbI9w&bookId=' + id + '&pageSize=15' rr = requests.get(urll) # print(rr) score = rr.text[16:19] return score bid=response.xpath('//a[@id="bookImg"]/@data-bid').extract()[0] #Book acquisition id if len(bid)>0: score=get_sc(bid) #Calling the method to get the score may return 9 if it is an integer," if score[1]==',': score=score.replace(',"',".0") else: score=score else: score='NULL' return score def get_story(self,response): story=response.xpath('//div[@class="book-intro"]/p/text()').extract()[0] if len(story)>0: story=story.strip() else: story='NULL' return story def get_news(self,response): news=response.xpath('//div[@class="detail"]/p[@class="cf"]/a/text()').extract()[0] if len(news)>0: news=news.strip() else: news='NULL' return news
There is no change in other parts, so the settings add the request header:
DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv 11.0) like Gecko', }
1.3.4 operation procedure
scrapy crawl read
Operation result:

1.3.5 complete code
read.py:
# -*- coding: utf-8 -*- from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from qd.items import QdItem import requests class ReadSpider(CrawlSpider): name = 'read' # allowed_domains = ['qidian.com'] start_urls = ['https://www.qidian.com/all?orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page=1'] rules = ( #Match all master pages url Rule depth crawl subpage Rule(LinkExtractor(allow=(r'https://www.qidian.com/all\?orderId=\&style=1\&pageSize=20\&siteid=1\&pubflag=0\&hiddenField=0\&page=(\d+)')),follow=True), #No depth crawling for matching details page Rule(LinkExtractor(allow=r'https://book.qidian.com/info/(\d+)'), callback='parse_item', follow=False), ) def parse_item(self, response): item=QdItem() item['book_name']=self.get_book_name(response) item['author']=self.get_author(response) item['state']=self.get_state(response) item['type']=self.get_type(response) item['about']=self.get_about(response) item['score']=self.get_score(response) item['story']=self.get_story(response) item['news']=self.get_news(response) yield item def get_book_name(self,response): book_name=response.xpath('//h1/em/text()').extract()[0] if len(book_name)>0: book_name=book_name.strip() else: book_name='NULL' return book_name def get_author(self,response): author=response.xpath('//h1/span/a/text()').extract()[0] if len(author)>0: author=author.strip() else: author='NULL' return author def get_state(self,response): state=response.xpath('//p[@class="tag"]/span/text()').extract()[0] if len(state)>0: state=state.strip() else: st='NULL' return state def get_type(self,response): type=response.xpath('//p[@class="tag"]/a/text()').extract() if len(type)>0: t="" for i in type: t+=' '+i type=t else: type='NULL' return type def get_about(self,response): about=response.xpath('//p[@class="intro"]/text()').extract()[0] if len(about)>0: about=about.strip() else: about='NULL' return about def get_score(self,response): def get_sc(id): urll = 'https://book.qidian.com/ajax/comment/index?_csrfToken=ziKrBzt4NggZbkfyUMDwZvGH0X0wtrO5RdEGbI9w&bookId=' + id + '&pageSize=15' rr = requests.get(urll) # print(rr) score = rr.text[16:19] return score bid=response.xpath('//a[@id="bookImg"]/@data-bid').extract()[0] #Book acquisition id if len(bid)>0: score=get_sc(bid) #Calling the method to get the score may return 9 if it is an integer," if score[1]==',': score=score.replace(',"',".0") else: score=score else: score='NULL' return score def get_story(self,response): story=response.xpath('//div[@class="book-intro"]/p/text()').extract()[0] if len(story)>0: story=story.strip() else: story='NULL' return story def get_news(self,response): news=response.xpath('//div[@class="detail"]/p[@class="cf"]/a/text()').extract()[0] if len(news)>0: news=news.strip() else: news='NULL' return news
items.py:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html from scrapy import Field,Item class QdItem(Item): # define the fields for your item here like: book_name = Field() #Title author=Field() #author state=Field() #state type=Field() #type about=Field() #brief introduction score=Field() #score story=Field() #Story news=Field() #Latest chapters
settings.py:
# -*- coding: utf-8 -*- # Scrapy settings for qd project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://docs.scrapy.org/en/latest/topics/settings.html # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html # https://docs.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'qd' SPIDER_MODULES = ['qd.spiders'] NEWSPIDER_MODULE = 'qd.spiders' DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv 11.0) like Gecko', } # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'qd (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'qd.middlewares.QdSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'qd.middlewares.QdDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://docs.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'qd.pipelines.QdPipeline': 300, #} # Enable and configure the AutoThrottle extension (disabled by default) # See https://docs.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
middlewares.py:
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://docs.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals class qdSpiderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_spider_input(self, response, spider): # Called for each response that goes through the spider # middleware and into the spider. # Should return None or raise an exception. return None def process_spider_output(self, response, result, spider): # Called with the results returned from the Spider, after # it has processed the response. # Must return an iterable of Request, dict or Item objects. for i in result: yield i def process_spider_exception(self, response, exception, spider): # Called when a spider or process_spider_input() method # (from other spider middleware) raises an exception. # Should return either None or an iterable of Request, dict # or Item objects. pass def process_start_requests(self, start_requests, spider): # Called with the start requests of the spider, and works # similarly to the process_spider_output() method, except # that it doesn't have a response associated. # Must return only requests (not items). for r in start_requests: yield r def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name) class qdDownloaderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)
pipelines.py:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html class QdPipeline(object): def process_item(self, item, spider): return item