requirement analysis
Knowing one's own self and the other will keep you alive.When learning technology, we are often confronted with too many choices and don't know what to do, maybe in all respects
If you are interested in something and do not have a thorough study in a certain field, it seems that you can do anything, you will be overwhelmed when you really want to do something.If
We can start with the skills we need to recruit for a job, and then we can do all the hard work to lay a good foundation for practical applications.
Use python to capture the recruitment details of the hooknet and filter the skill keywords to store in excel.
Job Requirements Page Analysis
As you can see from your observations, the details of the job page that is checked out are as follows: http://www.lagou.com/jobs/
PositionId.html composition.
PositionId can be obtained by analyzing Json's XHR.The job description in the red box is the data we want to capture.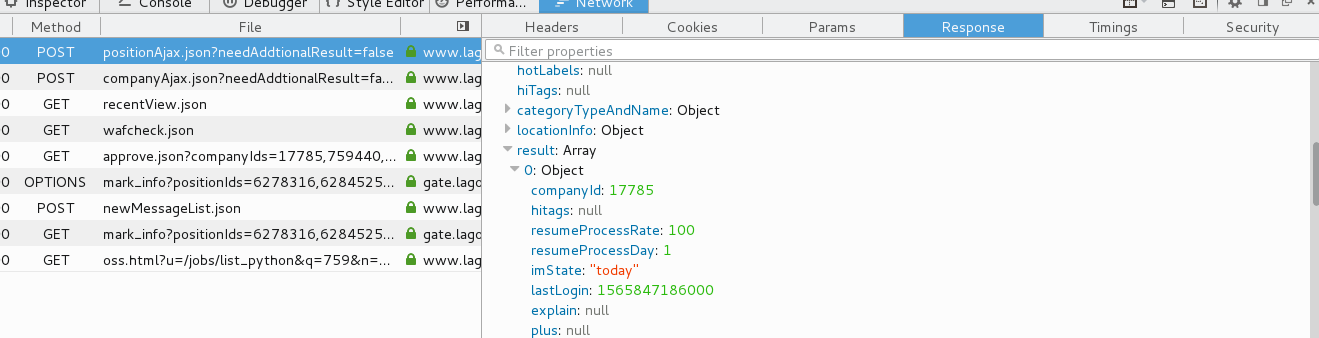
Knowing the source of the data, follow the general steps of wrapping Headers and submitting FormData to get feedback.
PositionId data collection
Be careful:
The pull-hook anti-crawler does more rigorously, so the request header can add a few more parameters to be unrecognized by the website.
We found the real request URL and found that a JSON string was returned. Parse the JSON string and note that it is POST
Pass value to control page flipping by changing the value of pn in Form Data.
XHR: The XMLHttpRequest object is used to exchange data with the server.
By clicking on the number of pages on a page, such as page 2, we can see a POST request on the right that contains the real one
URLs (URLs on browsers do not have job data, which can be found by looking at the source code), request headers for POST requests
Headers, POST Request Submitted Form Data (Page Information pn, Searched Job Information kd included here)
Real URL Acquisition
Request Header Information
The request Headers information that we need to construct is easily identified by the site as a crawler if it is not constructed here, thereby denying access to the request.
form fields
Form Data is the form information you need to include when sending a POST request.
JSON data returned
Find the required job information under content -> positionResult -> result, which contains information about the location, company name, position, etc.We just need to save this data.
Now that we have analyzed the web page, we can start the crawling process.
Project Code
configuration file config.py file
""" Date: 2019--14 10:36 User: yz Email: 1147570523@qq.com Desc: """ from fake_useragent import UserAgent import requests Host='www.lagou.com' Accept='application/json, text/javascript, */*; q=0.01' Connection='keep-alive' Origin='https://www.lagou.com' Referer='https://www.lagou.com/jobs/list_python' ua=UserAgent(verify_ssl=False) url = 'http://172.25.254.39: 9999/get_proxy/' proxies = requests.get(url).text pages = 20 # csv file location where information is stored csv_filename = 'lagou.csv' # Number of threads opened by multiple threads; ThreadCount = 100
Core Code File run.py
Data Storage:
csv format
Open thread pool, crawl job information in batch and store in csv file;
Modify file run.py : Encapsulate page crawling and page parsing tasks;
"""
Date: 2019--14 10:10
User: yz
Email: 1147570523@qq.com
Desc:
"""
import requests
import logging
import pandas as pd
import time
import pprint
from config import *
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='lagou.log',
filemode='w')
def getPositionIDPage(url_start, url_parse, page=1, kd='python'):
headers = {'User-Agent': ua.random,
'Host': Host,
'Origin': Origin,
'Referer': Referer,
'Connection': Connection,
'Accept': Accept,
'proxies': proxies
}
# Construct Form
data = {
'first': True,
'pn': str(page),
'kd': kd
}
try:
# The session object of the requests library helps us keep certain parameters across requests.
# cookies are also maintained between all requests made by the same session instance.
# Create a session object
session = requests.Session()
# Make a get request with the session object, set cookies
session.get(url_start, headers=headers, timeout=3) # Request Home Page for cookies
cookie = session.cookies # cookies acquired for this time
# Send another post request with session object, get cookies, return response information
response = session.post(url=url_parse,
headers=headers,
data=data,
)
time.sleep(1)
# Response status code is 4xx client error or 5xx server error response to throw an exception:
response.raise_for_status()
response.encoding = response.apparent_encoding
# print(cookie)
except Exception as e:
logging.error("page" + url_parse + "Crawl failed:", e)
else:
logging.info("page" + url_parse + "Crawl succeeded" + str(response.status_code))
return response.json()
def analyse_PositionID(html):
"""
//Resolve each job page details according to the pages you get there is an ID index to which it belongs
:param html:
:return:
"""
# tag = 'positionId'
positions = html['content']['positionResult']['result']
df = pd.DataFrame(positions)
return df
def task(page):
# Label page surface
url_start = 'https://www.lagou.com/jobs/list_python'
url_parse = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
html = getPositionIDPage(url_start, url_parse,page=page)
# pprint.pprint(content)
df = analyse_PositionID(html)
# Parse the page and return the data in DataFrame format;
return df
def save_as_csv():
"""
//Store the retrieved parsed information in csv format to a file in a multi-threaded manner
:return:
"""
# Open Thread Pool
with ThreadPoolExecutor(ThreadCount) as pool:
# In the map method, the iterative object-passing function extracts elements one by one from the front to the back, and stores the results in results in turn.
results = pool.map(task, range(1, pages + 1))
# For all information obtained by stitching, axis=0 means down, and axis=1 means across.
total_df = pd.concat(results, axis=0)
"""
sep: Field delimiter for output file, Default to comma;
header: Whether to write column names;
index: Whether to write row names(Indexes);
"""
total_df.to_csv(csv_filename, sep=',', header=True, index=False)
logging.info("file%s Storage Success" % (csv_filename))
return total_df
if __name__ == '__main__':
save_as_csv()
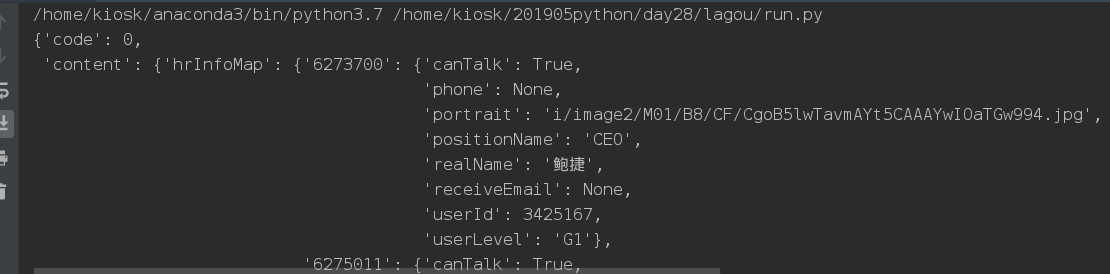
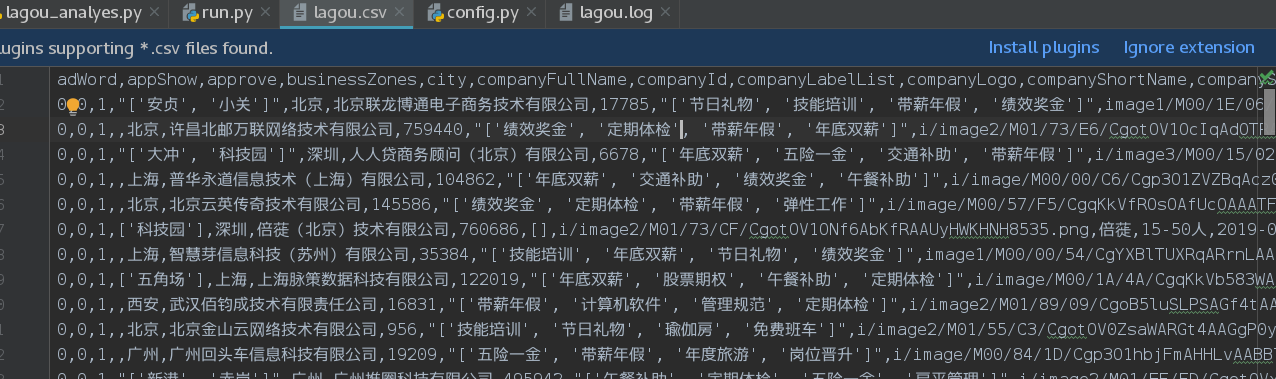
PositionId page parsing
Get the required job ID, and each job page detail has an ID index to which it belongs.Extract the information we want from the information we crawl down.
Core Code:
"""
Date: 2019--14 11:52
User: yz
Email: 1147570523@qq.com
Desc:
"""
import pandas as pd
from config import *
import matplotlib.pyplot as plt
import matplotlib # Configure Chinese fonts and modify font size
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family'] = 'sans-serif'
matplotlib.rcParams['font.size'] = 12
# Used for normal negative sign display
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_csv(csv_filename, encoding='utf-8')
def show_second_type():
# Get job category classification and group statistics
secondType_Series = df['secondType'].value_counts()
# Set the size of the graphic;
plt.figure(figsize=(10, 5))
# Draw bar charts;
secondType_Series.plot.bar()
# Display Graphics
plt.show()
def show_job_nature():
jobNature_Series = df['jobNature'].value_counts()
print(jobNature_Series)
plt.figure(figsize=(10, 5))
# Pie chart
jobNature_Series.plot.pie()
plt.show()
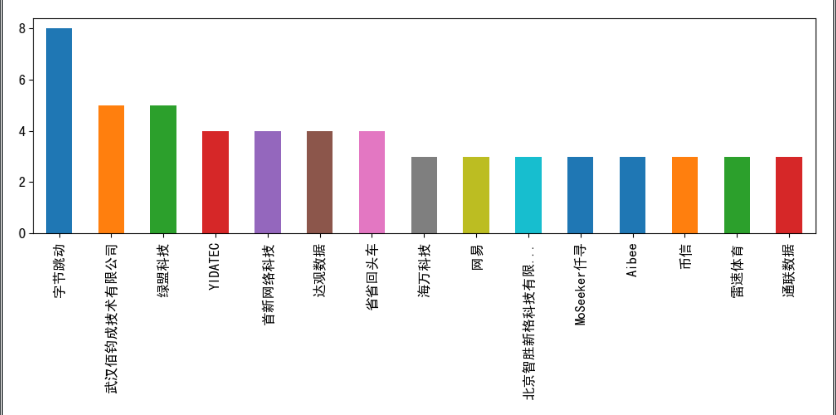
def show_company():
companyShortName_Series = df['companyShortName'].value_counts()
companyShortName_Series_gt5 =companyShortName_Series[companyShortName_Series > 2] # Select companies with more than or equal to 5 Python-related positions
plt.figure(figsize=(10, 5))
companyShortName_Series_gt5.plot.bar()
plt.show()
if __name__ == '__main__':
show_second_type()
show_job_nature()
show_company()
Position category statistics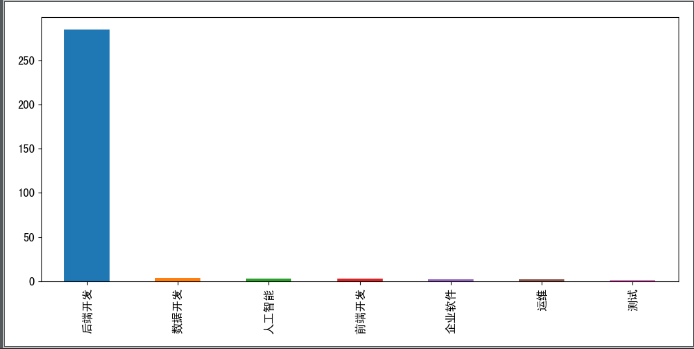
Company Statistics
Count the number of occurrences of each company, and then select companies that have more than or equal to 2 Python-related positions.