Font crawling
Font anti-crawling is also called custom font anti-crawling. By calling custom font file to render the text in the web page, and the text in the web page is no longer text, but the corresponding font encoding. It is impossible to capture the encoded text content by copying or simple acquisition.
Now it seems that many websites have adopted this anti-crawling mechanism, we explain it through the actual situation of cat's eye.
Below is the cat's eye page.
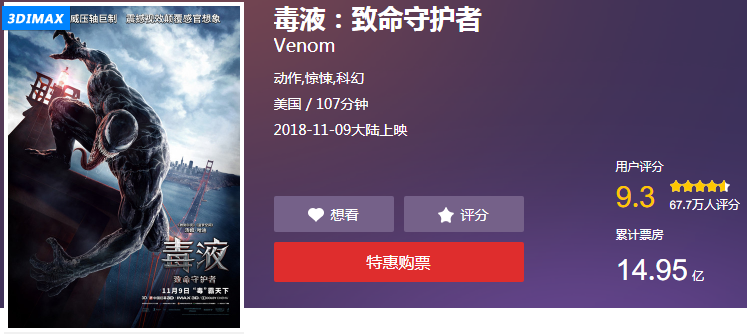
Look at the elements
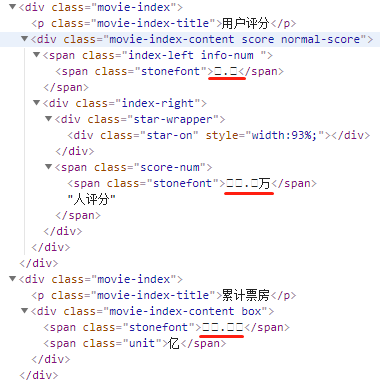
What the hell is this? The key information is all messy.
Learners familiar with CSS know that there is an @font-face in CSS, which allows web developers to specify online fonts for their pages. Originally used to eliminate the dependence on user computer fonts, now has a new role - anti-crawling.
There are thousands of Chinese characters in common use. If all of them are placed in custom fonts, the font files will become very large, which will inevitably affect the loading speed of web pages. Therefore, most websites will choose key content to protect them. As shown above, knowing is equal to not knowing.
The scrambling here is caused by unicode encoding. Looking at the source file, you can see the specific encoding information.
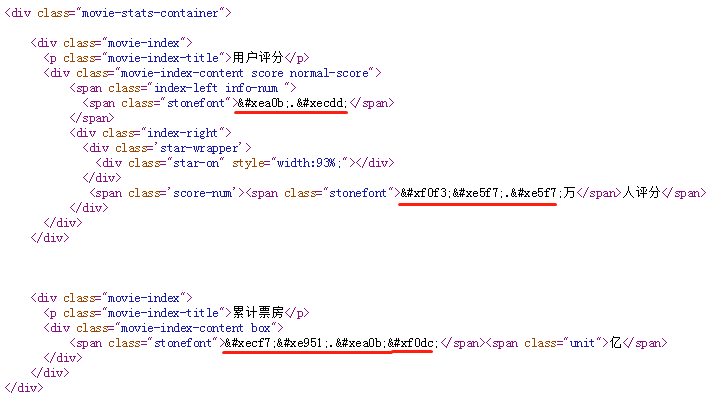
Search for stonefont and find the definition of @font-face:

Here, the. woff file is the font file. We download it and open it using the http://fontstore.baidu.com/static/editor/index.html page, which shows as follows:

The page source code shows & xea0b; is it a bit like what's shown here? In fact, it's true that by removing the beginning and end of the word x, the remaining four hexadecimal digits plus uni are the encoding in the font file. So & # xea0b corresponds to the number "9".
Knowing the principle, let's see how to achieve it.
To process font files, we need to use the FontTools library.
First convert font file to xml file.
from fontTools.ttLib import TTFont
font = TTFont('bb70be69aaed960fa6ec3549342b87d82084.woff')
font.saveXML('bb70be69aaed960fa6ec3549342b87d82084.xml')
Open the xml file
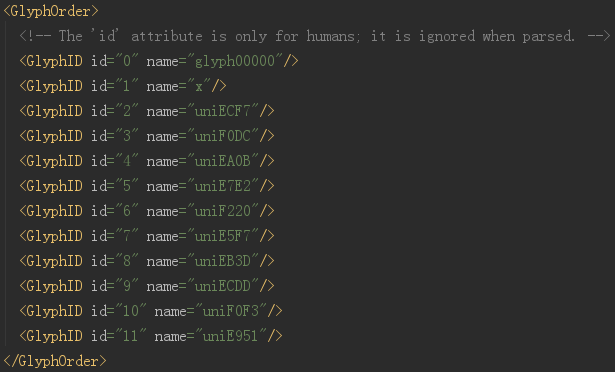
At the beginning, it shows all the codes. The id here is just the number. Don't think it's the real value. In fact, there is no place in the entire font file to explain what the real value of EA0B is.
See below
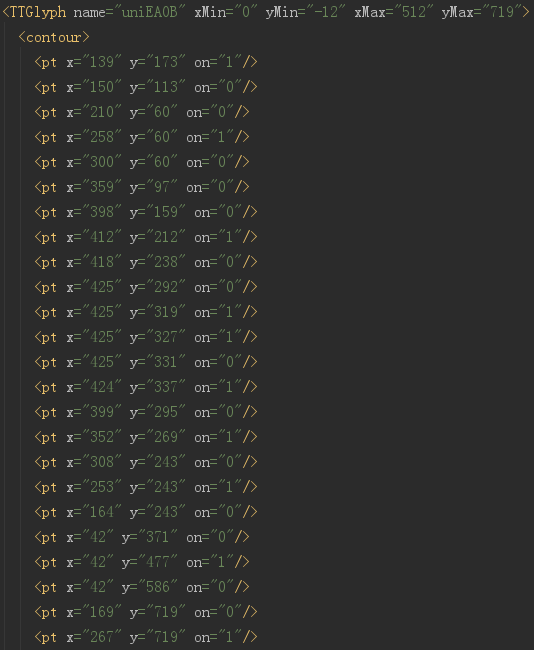
Here is the font information corresponding to each word. When the computer displays, it is not necessary to know what the word is, just know which pixel is black and which pixel is white.
Cat's eye font file is loaded dynamically, and changes every refresh. Although only 9 digits of 0-9 are defined in the font, the encoding and order will change. That is to say, "EA0B" in this font file represents "9", but not in other files.
However, one thing remains unchanged, that is, the shape of the word, which is the points defined in the figure above.
We first download a font file named base.woff, then use fontstore website to see the corresponding relationship between the code and the actual value, manually make a dictionary and save it. When the crawler crawls, download the font file, find the font in the font file according to the code in the source code of the web page, and recycle it to compare with the font in the base.woff file. The font is the same word as the font. After finding "glyph" in base.woff, we get the encoding of "glyph", and we have manually mapped the encoding with the value, so we can get the actual value we want.
The premise here is that the "glyph" defined in each font file is the same (cat's eye is like this, and may change the strategy later). If more complex, each font has a little random deformation, then this method is useless, only the killer mace "OCR" is offered.
The following is the complete code, grabbing the first page of the Cat's Eye 2018 movie, because the main demonstration is to crack the font anti-crawl, so did not grab all the data.
The base.woff file used in the code is not the same as the screenshot above, so you can see that the code and the value do not match the above.
import os
import time
import re
import requests
from fontTools.ttLib import TTFont
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
host = 'http://maoyan.com'
def main():
url = 'http://maoyan.com/films?yearId=13&offset=0'
get_moviescore(url)
os.makedirs('font', exist_ok=True)
regex_woff = re.compile("(?<=url\(').*\.woff(?='\))")
regex_text = re.compile('(?<=<span class="stonefont">).*?(?=</span>)')
regex_font = re.compile('(?<=&#x).{4}(?=;)')
basefont = TTFont('base.woff')
fontdict = {'uniF30D': '0', 'uniE6A2': '8', 'uniEA94': '9', 'uniE9B1': '2', 'uniF620': '6',
'uniEA56': '3', 'uniEF24': '1', 'uniF53E': '4', 'uniF170': '5', 'uniEE37': '7'}
def get_moviescore(url):
# headers = {"User-Agent": UserAgent(verify_ssl=False).random}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.106 Safari/537.36'}
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
ddlist = soup.find_all('dd')
for dd in ddlist:
a = dd.find('a')
if a is not None:
link = host + a['href']
time.sleep(5)
dhtml = requests.get(link, headers=headers).text
msg = {}
dsoup = BeautifulSoup(dhtml, 'lxml')
msg['name'] = dsoup.find(class_='name').text
ell = dsoup.find_all('li', {'class': 'ellipsis'})
msg['type'] = ell[0].text
msg['country'] = ell[1].text.split('/')[0].strip()
msg['length'] = ell[1].text.split('/')[1].strip()
msg['release-time'] = ell[2].text[:10]
# Download font files
woff = regex_woff.search(dhtml).group()
wofflink = 'http:' + woff
localname = 'font\\' + os.path.basename(wofflink)
if not os.path.exists(localname):
downloads(wofflink, localname)
font = TTFont(localname)
# Contains unicode Character, BeautifulSoup Cannot display properly, can only use the original text through regular access
ms = regex_text.findall(dhtml)
if len(ms) < 3:
msg['score'] = '0'
msg['score-num'] = '0'
msg['box-office'] = '0'
else:
msg['score'] = get_fontnumber(font, ms[0])
msg['score-num'] = get_fontnumber(font, ms[1])
msg['box-office'] = get_fontnumber(font, ms[2]) + dsoup.find('span', class_='unit').text
print(msg)
def get_fontnumber(newfont, text):
ms = regex_font.findall(text)
for m in ms:
text = text.replace(f'&#x{m};', get_num(newfont, f'uni{m.upper()}'))
return text
def get_num(newfont, name):
uni = newfont['glyf'][name]
for k, v in fontdict.items():
if uni == basefont['glyf'][k]:
return v
def downloads(url, localfn):
with open(localfn, 'wb+') as sw:
sw.write(requests.get(url).content)
if __name__ == '__main__':
main()