I believe that after learning python crawling, many people want to crawl some websites with a large amount of data. Taobao is a good target. It has a large amount of data, a wide variety of types and is not very difficult, and it is very suitable for beginners to crawl.Here is the entire crawl process:
Step 1: Build a url for access
#Build a url for access goods = "Fishtail skirt" page = 10 infoList = [] url = 'https://s.taobao.com/search' for i in range(page): s_num = str(44*i+1) num = 44*i data = {'q':goods,'s':s_num}
Step 2: Get Web Page Information
def getHTMLText(url,data): try: rsq = requests.get(url,params=data,timeout=30) rsq.raise_for_status() return rsq.text except: return "No page found"
Step 3: Get the data you need using the rules
def parasePage(ilt, html,goods_id): try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) slt = re.findall(r'\"view_sales\"\:\".*?\"', html) tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) ult = re.findall(r'\"pic_url\"\:\".*?\"', html) dlt = re.findall(r'\"detail_url\"\:\".*?\"', html) for i in range(len(plt)): goods_id += 1 price = eval(plt[i].split(':')[1]) sales = eval(slt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) pic_url = "https:" + eval(ult[i].split(':')[1]) detail_url = "https:" + eval(dlt[i].split(':')[1]) ilt.append([goods_id,price,sales,title,pic_url,detail_url]) return ilt except: print("We can't find what you need!")
Step 4: Save the data to a csv file
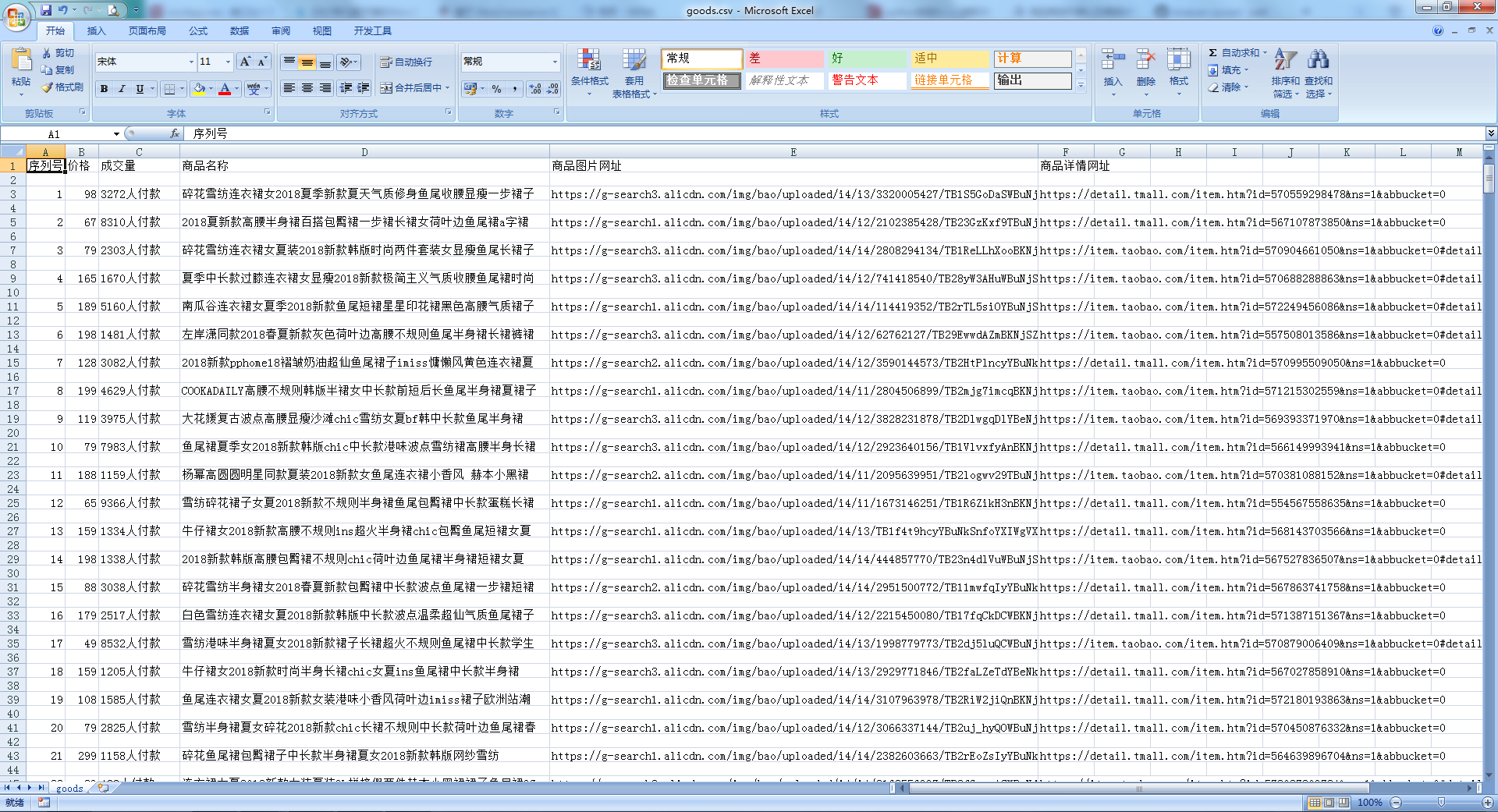
def saveGoodsList(ilt): with open('goods.csv','w') as f: writer = csv.writer(f) writer.writerow(["serial number", "Price", "volume", "Commodity Name","Merchandise Picture Web Address","Merchandise Details Web Site"]) for info in ilt: writer.writerow(info)
Here is the complete code:
import csv import requests import re #Get Web Page Information def getHTMLText(url,data): try: rsq = requests.get(url,params=data,timeout=30) rsq.raise_for_status() return rsq.text except: return "No page found" #Get the data you need regularly def parasePage(ilt, html,goods_id): try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) slt = re.findall(r'\"view_sales\"\:\".*?\"', html) tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) ult = re.findall(r'\"pic_url\"\:\".*?\"', html) dlt = re.findall(r'\"detail_url\"\:\".*?\"', html) for i in range(len(plt)): goods_id += 1 price = eval(plt[i].split(':')[1]) sales = eval(slt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) pic_url = "https:" + eval(ult[i].split(':')[1]) detail_url = "https:" + eval(dlt[i].split(':')[1]) ilt.append([goods_id,price,sales,title,pic_url,detail_url]) return ilt except: print("We can't find what you need!") #Save data to csv file def saveGoodsList(ilt): with open('goods.csv','w') as f: writer = csv.writer(f) writer.writerow(["serial number", "Price", "volume", "Commodity Name","Merchandise Picture Web Address","Merchandise Details Web Site"]) for info in ilt: writer.writerow(info) #Run the program if __name__ == '__main__': #Build a url for access goods = "Fishtail skirt" page = 10 infoList = [] url = 'https://s.taobao.com/search' for i in range(page): s_num = str(44*i+1) num = 44*i data = {'q':goods,'s':s_num} try: html = getHTMLText(url,data) ilt = parasePage(infoList, html,num) saveGoodsList(ilt) except: continue
The results are as follows: