Data Structure and Algorithms
1. Decomposition the sequence into separate variables
-
problem Need to decompose the primitive and sequence of N elements into N separate variables
-
Solution Using unpacking to decompose iterative objects
>>> p = (4, 5) >>> a, b = p >>> a 4 >>> b 5 >>> data = ['xyb', 18, 180, ('mmm', 20, 165)] >>> name, age, tall, another = data >>> name 'xyb' >>> another ('mmm', 20, 165)
Not only tuples and lists, but also iterative objects can be decomposed, including strings, files, iterators, and so on.
>>> s = '1,2,3' >>> a, _, b, _, c = s >>> a '1' >>> b '2' >>> c '3'
-
master Unneeded data is discarded with ____________.
2. Decomposition of Elements from Iterative Objects of Arbitrary Length
-
problem You need to decompose N objects from an iterative object, but the object may be longer than N, which will be abnormal
-
Solution Use * to match unpacking
>>> data = ['xyb', 18, 13586971744, 19857100635] >>> name, age, *number = data >>> name 'xyb' >>> number [13586971744, 19857100635]
-
master Intercept unknown data by *_
>>> one, *_, last = socres >>> one 1 >>> last 8 >>> _ [5, 6, 7, 8, 10, 64, 21]
3. Use a two-way queue to record history
-
problem We want to keep records of the last few times in iterations or other forms, i.e. historical records
-
Solution Using a two-way queue deque to help us complete
from collections import deque # 1. Without maximizing the queue, the queue is infinite >>> q = deque() >>> q.append(5) >>> q.append(6) >>> q.append(7) >>> q.appendleft(0) >>> q deque([0, 5, 6, 7]) >>> q.pop() 7 # 2. Give the maximum >>> q = deque(maxlen=3) >>> q.append(1) >>> q.append(2) >>> q.append(3) >>> q deque([1, 2, 3], maxlen=3) >>> q.append(4) >>> q deque([2, 3, 4], maxlen=3)
-
In a two-way queue, the complexity of adding and ejecting at both ends of the queue is O[1]
4. Find the largest or smallest N elements
-
problem Find the largest or smallest N elements in the set
-
Solution Use heapq Two functions in the module nlargest( ) - and - nsmallest()
>>> import heapq >>> nums = [1, 2, 5, 6, -8, 15, -32, 24, 6, 42, 0] >>> heapq.nlargest(3, nums) [42, 24, 15] >>> heapq.nsmallest(3, nums) [-32, -8, 0] # 1. He can also accept a key to operate on more complex data structures. >>> data = [ ... {'name': 'xyb', 'age': 18}, ... {'name': 'habby', 'age': 10}, ... {'name': 'yollw', 'age': 26} ... ] >>> heapq.nlargest(2, data, key=lambda x: x['age']) [{'name': 'yollw', 'age': 26}, {'name': 'xyb', 'age': 18}] >>> heapq.nsmallest(2, data, key=lambda x: x['age']) [{'name': 'habby', 'age': 10}, {'name': 'xyb', 'age': 18}]
-
extend If the data N to be sought is much smaller than the total data, then heapq.heapify() There will be better performance
>>> nums = [4, 5, 6, 8, 2, 5, -5, -48, 0, -31, 51] >>> heap = heapq.heapify(nums) >>> heap = list(nums) >>> heapq.heapify(heap) # The bottom is arranged in stack order >>> heap [-48, -31, -5, 0, 2, 5, 6, 8, 5, 4, 51] >>> heapq.heappop(heap) -48 >>> heapq.heappop(heap) -31 >>> heapq.heappop(heap) -5 >>> heapq.heappop(heap) 0 >>> heapq.heappop(heap) 2 >>> heapq.heappop(heap) 4
5. Map a key to multiple values
-
problem Each key in a dictionary maps multiple values
-
Solution : create defaultdict(list) This dictionary
>>> d = defaultdict(list) >>> d['a'].append(1) >>> d defaultdict(<class 'list'>, {'a': [1]}) >>> d['b'].extend([1,2,3]) >>> d defaultdict(<class 'list'>, {'a': [1], 'b': [1, 2, 3]})
6. Compare dictionary values
-
problem We want to do a variety of operations on data in dictionaries (maximizing, minimizing, sorting, etc.)
-
Solution 1 Reverse to use zip() Speaking about the keys and values of a dictionary
prices = { 'apple': 42.6, 'binana': 42.6, 'piple': 42.6, 'aaa': 42.6, } # 1. Maximum and Minimum min(zip(prices.values(), prices.keys())) max(zip(prices.values(), prices.keys())) # 2. Sort by value sorted(zip(prices.values(), prices.keys()))
Solution II Pass the key parameter to the min and max functions
prices = { 'apple': 42.6, 'binana': 42.6, 'piple': 42.6, 'aaa': 42.6, } # 1. Return key name min(prices, key=lambda k: prices[k]) max(prices, key=lambda k: prices[k])
7. Find the similarities between the two dictionaries
-
problem There are two dictionaries. We want to find out what they have in common (the same keys, values) in the two dictionaries.
-
Solution Dictionary keys() and values() The keys of the dictionary support the operation of the collection.
k1 = { 'x': 10, 'y': 15, 'z': 20, 'b': 80 } k2 = { 'w': 10, 'y': 15, 'z': 30, 'b': 80 } # 1. The same key in two dictionaries k1.keys() & k2.keys() # 2. Items with the same key and value in two dictionaries k1.items() & k2.items() # 3. Filtering certain items in a dictionary {key: k1[key] for key in k1.keys() - {'b', 'z'}} k1 = { 'x': 10, 'y': 15, }
8. Delete duplicates from the sequence and keep the key order of the elements unchanged
-
problem Remove duplicates from the sequence and keep the sequence unchanged
-
Solution 1 By means of set + generator (when elements can be hash, objects of _hash_ can be realized)
def dedupe(items): seen = set() for item in items: if item not in seen: yield item seen.add(item)
-
Solution 2 By means of set + generator (when elements can be hash, objects of _hash_ can be realized)
def dedupe(items, key=None): seen = set() for item in items: val = item if key is None else key(item) # Key step if val not in seen: yield val seen.add(val)
-
Advanced usage: For advanced data types, it can also be de-duplicated
a = [{'a': 1, 'y': 2}, {'a': 1, 'y': 6}, {'a': 1, 'y': 2}, {'a': 1, 'y': 2}] list(dedupe(a, key=lambda d: (d['a'], d['y'])))
9. Naming slices
-
problem There are many hard-coded slices like [0:5, 2], [-4, -3, -1] in the code. It's not easy for us to look back at the code.
-
Solution Naming slices by slice function
s = [1, 2, 3, 4, 5, 6, 7] head = slice(0, 4, 1) s[head] # [1, 2, 3, 4] head.start # 0 head.stop # 4 head.step # 1
-
Expand Use indices to fix a length, and all values must be within a boundary
s = [1, 2, 3, 4, 5, 6, 7] head = slice(0, 5, 2) print(head.indices(len(s))) # (0, 5, 1) for i in range(*head.indices(len(s))): print('Following table', i) print('value', s[i]) """ //Table 0 below //Value 1 //Table 2 below //Value 3 //Table 4 below //Value 5 """
10. Find the most frequent element in the sequence
-
problem There is a sequence of elements to find out what the most frequently occurring elements are.
-
Solution collection.Counter can be easily implemented
-
most_counter() finds the three elements with the highest frequency
from collections import Counter word = ['a', 'a', 'b', 'c', 'c', 'd'] counter = Counter(word) counter.most_common(2) # [('a', 2), ('c', 2)] counter['a'] # Number of Views 2 counter['d'] # Number of Views 1
-
In other uses of Counter, the underlying maintenance of counter is a dictionary.
# 1. Because behind counter, a dictionary is maintained, which is assigned by dictionary. s = ['a', 'b', 'c', 'd', 'a', 'b', 'c'] counter = Counter() for i in s: counter[i] += 1 print(counter) # Counter({'a': 2, 'b': 2, 'c': 2, 'd': 1}) # 2. Mathematical calculation of two counter s a = ['a', 'b', 'c', 'd'] b = ['b', 'c', 'e', 'h'] counter_a = Counter(a) counter_b = Counter(b) counter_a + counter_b # Counter({'a': 1, 'b': 2, 'c': 2, 'd': 1, 'e': 1, 'h': 1})
-
11. Sort dictionary lists by common keys
-
problem Have a list of dictionaries that sort lists according to the values in one or more dictionaries
-
Solution 1 Use operator Medium itemgetter Function to sort
rows = [ {'fname': 'B', 'iname': 'bbb', 'uid': '1006'}, {'fname': 'C', 'iname': 'aaa', 'uid': '1001'}, {'fname': 'D', 'iname': 'ddd', 'uid': '1000'}, {'fname': 'C', 'iname': 'ccc', 'uid': '1002'} ] from operator import itemgetter rows_by_fname = sorted(rows, key=itemgetter('fname')) rows_by_uid = sorted(rows, key=itemgetter('uid')) # Sort by multiple rows rows_by_fname_uid = sorted(rows, key=itemgetter('lname', 'uid')) ...... [{'fname': 'B', 'iname': 'bbb', 'uid': '1006'}, {'fname': 'C', 'iname': 'aaa', 'uid': '1001'}, {'fname': 'C', 'iname': 'ccc', 'uid': '1002'}, {'fname': 'D', 'iname': 'ddd', 'uid': '1000'}] [{'fname': 'D', 'iname': 'ddd', 'uid': '1000'}, {'fname': 'C', 'iname': 'aaa', 'uid': '1001'}, {'fname': 'C', 'iname': 'ccc', 'uid': '1002'}, {'fname': 'B', 'iname': 'bbb', 'uid': '1006'}]
Solution II To use lambda + sorted, the performance is a little slower than above
rows = [ {'fname': 'B', 'iname': 'bbb', 'uid': '1006'}, {'fname': 'C', 'iname': 'aaa', 'uid': '1001'}, {'fname': 'D', 'iname': 'ddd', 'uid': '1000'}, {'fname': 'C', 'iname': 'ccc', 'uid': '1002'} ] from operator import itemgetter rows_by_fname = sorted(rows, key=lambda k: k['fname']) rows_by_uid = sorted(rows, key=lambda k: k['uid']) # Sort by multiple rows rows_by_fname_uid = sorted(rows, key=lambda x:(x['fname'], x['uid'])) ...... [{'fname': 'B', 'iname': 'bbb', 'uid': '1006'}, {'fname': 'C', 'iname': 'aaa', 'uid': '1001'}, {'fname': 'C', 'iname': 'ccc', 'uid': '1002'}, {'fname': 'D', 'iname': 'ddd', 'uid': '1000'}] [{'fname': 'D', 'iname': 'ddd', 'uid': '1000'}, {'fname': 'C', 'iname': 'aaa', 'uid': '1001'}, {'fname': 'C', 'iname': 'ccc', 'uid': '1002'}, {'fname': 'B', 'iname': 'bbb', 'uid': '1006'}]
-
Expand The itemgetter and lambda methods can also be applied to max and min functions.
max(rows, key=lambda k: k['uid']) max(rows, key=itemgetter('uid')) {'fname': 'B', 'iname': 'bbb', 'uid': '1006'}
12. Sort instances by instance attributes
-
problem Ordering multiple instances of a class by instance attributes
-
Solution Using lambda or attrgetter by passing the key value of sorted
from operator import itemgetter class User: def __init__(self, user_id): self.id = user_id def __repr__(self): return 'User ({})'.format(self.id) users = [User(5), User(10), User(8), User(1)] sorted(users, key=lambda u: u.id) sorted(users, key=attrgetter('id')) # [User (1), User (5), User (8), User (10)]
-
Expand The attrgetter and lambda methods can also be applied to max and min functions.
max(users, key=lambda u: u.id) max(users, key=attrgetter('u')) User (10)
13. Grouping records by field
-
Solve There are a series of dictionary or instance objects that are grouped iteratively according to a characteristic field (such as date)
-
Solution 1 Groupby () to group data
rows = [ {'address': '5412 N CLARK', 'date': '07/01/2012'}, {'address': '5254 E CLARK', 'date': '07/01/2012'}, {'address': '5312 N CLARK', 'date': '07/02/2012'}, {'address': '5482 S CLARK', 'date': '07/03/2012'}, {'address': '5484 N CLARK', 'date': '28/02/2012'} ] from itertools import groupby from operator import itemgetter rows.sort(key=itemgetter('date')) # This step must be sorted, otherwise the grouping will go wrong for date, items in groupby(rows, key=itemgetter('date')): print(date) for i in items: print(' '*4, i)
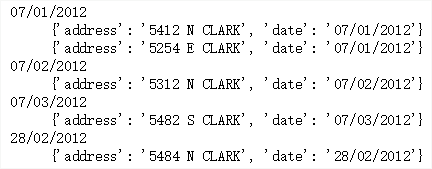
-
Solution II If the data is grouped in a single memory, without considering memory, use collections.defaultdict
from collections import defaultdict rows_by_date = defaultdict(list) for row in rows: rows_by_date[row['date']].append(row) rows_by_date
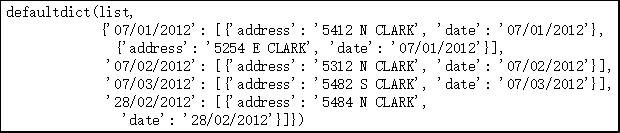
14. Screening the elements in the sequence
-
problem Some of the data in the sequence are what we need, some are unnecessary, and they are filtered according to specific conditions.
-
Solution 1 Use list derivation (where native input is not very large)
>>> my_list = [1, 2, 3, -5, 2, -10, -9, -12, 15] >>> [i for i in my_list if i > 0] [1, 2, 3, 2, 15] >>> [i for i in my_list if i < 0] [-5, -10, -9, -12]
-
Solution II Input data is very large. Generator expressions are used to generate values lazily
>>> res = (i for i in my_list if i < 0) >>> res <generator object <genexpr> at 0x0000023C252D0E08> >>> for i in range(6): ... print(i) ... 0 1 2 3 4 5
-
Solution 3 The screening conditions are too complicated, so the filter() function is used for filtering.
items = [', ', '**6', '-', '125', 'ss5', '12', '-10'] def parse(item): try: if int(item) > 10: return True except Exception: return False list(filter(parse, items)) # ['125', '12']
-
Development Numeric Conversion of Generating ExpressionsList-to-List Push Formulas, Trinomial Operations
# 1. Numeric Conversion >>> s = [1, 2, 5, 4, 6, 1, 3, 7] >>> [i**2 for i in s] [1, 4, 25, 16, 36, 1, 9, 49] # 2. Trinomial operation >>> s = ['1', '2', 'd', 'aa', '6.6', '0.2', '**'] >>> [i if i.isdigit() else None for i in s] ['1', '2', None, None, None, None, None]
-
Development II. Boolean sequence + itertools.compress for filtering, data beyond the Boolean list is not calculated
from itertools import compress data = [ 'aa1', 'aa2', 'aa3', 'aa4', 'aa5', 'aa6', 'aa7', 'aa8', 'aa9', 'aa10' ] s = [1, 2, 5, 4, 6, 1, 3, 7] bool_list = [n > 5 for n in s] # [False, False, False, False, True, False, False, True] list(compress(data, bool_list)) # ['aa5', 'aa8']
-
15. Extract values from a dictionary to create a dictionary
-
problem We need to create a dictionary, which itself is a subset of another dictionary
-
Solution 1 Dictionary Derivation
d = { 'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6 } {key: value for key, value in d.items() if value > 3} # {'d': 4, 'e': 5, 'f': 6} {key: value for key, value in d.items() if key in ['a', 'b', 'c']} # {'a': 1, 'b': 2, 'c': 3}
-
Solution II Mandatory conversion of tuple sequence with dict function, twice faster than the first one!
dict((k, v) for k, v in d.items() if v > 2) # {'c': 3, 'd': 4, 'e': 5, 'f': 6}
-
Solution 3 More esoteric writing than scheme 2. Dictionary value generation is 1.6 times faster than the first one.
key = {'a', 'b', 'c'} {key: d[key] for key in d.keys() & key} # The key is intersected once # {'c': 3, 'b': 2, 'a': 1}
16. Name the value of the tuple
-
problem Our code accesses tuples or lists through the following table, but sometimes it's hard for us to read. We want to access the contents of tuples like attributes of instances.
-
Solution 1 Naming a meta-ancestor with nametuple is a relatively common tuple, which can be achieved by adding a very small amount of space
>>> from collections import namedtuple >>> User = namedtuple('User', ['name', 'gender', 'age']) >>> a = User('a', 'M', 20) >>> a.name 'a' >>> a.age 20
Although he looks like he created a class and did an instantiated operation, he supports all operations of ordinary tuples, such as indexing and decomposition, unpacking, and so on.
nametuple To create named tuples using for loop unpacking data
data = [ ('a', 1, 5), ('b', 6, 3), ('c', 2, 5), ('d', 3, 7), ('e', 4, 8), ] # 1. Without naming tuples, use the following table to get values, and the semantic expression is not clear. def comput_cost(records): total = 0.0 for rec in records: total += rec[1] * rec[2] return total comput_cost(data) # 86.0 # 2. Generate by unpacking using named tuples User = namedtuple('User', ['name', 'data1', 'data2']) def comput_cost(records): total = 0.0 for rec in records: user = User(*rec) total += user.data1 * user.data2 return total # 86.0
-
Expanding Usage Instead of using dictionaries, it takes less memory than using dictionaries. __ slits __() Attribute classes are a little lower
# !!! Alternative dictionary usage created with nametuple requires a built-in _replace() method to modify the value >>> a = User('xyb', 20, 'F') >>> a.age = 21 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: can't set attribute >>> a._replace(age=21) User(name='xyb', age=21, gender='F') # Modified success
-
Expanding Usage II Create default tuples with _replace in conjunction with dictionaries
User = namedtuple('User', ['name', 'age', 'gender', 'number', 'date']) default_user = User('', '', '', None, None) def dict_to_tuple(d): return default_user._replace(**d) d = {'name': 'xyb', 'age': 20} dict_to_tuple(d) # User(name='xyb', age=20, gender='', number=None, date=None)
17. Generator expression as a single parameter of a function
-
problem We need to call a conversion function, but first we need to transform and filter the data.
-
Solutions Use generator expressions in functions
# 1. Columns such as sum functions nums = [1, 2, 3, 4, 5] sum(x * x for x in nums) # 2. any function (returns True as long as one of the elements of the iterable object passed in is True) import os files = os.listdir() if any(name.endswith('.py') for name in files): print('python file') else: print('sorry no python') # 3. Compare the maximum data = [ {'name': 'A', 'age': 64}, {'name': 'B', 'age': 28}, {'name': 'C', 'age': 36}, {'name': 'D', 'age': 15}, ] min(item['age'] for item in data) # 4. Output CSV s = ['i', 'love', 'a', 'girl'] print(','.join(item) for item in s)
-
Analysis Why can generator expressions be directly used as parameters of functions
>>> nums = [1, 2, 3, 4, 5, 6] >>> s = sum(x * x for x in nums) >>> s 91 >>> s = sum((x * x for x in nums)) >>> s 91 # Whether there is () effect is the same.
-
master Replacement of key in function by generator expression
data = { 'a': 20, 'b': 25, 'c': 15, 'd': 30 } min(data[item] for item in data) min(data, key=lambda k: data[k])
18. Combine multiple dictionaries into a single dictionary
-
problem There are multiple dictionaries or maps that logically merge them into a separate structure to perform certain operations, such as finding keys, and whether values exist
-
Solution Using collections.ChainMap to link the two dictionaries from the bottom
a = {'a': 1, 'b': 1} b = {'c': 1, 'b': 2} from collections import ChainMap c = ChainMap(a, b) len(c) list(c.keys()) # ['b', 'c', 'a'] list(c.values()) # [1, 1, 1]
-
If two dictionaries have the same key, the value depends on the key of the first dictionary.
-
If you want to delete the key-value pairs in the combined dictionary, you can only remove the first mapping or dictionary.
del c['a'] # √ del c['c'] # ×
-