We previously discussed convolution neural networks, which extract features from local regions and are very effective for image recognition processing of kittens and dogs. We also discussed cyclic neural networks for text processing because the order of text is sequential.Based on the above characteristics, we consider time or the front and back of text as a dimension. That text is a one-dimensional space, which is simpler than the two-dimensional space of pictures. Can convolution neural network handle this situation?
First come to the conclusion, the answer is yes.Pictures are two-dimensional data and text is one-dimensional data, so we can simplify the training neural network to extract one-dimensional features.In this case, one-dimensional network is similar to two-dimensional network, so we can migrate the characteristics of two-dimensional convolution network to one-dimensional convolution network.
When discussing neural networks, we know that convolution networks have the same translation invariance, which is a very good feature that can grasp the key to the problem and identify special features.In one-dimensional convolution neural network (Conv1D), a small piece of text has the characteristics that can be recognized elsewhere in the text after learning.It can be understood that when a sentence is said at the beginning and at the end, the feelings expressed should be the same and the effect is the same (in most cases), which is the translation invariance of the text.
Similarly, when processing pictures, we need to pool in order to prevent too much data and fitting. In one-dimensional neural networks, we also need to pool (MaxPooling1D).
When it comes to this, we're finished with the main idea. It's easy. Let's take an example. We'll also use the IMDB commentary sentiment analysis dataset we used before to see how it works, the old rules, the results, and finally give the full code:
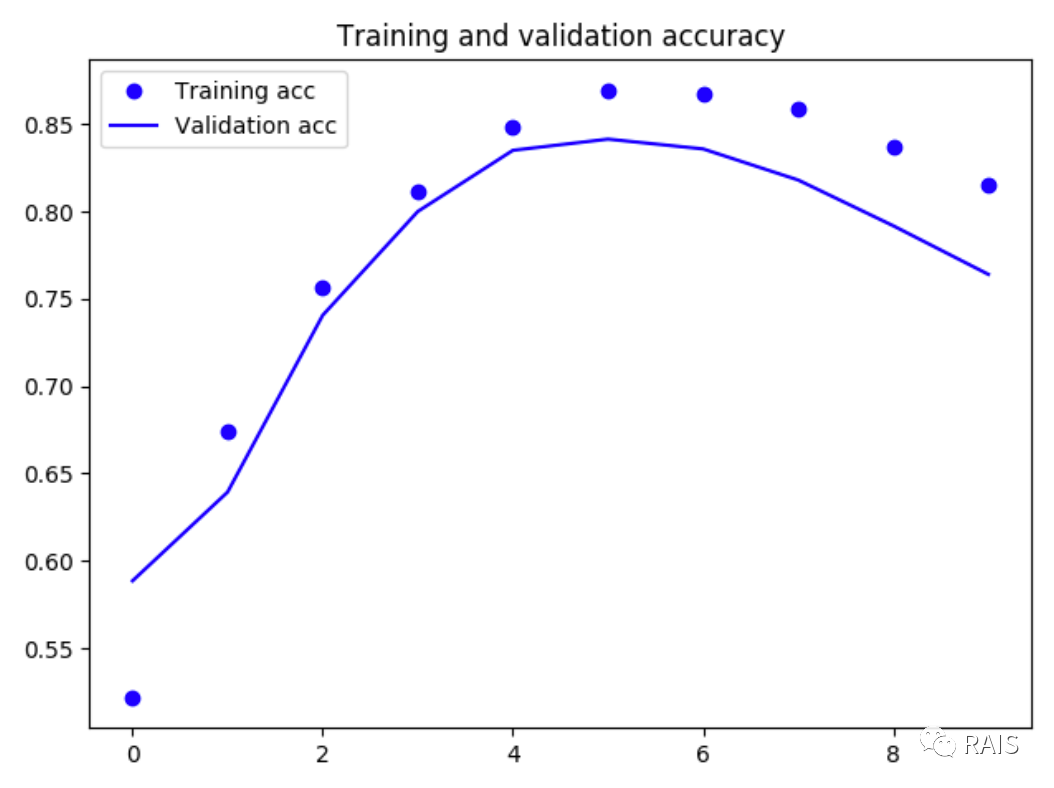
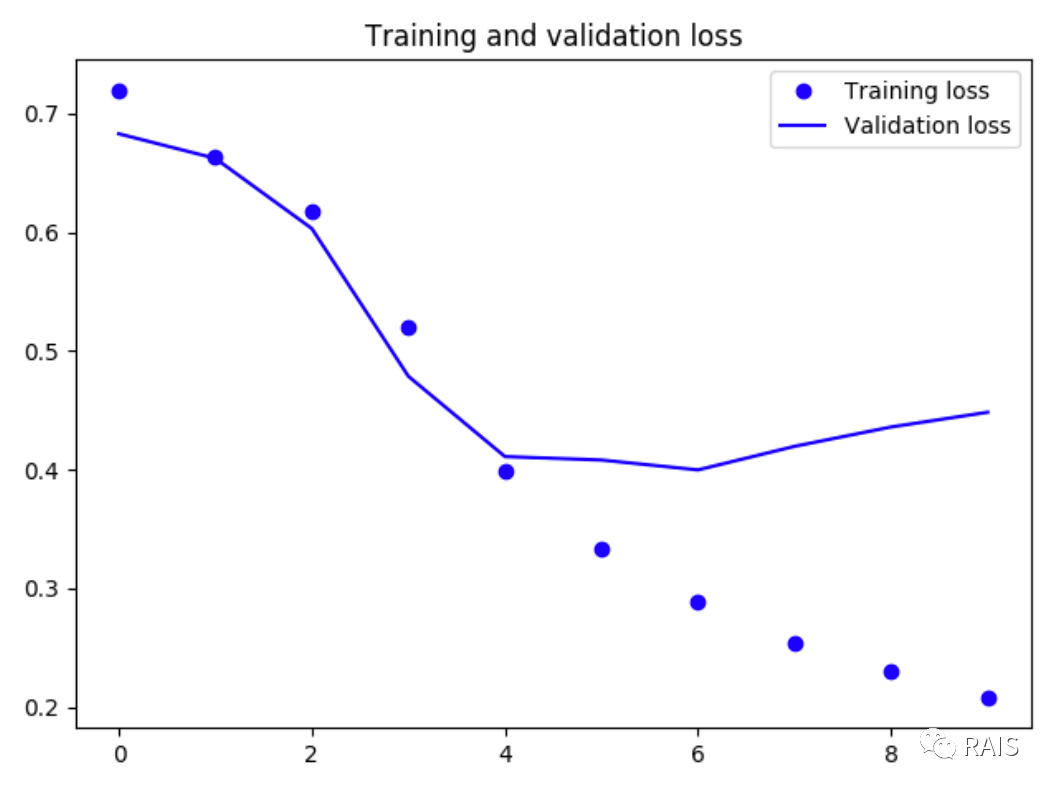
I don't know if you've practiced all of my previous codes. If you have, you probably know that some of the recent looping neural networks take more than an hour to execute (the previous LSTM), which is really too slow. This is a drawback of the looping neural network.This network is finished in a few minutes, and we see that it has been fitted since the fourth time or so, so it only needs to be trained four times, and we find that the accuracy of LSTM decreases by a very small amount and is within acceptable range, so this network has its unique superiority.Looking at the code below, notice that there is something very important behind it.
#!/usr/bin/env python3 import time import matplotlib.pyplot as plt from keras import layers from keras.datasets import imdb from keras.models import Sequential from keras.optimizers import RMSprop from keras.preprocessing import sequence def imdb_run(): max_features = 10000 max_len = 500 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features) x_train = sequence.pad_sequences(x_train, maxlen=max_len) x_test = sequence.pad_sequences(x_test, maxlen=max_len) model = Sequential() model.add(layers.Embedding(max_features, 128, input_length=max_len)) model.add(layers.Conv1D(32, 7, activation='relu')) model.add(layers.MaxPooling1D(5)) model.add(layers.Conv1D(32, 7, activation='relu')) model.add(layers.GlobalMaxPooling1D()) model.add(layers.Dense(1)) model.summary() model.compile(optimizer=RMSprop(lr=1e-4), loss='binary_crossentropy', metrics=['acc']) history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2) # Drawing acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(loss) + 1) plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.legend() plt.show() plt.figure() plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.legend() plt.show() if __name__ == "__main__": time_start = time.time() imdb_run() time_end = time.time() print('Time Used: ', time_end - time_start)
We know that convolution neural networks are used to extract features, and precisely to extract local features. Therefore, for this kind of text sequence, it is possible to extract the features of a small sequence without too long a range. This is a limitation of the convolution neural network. The advantage of cyclic neural network is that it can obtain the correlation in a longer range. How to combine the advantages of the two, you canLink them up over a longer range, and have a better training speed?
Yes, it's a big trick to combine the two. First, extract the features using a one-dimensional convolution neural network, and then associate the extracted features back and forth using a circular neural network. This can reduce the amount of data, but also take into account the before and after connections. Very advanced usage.
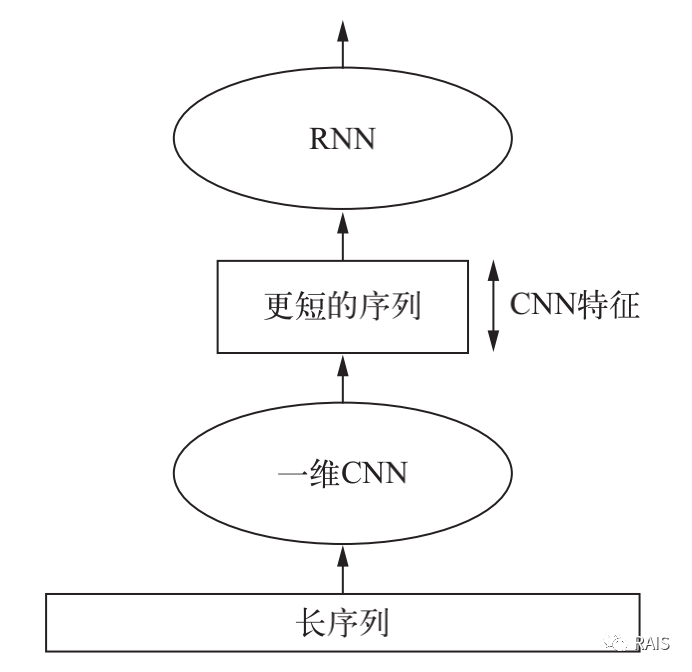
The network structure is similar to this:
model = Sequential() model.add(layers.Conv1D(32, 5, activation='relu',input_shape=(None, float_data.shape[-1]))) model.add(layers.MaxPooling1D(3)) model.add(layers.Conv1D(32, 5, activation='relu')) model.add(layers.GRU(32, dropout=0.1, recurrent_dropout=0.5)) model.add(layers.Dense(1))
The problem discussed in this paper is to use the one-dimensional convolution neural network for text sequence processing. At this point, text processing will be a short paragraph, and the following articles will discuss some other issues.
- This article was first published on WeChat Public Number: RAIS