MHA (Master High Availability) is currently a relatively mature solution for MySQL high availability. It was developed by youshimaton (now working for Facebook) of DeNA Company in Japan. It is an excellent high availability software for failover and master-slave upgrading in MySQL high availability environment. In the process of MySQL fault switching, MHA can automatically complete the database fault switching operation within 0-30 seconds, and in the process of fault switching, MHA can ensure the consistency of data to the greatest extent, in order to achieve high availability in the true sense.
The software consists of two parts: MHA Manager (Management Node) and MHA Node (Data Node).
MHA Node runs on each MySQL server, and MHA Manager detects the master node in the cluster regularly. When the master fails, it can automatically upgrade the slave of the latest data to the new master, and then redirect all other slaves to the new master. The whole failover process is completely transparent to the application.
Experimental environment

10.192.203.201, 10.192.203.101 with keepalive installed, VIP 108
Experimental steps
1 Modify / etc/hosts
Add these server ip and host name correspondences to the server where the mha management node and data node are located.
Such as:
cat /etc/hosts
10.192.203.201 pc2
10.192.203.101 slave1
10.192.203.102 PC
2 Mysql master-slave replication environment
The construction process is simple and can be referred to as follows: http://blog.csdn.net/yabingshi_tech/article/details/45192599.
Make sure that two slave libraries set read_only.
Make sure that master and alternate master are primary and alternate modes, otherwise errors may occur in the subsequent configuration process.
Configure host trust relationship
Generate password files at all nodes and then copy them to local computers and other servers. Take 10.192.203.201 as an example:
# ssh-keygen
# ssh-copy-id root@10.192.203.201
# ssh-copy-id root@10.192.203.101
# ssh-copy-id root@10.192.203.102
Then ssh verifies whether password-free login is possible.
4 install MHA
Click here to download:
http://download.csdn.net/download/yabignshi/8974251
http://download.csdn.net/detail/yabignshi/8974265
Install on all data nodes:
yum install perl-DBD-MySQL -y
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
When the installation is completed, the following script files are generated in the / usr/bin directory (these tools are usually triggered by MHA Manager scripts without human manipulation):
save_binary_logs // Save and copy master's binary logs
apply_diff_relay_logs // / Recognize differences in relay log events and apply their differences to other slave s
filter_mysqlbinlog// Remove unnecessary ROLLBACK events (MHA no longer uses this tool)
purge_relay_logs // / Clear relay logs (no blocking of SQL threads)
Install on the management node:
yum install perl-DBD-MySQL-y (since the experimental environment management node and data node are deployed on the same server, there is no need to re-install here)
yum install perl-Config-Tiny -y
yum install epel-release -y
yum install perl-Log-Dispatch -y
yum install perl-Parallel-ForkManager -y
Rpm-ivh mha4mysql-node-0.56-0.el6.noarch.rpm (because the experimental environment management node and data node are deployed on the same server, so there is no need to re-install here)
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
After installation, the following script files will be generated in the / usr/bin directory:
-rwxr-xr-x. 1 root root 1995 Apr 1 2014 masterha_check_repl -rwxr-xr-x. 1 root root 1779 Apr 1 2014 masterha_check_ssh -rwxr-xr-x. 1 root root 1865 Apr 1 2014 masterha_check_status -rwxr-xr-x. 1 root root 3201 Apr 1 2014 masterha_conf_host -rwxr-xr-x. 1 root root 2517 Apr 1 2014 masterha_manager -rwxr-xr-x. 1 root root 2165 Apr 1 2014 masterha_master_monitor -rwxr-xr-x. 1 root root 2373 Apr 1 2014 masterha_master_switch -rwxr-xr-x. 1 root root 5171 Apr 1 2014 masterha_secondary_check -rwxr-xr-x. 1 root root 1739 Apr 1 2014 masterha_stop -rwxr-xr-x. 1 root root 4807 Apr 1 2014 filter_mysqlbinlog -rwxr-xr-x. 1 root root 7525 Apr 1 2014 save_binary_logs -rwxr-xr-x. 1 root root 8261 Apr 1 2014 purge_relay_logs -rwxr-xr-x. 1 root root 16367 Apr 1 2014 apply_diff_relay_logs
5 Installation configuration keepalive
5.1 Install keepalive
Install keepalive on master and alternate master:
yum install -y popt-devel cd /usr/local/src wgethttp://www.keepalived.org/software/keepalived-1.2.2.tar.gz tar zxvf keepalived-1.2.2.tar.gz cd keepalived-1.2.2 ./configure --prefix=/ make make install
5.2 Modify configuration file
vi/etc/keepalived/keepalived.conf
The contents of master and alternate master configuration files are the same.
#ConfigurationFile for keepalived
global_defs {
notification_email { ######Define the mailbox to receive mail
wangjj@hrloo.com
}
notification_email_from jiankong@staff.tuge.com ######Define the mailbox to send mail
smtp_server mail.tuge.com
smtp_connect_timeout 10
}
vrrp_instance vrrptest { ######Define vrrptest instance
state BACKUP ######Server status
interface eth0 ######Used interfaces
virtual_router_id 51 ######Virtual routing flags, a set of lvs virtual routing flags must be the same in order to switch
priority 150 ######Service startup priority, the higher the value and priority, BACKUP can not be greater than MASTER
advert_int 1 ######Survival check time between servers
authentication {
auth_type PASS ######Authentication type
auth_pass ufsoft ######Authentication passwords, a set of lvs server authentication passwords must be consistent
}
virtual_ipaddress { ######Virtual IP Address
10.192.203.108
}
}Here the master server state is not configured as MASTER, and the priority of the configuration is the same. It is expected that when the master is down and restored, it will not take the initiative to grab the MASTER state to avoid the fluctuation of MySQL service.
vrrp_script is not configured here, which will allow mha to drift vip automatically later.
5.3 vi /etc/sysconfig/iptables
# Note that both machines need to be modified.
Add to:
-A INPUT-d 10.192.203.108/32 -j ACCEPT
- A INPUT-d 224.0.0.18-j ACCEPT# A D D VRRP Communication Support
Note: 10.192.203.108 in the first line needs to be changed to your own vip.
serviceiptables restart
5.4 Start keepalive
service keepalived start
Execute the ip addr command separately, and you can see the virtual IP on one of the machines
5.5 test
Stop the master server keepalived and check whether VIP is switched to the alternate master server (using ip) The addr command is validated.
6 configure Mha
6.1 Added Management Account
# Perform the following actions on the data node
grant all privileges on *.* TO mha@'10.192.%' IDENTIFIED BY 'test';
flush privileges;
6.2 Configuration/etc/mha/app1.cnf
# Only on the management side
mkdir /etc/mha
mkdir -p /var/log/mha/app1
vi /etc/mha/app1.cnf
Add to:
[server default] manager_log=/var/log/mha/app1/manager.log manager_workdir=/var/log/mha/app1.log master_binlog_dir=/data/mysql/data master_ip_failover_script= /usr/bin/master_ip_failover master_ip_online_change_script=/usr/bin/master_ip_online_change report_script=/usr/bin/send_report user=mha password=test ping_interval=2 repl_password=beijing repl_user=rep_user ssh_user=root [server1] hostname=10.192.203.201 port=3306 [server2] candidate_master=1 check_repl_delay=0 hostname=10.192.203.101 port=3306 [server3] hostname=10.192.203.102 port=3306
Configuration in server default is the common configuration of three data nodes. It can also be customized in a specific server.
/*
Interpretation of parameter concepts:
master_binlog_dir=/data/mysql/data# Sets the location where the master saves the binlog so that MHA can find the master's log
master_ip_failover_script=/usr/bin/master_ip_failover= Sets the handover script when automatic failover occurs
master_ip_online_change_script=/usr/bin/master_ip_online_change# Sets the handover script for manual handover
report_script=/usr/bin/send_report * * * * // Sets the script for alerting when a switch occurs
ping_interval=2 # Sets up the monitor main library, and the time interval for sending ping packets is 3 seconds by default. failover automatically occurs when three attempts are not answered.
Candidate master = 1 # is set as candidate master. If this parameter is set, the slave library will be promoted to the master library after master-slave switching occurs, even if the master library is not the latest slave of events in the cluster.
By default, if a slave lags behind relay logs of master 100M, MHA will not choose the slave as a new master because it takes a long time to recover the slave. By setting check_repl_delay=0, the MHA trigger switch will ignore the replication delay when selecting a new master. This parameter sets candidate for the recovery of the slave._ The master = 1 host is very useful because the candidate master must be a new master in the process of switching.
*/
6.3 master_ip_failover script code
To introduce the keepalived service into MHA, we only need to modify the script file master_ip_failover, which triggers the switch. In this script, we add the handling of the keepalived service when the Master goes down.
In the management node edit script / usr/bin/master_ip_failover, the modification is as follows:
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '10.192.203.108';
my $ssh_start_vip ="/etc/init.d/keepalived start";
my $ssh_stop_vip ="/etc/init.d/keepalived stop";
GetOptions(
'command=s' =>\$command,
'ssh_user=s' =>\$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' =>\$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' =>\$new_master_host,
'new_master_ip=s' =>\$new_master_ip,
'new_master_port=i' =>\$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPTTEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIPon the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status--orig_master_host=host --orig_master_ip=ip --orig_master_port=port--new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}Note: my $vip = 10.192.203.108'; VIP in this line should be changed to its own virtual IP according to the situation.
chmod +x /usr/bin/master_ip_failover
6.4 master_ip_online_change script code
Edit script / usr/bin/master_ip_online_change at management node
#!/usr/bin/env perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# itunder the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is notcomplete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
use MHA::NodeUtil;
use Time::HiRes qw( sleep gettimeofdaytv_interval );
use Data::Dumper;
my $_tstart;
my $_running_interval = 0.1;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $orig_master_ssh_user, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password, $new_master_ssh_user
);
my $vip = '10.192.203.108/32';
my $key = '1';
my $ssh_start_vip = "/etc/init.d/keepalivedstart";
my $ssh_stop_vip = "/etc/init.d/keepalivedstop";
my $orig_master_ssh_port = 22;
my $new_master_ssh_port = 22;
GetOptions(
'command=s' =>\$command,
'orig_master_is_new_slave' => \$orig_master_is_new_slave,
'orig_master_host=s' =>\$orig_master_host,
'orig_master_ip=s' =>\$orig_master_ip,
'orig_master_port=i' =>\$orig_master_port,
'orig_master_user=s' =>\$orig_master_user,
'orig_master_password=s' =>\$orig_master_password,
'orig_master_ssh_user=s' =>\$orig_master_ssh_user,
'new_master_host=s' =>\$new_master_host,
'new_master_ip=s' =>\$new_master_ip,
'new_master_port=i' =>\$new_master_port,
'new_master_user=s' =>\$new_master_user,
'new_master_password=s' =>\$new_master_password,
'new_master_ssh_user=s' =>\$new_master_ssh_user,
'orig_master_ssh_port=i' =>\$orig_master_ssh_port,
'new_master_ssh_port=i' =>\$new_master_ssh_port,
);
exit &main();
sub current_time_us {
my( $sec, $microsec ) = gettimeofday();
my$curdate = localtime($sec);
return $curdate . " " . sprintf( "%06d", $microsec);
}
sub sleep_until {
my$elapsed = tv_interval($_tstart);
if( $_running_interval > $elapsed ) {
sleep( $_running_interval - $elapsed );
}
}
sub get_threads_util {
my$dbh = shift;
my$my_connection_id = shift;
my$running_time_threshold = shift;
my$type = shift;
$running_time_threshold = 0 unless ($running_time_threshold);
$type = 0 unless($type);
my@threads;
my$sth = $dbh->prepare("SHOW PROCESSLIST");
$sth->execute();
while ( my $ref = $sth->fetchrow_hashref() ) {
my $id = $ref->{Id};
my $user = $ref->{User};
my $host = $ref->{Host};
my $command =$ref->{Command};
my $state = $ref->{State};
my $query_time = $ref->{Time};
my $info = $ref->{Info};
$info =~ s/^\s*(.*?)\s*$/$1/ if defined($info);
next if ( $my_connection_id == $id );
next if ( defined($query_time) && $query_time <$running_time_threshold );
next if ( defined($command) && $command eq "Binlog Dump" );
next if ( defined($user) && $user eq "system user" );
next
if ( defined($command)
&& $command eq "Sleep"
&& defined($query_time)
&& $query_time >= 1 );
if ( $type >= 1 ) {
next if ( defined($command) && $command eq "Sleep" );
next if ( defined($command) && $command eq "Connect");
}
if ( $type >= 2 ) {
next if ( defined($info) && $info =~ m/^select/i );
next if ( defined($info) && $info =~ m/^show/i );
}
push @threads, $ref;
}
return @threads;
}
sub main {
if( $command eq "stop" ) {
## Gracefully killing connections on the current master
#1. Set read_only= 1 on the new master
#2. DROP USER so that no app user can establish new connections
#3. Set read_only= 1 on the current master
#4. Kill current queries
#* Any database access failure will result in script die.
my $exit_code = 1;
eval {
## Setting read_only=1 on the new master (to avoid accident)
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error(die_on_error)_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
print current_time_us() . " Set read_only on the new master..";
$new_master_handler->enable_read_only();
if ( $new_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
$new_master_handler->disconnect();
# Connecting to the orig master, die if any database error happens
my $orig_master_handler = new MHA::DBHelper();
$orig_master_handler->connect( $orig_master_ip, $orig_master_port,
$orig_master_user, $orig_master_password, 1 );
## Drop application user so that nobody can connect. Disablingper-session binlog beforehand
$orig_master_handler->disable_log_bin_local();
print current_time_us() . " Drpping appuser on the orig master..\n";
#FIXME_xxx_drop_app_user($orig_master_handler);
## Waiting for N * 100 milliseconds so that current connections can exit
my $time_until_read_only = 15;
$_tstart = [gettimeofday];
my @threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_read_only > 0 && $#threads >= 0 ) {
if ( $time_until_read_only % 5 == 0 ) {
printf
"%s Waiting all running %d threads aredisconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_read_only * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump ."\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_read_only--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Setting read_only=1 on the current master so that nobody(exceptSUPER) can write
print current_time_us() . " Set read_only=1 on the orig master..";
$orig_master_handler->enable_read_only();
if ( $orig_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
## Waiting for M * 100 milliseconds so that current update queries cancomplete
my $time_until_kill_threads = 5;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_kill_threads > 0 && $#threads >= 0 ) {
if ( $time_until_kill_threads % 5 == 0 ) {
printf
"%s Waiting all running %d queries aredisconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_kill_threads * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump ."\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_kill_threads--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Terminating all threads
print current_time_us() . " Killing all applicationthreads..\n";
$orig_master_handler->kill_threads(@threads) if ( $#threads >= 0);
print current_time_us() . " done.\n";
$orig_master_handler->enable_log_bin_local();
$orig_master_handler->disconnect();
## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK
eval {
`ssh -p$orig_master_ssh_port $orig_master_ssh_user\@$orig_master_host\" $ssh_stop_vip \"`;
};
if ($@) {
warn $@;
}
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
## Activating master ip on the new master
#1. Create app user with write privileges
#2. Moving backup script if needed
#3. Register new master's ip to the catalog database
# We don't return error even thoughactivating updatable accounts/ip failed so that we don't interrupt slaves'recovery.
# If exit code is 0 or 10, MHA does notabort
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
$new_master_handler->disable_log_bin_local();
print current_time_us() . " Setread_only=0 on the new master.\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
print current_time_us() . " Creating app user on the newmaster..\n";
#FIXME_xxx_create_app_user($new_master_handler);
$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
`ssh -p$new_master_ssh_port $new_master_ssh_user\@$new_master_host\" $ssh_start_vip \"`;
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
#do nothing
exit 0;
}
else {
&usage();
exit 1;
}
}
sub usage {
print
"Usage: master_ip_online_change--command=start|stop|status --orig_master_host=host --orig_master_ip=ip--orig_master_port=port --new_master_host=host --new_master_ip=ip--new_master_port=port\n";
die;
}Note: You need to change my $vip = 10.192.203.108/32'; to your own vip.
chmod +x /usr/bin/master_ip_online_change
6.5 send_report script code
Edit script / usr/bin/send_report at the management node
#!/usr/bin/perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# itunder the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is notcomplete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Mail::Sender;
use Getopt::Long;
#new_master_host and new_slave_hosts areset only when recovering master succeeded
my ( $dead_master_host, $new_master_host, $new_slave_hosts,$subject, $body );
my $smtp='smtp.163.com';
my $mail_from='xxxxxxx@163.com';
my $mail_user='xxxxxxx@163.com';
my $mail_pass='Password';
my$mail_to=['949538827@qq.com','15521xxxx@139.com'];
GetOptions(
'orig_master_host=s' => \$dead_master_host,
'new_master_host=s' =>\$new_master_host,
'new_slave_hosts=s' =>\$new_slave_hosts,
'subject=s' =>\$subject,
'body=s' => \$body,
);
mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body);
sub mailToContacts {
my ( $smtp, $mail_from, $user, $passwd, $mail_to, $subject, $msg ) = @_;
open my $DEBUG, "> /tmp/monitormail.log"
or die "Can't open the debug file:$!\n";
my $sender = new Mail::Sender {
ctype => 'text/plain;charset=utf-8',
encoding => 'utf-8',
smtp => $smtp,
from => $mail_from,
auth => 'LOGIN',
TLS_allowed => '0',
authid => $user,
authpwd => $passwd,
to => $mail_to,
subject => $subject,
debug => $DEBUG
};
$sender->MailMsg(
{ msg => $msg,
debug => $DEBUG
}
)or print $Mail::Sender::Error;
return 1;
}
# Do whatever you want here
exit 0;
//Note: The following lines need to be modified:
my $smtp='smtp.163.com';
my $mail_from='xxxxxxx@163.com';
my $mail_user='xxxxxxx@163.com';
my $mail_pass='Password';
my$mail_to=['949538827@qq.com','15521xxxx@139.com'];# f Gives Execution Authority
chmod +x /usr/bin/send_report
Note: It is necessary to ensure that the management node server can send mail normally. You can try it first with the sendEmail command.
6.6 Set the way relay log s are cleared (on each slave node)
Make sure that relay_log_purge=0 from the server configuration file, otherwise warning will be missed when masterha_check_repl, relay_log_purge=0 is not set on slave
When the master library is switched to a slave Library in the future, remember to perform the same operation on the original master library.
In the process of switching, MHA relies on relay log information in the recovery process from the library, so the automatic clearance of relay log is set to OFF, and relay log is cleared manually.
By default, the relay log from the server is automatically deleted after the execution of the SQL thread.
However, in MHA environment, these relay logs may be used to recover other slave servers, so automatic deletion of relay logs needs to be disabled.
Regular removal of relay logs requires consideration of replication latency. Under ext3 filesystem, deleting large files takes a certain amount of time, which can lead to serious replication delay.
In order to avoid replication delay, it is necessary to temporarily create hard links for relay logs, because deleting large files through hard links in linux systems can be very fast.
(In mysql databases, hard links are often used to delete large tables)
7 Check if mha manage ment is successfully configured?
7.1 Check ssh login
[root@pc2.ssh]# masterha_check_ssh--conf=/etc/mha/app1.cnf Mon Feb 13 15:35:25 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping. Mon Feb 13 15:35:25 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf.. Mon Feb 13 15:35:25 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf.. Mon Feb 13 15:35:25 2017 - [info] StartingSSH connection tests.. Mon Feb 13 15:35:26 2017 - [debug] Mon Feb 13 15:35:25 2017 - [debug] Connecting via SSH fromroot@10.192.203.201(10.192.203.201:22) toroot@10.192.203.101(10.192.203.101:22).. Mon Feb 13 15:35:25 2017 - [debug] ok. Mon Feb 13 15:35:25 2017 - [debug] Connecting via SSH fromroot@10.192.203.201(10.192.203.201:22) toroot@10.192.203.102(10.192.203.102:22).. Mon Feb 13 15:35:26 2017 - [debug] ok. Mon Feb 13 15:35:26 2017 - [debug] Mon Feb 13 15:35:25 2017 - [debug] Connecting via SSH fromroot@10.192.203.101(10.192.203.101:22) toroot@10.192.203.201(10.192.203.201:22).. Mon Feb 13 15:35:25 2017 - [debug] ok. Mon Feb 13 15:35:25 2017 - [debug] Connecting via SSH fromroot@10.192.203.101(10.192.203.101:22) toroot@10.192.203.102(10.192.203.102:22).. Mon Feb 13 15:35:26 2017 - [debug] ok. Mon Feb 13 15:35:27 2017 - [debug] Mon Feb 13 15:35:26 2017 - [debug] Connecting via SSH fromroot@10.192.203.102(10.192.203.102:22) toroot@10.192.203.201(10.192.203.201:22).. Mon Feb 13 15:35:26 2017 - [debug] ok. Mon Feb 13 15:35:26 2017 - [debug] Connecting via SSH fromroot@10.192.203.102(10.192.203.102:22) toroot@10.192.203.101(10.192.203.101:22).. Mon Feb 13 15:35:27 2017 - [debug] ok. Mon Feb 13 15:35:27 2017 - [info] All SSHconnection tests passed successfully.
If SSH can log on to several other servers without password, it will report an error when checking ssh:
[root@PC .ssh]# masterha_check_ssh--conf=/etc/mha/app1.cnf Fri Feb 10 10:04:35 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping. Fri Feb 10 10:04:35 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf.. Fri Feb 10 10:04:35 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf.. Fri Feb 10 10:04:35 2017 - [info] StartingSSH connection tests.. Fri Feb 10 10:04:36 2017 -[error][/usr/share/perl5/vendor_perl/MHA/SSHCheck.pm, ln63] Fri Feb 10 10:04:35 2017 - [debug] Connecting via SSH fromroot@10.192.203.201(10.192.203.201:22) toroot@10.192.203.101(10.192.203.101:22).. Warning: Permanently added '10.192.203.201'(RSA) to the list of known hosts. Permission denied(publickey,gssapi-keyex,gssapi-with-mic,password). Fri Feb 10 10:04:35 2017 -[error][/usr/share/perl5/vendor_perl/MHA/SSHCheck.pm, ln111] SSH connectionfrom root@10.192.203.201(10.192.203.201:22) toroot@10.192.203.101(10.192.203.101:22) failed! Fri Feb 10 10:04:37 2017 - [debug] Fri Feb 10 10:04:36 2017 - [debug] Connecting via SSH fromroot@10.192.203.101(10.192.203.101:22) toroot@10.192.203.201(10.192.203.201:22).. Fri Feb 10 10:04:36 2017 - [debug] ok. Fri Feb 10 10:04:36 2017 - [debug] Connecting via SSH fromroot@10.192.203.101(10.192.203.101:22) toroot@10.192.203.102(10.192.203.102:22).. Fri Feb 10 10:04:37 2017 - [debug] ok. Fri Feb 10 10:04:38 2017 - [debug] Fri Feb 10 10:04:36 2017 - [debug] Connecting via SSH fromroot@10.192.203.102(10.192.203.102:22) toroot@10.192.203.201(10.192.203.201:22).. Fri Feb 10 10:04:37 2017 - [debug] ok. Fri Feb 10 10:04:37 2017 - [debug] Connecting via SSH fromroot@10.192.203.102(10.192.203.102:22) to root@10.192.203.101(10.192.203.101:22).. Fri Feb 10 10:04:38 2017 - [debug] ok. SSH Configuration Check Failed! at/usr/bin/masterha_check_ssh line 44
Need to check:
(1) Whether the/etc/hosts file is configured correctly;
(2) Is the password file ssh-copy-id on its own server?
If you encounter this error, correct it, empty the contents under. ssh, and then re-authenticate.
7.2 Check whether mysql replication has been successfully configured
[root@pc2 app1]# masterha_check_repl--conf=/etc/mha/app1.cnf
Fri Feb 10 11:25:05 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping. Fri Feb 10 11:25:05 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf.. Fri Feb 10 11:25:05 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf.. Fri Feb 10 11:25:05 2017 - [info]MHA::MasterMonitor version 0.56. Fri Feb 10 11:25:06 2017 -[error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln193] There is noalive slave. We can't do failover Fri Feb 10 11:25:06 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln424] Errorhappened on checking configurations. at/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm line 326 Fri Feb 10 11:25:06 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln523] Errorhappened on monitoring servers. Fri Feb 10 11:25:06 2017 - [info] Got exitcode 1 (Not master dead). MySQL Replication Health is NOT OK!
Clearly, I checked the replication status is normal, why can't it pass?
Solution:
You need to ensure that master and alternate master are set to double master replication. Let master also point to the alternate master.
Verify again if an error is reported:
[root@pc2 mysql]# masterha_check_repl --conf=/etc/mha/app1.cnf
Mon Feb 13 17:21:52 2017 - [info] Connecting toroot@10.192.203.101(10.192.203.101:22)..
Checking slave recovery environment settings..
Opening /data/mysql/relay-log.info ... ok.
Relay log found at /data/mysql, up to slave1-relay-bin.000011
Temporary relay log file is /data/mysql/slave1-relay-bin.000011
Testing mysql connection and privileges..ERROR 1045 (28000): Accessdenied for user 'mha'@'slave1' (using password: YES)
mysql command failed with rc 1:0!
at/usr/bin/apply_diff_relay_logs line 375
main::check()called at /usr/bin/apply_diff_relay_logs line 497
eval{...} called at /usr/bin/apply_diff_relay_logs line 475
main::main()called at /usr/bin/apply_diff_relay_logs line 120
Mon Feb 13 17:21:53 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln205] Slavessettings check failed!
Mon Feb 13 17:21:53 2017 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm,ln413] Slave configuration failed.
Mon Feb 13 17:21:53 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln424] Errorhappened on checking configurations. at/usr/bin/masterha_check_repl line 48
Mon Feb 13 17:21:53 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln523] Errorhappened on monitoring servers.
Mon Feb 13 17:21:53 2017 - [info] Got exitcode 1 (Not master dead).
MySQL Replication Health is NOT OK!Solution:
Create users on slave1:
mysql> grant ALL PRIVILEGES ON *.* TO 'mha'@'slave1'identified by 'test';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
Similarly, create users on PC s:
mysql> grant ALL PRIVILEGES ON *.* TO 'mha'@'PC' identifiedby 'test';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
When re-validating, if an error is reported:
Can't exec "mysqlbinlog": No suchfile or directory at /usr/share/perl5/vendor_perl/MHA/BinlogManager.pm line106.
mysqlbinlog version command failed with rc1:0, please verify PATH, LD_LIBRARY_PATH, and client options
Solution:
Create a soft connection on all data nodes:
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
Verify again and report an error:
Testing mysql connection andprivileges..sh: mysql: command not found
mysql command failed with rc 127:0!
Solution:
Establish soft connections on all data nodes:
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
Finally, everything is normal:
[root@pc2 mysql]# masterha_check_repl --conf=/etc/mha/app1.cnf
Mon Feb 13 17:32:49 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping.
Mon Feb 13 17:32:49 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf..
Mon Feb 13 17:32:49 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf..
Mon Feb 13 17:32:49 2017 - [info]MHA::MasterMonitor version 0.56.
Mon Feb 13 17:32:49 2017 - [info]Multi-master configuration is detected. Current primary(writable) master is10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] Masterconfigurations are as below:
Master 10.192.203.101(10.192.203.101:3306),replicating from 10.192.203.201(10.192.203.201:3306), read-only
Master 10.192.203.201(10.192.203.201:3306),replicating from 10.192.203.101(10.192.203.101:3306)
Mon Feb 13 17:32:49 2017 - [info] GTID failovermode = 0
Mon Feb 13 17:32:49 2017 - [info] DeadServers:
Mon Feb 13 17:32:49 2017 - [info] AliveServers:
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.101(10.192.203.101:3306)
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.102(10.192.203.102:3306)
Mon Feb 13 17:32:49 2017 - [info] AliveSlaves:
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.101(10.192.203.101:3306) Version=5.5.19-log (oldest major versionbetween slaves) log-bin:enabled
Mon Feb 13 17:32:49 2017 - [info] Replicating from10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] Primary candidate for the new Master(candidate_master is set)
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.102(10.192.203.102:3306) Version=5.5.19-log (oldest major versionbetween slaves) log-bin:enabled
Mon Feb 13 17:32:49 2017 - [info] Replicating from10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] CurrentAlive Master: 10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] Checkingslave configurations..
Mon Feb 13 17:32:49 2017 - [info] Checkingreplication filtering settings..
Mon Feb 13 17:32:49 2017 - [info] binlog_do_db= , binlog_ignore_db=
Mon Feb 13 17:32:49 2017 - [info] Replication filtering check ok.
Mon Feb 13 17:32:49 2017 - [info] GTID(with auto-pos) is not supported
Mon Feb 13 17:32:49 2017 - [info] StartingSSH connection tests..
Mon Feb 13 17:32:51 2017 - [info] All SSHconnection tests passed successfully.
Mon Feb 13 17:32:51 2017 - [info] CheckingMHA Node version..
Mon Feb 13 17:32:52 2017 - [info] Version check ok.
Mon Feb 13 17:32:52 2017 - [info] CheckingSSH publickey authentication settings on the current master..
Mon Feb 13 17:32:52 2017 - [info]HealthCheck: SSH to 10.192.203.201 is reachable.
Mon Feb 13 17:32:52 2017 - [info] MasterMHA Node version is 0.56.
Mon Feb 13 17:32:52 2017 - [info] Checkingrecovery script configurations on 10.192.203.201(10.192.203.201:3306)..
Mon Feb 13 17:32:52 2017 - [info] Executing command: save_binary_logs--command=test --start_pos=4 --binlog_dir=/data/mysql--output_file=/var/tmp/save_binary_logs_test --manager_version=0.56--start_file=single-mysql-bin.000018
Mon Feb 13 17:32:52 2017 - [info] Connecting toroot@10.192.203.201(10.192.203.201:22)..
Creating /var/tmp if not exists.. ok.
Checking output directory is accessible or not..
ok.
Binlog found at /data/mysql, up to single-mysql-bin.000018
Mon Feb 13 17:32:52 2017 - [info] Binlogsetting check done.
Mon Feb 13 17:32:52 2017 - [info] CheckingSSH publickey authentication and checking recovery script configurations on allalive slave servers..
Mon Feb 13 17:32:52 2017 - [info] Executing command : apply_diff_relay_logs--command=test --slave_user='mha' --slave_host=10.192.203.101--slave_ip=10.192.203.101 --slave_port=3306 --workdir=/var/tmp--target_version=5.5.19-log --manager_version=0.56--relay_log_info=/data/mysql/relay-log.info --relay_dir=/data/mysql/ --slave_pass=xxx
Mon Feb 13 17:32:52 2017 - [info] Connecting toroot@10.192.203.101(10.192.203.101:22)..
Checking slave recovery environment settings..
Opening /data/mysql/relay-log.info ... ok.
Relay log found at /data/mysql, up to slave1-relay-bin.000011
Temporaryrelay log file is /data/mysql/slave1-relay-bin.000011
Testing mysql connection and privileges.. done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Mon Feb 13 17:32:52 2017 - [info] Executing command : apply_diff_relay_logs--command=test --slave_user='mha' --slave_host=10.192.203.102--slave_ip=10.192.203.102 --slave_port=3306 --workdir=/var/tmp--target_version=5.5.19-log --manager_version=0.56--relay_log_info=/data/mysql/relay-log.info --relay_dir=/data/mysql/ --slave_pass=xxx
Mon Feb 13 17:32:52 2017 - [info] Connecting toroot@10.192.203.102(10.192.203.102:22)..
Checking slave recovery environment settings..
Opening /data/mysql/relay-log.info ... ok.
Relay log found at /data/mysql, up to PC-relay-bin.000011
Temporary relay log file is /data/mysql/PC-relay-bin.000011
Testing mysql connection and privileges.. done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Mon Feb 13 17:32:53 2017 - [info] Slavessettings check done.
Mon Feb 13 17:32:53 2017 - [info]
10.192.203.201(10.192.203.201:3306)(current master)
+--10.192.203.101(10.192.203.101:3306)
+--10.192.203.102(10.192.203.102:3306)
Mon Feb 13 17:32:53 2017 - [info] Checkingreplication health on 10.192.203.101..
Mon Feb 13 17:32:53 2017 - [info] ok.
Mon Feb 13 17:32:53 2017 - [info] Checkingreplication health on 10.192.203.102..
Mon Feb 13 17:32:53 2017 - [info] ok.
Mon Feb 13 17:32:53 2017 - [info] Checkingmaster_ip_failover_script status:
Mon Feb 13 17:32:53 2017 - [info] /usr/bin/master_ip_failover --command=status--ssh_user=root --orig_master_host=10.192.203.201--orig_master_ip=10.192.203.201 --orig_master_port=3306
IN SCRIPT TEST====/etc/init.d/keepalivedstop==/etc/init.d/keepalived start===
Checking the Status of the script.. OK
Mon Feb 13 17:32:53 2017 - [info] OK.
Mon Feb 13 17:32:53 2017 - [warning]shutdown_script is not defined.
Mon Feb 13 17:32:53 2017 - [info] Got exitcode 0 (Not master dead).
MySQL Replication Health is OK.
8 Start monitoring on the management side
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
# View status
masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:3349) is running(0:PING_OK),master:10.192.203.201
9 Verify failover
Close Mysql instance on 10.192.203.201:
[root@pc2mha]# service mysqld stop
Shutting downMySQL... SUCCESS!
View logs on the management node:
tail -f /var/log/mha/app1/manager.log
You will see:
Started automated(non-interactive)failover. Invalidated master IP address on10.192.203.201(10.192.203.201:3306) The latest slave10.192.203.101(10.192.203.101:3306) has all relay logs for recovery. Selected10.192.203.101(10.192.203.101:3306) as a new master. 10.192.203.101(10.192.203.101:3306): OK:Applying all logs succeeded. 10.192.203.101(10.192.203.101:3306): OK:Activated master IP address. 10.192.203.102(10.192.203.102:3306): Thishost has the latest relay log events. Generating relay diff files from the latestslave succeeded. 10.192.203.102(10.192.203.102:3306): OK:Applying all logs succeeded. Slave started, replicating from10.192.203.101(10.192.203.101:3306) 10.192.203.101(10.192.203.101:3306):Resetting slave info succeeded. Master failover to10.192.203.101(10.192.203.101:3306) completed successfully. Mon Feb 13 17:44:28 2017 - [info] Sendingmail.. Unknown option: conf
Alarm mail was also received:
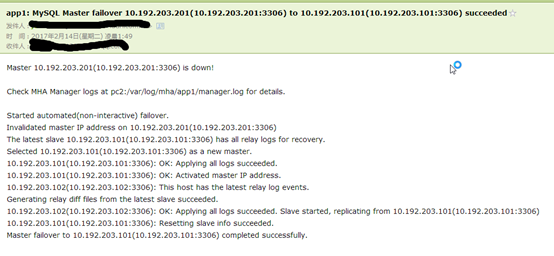
Vip also drifted over:
[root@slave1 mysql]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0:<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen1000
link/ether 08:00:27:04:05:16 brd ff:ff:ff:ff:ff:ff
inet 10.192.203.101/24 brd 10.192.203.255 scope global eth0
inet 10.192.203.108/32 scope global eth0
inet6 fe80::a00:27ff:fe04:516/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
3: eth1:<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen1000
link/ether 08:00:27:3a:ec:3c brd ff:ff:ff:ff:ff:ff
inet 10.0.10.5/24 brd 10.0.10.255 scope global eth1
inet6 fe80::a00:27ff:fe3a:ec3c/64 scope link tentative dadfailed
valid_lft forever preferred_lft foreverCheck slave status on PC:
mysql> show slave status \G;
*************************** 1. row***************************
Slave_IO_State: Waiting formaster to send event
Master_Host: 10.192.203.101
Master_User: rep_user
Master_Port: 3306
You can see that 10.192.203.102 replication automatically points to 10.192.203.101.
Looking at the variable read_only on the current master, we found that it was automatically closed, indicating that the previous slave can now write:
mysql> showvariables like 'read_only';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | OFF |
+---------------+-------+
1 row in set (0.01 sec)
When the handover is completed, the manager process automatically hangs up:
[root@pc2 mysql]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
The mha configuration file was modified by itself (the configuration information of the original master library was deleted):
[root@pc2 mha]# cat app1.cnf
[server default] manager_log=/var/log/mha/app1/manager.log manager_workdir=/var/log/mha/app1.log master_binlog_dir=/data/mysql master_ip_failover_script=/usr/bin/master_ip_failover master_ip_online_change_script=/usr/bin/master_ip_online_change password=test ping_interval=2 repl_password=beijing repl_user=rep_user report_script=/usr/bin/send_report ssh_user=root user=mha [server2] candidate_master=1 check_repl_delay=0 hostname=10.192.203.101 port=3306 [server3] hostname=10.192.203.102 port=3306
Now the master library 10.192.203.101 has no original master-slave replication information:
mysql> showslave status \G;
Empty set (0.00sec)
ERROR:
No queryspecified
The next thing we should do is:
(1) Find out the reason why the main library hangs and fix it.
(2) Make sure that the original repository catches up with the current one and continues to replicate correctly.
(3) On the current main library, change master to points to the original main library and starts to replicate, so as to prepare for future failover.
(4) Check whether the current master-slave replication status is normal (masterha_check_repl--conf=/etc/mha/app1.cnf)
(5) Start the original main library keepalive process
(5) Ensure that the original main library configuration file (read_only set to 1, relay_log_purge=0)
(8) Modify the mha configuration file to add the original master database information
(9) Start the manager process to check whether the mha status is normal
10 Online Switching
In many cases, an existing primary server needs to be migrated to another server. For example, the main server hardware failure, the RAID control card needs to be rebuilt, the main server will be moved to a better performance server, and so on. Maintenance of the primary server results in performance degradation, resulting in downtime at least not being able to write data. In addition, blocking or killing the currently running session can lead to data inconsistencies between hosts. MHA provides fast switching and elegant resistance
Plug writing, the switching process only takes 0.5-2 seconds, during which the data can not be written. In many cases, blocking writes of 0.5-2s are acceptable. Therefore, switching primary servers does not require scheduling maintenance time windows.
The general process of MHA online switching:
(1) Detecting replication settings and determining the current primary server
(2) Identify a new primary server
(3) Blocking Writing to the Current Main Server
(4) Waiting for all slave servers to catch up with replication
(5) Grant write to the new primary server
(6) Reset the slave server
If I want to switch back from 10.192.203.101 to 10.192.203.201 now, it will be done online.
10.1 Stop MHA Monitoring
masterha_stop --conf=/etc/mha/app1.cnf
10.2 Online Switching
[root@pc2 bin]# masterha_master_switch--conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=10.192.203.201--new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
Tue Feb 14 02:44:20 2017 - [info]MHA::MasterRotate version 0.56. Tue Feb 14 02:44:20 2017 - [info] Startingonline master switch.. Tue Feb 14 02:44:20 2017 - [info] Tue Feb 14 02:44:20 2017 - [info] * Phase1: Configuration Check Phase.. Tue Feb 14 02:44:20 2017 - [info] Tue Feb 14 02:44:20 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping. Tue Feb 14 02:44:20 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf.. Tue Feb 14 02:44:20 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf.. Tue Feb 14 02:44:20 2017 - [info]Multi-master configuration is detected. Current primary(writable) master is10.192.203.101(10.192.203.101:3306) Tue Feb 14 02:44:20 2017 - [info] Masterconfigurations are as below: Master 10.192.203.101(10.192.203.101:3306),replicating from 10.192.203.201(10.192.203.201:3306) Master 10.192.203.201(10.192.203.201:3306),replicating from 10.192.203.101(10.192.203.101:3306), read-only Tue Feb 14 02:44:20 2017 - [info] GTIDfailover mode = 0 Tue Feb 14 02:44:20 2017 - [info] CurrentAlive Master: 10.192.203.101(10.192.203.101:3306) Tue Feb 14 02:44:20 2017 - [info] AliveSlaves: Tue Feb 14 02:44:20 2017 - [info] 10.192.203.201(10.192.203.201:3306) Version=5.5.19-log (oldest major versionbetween slaves) log-bin:enabled Tue Feb 14 02:44:20 2017 - [info] Replicating from10.192.203.101(10.192.203.101:3306) Tue Feb 14 02:44:20 2017 - [info] 10.192.203.102(10.192.203.102:3306) Version=5.5.19-log (oldest major versionbetween slaves) log-bin:enabled Tue Feb 14 02:44:20 2017 - [info] Replicating from10.192.203.101(10.192.203.101:3306) It is better to execute FLUSHNO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to executeon 10.192.203.101(10.192.203.101:3306)? (YES/no): yes Tue Feb 14 02:45:03 2017 - [info] ExecutingFLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time.. Tue Feb 14 02:45:03 2017 - [info] ok. Tue Feb 14 02:45:03 2017 - [info] CheckingMHA is not monitoring or doing failover.. Tue Feb 14 02:45:03 2017 - [info] Checkingreplication health on 10.192.203.201.. Tue Feb 14 02:45:03 2017 - [info] ok. Tue Feb 14 02:45:03 2017 - [info] Checkingreplication health on 10.192.203.102.. Tue Feb 14 02:45:03 2017 - [info] ok. Tue Feb 14 02:45:03 2017 - [info]10.192.203.201 can be new master. Tue Feb 14 02:45:03 2017 - [info] From: 10.192.203.101(10.192.203.101:3306)(current master) +--10.192.203.201(10.192.203.201:3306) +--10.192.203.102(10.192.203.102:3306) To: 10.192.203.201(10.192.203.201:3306) (newmaster) +--10.192.203.102(10.192.203.102:3306) +--10.192.203.101(10.192.203.101:3306) Starting master switch from10.192.203.101(10.192.203.101:3306) to 10.192.203.201(10.192.203.201:3306)?(yes/NO): yes Tue Feb 14 02:45:09 2017 - [info] Checkingwhether 10.192.203.201(10.192.203.201:3306) is ok for the new master.. Tue Feb 14 02:45:09 2017 - [info] ok. Tue Feb 14 02:45:09 2017 - [info] ** Phase1: Configuration Check Phase completed. Tue Feb 14 02:45:09 2017 - [info] Tue Feb 14 02:45:09 2017 - [info] * Phase2: Rejecting updates Phase.. Tue Feb 14 02:45:09 2017 - [info] Tue Feb 14 02:45:09 2017 - [info] Executingmaster ip online change script to disable write on the current master: Tue Feb 14 02:45:09 2017 - [info] /usr/bin/master_ip_online_change--command=stop --orig_master_host=10.192.203.101--orig_master_ip=10.192.203.101 --orig_master_port=3306--orig_master_user='mha' --orig_master_password='test'--new_master_host=10.192.203.201 --new_master_ip=10.192.203.201--new_master_port=3306 --new_master_user='mha' --new_master_password='test' --orig_master_ssh_user=root--new_master_ssh_user=root --orig_master_is_new_slave Tue Feb 14 02:45:09 2017 728241 Setread_only on the new master.. ok. Tue Feb 14 02:45:09 2017 733969 Drpping appuser on the orig master.. Tue Feb 14 02:45:09 2017 735861 Set read_only=1on the orig master.. ok. Tue Feb 14 02:45:09 2017 739394 Killing allapplication threads.. Tue Feb 14 02:45:09 2017 739431 done. SIOCSIFFLAGS: Cannot assign requestedaddress Tue Feb 14 02:45:09 2017 - [info] ok. Tue Feb 14 02:45:09 2017 - [info] Lockingall tables on the orig master to reject updates from everybody (includingroot): Tue Feb 14 02:45:09 2017 - [info] ExecutingFLUSH TABLES WITH READ LOCK.. Tue Feb 14 02:45:09 2017 - [info] ok. Tue Feb 14 02:45:09 2017 - [info] Origmaster binlog:pos is single-mysql-bin.000009:997. Tue Feb 14 02:45:09 2017 - [info] Waiting to execute all relay logs on10.192.203.201(10.192.203.201:3306).. Tue Feb 14 02:45:09 2017 - [info] master_pos_wait(single-mysql-bin.000009:997)completed on 10.192.203.201(10.192.203.201:3306). Executed 0 events. Tue Feb 14 02:45:09 2017 - [info] done. Tue Feb 14 02:45:09 2017 - [info] Gettingnew master's binlog name and position.. Tue Feb 14 02:45:09 2017 - [info] single-mysql-bin.000022:107 Tue Feb 14 02:45:09 2017 - [info] All other slaves should start replicationfrom here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.192.203.201',MASTER_PORT=3306, MASTER_LOG_FILE='single-mysql-bin.000022', MASTER_LOG_POS=107,MASTER_USER='rep_user', MASTER_PASSWORD='xxx'; Tue Feb 14 02:45:09 2017 - [info] Executingmaster ip online change script to allow write on the new master: Tue Feb 14 02:45:09 2017 - [info] /usr/bin/master_ip_online_change--command=start --orig_master_host=10.192.203.101 --orig_master_ip=10.192.203.101--orig_master_port=3306 --orig_master_user='mha' --orig_master_password='test'--new_master_host=10.192.203.201 --new_master_ip=10.192.203.201--new_master_port=3306 --new_master_user='mha' --new_master_password='test'--orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave Tue Feb 14 02:45:09 2017 946501 Setread_only=0 on the new master. Tue Feb 14 02:45:09 2017 947009 Creatingapp user on the new master.. Tue Feb 14 02:45:10 2017 - [info] ok. Tue Feb 14 02:45:10 2017 - [info] Tue Feb 14 02:45:10 2017 - [info] *Switching slaves in parallel.. Tue Feb 14 02:45:10 2017 - [info] Tue Feb 14 02:45:10 2017 - [info] -- Slaveswitch on host 10.192.203.102(10.192.203.102:3306) started, pid: 8353 Tue Feb 14 02:45:10 2017 - [info] Tue Feb 14 02:45:10 2017 - [info] Logmessages from 10.192.203.102 ... Tue Feb 14 02:45:10 2017 - [info] Tue Feb 14 02:45:10 2017 - [info] Waiting to execute all relay logs on10.192.203.102(10.192.203.102:3306).. Tue Feb 14 02:45:10 2017 - [info] master_pos_wait(single-mysql-bin.000009:997)completed on 10.192.203.102(10.192.203.102:3306). Executed 0 events. Tue Feb 14 02:45:10 2017 - [info] done. Tue Feb 14 02:45:10 2017 - [info] Resetting slave10.192.203.102(10.192.203.102:3306) and starting replication from the newmaster 10.192.203.201(10.192.203.201:3306).. Tue Feb 14 02:45:10 2017 - [info] Executed CHANGE MASTER. Tue Feb 14 02:45:10 2017 - [info] Slave started. Tue Feb 14 02:45:10 2017 - [info] End oflog messages from 10.192.203.102 ... Tue Feb 14 02:45:10 2017 - [info] Tue Feb 14 02:45:10 2017 - [info] -- Slaveswitch on host 10.192.203.102(10.192.203.102:3306) succeeded. Tue Feb 14 02:45:10 2017 - [info] Unlockingall tables on the orig master: Tue Feb 14 02:45:10 2017 - [info] ExecutingUNLOCK TABLES.. Tue Feb 14 02:45:10 2017 - [info] ok. Tue Feb 14 02:45:10 2017 - [info] Startingorig master as a new slave.. Tue Feb 14 02:45:10 2017 - [info] Resetting slave10.192.203.101(10.192.203.101:3306) and starting replication from the newmaster 10.192.203.201(10.192.203.201:3306).. Tue Feb 14 02:45:10 2017 - [info] Executed CHANGE MASTER. Tue Feb 14 02:45:10 2017 - [info] Slave started. Tue Feb 14 02:45:10 2017 - [info] All newslave servers switched successfully. Tue Feb 14 02:45:10 2017 - [info] Tue Feb 14 02:45:10 2017 - [info] * Phase5: New master cleanup phase.. Tue Feb 14 02:45:10 2017 - [info] Tue Feb 14 02:45:10 2017 - [info] 10.192.203.201: Resetting slave infosucceeded. Tue Feb 14 02:45:10 2017 - [info] Switchingmaster to 10.192.203.201(10.192.203.201:3306) completed successfully.
You need to enter two yes manually in the middle.
10.3 Check if the switch is successful
Execute master ha_check_repl -- conf=/etc/mha/app1.cnf to verify that the current master-slave configuration is correct.
Log in to the slave libraries and verify that the replication now points to the new master library.
Now 10.192.203.101, 10.192.203.102 copies all point to 10.192.203.201.
No replication information was found on 10.192.203.201:
mysql> show slave status \G;
Empty set (0.00 sec)
ERROR:
No query specified
It is found that there are the following characteristics after online switching:
After the online switch is completed, other library replicates will point to the current main library. The original replicated information on the current main library has been cleared
(2) The information of the original main library in the mha configuration file has not been deleted.
(3) The original main library automatically becomes read-only, and now the main library automatically becomes writable.
(4) The vip of the original main library drifts automatically to the current main library.
10.4 Follow-up
(1) After the online switching is completed, the current main library still needs to change master to the original main library, and then start replication.
(2) Start the keepalive process of the original main library
(3) Start mha monitoring
I found that when the standby main library was down, if the main library was also down, then mha could not automatically switch to other slave s. Error log:
Wed Feb 15 21:42:04 2017 -[error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln492] Server 10.192.203.101(10.192.203.101:3306) isdead, but must be alive! Check server settings.
Wed Feb 15 21:42:04 2017 -[error][/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln177] Got ERROR: at/usr/share/perl5/vendor_perl/MHA/MasterFailover.pm line 268
This article refers to: http://www.cnblogs.com/xuanzhi201111/p/4231412.html
If there are any mistakes in the article, you are welcome to point out.