One background
With the rapid development of the Internet industry, web-based business and processes become more cumbersome and iterative faster. Traditional manual testing can not meet the market demand. In order to reduce the labor cost of regression, rapid iteration and automatic testing are the inevitable trend. This article mainly introduces the webUI automation platform.
II. Characteristic functions
- Platform to realize data separation
- Internationalization, support simulation of overseas users, multi language verification
- Distributed concurrent cluster
- Use case management across environmental branches
- Support online & H5 page UI automation
- Custom positioning expression
- Dynamically generated expectations
- Pre / post actions support the combination of use cases / sql according to business requirements
- Interface & html mock
- Picture comparison
- Interface data comparison
- selenium IDE recording script to platform use case
- Common parameters
- Data encryption and decryption, etc
- ...
III. system architecture design & framework selection
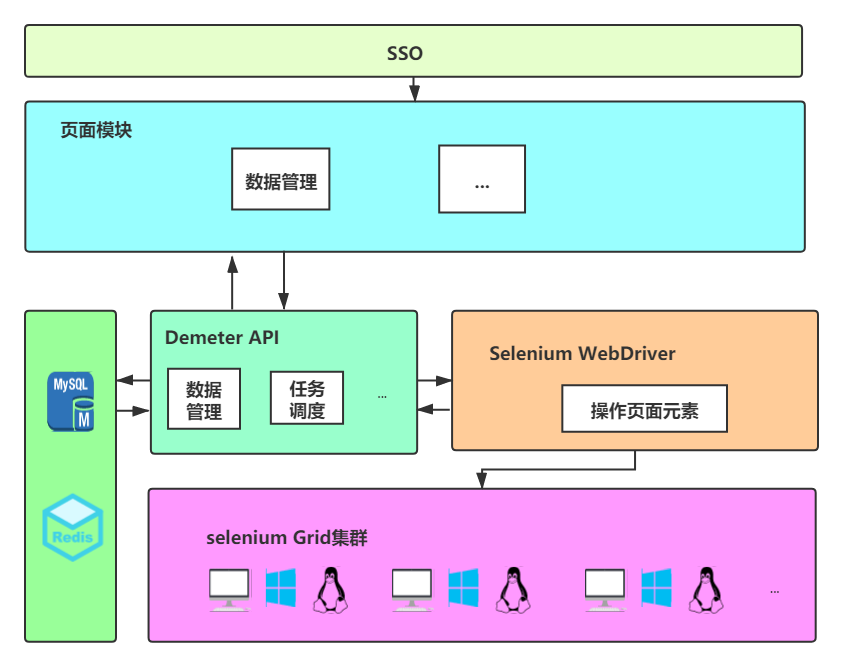
Automated test framework
There are generally three mainstream testing frameworks in the market: data-driven, page object and behavior driven
- Data driven
The same test script uses different test data to execute, and the test data and test behavior are completely separated. This design pattern is called data-driven. - Page object mode
Page object mode separates the test code from the page elements and operation methods of the tested page, so as to reduce the impact of page element changes on the test code. - Behavior driven
The behavior driven model can establish a one-to-one mapping relationship between user stories or requirements and test cases to ensure that the objectives and scope of development and testing are strictly consistent with the requirements. It can better enable the demander, developer and tester to carry out relevant development work with unique requirements and prevent inconsistent understanding of requirements.
In this article, we use both data-driven and page object patterns. Separate the test data from the test behavior, and take the page element as a part of the test data, separate it from the test method and test code. In order to minimize the use case maintenance cost when the requirements change.
Implementation method:
- Manage the tested page separately, including page url, page type, etc
- Associate the element under test with the page
- Each use case is composed of multiple steps, and each step is composed of tested elements, operations, etc
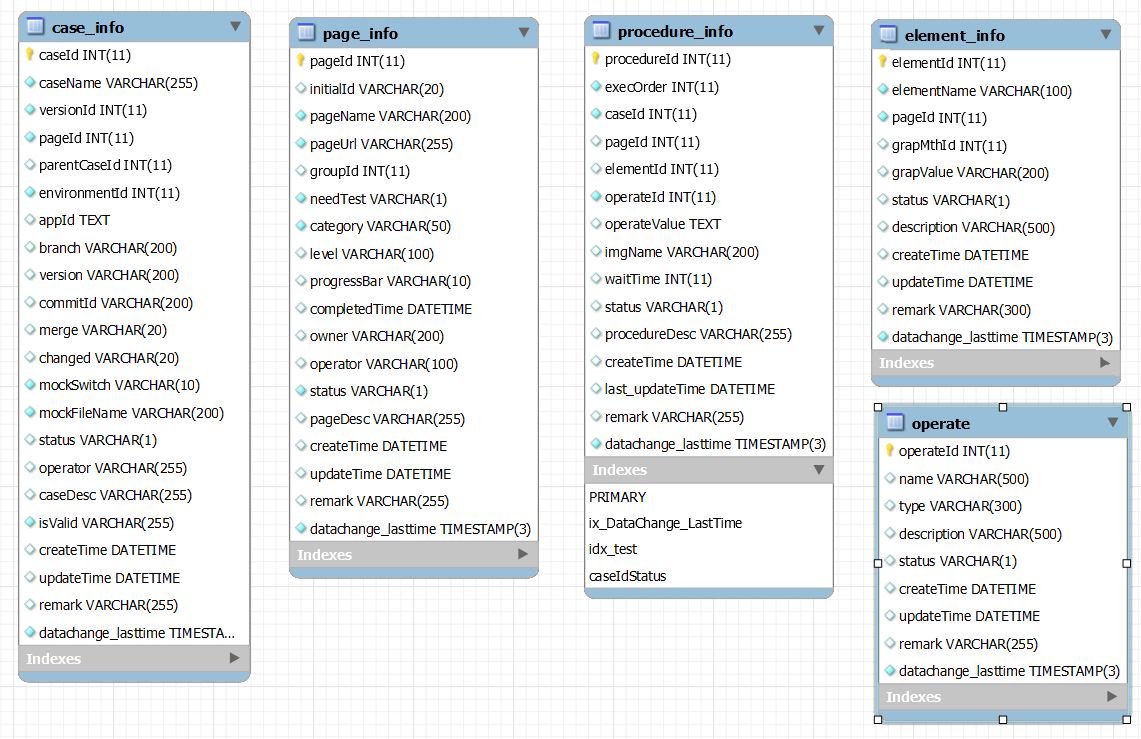
Selenium
Why selenium?
Selenium has a history of more than ten years, and now it has reached selenium 3. This is a very mature tool. It has a large number of users, the development team has been maintaining it, and the community is very active. Basically, people will answer the questions they ask by email. And the questions asked by others will also be copied to you. You can see what functions others use, what problems they encounter, and how to solve them. These can help us become more familiar with selenium.
Furthermore, it supports most mainstream browsers, including Firefox, ie, chrome, safari, opera, etc.
Moreover, its supporting tools are very perfect. selenium IDE can record and play back use cases through user behavior, and can be converted into test scripts in various languages. selenium Grid can execute test scripts in multiple test environments in a concurrent manner to realize the concurrent execution of test scripts, which greatly shortens the execution time of use cases.
Moreover, selenium supports almost all programming languages, such as java, javaScript, Ruby, PHP, Python, Perl, C#.
On the principle of selenium, there are a lot of documents on the Internet. It will not be repeated here.
WebDriver
WebDriver is actually selenium 2. Compared with selenium 1, selenium 1 controls page elements through js injection, while WebDriver uses the internal interface of the browser to operate page elements. It will first find the coordinate position of the element, and then perform the corresponding operation at this coordinate point.
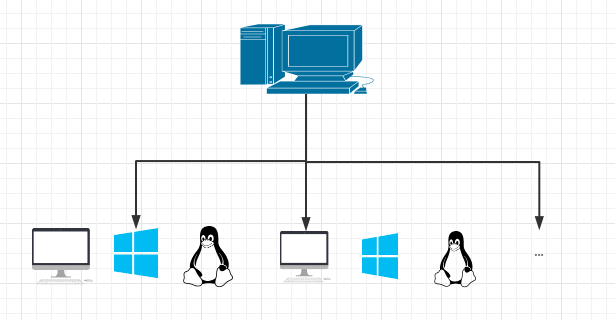
Selenium Grid
Selenium Grid is a part of selenium suite. It is specially used to run multiple test cases in parallel on different browsers, operating systems and machines.
Four function introduction
Platformization
To achieve the following objectives
Business generality. That is, different businesses can enter data through our platform to realize ui automation.
Data visualization. So that testers can enter and view data through the platform to reduce communication costs.
Front end frame: Flying ice( https://ice.work/ )
Why choose flying ice?
First, feibing is a front-end development framework developed by Ali. The framework has detailed documents and rich components, which greatly reduces our learning and development costs.
Secondly, the kernel of feibing is react. React, as a very mature framework, has a large number of users. There are also a lot of data on the Internet, which can make us have data to check when we encounter problems.
internationalization
Why internationalization?
Since the business of our department is mainly aimed at the international market and most users come from overseas, it is essential for us to imitate overseas users and conduct multilingual testing.
How to achieve it?
During our initial research, we found that there are three ways to simulate overseas users.
- Modify the hosts file of the test machine and change the ip to overseas ip
- Use machines deployed overseas as test machines to execute use cases
- Using vpn
After practice, we found that the server is not allowed to modify the hosts file, so we excluded scheme 1. Scheme 2 is closest to real users, but it needs to deploy test environment machines overseas, which is expensive and unrealistic. So we finally choose scheme 3.
Implementation method:
1 encapsulate vpn into browser plug-in
Add a new file manifest.json and write the following contents
{
"version": "1.0.0",
"manifest_version": 2,
"name": "Chrome Proxy",
"permissions": [
"proxy",
"tabs",
"unlimitedStorage",
"storage",
"<all_urls>",
"webRequest",
"webRequestBlocking"
],
"background": {
"scripts": ["background.js"]
},
"minimum_chrome_version":"22.0.0"
}
- Add a new file background.js and write the following contents
var sessionId = Math.ceil(Math.random()*10000000);
var config = {
mode: "fixed_servers",
rules: {
singleProxy: {
scheme: "https",
host: "vpn address",
port: parseInt(22225)
}
}
};
chrome.proxy.settings.set({value: config, scope: "regular"}, function() {});
function callbackFn(details) {
return {
authCredentials: {
username: "vpn account number",
password: "vpn Account password"
}
};
}
chrome.webRequest.onAuthRequired.addListener(
callbackFn,
{urls: ["<all_urls>"]},
['blocking']
);
- Install plug-ins
Package the above two files into xx.zip file (the file name can be customized) and put them in the resources / VPN plugins directory. Before starting the browser, write to the Resource
ChromeOptions options = new ChromeOptions();
String proxyPath = BrowserStartUtil.class.getClassLoader().getResource("/vpnPlugins/xx.zip").getPath();
options.addExtensions(new File(proxyPath));
driver = new RemoteWebDriver(new URL(String.format("http://%s/wd/hub", hubIp)), options);
driver.get(url);
// do-something()
driver.quit()
At this point, the plug-in will be installed automatically after the browser starts
Suppose we want to simulate French users and American users, what should we do?
Because the vpn accounts in each country are different, we encapsulate each vpn account into a different zip. When you need to simulate a French user, call the French zip file; When you need to impersonate a U.S. user, you call the U.S. zip file.
if (countryCode.contains("au")) {
String proxyPath = BrowserStartUtil.class.getClassLoader().getResource(IBU_AU_RESIDENTIAL_PROXY_PATH).getPath();
options.addExtensions(new File(proxyPath));
return options;
}
if (countryCode.contains("us")) {
String proxyPath = BrowserStartUtil.class.getClassLoader().getResource(IBU_US_RESIDENTIAL_PROXY_PATH).getPath();
options.addExtensions(new File(proxyPath));
return options;
}
if (countryCode.contains("sg")) {
String proxyPath = BrowserStartUtil.class.getClassLoader().getResource(IBU_SG_RESIDENTIAL_PROXY_PATH).getPath();
options.addExtensions(new File(proxyPath));
return options;
}
if (countryCode.contains("fr")) {
String proxyPath = BrowserStartUtil.class.getClassLoader().getResource(IBU_FR_RESIDENTIAL_PROXY_PATH).getPath();
options.addExtensions(new File(proxyPath));
return options;
}
if (countryCode.contains("de")) {
String proxyPath = BrowserStartUtil.class.getClassLoader().getResource(IBU_DE_RESIDENTIAL_PROXY_PATH).getPath();
options.addExtensions(new File(proxyPath));
return options;
}
return options;
Here, if you just execute it on your own machine, it's enough.
But if you want to send it to the server, you will find that the plug-in is not installed successfully. Why?
First of all, because linux servers are generally virtual images, we can't really open the browser to execute case, so we can only use headless mode to execute case.
The plug-in installation must open the real browser. What should I do? Please refer to concurrent execution to execute the use case using a remote device with a real browser.
Distributed concurrent execution
In this paper, the distributed concurrent environment mainly uses selenium Grid cluster.
As mentioned in internationalization, in order to simulate overseas users, browsers with real environment are bound to be used. Moreover, when there are many test cases, the execution time plays a decisive role in whether automation can be applied to the actual iterative process. For the above reasons, we decided to build a distributed concurrent environment.
- Establish hub node
Write the sh script so that when the service is deployed, the linux server can be set as a hub node by executing the script
java -jar /opt/tomcat/bin/selenium-server-standalone-3.141.59.jar -role hub -timeout 300000 -browserTimeout 900000
- Prepare node machine
● download jdk and configure java environment variables
● download selenium-server-standalone-3.141.59.jar (you can search Baidu by yourself)
● download the corresponding driver according to the tested browser version
● open the dos window and execute the following commands (modify the position of driver driver according to your actual situation, and xxx is the IP of hub machine)
java -jar selenium-server-standalone-3.141.59.jar -role node -hub http://xxx:4444/grid/register -port 80 -Dwebdriver.chrome.driver="D:\node\chromedriver75.0.3770.90_win32.exe"
When the following prompt appears (The node is registered to the hub and ready to use), it indicates that the node registration is successful
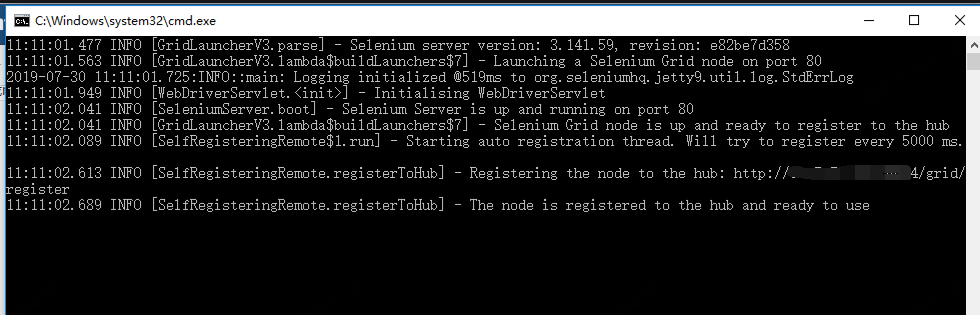
At this point, use the RemoteWebDriver to open the browser of the node machine for testing (replace the hub IP with the IP of your hub machine)
WebDriver driver = new RemoteWebDriver(new URL(String.format("http://%s/wd/hub", hubIp)), options);
Use case management across environmental branches
In practical application, we have encountered a problem. A business usually involves multiple developers in parallel. Each developer will only test its own branch after testing. When these sub branches are tested, the code will be combined for integration testing.
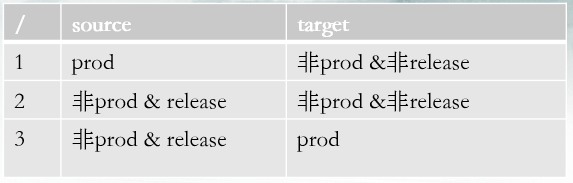
So how to combine the automation use cases of multiple sub branches and synchronize them to production after code release as daily production inspection use cases? Use case management across environment branches realizes this function.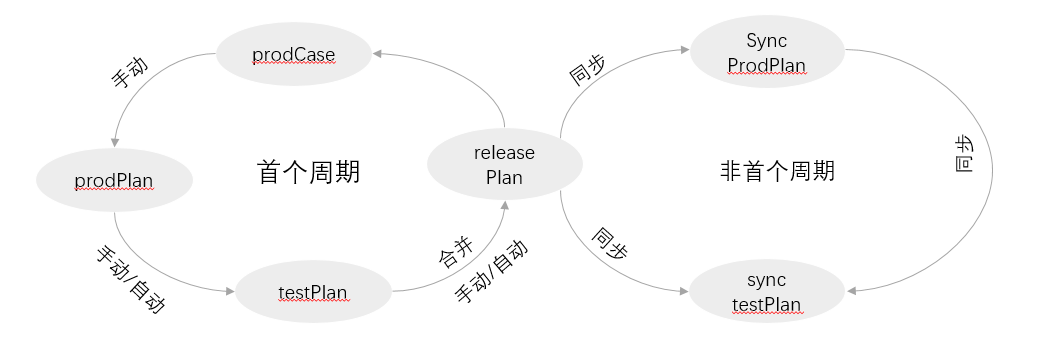
merge
Direction: only non release branch test cases of the test environment can be merged into the release branch
Principle:
1. Compare the case to be merged with the case of the main branch. If the parent case of the case to be merged is the same as the parent case of the case of the main branch, merge. Otherwise, copy the case to be merged and associate it with the plan of the main branch
2. Merge: compare the steps of the above two use cases. If the steps are identical, the merge is successful; If the number of steps of the case to be merged is greater than the number of steps of the case of the main branch, and the first n steps are exactly the same as the main branch, the extra copy will be associated with the case of the main branch; If the number of steps of the main branch case is greater than that of the case to be merged, the merge fails
3. Merge failure response data: failed plans, use cases and steps
synchronization
Principle (C3 - > C4):
1. If c3 changes, and the parent case of c3 is not equal to c4, or the parent case of c3 does not exist or is empty, copy c3 to generate a new case c5
2. If c3 changes and the parent case of c3 is c4, delete c4 and copy c3 to generate a new c4
H5 UI automation
h5 automation adopts the h5 mode provided by the browser laboratory. Such as chrome browser
ChromeOptions options = new ChromeOptions();
Map<String, String> mobile = new HashMap<>();
mobile.put("deviceName", "iphone X");
options.setExperimentalOption("mobileEmulation", mobile);
Custom positioning expression
As shown in the figure below, when we need to locate the first clickable date, we will find that the most powerful xpath is slightly beyond our power.
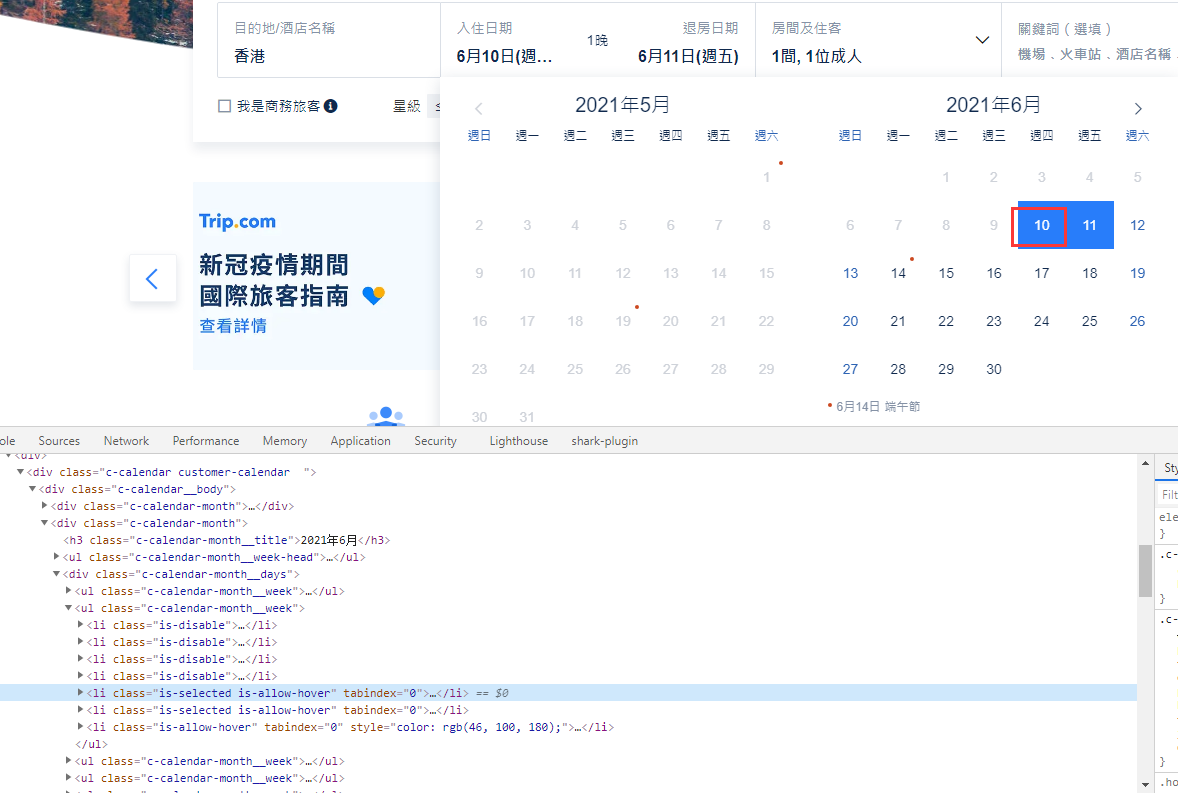
In this case, we add A user-defined positioning expression: filter (grapMth, grapValue, logical exp, Index). This expression can obtain element list A according to grapMth and grapValue, then filter according to the specified expression to obtain element list B, and finally obtain the Index element in B.
Of which:
- ocatorType: element fetching method, supporting id/name/className/tagName/linkText/partialLinkText/cssSelector,
- locatorValue: the positioning expression of the element. It supports that [] is used to represent all elements of the level. For example: / / div/ul[]/li, it means to obtain the li tag elements of all ul tags under the Div
- logicalExp: logical expression. Multiple logical expressions can be passed in
- Index: index
If you pass in xpath, //[@id = 'searchFormWrapper'] / UL / Li [2] / div [3] / div / div [1] / div [2] / div / UL [] / Li, [class! = is disable and text! = null and class! = null], 2 can be located to 2021 / 6 / 11
Dynamic expected value
Most of the time, the values in our pages, including URLs, change dynamically. For example, dynamic dates may be passed in, but these data have certain rules. Then we can dynamically obtain or generate the expected value according to this law.
Most of the dynamic expectations here are our own encapsulated interfaces. For example, randomly generate a date in a specified format, a string of a specified length, an e-mail address, etc. The following are some dynamic expectation generation methods.
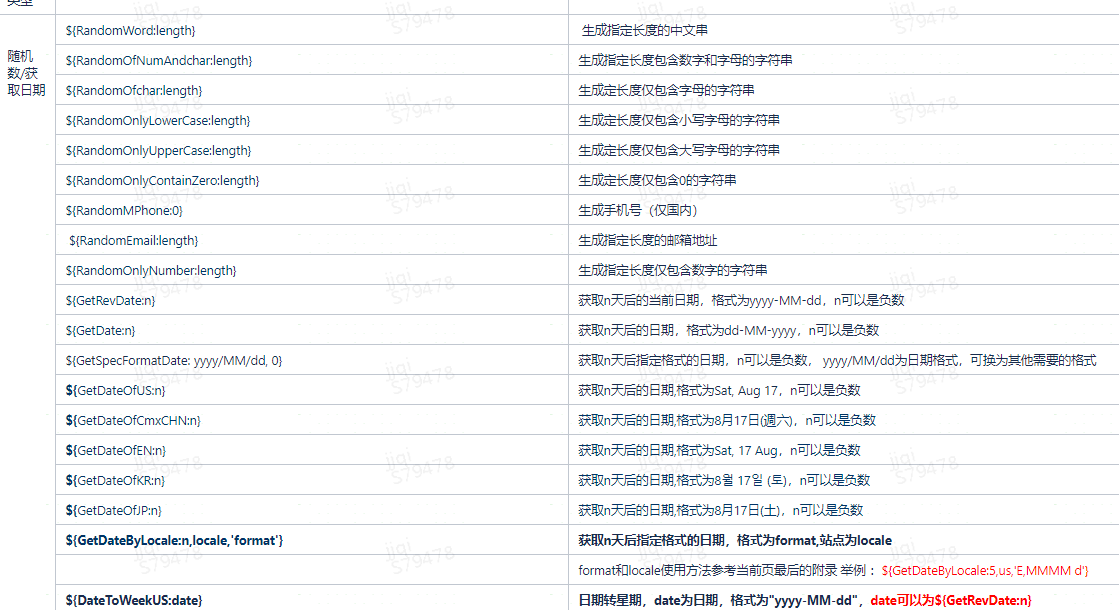
In order to support the expectation value with mathematical calculation logic, we also introduce a powerful expression engine Aviator.
Aviator is a high-performance, lightweight expression engine based on java implementation. It dynamically compiles String type expressions into Java ByteCode and sends them to the JVM for execution.
Aviator supports all relational and arithmetic operators, does not support bit operations, and supports the priority of expressions. The priority is the same as that of Java operators, and supports forcing the priority through parentheses.
<dependency>
<groupId>com.googlecode.aviator</groupId>
<artifactId>aviator</artifactId>
<version>5.1.3</version>
</dependency>
AviatorEvaluator.execute(destValue)
Front / rear action
If each case you want to test has a common part, you can propose this common part as a component case. When other cases need to be used, only configure the case as a pre action. Such a process can reduce the case maintenance cost of public components. When this part of the business changes, it will only need to maintain the component cases without modifying this part of the use cases in each case.
But what's more complicated here is that your pre action can also have pre action. The preceding action can be case or sql. Then the execution node of case/sql is very important.
This paper adopts the structure of queue + tree, and uses the special of tree and queue to sort the pre and post actions of case. Then execute in sequence.
For example:
There are already case a (Ca). Ca has pre actions 1, 2 and 3, of which 1 is sql, 2 is case(C2), C2 is SQL by pre actions 4, 5, 4 & 5, and 3 is Sql Queue to store pre actions (1, 2 and 3) Tree root node Ca
When the Queue is not empty, the loop is entered
First cycle: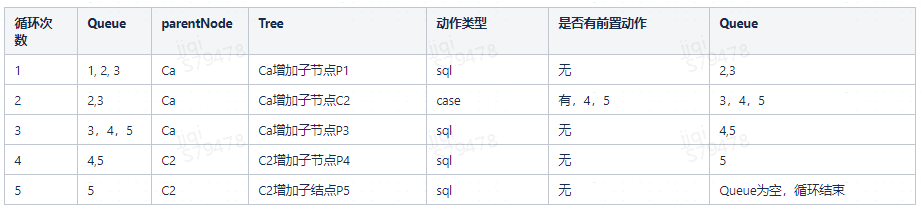
Difficulties:
- How to obtain the parentNode and how to judge what the parentNode of this cycle should be?
answer1: record the parent node with pre action in the map. The key uses caseid, and value is the pre action length of each parent node, which is the number of cycles of each parent node
Answer2: the data type in the queue is CasePrework. When going to each preceding action, find the parent node according to CasePrework.caseId - The local debugging case does not have an id. even if a temporary id is given, the parent node cannot be obtained according to CasePrework.caseId. How can the local debugging case obtain the parent node of the current use case?
answer: according to the initial length of the Queue, the parentNode will not be replaced within this length - The resulting tree is as follows:
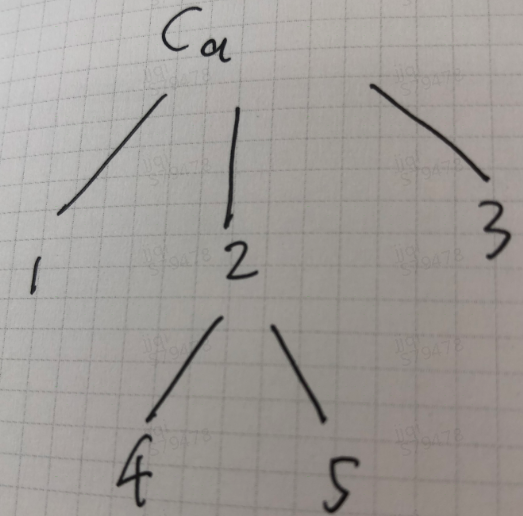
Sorting algorithm: use the post root sorting method of the tree to generate the execution order list of pre actions, and traverse the list to execute pre actions
destList: [1, 4, 5, 2, 3, Ca]
Data Mock
In fact, the most frequent changes we encounter in UI automation do not come from changes in page style interaction, but from the unavailability of case s due to data changes. In order to solve this problem, we also connected to the interface Mock service developed by our classmates. The page can be static through data Mock, and the whole page can be verified through image comparison.
Page Mock
When the test development is parallel, that is, when coding is developed, the test is used to write use cases. In this case, the test belongs to blind writing and cannot be debugged. The cost of joint debugging will be relatively high when it is developed and tested.
Therefore, we provide the page Mock function. The test can build a simple version page according to the agreed attribute id with the development students, or let the development students provide a simple version of html for case debugging. Reduce the cost of joint commissioning in the later stage.
Page data verification
In UI automation testing, in addition to the verification of page function, style, interaction and compatibility, it is essential to verify the data accuracy. To verify the data, we also customize the operation method to obtain the interface response data, and obtain the value of the specified attribute through jsonPath to compare with the page data.
Interface data comparison
The platform provides cross environment use case management function, that is, there are test environment use cases on the platform&Production environment use case
For various reasons, the platform has not been released to the production environment. The business data of our test environment and production environment are isolated. When executing test environment use cases, you need to compare the interface data of the test environment with the page; When the production case is executed, the production interface needs to be called to compare the data.
Therefore, we must provide a service so that users can call both the interface of the test environment and the interface of the production environment. To this end, we provide springboard service.
The springboard service mainly realizes to find the ip address of the service in the corresponding environment according to the service id (appId) & environment provided by the user, and then call the corresponding interface according to ip+port to obtain the interface response data.
The response data of the but interface is usually json objects. Users cannot compare the whole object, so we also introduced JsonPath
So that users can freely obtain the required data
<dependency>
<groupId>com.jayway.jsonpath</groupId>
<artifactId>json-path</artifactId>
<version>2.4.0</version>
</dependency>
Picture comparison
At present, the popular algorithms in the market are Euclidean distance, cosine distance and Hamming distance
Euclidean distance
Euclidean distance is the most common distance measure (used to measure the distance of individuals in space. The farther the distance, the greater the difference between individuals). It measures the actual distance between two points in n-dimensional space.
Cosine distance
Cosine similarity measures the difference between two individuals by using the cosine value of the angle between two vectors in vector space. The more similar the two vectors are, the smaller the included angle is, and the closer the cosine value is to 1. Compared with distance measurement, cosine similarity pays more attention to the difference of two vectors in direction than distance or length.
Hamming distance
Hamming distance represents the number of corresponding bits of two words (of the same length). We use d (x,y) to represent the Hamming distance between two words x,y. XOR two strings and count the number of strings with the result of 1, then this number is the Hamming distance.
The higher the vector similarity, the smaller the corresponding Hamming distance. For example, 10001001 and 10010001 have two different bits.
Among them, Hamming distance has two advantages: efficiency and fast calculation speed, and the accuracy is not low. For automation use cases of large suites, test efficiency is a part that can not be ignored. Therefore, the Hamming distance method is selected in this paper.
public ResponseResult getSimilarity(MultipartFile[] files) {
try {
int[] pixels1 = getImgFinger(files[0]);
int[] pixels2 = getImgFinger(files[1]);
int hammingDistance = getHammingDistance(pixels1, pixels2);
BigDecimal similarity = new BigDecimal(calSimilarity(hammingDistance)*100).setScale(2, BigDecimal.ROUND_HALF_UP);
return new ResponseResult(ResponseResult.SUCCESS_CODE, String.valueOf(similarity));
} catch (IOException e) {
logger.error("imgCompare exception", e);
return new ResponseResult(ResponseResult.EXCEPTION_CODE,e.getMessage());
}
}
private int getHammingDistance(int[] a, int[] b) {
int sum = 0;
for (int i = 0; i < a.length; i++) {
sum += a[i] == b[i] ? 0 : 1;
}
return sum;
}
private int[] getImgFinger(MultipartFile file) throws IOException {
Image image = ImageIO.read(file.getInputStream());
image = toGrayscale(image);
image = scale(image);
int[] pixels1 = getPixels(image);
int averageColor = getAverageOfPixelArray(pixels1);
pixels1 = getPixelDeviateWeightsArray(pixels1, averageColor);
return pixels1;
}
private BufferedImage convertToBufferedFrom(Image srcImage) {
BufferedImage bufferedImage = new BufferedImage(srcImage.getWidth(null),
srcImage.getHeight(null), BufferedImage.TYPE_INT_ARGB);
Graphics2D g = bufferedImage.createGraphics();
g.drawImage(srcImage, null, null);
g.dispose();
return bufferedImage;
}
private BufferedImage toGrayscale(Image image) {
BufferedImage sourceBuffered = convertToBufferedFrom(image);
ColorSpace cs = ColorSpace.getInstance(ColorSpace.CS_GRAY);
ColorConvertOp op = new ColorConvertOp(cs, null);
BufferedImage grayBuffered = op.filter(sourceBuffered, null);
return grayBuffered;
}
private Image scale(Image image) {
image = image.getScaledInstance(32, 32, Image.SCALE_SMOOTH);
return image;
}
private int[] getPixels(Image image) {
int width = image.getWidth(null);
int height = image.getHeight(null);
int[] pixels = convertToBufferedFrom(image).getRGB(0, 0, width, height,
null, 0, width);
return pixels;
}
private int getAverageOfPixelArray(int[] pixels) {
Color color;
long sumRed = 0;
for (int i = 0; i < pixels.length; i++) {
color = new Color(pixels[i], true);
sumRed += color.getRed();
}
int averageRed = (int) (sumRed / pixels.length);
return averageRed;
}
private int[] getPixelDeviateWeightsArray(int[] pixels,final int averageColor) {
Color color;
int[] dest = new int[pixels.length];
for (int i = 0; i < pixels.length; i++) {
color = new Color(pixels[i], true);
dest[i] = color.getRed() - averageColor > 0 ? 1 : 0;
}
return dest;
}
Five difficult and miscellaneous diseases & common problems
- Element cannot be located
Custom positioning expression, or positioning through js.
- How to deal with the residual driver and browser processes after the use case is run?
Set a scheduled task to clean up residual processes regularly every day - The use case execution time is too long, resulting in the incomplete execution of the use case, the connection has been disconnected, and the execution result cannot be received
You can solve this problem by setting timeOut, but timeOut cannot be set too long - After a period of execution of a large number of use cases, the machine is stuck and the memory is insufficient. What should I do?
In the scheduled task of cleaning up residual processes, increase the command to clean up the disk cache - After the service runs for a period of time, the selenium grid cluster node machine cannot connect to the master node
• check whether the main service is running normally
• check whether the selenium service of the master node is running normally (ps -ef | grep java)
• check whether the boot port is normal (netstat ant | grep4444)
You can see a large number of closures_ Wait process, and both requestor and receiver are current machines.
This indicates that the connection between the main service and selenium during the execution of the use case fails to end normally after the execution of the use case.
Check whether timeOut and browserTimeOut are set in the command to create the master node. Turn down or remove these two values - How does the distributed service realize the function of uploading files?
• upload your own files to the file server when writing use cases
• when the use case is executed, it is downloaded to the node machine where the use case is executed.
• how to download files to the client when the service runs on a linux server? Put a jar package on the node machine, call the client service when executing the use case, download the file locally, and then upload it - How to ensure service stability
• establish appropriate retry mechanism
• scheduled task cleaning system cache
• scheduled tasks to clean up residual processes
• timed restart of the machine (optional)
If the operation fails due to network instability, it is useless to retry in this case. Then you can mark the failure cases caused by this reason first. Try again when the execution of all use cases ends or the network returns to normal
Vi. summary
Business: it has been applied to multiple business scenarios, and the daily patrol case is 1000 +. Many bug s have also been scanned through automation. Bugs that cannot be found by manual testing, such as page label errors, can also be detected automatically. The iteration regression manpower is reduced by 5 manpower, and the iteration cycle is shortened from two Monday releases to one Monday releases.
Personal aspect: this platform was designed and completed independently by individuals. Many problems were encountered in the whole process. At the beginning, it was also very uneasy. After all, it was the first project. Fortunately, I persisted, learned a lot of new technologies and deepened my understanding of a lot of knowledge. The thought of exquisite design ideas and the satisfaction of solving new difficult problems made me move forward. I hope to see you here and work hard together.