Construction of ecological environment of Hadoop 3 Apache platform
System environment
The server: hadoop0,hadoop1,hadoop2 Operating system: CentOS 7.6 Software list and version: - jdk-8u202-linux-x64 - hadoop-3.2.28. - zookeeper-3.4.10 - afka_2.12-2.7.11 - spark-3.1.2-bin-hadoop3.2 - MySQL-5.1.72-1.glibc23.x86_64.rpm-bundle - hbase-2.3.7 - hive-3.1.2
1, Basic environmental preparation
1.1. Modify hostname (all nodes)
[root@hadoop0 ~]# vi /etc/hostname hadoop0
1.2. Modify the hosts file (all nodes)
[root@hadoop0 ~]# vi /etc/hosts 172.16.0.177 hadoop0 172.16.0.178 hadoop1 172.16.0.179 hadoop2
1.3. Close the firewall (all nodes)
View firewall status command: systemctl status firewalld
active(running) means that the firewall is open
Permanent closing method:
[root@hadoop0 ~]# systemctl disable firewalld [root@hadoop0 ~]# systemctl stop firewalld
After execution, the status changes to inactive(dead), indicating that the firewall is closed
1.4 clock synchronization (all nodes)
1.4.1 install and configure ntp to synchronize Alibaba cloud time server, and synchronize time from domestic general time server
[root@hadoop0 ~]# yum -y install ntp [root@hadoop0 ~]# crontab -e --After that, add the following text to represent regular execution every 5 minutes ntpdate Command synchronization time */5 * * * * /usr/sbin/ntpdate cn.pool.ntp.org
1.4.2. Close ntp:
[root@hadoop0 ~]# systemctl stop ntpd
1.4.3 start ntp:
[root@hadoop0 ~]# systemctl start ntpd [root@hadoop0 ~]# systemctl enable ntpd
1.4.4. Check whether crontab is executed
[root@hadoop0 ~]# tail -f /var/log/cron
1.5. Secret free login
1.5.1. Execute Hadoop 0, Hadoop 1 and Hadoop 2 respectively.
Enter / root directory
[root@hadoop0 ~]# ssh-keygen -t dsa [root@hadoop1 ~]# ssh-keygen -t dsa [root@hadoop2 ~]# ssh-keygen -t dsa
1.5.2. Execute on Hadoop 0
[root@hadoop0 ~]# cd /root/.ssh/ [root@hadoop0 .ssh]# cat id_dsa.pub >> authorized_keys
1.5.3 copy the key of Hadoop 0 to Hadoop 2
[root@hadoop0 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop2
1.5.4 copy the key of Hadoop 1 to Hadoop 2
[root@hadoop1 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop2
1.5.5 copy the key of Hadoop 2 to Hadoop 0 and Hadoop 1
[root@hadoop2 ~]# scp /root/.ssh/authorized_keys hadoop0:/root/.ssh/ [root@hadoop2 ~]# scp /root/.ssh/authorized_keys hadoop1:/root/.ssh/
1.6. Close SELinux (all nodes)
Modify profile
[root@hadoop0 ~]# vi /etc/selinux/config
Modify SELINUX=enforcing to SELINUX=disabled
Effective after restart
1.7 installation jdk
1.7.1 to facilitate management, create a software folder in the root directory
[root@hadoop0 /]# mkdir software
1.7.2. Put the jdk installation package under the software folder
[root@hadoop0 software]# ll -rw-r--r--. 1 root root 194042837 Nov 11 16:46 jdk-8u202-linux-x64.tar.gz
1.7.3. Unzip and rename
[root@hadoop0 software]# tar -zxvf jdk-8u202-linux-x64.tar.gz [root@hadoop0 software]# mv jdk1.8.0_202/ jdk [root@hadoop0 software]# ll drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk -rw-r--r--. 1 root root 194042837 Nov 11 16:46 jdk-8u202-linux-x64.tar.gz
1.7.4 copy to Hadoop 1 and Hadoop 2
[root@hadoop0 software]scp -r /software/jdk hadoop1:/software/ [root@hadoop0 software]scp -r /software/jdk hadoop2:/software/
1.7.5. Configure environment variables (all nodes)
[root@hadoop0 software]# vi /etc/profile export JAVA_HOME=/software/jdk export PATH=.:$PATH:$JAVA_HOME/bin [root@hadoop0 software]# source /etc/profile [root@hadoop0 software]# java -version java version "1.8.0_202" Java(TM) SE Runtime Environment (build 1.8.0_202-b08) Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
[root@hadoop1 software]# vi /etc/profile export JAVA_HOME=/software/jdk export PATH=.:$PATH:$JAVA_HOME/bin [root@hadoop1 software]# source /etc/profile [root@hadoop1 software]# java -version java version "1.8.0_202" Java(TM) SE Runtime Environment (build 1.8.0_202-b08) Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
[root@hadoop2 software]# vi /etc/profile export JAVA_HOME=/software/jdk export PATH=.:$PATH:$JAVA_HOME/bin [root@hadoop2 software]# source /etc/profile [root@hadoop2 software]# java -version java version "1.8.0_202" Java(TM) SE Runtime Environment (build 1.8.0_202-b08) Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
Note: the above steps can also refer to: Hadoop cluster first setup record (three nodes) step02: CentOS 7 system environment preparation
2, Hadoop ecological environment installation
2.1 hadoop installation
2.1.1 upload all installation packages to the software folder
[root@hadoop0 software]# ll total 1581028 -rw-r--r--. 1 root root 278813748 Nov 15 10:21 apache-hive-3.1.2-bin.tar.gz -rw-r--r--. 1 root root 395448622 Nov 11 17:29 hadoop-3.2.2.tar.gz -rw-r--r--. 1 root root 272812222 Nov 15 10:37 hbase-2.3.7-bin.tar.gz drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk -rw-r--r--. 1 root root 194042837 Nov 11 16:46 jdk-8u202-linux-x64.tar.gz -rw-r--r--. 1 root root 68778834 Nov 12 21:42 kafka_2.12-2.7.1.tgz -rw-r--r--. 1 root root 141813760 Nov 15 13:47 MySQL-5.1.72-1.glibc23.x86_64.rpm-bundle.tar -rw-r--r--. 1 root root 3362563 Nov 15 10:34 mysql-connector-java-5.1.49.tar.gz -rw-r--r--. 1 root root 228834641 Nov 15 09:12 spark-3.1.2-bin-hadoop3.2.tgz -rw-r--r--. 1 root root 35042811 Nov 12 20:02 zookeeper-3.4.10.tar.gz
2.1.2. Unzip and rename
[root@hadoop0 software]# tar -zxvf hadoop-3.2.2.tar.gz [root@hadoop0 software]# mv hadoop-3.2.2 hadoop
2.1.3 adding environment variables
[root@hadoop0 software]# vi /etc/profile export HADOOP_HOME=/software/hadoop export PATH=.:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin [root@hadoop0 software]# source /etc/profile
Also configure the environment variables of Hadoop 1 and Hadoop 2
2.1.4 configure hadoop-env.sh
[root@hadoop0 software]# vi hadoop-env.sh export JAVA_HOME=/software/jdk
2.1.5. Configure hdfs-site.xml
[root@hadoop0 software]# vi hdfs-site.xml <property> <name>dfs.datanode.data.dir</name> <value>file:///software/hadoop/data/datanode</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///software/hadoop/data/namenode</value> </property> <property> <name>dfs.namenode.http-address</name> <value>hadoop0:50070</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop1:50090</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property>
2.1.6. Configure yarn-site.xml
[root@hadoop0 software]# vi yarn-site.xml <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoop0:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoop0:8030</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>hadoop0:8050</value> </property>
2.1.7. Configure core-site.xml
[root@hadoop0 software]# vi core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop0/</value> </property> </configuration>
2.1.8. Configure mapred-site.xml
[root@hadoop0 hadoop]# vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--history address-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop0:10020</value>
</property>
<!--history web address-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop0:19888</value>
</property>
</configuration>
2.1.9. Configure workers
[root@hadoop0 hadoop]# vi workers
hadoop1
hadoop2
2.1.10 copy the configuration on Hadoop 0 to other nodes
Copy hadoop
[root@hadoop0 hadoop]# scp -r /software/hadoop hadoop1:/software/ [root@hadoop0 hadoop]# scp -r /software/hadoop hadoop2:/software/
2.1.11 format hdfs
[root@hadoop0 hadoop]# hdfs namenode -format
2.1.12 start up test
Start hadoop
[root@hadoop0 hadoop]# start-all.sh start
If an error is reported
ERROR:Attempting to operate on hdfs namenode as root
[root@hadoop0 hadoop]# cd /software/hadoop/etc/hadoop [root@hadoop0 hadoop]# vi hadoop-env.sh
Add: (the master node can be added)
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
Start the historyserver
[root@hadoop0 ]# cd /software/hadoop/sbin [root@hadoop0 sbin]# mr-jobhistory-daemon.sh start historyserver
Stop historyserver
[root@hadoop0 sbin]# mr-jobhistory-daemon.sh stop historyserver
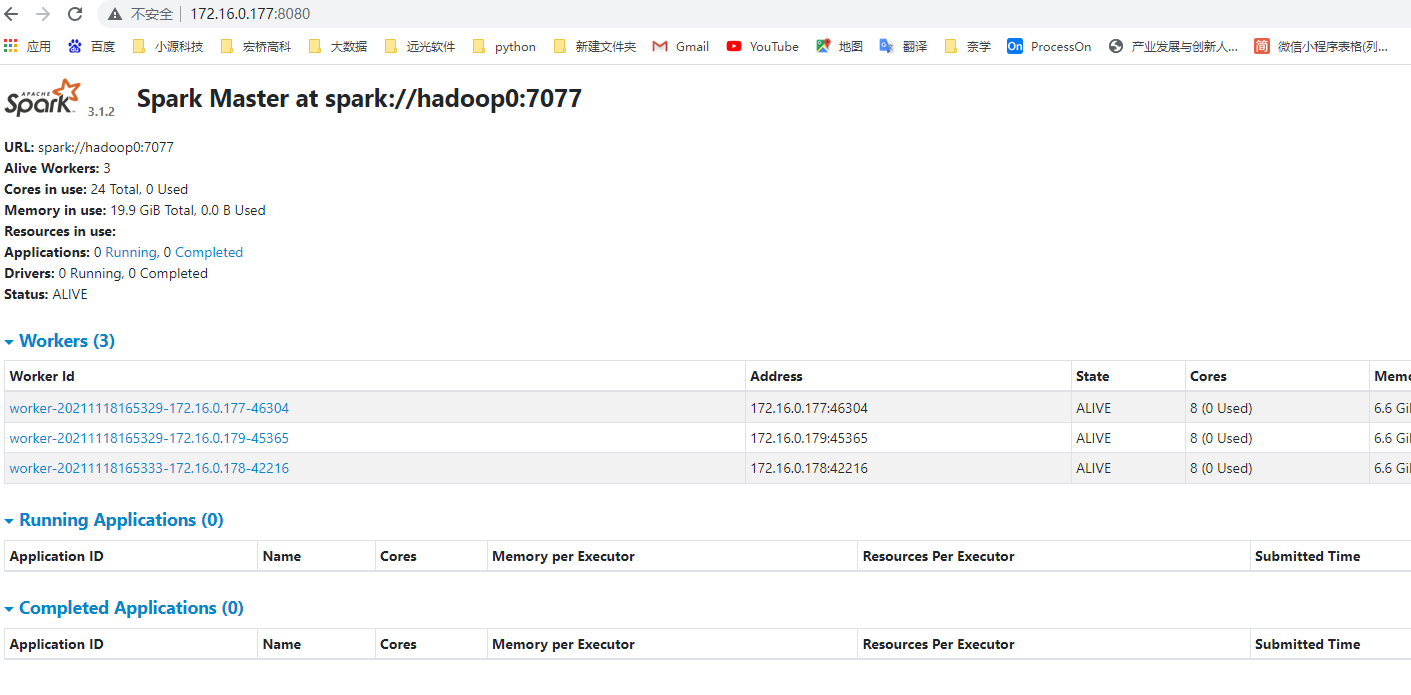
2.1.12. Start successfully to view the web page:
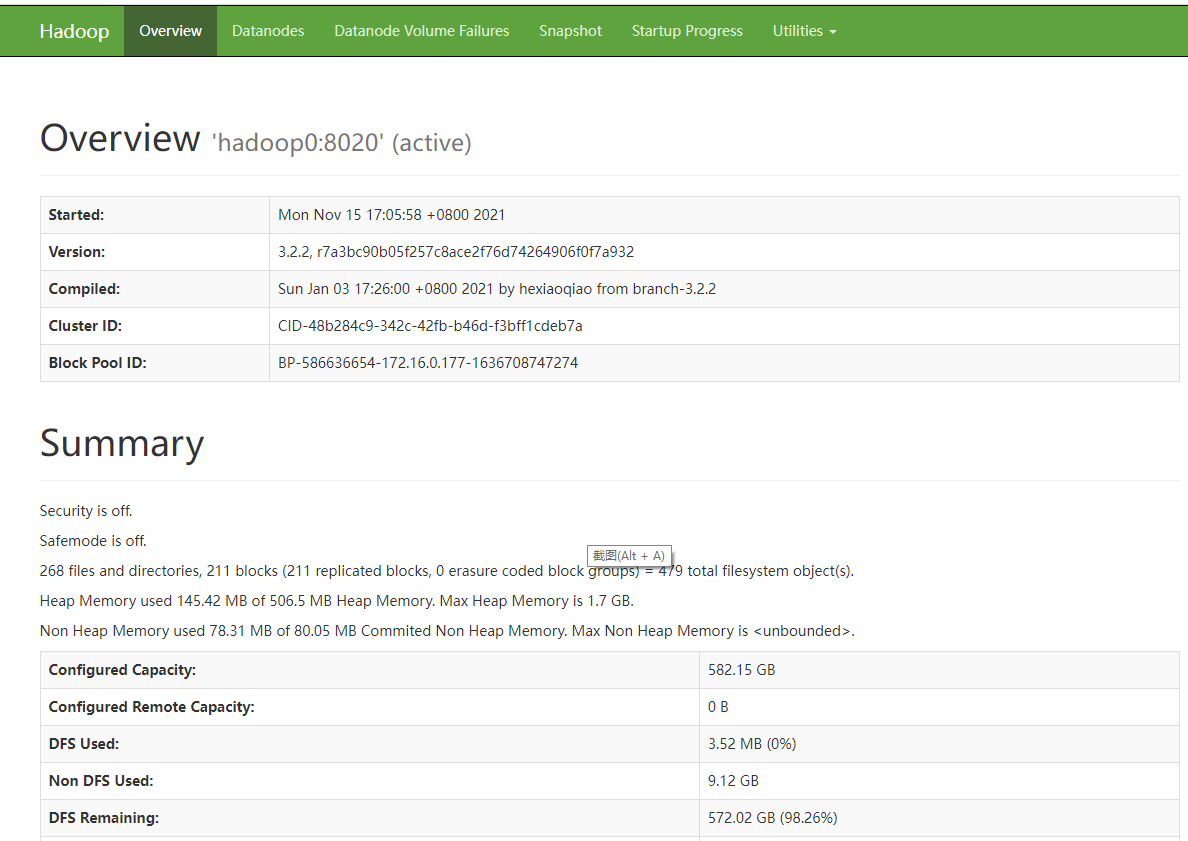
jobhistory web interface
2.2 installation of zookeeper
2.2.1. Unzip and rename
[root@hadoop0 software]# tar -zxvf zookeeper-3.4.10.tar.gz [root@hadoop0 software]# mv zookeeper-3.4.10 zk
2.2.2. Configure environment variables
[root@hadoop0 software]# vi /etc/profile export ZOOKEEPER_HOME=/software/zk export PATH=.:$PATH:$ZOOKEEPER_HOME/bin [root@hadoop0 software]# source /etc/profile
Also configure the environment variables of Hadoop 1 and Hadoop 2
2.2.3 modification of configuration file
[root@hadoop0 software]# cd /software/zk/conf [root@hadoop0 conf]# mv zoo_sample.cfg zoo.cfg [root@hadoop0 conf]# vi zoo.cfg dataDir=/software/zk/data server.0=hadoop0:2888:3888 server.1=hadoop1:2888:3888 server.2=hadoop2:2888:3888
2.2.4 create data storage directory
[root@hadoop0 zk]# mkdir data [root@hadoop0 zk]# cd data [root@hadoop0 data]# vi myid 0
2.2.5 copy to other nodes
[root@hadoop0 software]# scp -r /software/zk hadoop1:/software/ [root@hadoop0 software]# scp -r /software/zk hadoop2:/software/
2.2.6. Modify the myid of other nodes
Hadoop 0 corresponds to 0, Hadoop 1 corresponds to 1, and Hadoop 2 corresponds to 2. Just ensure that the values of each node are different
[root@hadoop1 data]# vi myid 1
[root@hadoop2 data]# vi myid 2
2.2.7 start zookeeper on three servers respectively
cd /software/zk/bin
[root@hadoop0 bin]# zkServer.sh start [root@hadoop1 bin]# zkServer.sh start [root@hadoop2 bin]# zkServer.sh start
2.2.8 viewing status
Only one node will be Mode: leader
[root@hadoop0 bin]# zkServer.sh status Using config: /software/zk/bin/../conf/zoo.cfg Mode: follower
[root@hadoop1 ~]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /software/zk/bin/../conf/zoo.cfg Mode: leader
[root@hadoop2 ~]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /software/zk/bin/../conf/zoo.cfg Mode: follower
2.3 hbase installation
2.3.1. Unzip and rename
[root@hadoop0 software]# tar -zxvf hbase-2.3.7-bin.tar.gz [root@hadoop0 software]# mv hbase-2.3.7 hbase
2.3.2. Configure environment variables
[root@hadoop0 software]# vi /etc/profile export HBASE_HOME=/software/hbase export PATH=.:$PATH:$HBASE_HOME/bin [root@hadoop0 software]# source /etc/profile
Also configure the environment variables of Hadoop 1 and Hadoop 2
2.3.3 modification of configuration file
Under the directory / software/hbase/conf, configure hbase-env.sh
[root@hadoop0 conf]# vi hbase-env.sh export JAVA_HOME=/software/jdk/ export HBASE_MANAGES_ZK=false Note: here false Represents the use of an external zookeeper,true The representative uses hadoop Self contained zookeeper
2.3.4. Configure hbase-site.xml
Note: hdfs://hadoop0:8020/hbase The port of is consistent with Hadoop. Hadoop does not have a port configured. The default port is
8020 is configured with a general configuration 9000 port.
[root@hadoop0 conf]# vi hbase-site.xml <property> <name>hbase.rootdir</name> <value>hdfs://hadoop0:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop0,hadoop1,hadoop2</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/software/zk</value> </property>
2.3.5. Configure the region servers file (the hostname of the stored region server)
hadoop1 hadoop2
2.3.6 copy to other nodes
[root@hadoop0 software]# scp -r /software/hbase hadoop1:/software/ [root@hadoop0 software]# scp -r /software/hbase hadoop2:/software/
2.3.7 startup
Necessary preconditions:
- a. Start ZooKeeper
- b. Start Hadoop
Start on the primary node Hadoop 0 and enter the / software/hbase/bin directory
After the environment variable is configured, you can start using start-hbase.sh in any directory.
[root@hadoop0 bin]# ./start-hbase.sh
2.3.8 stop
[root@hadoop0 bin]# ./stop-hbase.sh
2.3.9 shell command verification
On the primary server
[root@hadoop0 conf]# hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/software/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/software/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell Version 2.3.7, r8b2f5141e900c851a2b351fccd54b13bcac5e2ed, Tue Oct 12 16:38:55 UTC 2021 Took 0.0011 seconds hbase(main):001:0> list TABLE 0 row(s) Took 0.9189 seconds => [] hbase(main):002:0> quit
quit or exit exit
2.3.10 interface verification, browser access: http://hadoop0:16010 (the original 0.x version was 60010 port)
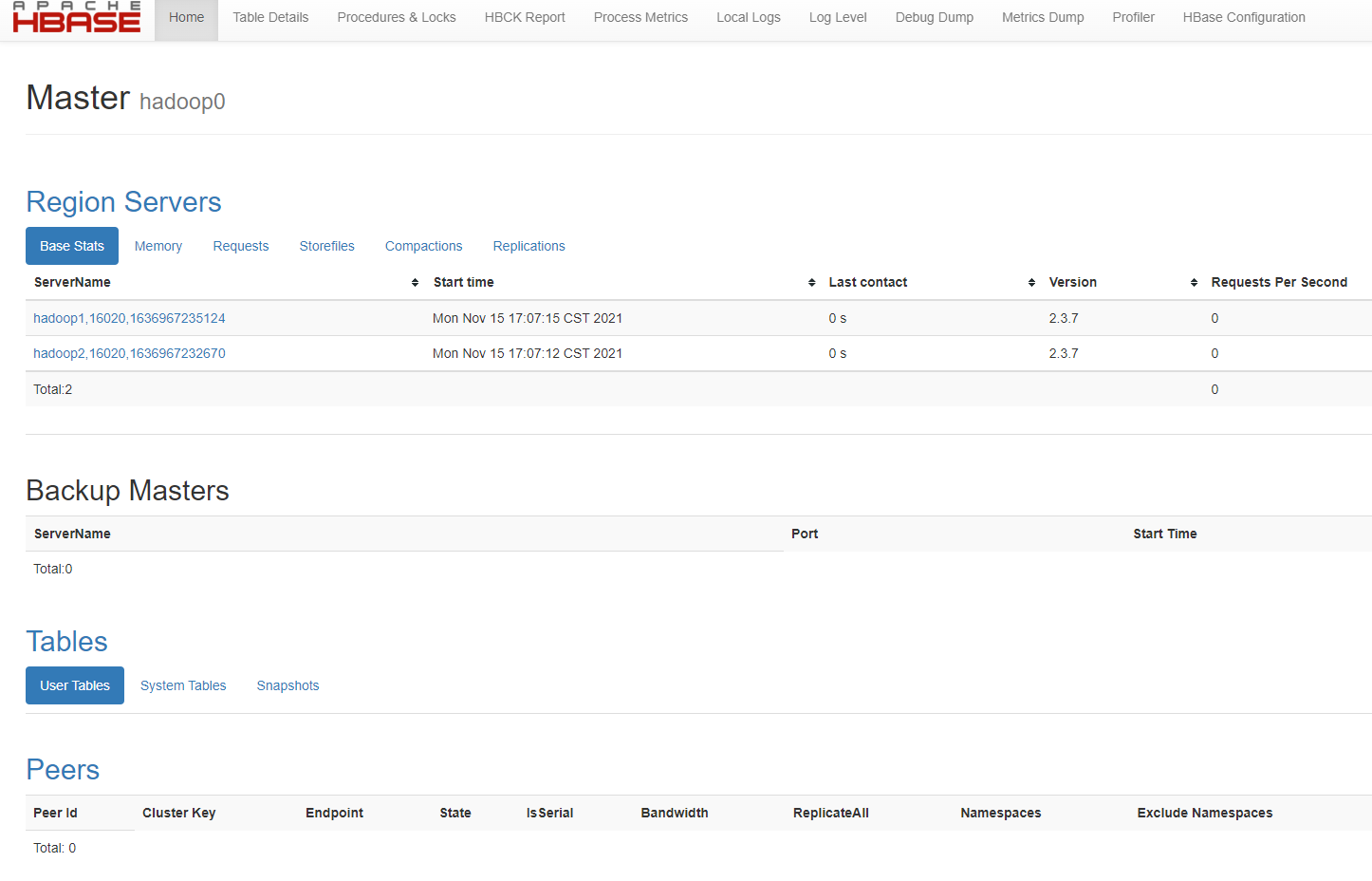
Note: stop hbase first, then hadoop, and finally zkServer
2.4. mysql installation
2.4.1 check and delete existing
Delete if you have one, and leave it alone if you don't have one.
[root@hadoop0 ~]# rpm -qa | grep mysql [root@hadoop0 ~]# rpm -e mysql-libs-5.1.73-8.el6_8.x86_64 --nodeps [root@hadoop0 ~]# rpm -qa | grep mariadb mariadb-libs-5.5.60-1.el7_5.x86_64 [root@hadoop0 software]# rpm -e --nodeps mariadb-libs-5.5.60-1.el7_5.x86_64
2.4.2. Delete mysql scattered folders
[root@hadoop0 software]# whereis mysql [root@hadoop0 software]# rm -rf /usr/lib64/mysql
2.4.3. Decompression and renaming
[root@hadoop0 software]# tar -xvf MySQL-5.1.72-1.glibc23.x86_64.rpm-bundle.tar [root@hadoop0 software]# tar -xvf MySQL-5.1.72-1 mysql
2.4.4 installation of server
[root@hadoop0 software]# cd mysql [root@hadoop0 mysql]# ll total 138496 -rw-r--r--. 1 7155 wheel 7403559 Sep 12 2013 MySQL-client-5.1.72-1.glibc23.x86_64.rpm -rw-r--r--. 1 7155 wheel 65449113 Sep 12 2013 MySQL-debuginfo-5.1.72-1.glibc23.x86_64.rpm -rw-r--r--. 1 7155 wheel 8791454 Sep 12 2013 MySQL-devel-5.1.72-1.glibc23.x86_64.rpm -rw-r--r--. 1 7155 wheel 20787882 Sep 12 2013 MySQL-embedded-5.1.72-1.glibc23.x86_64.rpm -rw-r--r--. 1 7155 wheel 19526788 Sep 12 2013 MySQL-server-5.1.72-1.glibc23.x86_64.rpm -rw-r--r--. 1 7155 wheel 1883524 Sep 12 2013 MySQL-shared-5.1.72-1.glibc23.x86_64.rpm -rw-r--r--. 1 7155 wheel 3317236 Sep 12 2013 MySQL-shared-compat-5.1.72-1.glibc23.x86_64.rpm -rw-r--r--. 1 7155 wheel 14643692 Sep 12 2013 MySQL-test-5.1.72-1.glibc23.x86_64.rpm [root@hadoop0 mysql]# rpm -ivh MySQL-server-5.1.72-1.glibc23.x86_64.rpm
2.4.5 installing the client
[root@hadoop0 mysql]# rpm -ivh MySQL-client-5.1.72-1.glibc23.x86_64.rpm
2.4.6 log in to mysql (remember to start mysql service before logging in)
Start MySQL service
[root@hadoop0 mysql]# service mysql start
Log in to MySQL
Then log in, and the initial password is / root /. Mysql_ In the file secret
[root@hadoop0 software]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 190 Server version: 5.1.72 MySQL Community Server (GPL) Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
Or log in with root password free
2.4.7. Modify password
First use root Account login mysql,Then execute:
Mode 1
mysql>UPDATE user SET password=PASSWORD('123456') WHERE user='root';
mysql>FLUSH PRIVILEGES;
Mode 2
mysql> set PASSWORD=PASSWORD('root');
Exit login verification to see whether the password is changed successfully
2.4.8 add remote login permission and execute the following two commands:
mysql> grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option; mysql> flush privileges;
2.4.9. Create hive database
establish hive database >create database hive; establish hive User and set password >create user 'hive'@'%' identified by 'hive'; to grant authorization >grant all privileges on hive.* to 'hive'@'%'; Refresh permissions >flush privileges;
2.5 hive installation
2.5.1. Decompression and renaming
[root@hadoop0 software]# tar -zxvf apache-hive-3.1.2-bin.tar.gz [root@hadoop0 software]# mv apache-hive-3.1.2-bin hive
2.5.2. Modify configuration file
There is no directory. Just vim.
[root@hadoop0 software]# cd hive [root@hadoop0 conf]# vim hive-site.xml <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> </configuration>
2.5.3. Add MySQL driver package (mysql-connector-java-5.1.49-bin.jar)
The jar package is placed in the lib directory under the root path of hive
2.5.4. Configure environment variables
[root@hadoop0 conf]# vi /etc/profile [root@hadoop0 conf]# export HIVE_HOME=/software/hive [root@hadoop0 conf]# export PATH=$PATH:$HIVE_HOME/bin [root@hadoop0 conf]# source /etc/profile
Also configure the environment variables of Hadoop 1 and Hadoop 2
2.5.5 verify Hive installation
[root@hadoop0 lib]# hive --help Usage ./hive <parameters> --service serviceName <service parameters> Service List: beeline cli help hiveburninclient hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledump rcfilecat schemaTool version Parameters parsed: --auxpath : Auxillary jars --config : Hive configuration directory --service : Starts specific service/component. cli is default Parameters used: HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory HIVE_OPT : Hive options For help on a particular service: ./hive --service serviceName --help Debug help: ./hive --debug --help
2.5.6 initialize metabase
Note: when hive relies on an ordinary distributed hadoop cluster, it will be initialized automatically when it is started for the first time.
[root@hadoop0 lib]# schematool -dbType mysql -initSchema
2.5.7 copy to other nodes
[root@hadoop0 software]# scp -r /software/hive hadoop1:/software/ [root@hadoop0 software]# scp -r /software/hive hadoop2:/software/
2.5.8. Start Hive client
[root@hadoop0 bin]# hive --service cli Logging initialized using configuration in jar:file:/software/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties hive>
2.5.9 exit Hive
hive> quit; perhaps hive> exit;
2.6 kafka installation
2.6.1. Decompression and renaming
[root@hadoop0 software]# tar -zxvf kafka_2.12-2.7.1.tgz [root@hadoop0 software]# mv kafka_2.12-2.7.1 kafka
2.6.2. Modify configuration file
[root@hadoop0 software]# cd kafka [root@hadoop0 kafka]# mkdir data [root@hadoop0 kafka]# cd config [root@hadoop0 config]# vi server.properties #Each broker ID is different broker.id=0 #Add the following three items after log.retention.hours=168 message.max.byte=5242880 default.replication.factor=1 replica.fetch.max.bytes=5242880 #Set the connection port of zookeeper zookeeper.connect=hoatname:2181,hoatname:2181,hostname:2181 #Directory of log files log.dirs=/software/kafka/logs/
2.6.3 copy to other nodes
[root@hadoop0 software]# scp -r /software/kafka hadoop1:/software/ [root@hadoop0 software]# scp -r /software/kafka hadoop2:/software/
Note: modify the broker.id value in kafka/config/server.properties of the cluster node to make each node unique
2.7 spark installation
2.7.1. Decompression and renaming
[root@hadoop0 software]# tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz [root@hadoop0 software]# mv spark-3.1.2-bin-hadoop3.2 spark
2.7.2. Modify the configuration spark-env.sh
[root@hadoop0 software]# cd spark/conf [root@hadoop0 conf]# vi spark-env.sh export JAVA_HOME=/root/training/jdk1.7.0_75 export SPARK_MASTER_HOST=spark82 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=1 export SPARK_WORKER_MEMORY=1024m
2.7.3. Modify and configure slave
[root@hadoop0 conf]# vi slave hadoop1 hadoop2
2.7.4 copy to other nodes
[root@hadoop0 software]# scp -r /software/spark hadoop1:/software/ [root@hadoop0 software]# scp -r /software/spark hadoop2:/software/
2.7.5. Start Spark cluster: start-all.sh